
使用递归神经网络的目标依赖产品评价分析
2018-11-17 01:26蒋一翔徐元根王永恒
计算机工程与设计 2018年11期
蒋一翔,徐元根,王永恒
(1.浙江中烟工业有限责任公司宁波卷烟厂,浙江 宁波 315000;2.湖南大学 信息科学与工程学院,湖南 长沙 410082)
0 引 言
收集和分析用户对产品的评价对企业具有重要价值。微博,如Twitter和新浪微博是Web 2.0时代最流行的应用程序之一,它允许用户以发布短消息的形式与他人分享他们的观点。自从微博出现以来,已经吸引了很多人用它来记录自己的生活,讨论热门话题,表达和分享意见。以微博为代表的公开社交数据已成为挖掘人们的意见和情感的重要资源[1]。微博能提供有效的数据,以支持客户满意度调查,公众情感检测,社会学研究等。情感分析技术可用于根据作者表达的情感自动分类文本。最近一个有用的应用是通过微博流的情感分析来管理潜在客户。通过监控在线微博流和分析客户对产品的看法,企业可以发现其产品的缺陷并找到潜在客户。与传统的文本数据相比,微博有一些新的特征,如限定的内容大小,通常包含拼写和语法错误,使用各种表情和口语表达式[2]等。这些特征使得确定微博的情感极性更加困难。本文使用微博数据流来支持产品评价的分析。
微博帖子通常包含多种评论内容,其中一些与给定的目标无关。然而,主流的情感分析方法基本不考虑评论内容与目标的关联,所有出现在帖子中的情感表达,无论是否正确,将被视为与目标相关,这将导致情感分析错误[3]。近期提出的使用递归神经网络(RNN)的新情感分析方法[4,5]表现出良好的效果。使用深度学习的RNN被证明是一种有前景的情感分析方向。然而,这些方法具有一些局限性,即需要大量的标记样本来训练模型。输入树中的所有节点都需要用5个情感级别中的一个手动标记,这种代价是非常昂贵的。另一个局限性是RNN模型是目标无关的,它不能直接用于目标相关的情感分析。本文提出一种基于RNN的目标依赖情感分析方法TD-RNN(target-dependent RNN)。
TD-RNN扩展了原始RNN模型来更好地支持目标依赖的情感分析。使用基于聚类的数据划分方法在标记样本有限的情况下获得更高的精度。另外提出了一种树修剪方法,用于在构造RNN之前从语法树中去除不相关的部分。
1 相关研究
