
面向开源软件的自承认代码重构现象研究
2018-11-15 01:54李增扬
小型微型计算机系统 2018年11期
张 迪,李增扬,李 兵,梁 鹏
(武汉大学 计算机学院,武汉 430072)
1 引 言
软件系统从诞生开始会发生逐渐演进.软件演进通常占据软件开发生命周期的75%[1].然而,质量的降低和复杂性增加促使了开发人员提出灵活的、可维护的、可扩展的技术用以提高软件的可靠性且减少修改的代价.重构就是其中之一.根据定义,重构是“改变软件系统的过程,它不会改变代码的外部行为,而是改进其内部结构[2]”.重构的目标是使源代码更简单、更易于维护[2].软件的可维护性可以通过代码异味[3](code smell)来度量,而重构是解决代码异味的一种有效方法[1].
我们知道,开发人员经常在版本控制系统的提交消息中明确声称他们对软件系统的修改为重构(Refactoring).所以,根据定义,重构之后的软件系统的可维护性将会得到改善.我们称这类代码修改为开发人员的自承认重构(Self-admitted refactoring,简称SAR).因此,一个项目的提交可以分为两类:自承认重构(简称:SAR)和非自承认重构(简称:非SAR).一个SAR对应的软件代码库版本称为SAR版本.目前,SAR是否改善了源代码的结构质量尚未得到研究和证实.
本文为了深入了解自承认重构现象,对一个大型开源软件项目(即Fastjson)进行了探索性案例研究.我们使用代码异味(Code smell)来评估SAR对软件质量的影响.本文得到的主要结果有:1)在选定的项目中,SAR往往不增加代码异味的数量;2)在SAR版本中,被修改的源文件数量与新引入的代码异味之间存在显著相关关系;3)进行过SAR的开发者占总开发者的比例相对较小;4)SAR在软件生命周期中分布不均衡.
本文的组织如下:第2节介绍代码异味及其检测工具,并介绍SAR的研究背景和相关工作;第3节描述了案例研究设计,包括研究问题、案例选取、所需收集的数据、数据收集方法、数据分析方法等;第4节给出了研究结果;第5节针对结果进行了讨论;最后,第6节给出了本文结论.
2 相关研究
在这一节中,我们将从三个方面讨论与自承认重构领域相关的研究工作.
2.1 代码异味与重构
Fowler等人提出使用代码异味(code smell)来表示代码的结构质量问题[2].他们定义了22种常见的代码异味,包括重复代码(duplicated code)、狎昵关系(inappropriate intimacy)等[2].后来一些新的代码异味被提出,例如:Kerievsky提出了5种新的代码异味,包括条件复杂度(conditional complexity)、方案扩展(solution sprawl)等[4].Zhang等人针对目前代码异味的研究情况做了文献综述,他们发现Duplicated Code被过度研究,且很多的研究重点都放在了检测代码异味上,而非代码异味对软件的影响[5].
重构可以帮助改进软件设计,使软件更容易理解,帮助开发人员发现bug并提高开发效率[2].针对手工重构存在容易引入错误的问题,刘伟等人提出了一种以单例模式为导向的源代码自动重构方法,通过将源代码转换成抽象语法树并进行操作的方式,成功实现了单例化重构[6].Monteiro和Fernandes提供了一组面向切面编程(AOP)风格代码的重构和代码异味特征,并且还提供了一组特定的AOP的重构[7].Hamaz提出了一种基于对代码异味之间依赖关系的定量分析的方法,指出有些代码异味需要更多的补救修复工作,并且在重构过程中开发人员应给予必要的关注[8].另外,他们的文章中还介绍了Kerievsky和Fowler提出的代码异味之间的区别.但在项目的提交中,一些开发人员明确承认的重构却很少被研究.
2.2 代码异味检测方法与工具
在代码异味数量庞大的情况下,手动检测代码异味是低效的.此外,它严重依赖于开发人员的经验,缺乏相关的经验可能导致检测的混乱[9].而各种检测代码异味的方法和工具可以进行良好的检测工作.一些工具已经被应用到软件开发的实践中.其中,Klockwork、PMD和FindBugs是典型的用来检测潜在代码缺陷(检测包括:命名缺陷和未使用的代码)和代码异味(例如:长方法和上帝类等)的工具.
