
一种结合深度学习特征和社团划分的图像分割方法
2018-11-14 10:27胥杏培宋余庆
小型微型计算机系统 2018年11期
胥杏培,宋余庆,陆 虎
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
1 引 言
近几年来,图像分割作为计算机视觉领域中十分重要的研究领域,吸引了大量学者的兴趣.图像分割被广泛应用于图像检索,医学图像的处理,人脸识别,遥感图像处理[1]等领域.图像分割是对图像的每个像素点进行处理,划分成若干个相似区域.但是在实际应用中,我们所要求的是要求图像分割能够得到更好的分割的结果,在时间上,要求有更快的速度.虽然该领域已经出现了很多好的算法,但想要开发出一种简单有效的图像分割算法仍存在较大的困难和挑战.
寻找到一种好的特征对于提高分割的准确性是非常重要的,大多数现有的特征都依赖人工标定.例如HOG,SIFT,LBP,GLCM等特征.最近,用深度学习的方法自动获取特征在机器学习领域广泛应用.例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层特征,例如边缘检测器,小波滤波器等,然后在这些低层次特征的基础之上,通过非线性组合来获得高层次的特征.常用的深度学习模型结构包括自动编码器(Auto Encoder)[2],深信度网络(Deep Belief Networks)[3],卷积神经网络( Convolutional Neural Networks)等.其中,卷积神经网络(CNN)[4-6]成功应用于计算机视觉领域,归结于它能够很好的将图像的低级特征通过非线性方式整合成高级特征[7].
在本文中,我们提出了一种新的自适应图像分割方法.为了解决以像素点为单位分割的庞大计算量,我们通过SLIC超像素算法对图像预处理之后,将改进的VGG-16模型作为特征提取器,提取单个超像素区域的深度学习特征.并且提取对应超像素区域Lab颜色特征,构建两个相似度矩阵,通过线性组合构建成一个相似度矩阵.用社团划分的思想在相似度矩阵的基础上对图像进行分割,如图1所示.为了得到合理的分割结果,本文采用谱聚类算法对图像进行聚类,并用模块度Q[8,21]来选择最佳的分割类别数,因此省去了繁琐的人工设定分割类别数的过程.
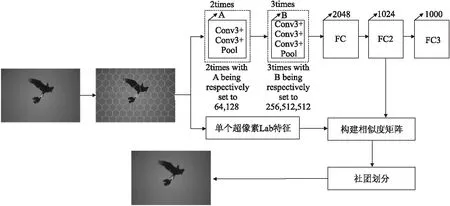
图1 基于深度学习特征和社团划分的图像分割方法
2 相关工作
本章节我们主要回顾前人的相关工作.目前图像分割方法主要是通过整合人工特征对图像进行分割.S.J.Li等人提出了一种基于超像素的HOS算法[14],该算法通过提取超像素区域的颜色特征和纹理特征,但该算法在构建相似度矩阵的过程中,迭代的时间较长,从而使得算法的时间复杂度较高.Ester.M提出了超像素和密度函数,将高密度的区域划分为簇,并且在数据空间中进行聚类的DBCAN算法[10],该算法是基于密度函数定义,相对抗噪音能相对处理任意形状的簇.Ncut算法[11]是一种经典的图像分割方法.Pizzuti提出了利用遗传算法和Ncut算法相结合的Gencut算法[12].L.Zelnik等人提出了一种基于自适应谱聚类Self-tuning算法[13]. 由于算法需要将图像的维数设定为固定大小,因此该算法只适用于维度较小的图像.
针对以像素点为单位的庞大的计算以及人工提取特征的不确定性,我们通过将深度学习和社团划分相结合的方法,来对图像进行分割.首先通过SLIC超像素算法对图像进行预处理,将图像由像素级划分为区域级.将图像划分为若干超像素区域,然后再通过微调VGG-16模型,将该模型作为本文深度学习特征提取器,提取单个超像素区域的深度学习特征.并且提取单个超像素区域的Lab颜色特征,通过线性叠加,构建相似度矩阵.将单个超像素点看成社团中的节点,通过社团划分方法对图像进行自适应分割.大量的实验结果验证了本文算法的有效性.