当前情感分析方法主要包括基于情感词典的方法和基于机器学习的方法。基于情感词典的方法使用情感词的支配极性来确定文本的极性。Fiaidhi等使用3个评分方案对Twitter数据进行评分,包括从负面词汇中减去正面词汇,TF-IDF加权方案和LDA(latent Dirichlet allocation)[6]。Cruz等通过关联分析的方法构建面向特定领域的情感词典来支持情感分析[7]。然而,微博的情感分析通常效果不佳,因为微博中包含许多种类特殊的情感词语和在一般意见词典中不存在的表情。基于机器学习的方法将情感分类视为文本分类的一种特殊情况。这些方法需要大量的标记数据来训练情感分类器。Al-Qudah等采用模糊集理论提取文本特征进行阿拉伯语的情感分析[8]。Lim等利用推特标签和表情作为情感标签,避免了手动注释[9]。他们的方法允许识别和分类多种情感类型的推文。近期Socher等提出基于RNN的情感分析方法[5]。他们的RNN模型需要使用包含大量细粒度情感标签的情感树库进行训练。他们的模型在多个指标上优于所有以前的方法。
目标依赖方法根据给定目标表达的情感对帖子进行分类。Joshi等采用模糊本体和模糊逻辑来支持情感词和评价目标之间的对应[10]。Vo等在进行面向目标的情感分析时,没有采用句法分析,而是基于统计的方法自动获取丰富的特征,通过分析情感的上下文来对应情感的目标[11]。Dong等提出了一种适应性递归神经网络模型(AdaRNN)用于目标相关的推特情感分类[12]。他们使用依赖树来构造RNN,并通过使用根据语言标签和组合向量的不同组合矩阵来扩展RNN模型。与他们的工作相比,本文将RNN模型扩展为目标依赖性,而AdaRNN的组成矩阵不是目标依赖性的。本文还使用基于聚类的数据分区,在标记样本有限的情况下获得高精度的分析结果。
2 基于递归神经网络的情感分析
在RNN模型[4,5,13]中,短语和词表示为D维向量。基于二叉树表示向量组合,并且以递归方式使用不同类型的组合函数递归地计算父向量。
如图1所示,当短语“不是很好”被解析为二叉树时,叶节点中的每个词用向量表示。通过“很”和“好”的组合获得“很好”的表示,并且通过“不是”和“很好”的组合递归地获得三元组“不是很好”的表示。该模型使用以下公式来计算父向量
(1)
其中,vP是父向量,vl和vr是左和右子向量,g是组合函数,f=tanh是标准的元素性非线性方程,W∈D×2D是组合矩阵,b是偏差向量。每个父向量vp,i被给予等式(2)的相同softmax分类器以计算其标签概率
svP,i=softmax(Wsvp,i)
(2)
其中,Ws∈5×D是情感分类矩阵(情感被分为5个级别:非常消极、消极、中性、积极和非常积极)。有人把这个基本模型扩展为每个词和较长的短语在语法树中分别用向量和矩阵表示的矩阵向量RNN(MV-RNN)[13],以及对所有节点使用相同的基于张量的合成函数的递归神经网络(RNTN)[5]。
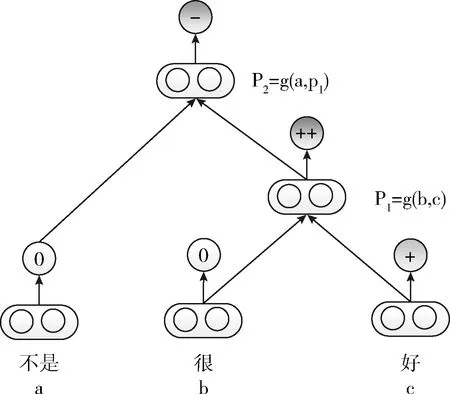
图1 RNN模型结构
3 TD-RNN方法
3.1 方法概述