需要指出的是,代码异味一般产生在代码的升级过程中产生.林涛等人总结了代码异味面临的两个问题:1)类型难以划分;2)难以量化.他们对4种代码异味进行了量化研究,并提出了面向代码异味的“容器-破坏者-发现者”检测策略.将人工免疫基本概念和信号迁移至软件工程,检测结果优良[10].
2.3 自承认现象的研究
自承认现象的研究,在技术债务研究领域比较流行.Potdar和Shihab对自承认技术债务(Self-admitted technical debt)进行了探索性研究,发现在2.4%的文件中存在自承认技术债务,而26.3%~63.5%的自承认技术债务在引入后会被清除[11].
Gabriele Bavota 等人,针对Potdar的论文进行了深入的分析,通过对159个软件的自承认技术债务的演变与扩散的检验中得出以下几点结论:1)自承认技术债务普遍存在的;2)技术债务主要表现为代码,缺陷以及需求债务;3)在开发者没有修复的情况下会随时间增加;4)即使修复,也会在系统存活很长时间[12].Maldonado等人利用自然语言处理的方法,通过对源注释的自动识别来挖掘自承认技术债务,研究表明即使在一个相对较小的训练数据集下也具有良好的准确率[13].Sultan Wehaibi等人就自承认技术债务对软件质量的影响方面进行了进一步探索,通过对开源项目进行了案例研究后发现,自承认技术债务比非自承认技术债务要引入更少的代码缺陷,技术债务不仅可能产生代码缺陷的影响,而且会令系统难以适应未来的变化[14].
在软件重构与自承认技术债务相关研究的启发下,我们将类似的概念迁移到探索自承认重构(SAR)的方向上,使用代码异味作为代码质量的度量指标,来验证在SAR版本中代码质量是否得到了改善.关于SAR的研究结果将有助于开发者了解代码的状况以及软件的质量,并提示开发人员改善项目.
3 研究设计
我们对一个托管在GitHub上的大型Java开源软件项目(Open source software,简称OSS)进行案例研究.在本节中,我们将根据Runeson和Höst提出的指导原则[15]来设计和描述本文的案例研究.
3.1 目标与研究问题
本案例研究的目标是:利用“目标-问题-度量”方法[16],在开源项目环境中,分析SAR对源代码的影响,并验证其提高代码可维护性的有效性.基于上述目标,我们提出四个主要研究问题(RQs):
RQ1:SAR改善了源代码的结构质量吗?
重构的目的在于提高软件的内部质量[2],因此,我们想探究在SAR版本中源代码的质量是否有所提高.这个RQ可以分解为以下三个子问题进行细化研究:
RQ1.1:SAR减少了代码异味吗?如果是,哪些代码异味最容易减少?
代码异味是被广泛接受的衡量源代码质量的指标[2].因此,研究SAR是否减少了代码异味将是评估代码质量的关键.如果答案是肯定的,那么接下来我们想知道哪些代码异味会在SAR版本中减少.
RQ1.2:与非SAR版本相比,SAR版本是否具有更少的代码异味?
代码异味的数量可以在一定程度上反映软件系统的结构质量.所以,SAR中的代码异味是否少于非SAR是一个值得研究的问题.
RQ1.3:在SAR中,代码异味的严重级别的分布情况是怎样的?
代码异味检测工具提供了代码异味的严重级别,其代表着代码异味的严重程度和修复的优先等级.在SAR中,代码异味严重程度的分布可以用来评估代码的总体质量状态.
RQ2:SAR和非SAR版本之中修改文件的数量有明显区别吗? 被修改文件的数量与SAR中新引入的代码异味的数量具有相关性吗?
在软件开发过程中,每一次提交都涉及到不同数量的源文件的修改,因此被修改的文件数量和SAR中引入的代码异味数量之间的关系是一个值得探索的问题.
RQ3:是否有开发者倾向于自承认重构?
不同的开发者有不同的代码风格和代码理解能力.自承认重构信息是基于自然语言基础上的,因此SAR是否与开发者的经验、写作风格或者提交次数有关系,是研究SAR现象的关键.
RQ4:在项目开发的生命周期中,SAR是如何分布的?
SAR分布是否平衡反映着软件项目开发周期中的自承认重构状态,了解SAR分布对我们了解整体软件生命周期状态将有所帮助和启发.