3 算法描述
3.1 多尺度特征提取
超像素算法已经被广泛应用于计算机视觉的各个领域中.超像素可以有效的捕捉图像的结构化信息,本文首先使用简单线性迭代聚类(SLIC)[15]方法对图像进行过分割,得到一定数量的超像素.本文设定的超像素的个数为200.其次,本文采用两种特征描述符来表示一幅图像,分别为Lab颜色特征以及深度学习特征(改进VGG-16模型学习的特征[16]).
本文的低级特征采用Lab颜色特征.因为对于彩色图像而言,颜色是最直接和最重要的特征之一.为了降低计算复杂度,在计算相似度矩阵之前先计算超像素的邻接矩阵.超像素i,j对应邻接矩阵为:
(1)
我们定义单个超像素区域的Lab颜色特征的相似度矩阵为:
(2)
本文使用改进的VGG-16模型提取深度学习的特征,该模型是在Caffe框架下,通过训练ImageNet数据集得到.本文通过微调VGG-16模型,将该模型的全连接层替换成全卷积.并且将模型的第15层FC2层的特征维度由4096维降成1024维.大量的实验表明,模型收敛更快,能够得到更好的高级特征.
由于我们提取的超像素区域可能是一个不规则的区域,而该模型的输入必须是一个规则区域,因此我们将单个超像素区域放入到一个矩形框内.输入图像,并在该模型的全连接层FC2层提取图像的特征,得到1024维的深度学习特征.于是得到的不同超像素区域的深度学习特征维度为200×1024.同时我们在超像素邻接矩阵的基础上构建.然后计算欧式距离来构建超像素邻接矩阵的相似度矩阵
(3)
其中n表示超像素的个数.i,j∈[1,n] ,并且xi,xj,表示单个超像素的深度学习特征,维度为1×1024.
综合上述的改进VGG-16模型提取深度学习特征得到相似度矩阵W(deep)(维度为200×200),和Lab颜色特征的相似度矩阵W(color)(维度为200×200).我们通过线性叠加的方式,用平衡参数a来调整颜色特征和深度学习特征所占的比重,得到新的混合特征W(mix)定义为:
W(mix)=a×W(color)+(1-a)×W(deep)
(4)
3.2 社团划分
随着复杂网络理论的发展,基于图论的图像分割技术已经有了很大的发展.我们将SLIC超像素算法得到的单个超像素点看成是社团中的节点.通过计算节点之间的相似度,对社团进行聚类.将图像的分割问题归结为社团划分问题.

为了有效评价社团划分的合理性,Newman和Girvan[19,20]提出了一个用以评价网络分解满意度的指标的质量函数或者称为模块度Q[21],应用于加权网络分析.适用于加权网络和加权邻接矩阵,模块度Q被定义为:
(5)
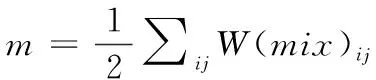
BSDS500数据集是由伯克利大学提供的自然图像数据集,该数据集包含500张自然图像,并且每张图像包含对应的ground-truth.且人工标定的图像超过95%的类别数都小于20,因此在本文中我们设定谱聚类算法n的输入为[2,20],分别计算19个聚类结果,然后通过计算模块度Q的值,来选取最佳的聚类结果.
3.3 算法流程
本文算法如下:基于深度特征学习的图像分割算法
输入:图像
输出:最终的分割结果
Step1.通过SLIC过分割获得超像素
Step2.提取超像素颜色特征以及深度学习特征,构建两个相似度矩阵W(color)和W(deep).
Step3.通过参数a,构建相似度矩阵w(mix)
Step4.对获得的相似度矩阵w(mix),通过谱聚类,得到个聚类的结果
Step5.通过模块度Q计算每个聚类对应的Q值,选取最大的Q值对应的聚类
Step6.得出聚类结果,实现图像分割
4 实验结果与分析
在本章节中,为了验证算法的有效性,我们在BSDS500数据集上进行了测试,并将实验的数据结果与CTM算法[9],Gencut算法[12],DBSCAN算法[10],HOS算法[14],Ncut算法[11],self-tuning算法[13]进行了比较.算法的实验环境为:CPU:i-6700k,显卡:GTX1080,内存:32G,操作系统:Ubuntu 14.04.