本文的TD-RNN的整体架构如图2所示。历史微博数据根据语法树结构相似性离线聚类。从每个簇中随机选择一定数量的样本并手动标记,然后将标记的样品用于训练目标依赖性的RNN模型。在线微博流中的微博被解析生成语法树,树中的不相关部分在领域本体和语法库的帮助下被分析和修剪,最终的二叉树被输入到目标依赖的RNN中以预测语义标签。同时使用演进的聚类算法对在线微博流进行聚类。如果找到新的簇,并且簇的大小超过阈值,可以考虑标记该簇的样本并重新训练模型。
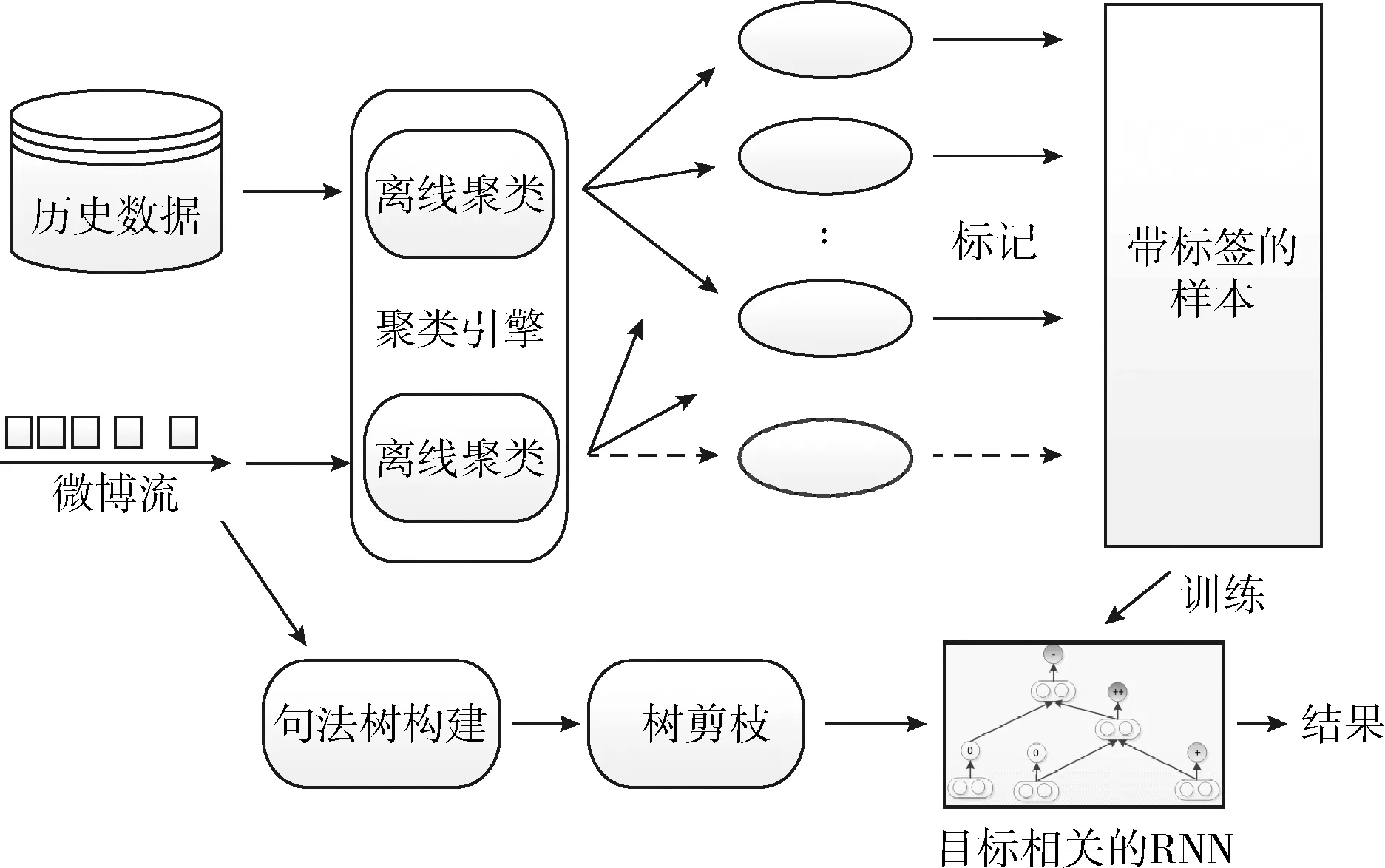
图2 TD-RNN总体框架
3.2 基于聚类的数据分区
标记样本是一项相当昂贵的任务,因为树中的所有节点都必须手动标记。为了能在有限标记样本的情况下使RNN模型获得更好的准确度,训练样本应均匀分布在数据空间上。由于TD-RNN模型是基于语法树构造的并且是目标依赖的,我们使用语法树结构和一些关键词作为特征来聚类微博。手工设置可以影响各种目标的情感分析的关键字,例如, “比”,“然而”,“但是”等。我们使用减法聚类[14]作为离线聚类算法来聚类历史数据。数据点本身视为候选焦点(聚类中心)。每个数据的潜在价值可用以下公式计算
(3)
其中,pi(zi)是数据点zi的潜在值,N是数据点的数目,ra是正常数。由上可知数据点的潜在值是其到所有其它数据点的距离的函数。选择具有最高潜在值的点作为第一个簇中心。所有数据点的潜在值逐渐减少,减少值取决于它们到聚类中心的距离。下一个簇中心是具有剩余最大潜在值的数据点,以此类推。为了聚类在线微博流,使用基于减法聚类的演进聚类算法[15,16]。将演进聚类中的潜在值定义为
(4)
其中:pk(zk)是在时间k计算的数据点zk的潜在价值。我们不从零开始执行eClustering,而是使用离线减法聚类的结果作为先验知识。
离线和在线算法的关键问题是计算两个数据点之间的距离。每个数据点表示为具有由诸如“NP”,“VP”等符号标记的语法树的节点,关键字也包括在树节点中。我们使用以下等式计算两个语法树之间的相似性
(5)
其中,T[]是两个语法树T1和T2之间的公共子树的集合,size(T[i])是子树T[i]的节点数,函数ht(x)获得原始语法树中节点x的高度,α∈(0,1)是权重因子,函数sk(x)计算公共节点x上来自T1和T2的关键字之间的相似性。共式(5)使得相似性值与共同子树的数量、共同子树的大小、共同子树的节点的高度以及共同子树的关键词相似度成比例。我们使用Droschinsky等提出的方法[17]得到所有共同的子树。小尺寸(小于阈值)的子树将被忽略。两个语法树T1和T2之间的距离被定义为1/sim(T1,T2)。