3.2 案例选取
本研究主要探索SAR现象,因此以SAR作为分析单元.我们将采用以下标准对案例进行选取:
·所选项目应具有两年以上的历史.
·所选项目主要开发语言为Java.PMD是被广泛用于检测代码异味的工具,本案例分析中,我们将使用PMD来检测代码异味.我们希望利用PMD的eclipse插件,从而所选项目应为Java编写.
·所选项目拥有至少20个SAR.SAR越多意味着拥有越多可以用于案例分析研究的数据,而相对较少的SAR可能会导致结论的局限.
·所选项目的开发开发者数目需超过10个.
·项目的源代码应该有良好的注释(高可读性和可分析性),以便于数据分析.
·项目完整的提交数据列表可以由TortoiseGit客户端导出.
3.3 数据收集过程
3.3.1 需收集的数据
为了回答第3.1节中定义的RQs,表1中列出了我们需要收集的数据项,也列出了每个数据项对应的目标RQ(s).
3.3.2 数据收集方法
图1显示了SAR的收集过程.对于选定的项目我们执行以下步骤:
1)下载代码存储库——从GitHub下载项目代码库.
2)导出提交记录——使用TortoiseGit客户端导出项目的提交记录.
3)识别候选SAR——根据SAR的定义,识别SAR的一种方法是在选定的项目提交信息中搜索“refactor ”的关键字.输出则是一组候选SAR版本信息.
4)手动检查候选SAR——检查每个候选SAR提交信息,以排除错误情况.例如:开发人员可能会写“going to refactor”、“not refactor”等,在这种情况下,是没有重构发生的.因此,我们需要手动检查每个候选SAR版本,排除错误识别.
5)记录SAR的提交——记录SAR相关的提交信息,包含修订号和开发者等.
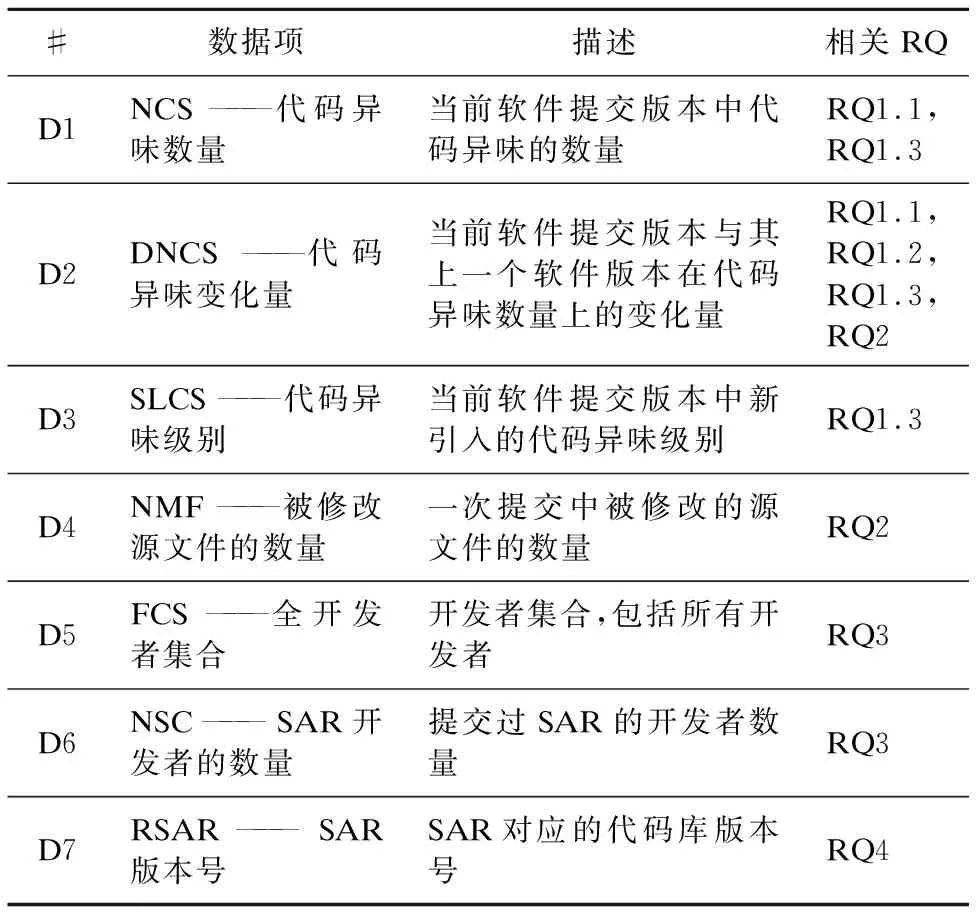
表1 需收集的数据项
3.3.3 非SAR版本收集
为了回答RQ1.2,对于所选定的项目,我们还需要收集不包含SAR的普通提交版本用来做对比实验.我们称之为非SAR.在选取的过程中,我们采用了随机选择的方式,并要求保证非SAR集合的版本数量与SAR集合的版本数量保持一致,以排除数量因素的干扰.