为得到定量分析结果,我们通过两种指标来对分割进行评价度量,(1)概率兰德指数(PRI)[22],(2)信息变化(VOI)[23].
概率兰德指数(Probabilistic Rand Index,PRI)是一个经典的评价聚类的标准.PRI需要给定实际类别信息C,假设K是聚类结果,a表示在C与K中都是同类别的元素对数,b表示在C与K中都是不同类别的元素对数,则概率兰德指数为:
(6)
信息变换(Variation of Information,VOI)被定义为:
VOI(c,c′)=H(c)+H(c′)-2I(c,c′)
(7)
其中H(c)和H(c′)是c和c′分割的熵,并且I(c,c′)是c和c′分割的互信息,这一指标的范围是[0,+∞],VOI的值越小越好.
如图2所示.我们在BSDS500数据集上测试了本文的算法.根据大量的实验结果显示,当a=0.3时PRI和VOI的指标达到最佳.本文针对不同算法,选取合适的参数,整个数据集求PRI和VOI的均值得到如图2所示的直方图.
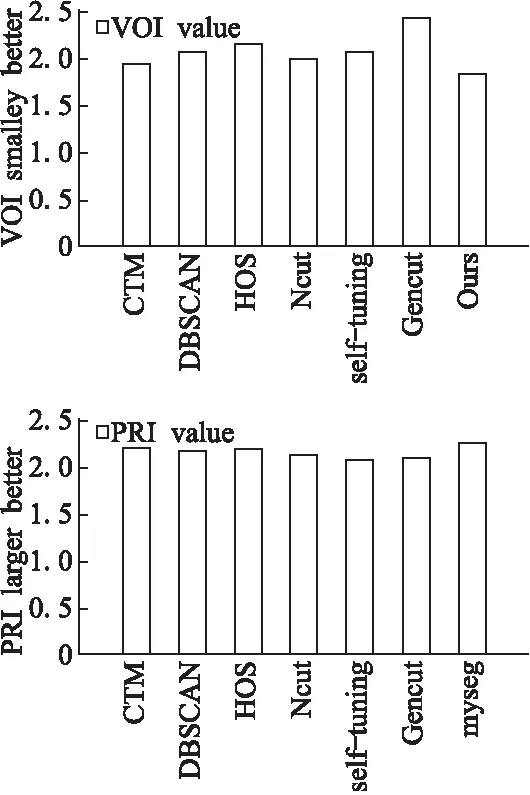
图2 本文算法与其它流行算法的PRI和VOI值的比较
如图3 所示,本文算法与与CTM算法[9],Gencut算法[12],DBSCAN算法[10],HOS算法[14],Ncut算法[11],Self-tuning算法[13]分割结果的比较,由于BSDS500数据库中的图像大小为321×481或者481×321,然而Ncut算法,和Self-tuning算法不能直接处理这样大的图像,因此我们先将图像维度缩小为160×160,然后对图像进行分割.本文算法,CTM算法,Gencut算法,DBSCAN算法,HOS算法均可以在原图上进行分割.试验中算法均需要设置参数,对于CTM算法,我们按照对应文献中的参数选择方法,并在一定范围内变化,选择最优的结果.DBSCAN算法需要预先定义超像素的个数k.
为了方便比较,我们设定了和本文算法相同的超像素的个数.Gencut算法需要预先设定9个参数,该算法通过遗传算法和Ncut算法的结合进行分割,CTM算法是在超像素的基础之上,通过对纹理特征的拟合进行分割,DBSCAN是通过超像素预处理之后,根据密度函数进行分割.HOS算法通过超像素对图像进行预处理之后,提取图像的HOG纹理特征和Lab颜色特征对图像进行分割,Ncut算法和Self-tuning算法需要预定义像素点k领域,试验中我们设置k=8,本文算法通过超像素算法对图像进行预处理,引入深度学习的思想,提取图像的深度学习特征,并且结合传统的颜色特征,构建相似度矩阵,通过谱聚类算法对图像进行分割,通过下图可以看出我们的算法在PRI和VOI指数上均取得较好的实验结果.