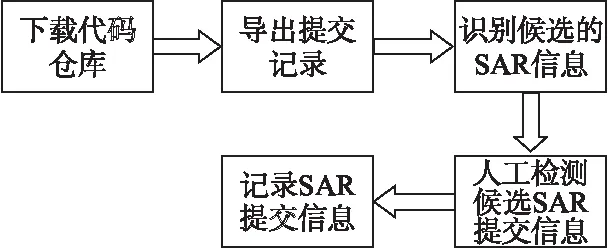
图1 SAR收集过程
3.3.4 代码异味收集
我们使用静态检测的方法来识别代码异味.作为广为使用的检测方法,静态代码嗅探方法通过多种方式测量并分析代码是否违反了特定的质量规则(例如:coupling metrics).许多工具都采用了静态嗅探的检测方法,例如广泛使用的代码异味检测工具PMD.
在PMD检测工具中有33个规则集和237条检测规则(如:圈复杂度和松耦合).在本文案例研究中,在下载了所选项目的代码存储库后,将会对每个SAR对应的代码库版本导出.随后,我们将分析每个SAR对应版本的源文件,以及它上一个版本的源文件,以获得两个代码库版本的源文件之间代码异味分析报告的差异.图2显示了代码异味收集的过程.对于每一个SAR版本与非SAR版本,我们都执行以下步骤:
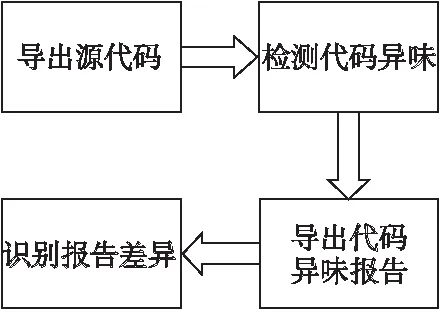
图2 Code smell的收集过程
1)导出源代码所需版本——导出目标版本(V1),以及它的前一次提交版本(V2).
2)检测代码异味——使用PMD插件来检测V1和V2中的代码异味.PMD插件生成代码异味检测报告.
3)导出代码异味报告——导出上一步生成的代码异味检测报告.
4)识别代码异味报告中的差异——比较V1和V2的代码异味报告,确定报告之间代码异味的差异.
3.3.5 数据分析方法
为了回答第3.1节提出的研究问题,我们需要收集SAR代码异味数据.根据表1规定的收集的数据项.我们将针对不同的RQ,采取不同的数据分析方法.本文中所有的数据搜集过程,我们都编写了实验程序*https://github.com/vicotorz/PMDlet.
对于RQ1.1、RQ1.2和RQ3,只需使用描述性统计.具体地,针对RQ1.1,我们将收集SAR项目中的代码异味数量(NCS)和代码异味变化量(DNCS),重点对代码异味的增减情况进行统计,并计算代码异味增加、不增加、减少代码的项目版本比例,结合代码异味数量,来确定SAR项目中代码异味的具体情况.RQ1.2中我们将引入同等数量的非SAR版本与SAR版本进行参照对比实验,利用代码异味变化量(DNCS)验证代码异味在自承认与非自承认重构版本中的差别.RQ1.3中,我们将对SAR版本中检测到的代码异味级别进行数据统计,并分析各种代码异味级别的占比,用以评估SAR版本中的代码异味级别分布,以及代码质量情况.
对于RQ2,我们将对代码异味变化量(DNCS)和修改的源代码数量(NMF)的相关系数.即利用Pearson计算了两个变量之间的相关系数[17],用以确定两者的关联关系.
为了回答RQ3,将会统计所有参与开发项目的开发者作者信息,以及有关SAR作者信息(包括用户名,邮件,提交次数,SAR提交次数).计算SAR开发者所占的数量SAR作者在软件开发过程中自承认重构对应的比例.
对于RQ4,利用已收集的SAR信息,进行位置标注,用Matlab程序对SAR分布进了图形描述.以确认和总观SAR在项目周期中的分布特点.表2概括总结了分析的方法.
需要指出的是,在实验过程中,PMD默认规则集中有许多并不适合我们案例分析的代码异味.例如,“LocalVariableCouldBeFinal”表示将局部变量转换为final的代码异味的建议,这种代码异味经常发生且粒度太小.因此我们从PMD所能检测的代码异味集合中选择一些关键代码异味.在选取过程中,我们由两组人员分析了PMD提供的代码异味规则描述,综合选择了规则语句中包含单词“maintainability”、“readability”和与可维护性相关的代码异味.如表3中展示了一些被PMD检测到的代码异味.

表2 数据分析方法
为了测试SAR对代码质量的影响,需要与非SAR版本进行比较.但非SAR的数量远远超过SAR的版本数量,由于数目庞大,测试所有非SAR不仅会很耗时,同时也引入了数量不确定性因素,因此我们随机选择了与SAR版本数量相等的非SAR版本.

表3 PMD规则
4 研究结果
4.1 所选项目
本文中,我们选择了一个大型的开源软件项目用作为案例分析,即Fastjson*https://github.com/alibaba/fastjson.Fastjson是一个java库,用来将java对象转换成json格式,也可以将json字符串转换为等效的java对象.Fastjson作为一种流行的开源项目,广泛应用于许多软件项目中.表4列出了Fastjson项目信息.
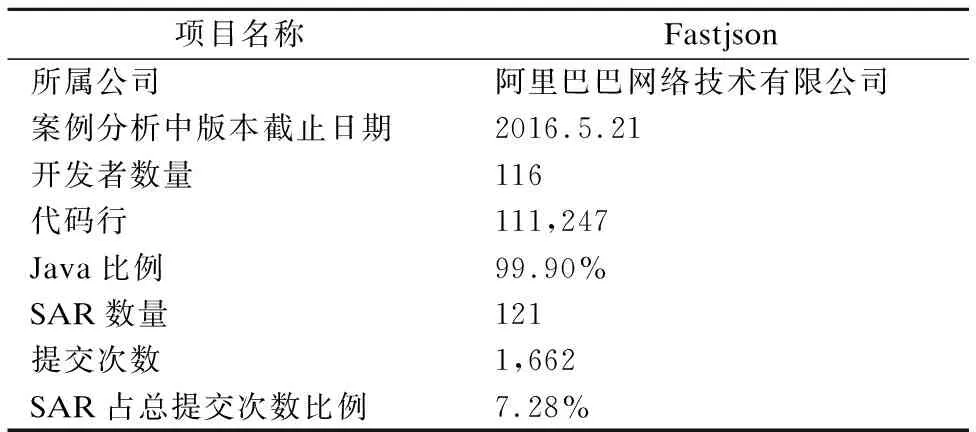
表4 项目统计信息
4.2 结果
4.2.1 代码质量的影响(RQ1)
RQ1.1:表5列出了在SAR版本中不同的代码异味状况.如表5所示,70.25%(85/121)的SAR版本没有增加代码异味.