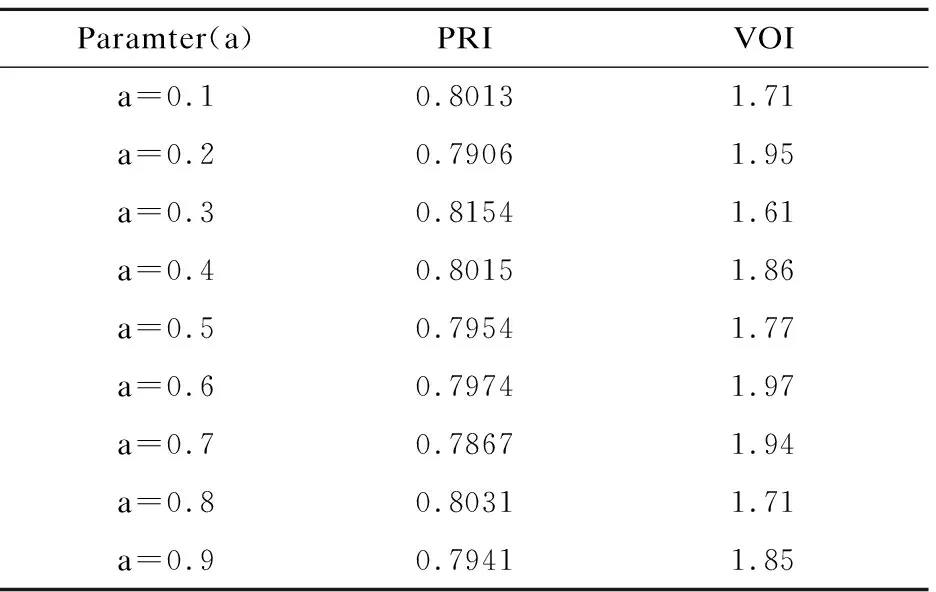
表1 针对a的不同取值PRI和VOI的值
如表 1所示,我们通过平衡参数a来调整深度学习的特征和Lab颜色特征之间的权重.表1的实验结果是在BSDS500数据集测试,并对实验结果求均值.本文设定a的取值范围属于[0,1]之间,当a=0.3时,本文算法的PRI值最大,VOI值最小.
如图4所示,本文算法与其他6中算法实验对比图.本文算法相较于其他几种算法,对于山的轮廓部分能够很好的分割出来.并且对于整个山体的细节部分可以很好的分割出来.由于本文算法不仅注重底层的颜色特征的提取,并且能够把握深度学习提取的高层特征.将两者相结合构建新的相似度矩阵,并且通过一个线性参数来调整两者的比重.再通过社团划分的思想对图像进行分割.

图4 本文算法和其他流行方法的比较,依次为原图,CTM,DBSCAN,HOS,Gencut,CTM,Self-tuning,以及本文算法
如图 5所示,我们的算法在BSDS500上进行了测试,图 5的上半部分是原图,下半部分是分割后的结果图.我们通过选取BSDS500数据集中自然图像的风景,物体,动物,人等具有代表性的图像.来证实我们算法的有效性.从图中我们可以看出,我们的算法能够很好的处理简单以及复杂背景的自然图像,并且能够有效的避免过分割现象.

图5 算法在BSDS500数据集上测试的结果,上部分原图,下部分为分割图
5 结 语
在本文中,我们提出了一种基于深度学习特征和社团划分的彩色图像分割方法.首先对图像进行超像素预处理之后,提取超像素区域的颜色特征以及深度学习特征,构建相似度矩阵.在相似度矩阵的基础上,利用谱聚类算法进行聚类.选取最大模块度Q值来判断实验最佳聚类效果.大量的实验结果验证了本文提出的算法的有效性.此外,我们的算法在公共数据集BSDS500上进行了测试.并与现有的几种著名图像分割方法进行比较.在不同图像上的分割实验结果表明,我们提出的图像分割算法优于其它几种方法.该算法能够有效的处理复杂背景的图像,并减少过分割现象.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
现代计算机(2018年27期)2018-10-25
军事文摘(2017年16期)2018-01-19
舰船电子对抗(2017年6期)2018-01-11
学苑创造·A版(2017年1期)2017-01-19
互联网天地(2016年1期)2016-05-04
CHIP新电脑(2016年3期)2016-03-10
漫画月刊·哈版(2015年2期)2015-05-26