表5 DNCS信息
我们在表6中列出了最容易减少的前5类代码异味.在所有类型的代码异味中,DataflowAnomalyAnalysis是最常被减少的.并且这种类型的代码异味,在SAR版本中出现最多.接下来,我们对表6中所列出的5种代码异味进行简要介绍:
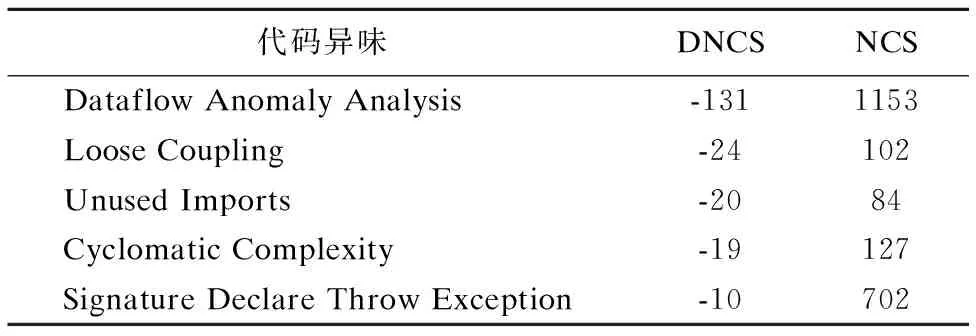
表6 变化最大的前5名代码异味
·数据流异常分析(Dataflow Anomaly Analysis):1)已定义的变量为初始化;2)变量定义后仅在某个分支中使用;3)已赋值的变量在未使用的情况下重新赋值.
·松耦合(Loose Coupling):使用实现类型作为对象引用,限制了适用范围以及灵活性.
·未使用的引入(Unused Imports):未使用的imports包.
·秩复杂性(Cyclomatic Complexity):圈复杂度,表现在独立可行的路劲条数,数值越大表示判断逻辑复杂.
·具体声明异常(Signature Declare Throws Exception):不确定方法中抛出的具体异常.
RQ1.2:在本文的案例研究中,有121个SAR版本与121个随机的非SAR版本.如表7所示,在非SAR版本中,代码异味增加(DNCS>0),保持不变(DNCS=0),减少(DNCS<0)的情况分别为76、29和16.而在SAR版本中,代码异味的数量增加(DNCS>0),保持不变(DNCS=0),减少(DNCS<0),分别为36、39和46.37.19%(45/121)的非SAR版本中没有增加代码的异味,而70.25%(85/121)的SAR版本中代码异味没有增加.这意味着,与非SAR版本相比,SAR更倾向于不增加Fastjson中的代码异味.
RQ1.3:PMD可以检测237种代码异味.其中定义了每个代码异味的严重级别(使用1-5来表示),分别为:Error High、Error、Warning High、Warning和Information.表7展示了PMD标识的代码异味的默认的严重级别的分布.#(PMD code smell type)表示PMD中定义的相应严重级别的代码异味数量.DNCS定义为SAR中代码异味数量的增量.#(PMD code smell)表示PMD在项目中实际检测到的代码异味严重级别的数量.#(Detected code smell type)是实际检测到的代码异味类型的数量.类型比例表示PMD可以检测到的代码异味类型占所有代码异味类型的比例.
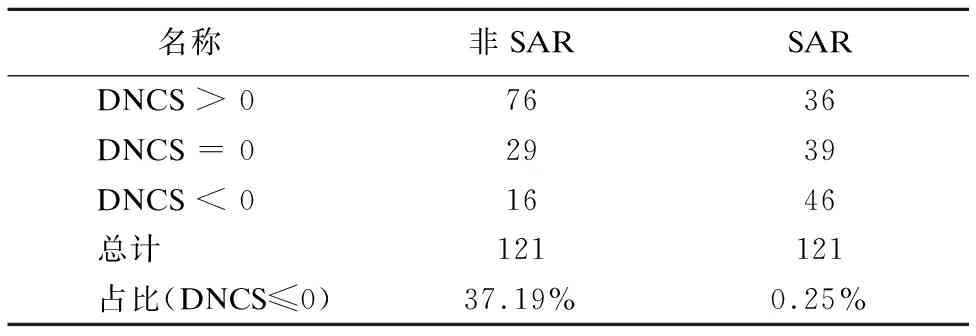
表7 代码异味的变化量
如表8所示,在Fastjson的所有SAR版本中,存在着131个严重级别为“Information”的代码异味,引入了8个严重级别为“Error”的代码异味;减少了20个严重级别为 “Warning”、327 个严重级别为“Warning High”及17个严重级别为“Error High”的代码异味.

表8 代码异味严重级别分布
4.2.2 被修改的源文件数量与引进代码异味数量的关系(RQ2)
表9显示了SAR和非SAR中被修改的源文件数量(NMF)的平均值.总体来讲,平均每个SAR中被修改的源文件数量(41)比非SAR(66)要少.

表9 NMF 分布
我们利用Pearson相关性研究了NMF与新引入的代码异味(DNCS>0)之间的关系.如表10所示,被修改的源文件的数量与新引入代码异味数量的显著性水平为α= 0.01,呈显著相关关系.

表10 相关性结果
4.2.3 有关SAR开发者(RQ3)
并不是所有开发者在软件开发过程中都具有自承认重构行为.在分析了Fastjson的提交信息之后,我们发现特定的开发者具有SAR行为倾向.表11显示了在项目中执行SAR的开发者信息.FSC指参与项目的总开发人员数量、SAR开发者代表自承认重构的提交总人数.

表11 开发者信息
图3展示了每个SAR开发者所产生的SAR的数量.其中有大量使用了不同网络身份的开发者.我们通过身份语义、邮箱等关键信息分析并合并了不同的网络身份,最后产生了3个SAR开发者的合并集合.结果显示,提交人3在Fastjson项目中执行了大部分(108/121)的自承认重构.
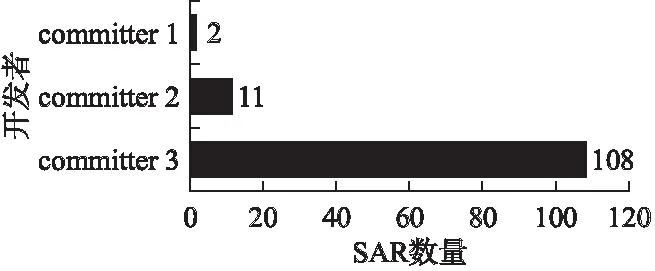
图3 开发者SAR数量
此外,我们计算了SAR开发者自承认件重构次数占其自身提交总次数的比例,结果如表12所示,每个SAR开发者的仅有不超过20%的SAR行为.

表12 SAR开发者的SAR比例
4.2.4 自承认重构分布(RQ4)
图4展示了SAR对应的代码库版本(RSAR)的分布情况.每条线代表一次SAR的出现.如图4所示,深色粗线条的部分具有较高的SAR密度.
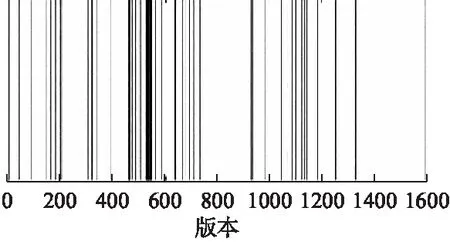
图4 Fastjson的SAR分布
5 讨 论
5.1 研究结果分析
RQ1:如表5和表7所示,并非所有的SAR都能提高代码的质量.在SAR版本中,倾向于不增加项目的代码异味,也就意味着总体上SAR中的代码异味会减少,代码质量会得到改善.这与开发者提高代码的可维护性的重构意图相吻合.事实上,29.75%的SAR(总共121个SAR中的36个)引入了新的代码异味.从SAR和非SAR两个数据集的比较结果可以看出,有37.19%的非SAR版本和70.25%的SAR版本没有增加代码异味,这意味着SAR引入的代码异味比非SAR引入的要少.DataflowAnomalyAnalysis是发生和变化最频繁的代码异味.在使用PMD进行案例分析的过程中,前两类代码异味数量偏大可能是由于它们对应的PMD代码异味检测规则粒度太小导致的.
如表8所示,实际检测的代码异味严重级别包括了PMD中定义的所有严重级别类型.42.86%的代码有“Error High”严重级别.在所有检测到的代码异味中,严重级别为“Error High”的代码异味数量最大,这意味着被研究项目的代码质量一般.导致这种结果的原因可能是由于预定义代码异味类型的数量不平衡,规定的大部分代码异味类型严重级别为“Warning High”(见表7)所致.另外,出现的“Error”高严重级别的代码异味是一种代码质量下滑的信号,应该特别注意.
RQ2:在SAR中,被修改的源文件数量与新引入的代码异味数量之间存在显著正相关.我们通读了所有的SAR版本提交信息,发现Git的重命名、添加和删除操作将导致了代码异味的增多.因此,Git中的特定操作与代码异味之间的关系可以进行更深入的研究.
RQ3:如表12所示,我们可以看到只有6.25%的开发者在提交记录中自承认软件重构.在SAR开发者的提交记录中,SAR的提交次数所占的比例也是较小的.
RQ4:自承认重构行为大部分发生在了Fastjson的开发初期与中期,这表示在项目开发生命周期中的不成熟阶段,即频繁进行质量改进活动.
5.2 启发性信息
代码异味的增多意味着项目质量的下降,在对Fastjson的研究过程中,SAR通常是代码质量改进的积极信号.然而一些SAR版本中会存在代码质量下降的情况,原因可能是SAR版本中没有发生真正的重构.
在本文的案例研究中,被修改的源文件数量与新引入的代码异味数量存在显著的正相关关系,这意味着开发人员对源文件增加,删除,重命名,修改等操作对代码异味的变化有着直接的影响.另外,值得指出的是,开发者在开发过程中需要注意代码规范.
SAR表明了开发人员对代码质量改进的认识,因为开发人员明确地宣称了重构,在某种程度上表明了他们进行代码结构质量改进的意愿.SAR的作用除了标记重构信息,记录版本更新以外,在多人协同开发过程中,也为接下来他人接替代码项目起到了提示作用.
值得一提的是,在本文的研究过程中,发现了很多一些残缺,意义模糊的提交信息,因此,在协同开发过程中,规范格式的提交信息(包括修改说明)是有必要值得实践的.
5.3 有效性威胁
本案例分析的结果有效性存在着以下两点潜在威胁:首先,PMD工具中可能潜在着代码异味检测的不准确.考虑到PMD被广泛应用于工业,我们认为PMD是可靠的,因此这种威胁是有限的.其次,本案例研究中只选择了一个大型的Java开源项目,因此我们不能断言,本案例研究中关于SAR的结论适用于闭源软件系统和用其它编程语言编写的软件项目.
6 总 结
以往研究中很少有针对SAR现象的研究.本文中我们从多个角度探讨了自承认重构(SAR)现象,经过对Fastjson项目进行案例分析,得到如下结果:1)虽然小部分的SAR引入了新的代码异味,但总体上SAR往往是代码质量提高的信号;2)DataflowAnomalyAnalysis是Fastjson项目中SAR中最常发生和减少的代码异味类型;3)平均来讲,SAR引入的代码异味数量比非SAR引入的代码异味数量少;4)SAR版本中,大多数代码异味的严重级别为 “Warning High”,而严重级别为“Error”的代码异味只占小部分;5)在SAR中,被修改的源文件数量与新引入的代码异味数量呈正相关关系;6)进行过SAR的开发者占所有开发者的比例较小;7)在Fastjson项目开发生命周期的初期和中期,SAR的发生频率较高.
正如我们看到的,自承认重构总体上提高了代码质量.在本文有关SAR的案例研究中,有很多可以切入并深入研究细节,未来我们对SAR的研究将侧重于以下几个方面:
·SAR与自承认技术债务的关系.自承认技术债务往往是开发者特意为之,需要有计划地通过重构来进行偿还.自承认技术债务与SAR的关系,自承认技术债务和SAR是如何来共同影响软件代码质量和软件的可维护性的,都值得下一步深入研究.
·更多案例的SAR分析.SAR在不同的项目上,表现可能会有所不同.我们将对不同应用领域中的更多的软件项目上进行本文案例分析的重复性研究,探索是否得到关于SAR的共性结论.
·SAR密度.SAR的分布提供了有价值的重构提交信息,同时,SAR密度可以更好地了解代码历史和演化,评估代码状态.
·SAR动机.不同的SAR具有不同的动机,研究背后的深层原因会让我们对SAR有更深的认识与理解.
·细化SAR的划分.在本文中,我们利用关键字搜索的方式简单地对SAR进行了挑选,然而事实上,自承认重构的表现复杂,比如关键字Move Method等,原则上也应该划分为SAR.我们可以利用数据挖掘的方式深入进行SAR的识别工作.
猜你喜欢
宠物世界·猫迷(2017年7期)2018-01-25
新高考·高二数学(2016年7期)2017-01-23
经济(2016年29期)2016-12-27
纺织科技进展(2016年3期)2016-11-29
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
CHIP新电脑(2016年3期)2016-03-10
股市动态分析(2015年16期)2015-09-10
汽车维修与保养(2015年8期)2015-04-17
家庭生活指南(2009年7期)2010-04-07