3.3 语法树剪枝
语法树通常包括给分类带来较高成本的噪声。面向目标依赖的情感分析,我们提出了一种剪枝方法,从语法树中剪除与目标无关的评估表达式。为了修剪语法树的无关部分,我们需要检测由情感表达式及其目标组成的有效评估表达式。情感表达式与其目标之间的语法路径指的是语法结构中连接这两个节点的语法结构。在图3中,情感表达“负评论”与其目标“京东”之间的语法路径为NN→NP→IP→VP→VP→NP→NN。通过对大规模语料库的语法路径进行计数,我们可以发现,有效路径比无效路径更频繁地出现。一般来说,目标是我们可以通过POS标记检测的名词,情感表达式可以通过意见词典找到。在从语法树提取句法路径之后,我们需要进行泛化,使具有小差分的路径聚合到一个路径。该步骤聚集路径中相同的相邻元素,例如,上面所示的路径可以被概括为NN→NP→IP→VP→NP→NN。我们选择出现最频繁的路径来构建语法路径库。

图3 语法树和句法路径的一个例子
树修剪算法在算法1中给出。在第(2)-(3)行为通过POS标记和情感词典获得名词和情感表达集。在第(4)-(5)行中,在集合N中但和目标无关的对象(通过手工建立相关对象列表处理)被置于集合IN中,这些是要修剪的对象。与目标具有竞争关系的对象也被置入IN。在第(6)-(12)行中,得到所有的情感表达式—目标对,并与句法路径库匹配。如果路径不匹配或者匹配路径的频率小于阈值,则该路径被视为无效路径。我们找到情感表达式SE_p及其目标t的共同父节点comm_parent,然后修剪包含SE_p或t的comm_parent的子树。然后,如果没有任何以comm_parent为根的子树,则从语法树中剪除comm_parent。
算法1: 从语法树中剪除不相关的部分
输入: t: 语法树, Ta: 目标, L: 路径库
输出: 修剪后的树
方法:
(1)IN ← φ
(2)N ← get_noun_set(t)
(3)SE ← get_sentiment_expression(t)
(4)IN +← filter_noun(N)
(5)IN +← filter_compititive(N,Ta)
(6)for each n in IN
(7)| SE_p←get_target_SE(t,n,SE,Ta,L)
(8)| if SE_p≠φ then
(9)|| comm_parent←find_comm_parent(t,n,SE_p)
(10)|| t←prune_subtree(t,comm_parent)
(11)|end if
(12)end for
(13)return t
树剪枝的一个示例如图3所示。我们假设“华为”是目标。可以发现情感表达集是{不错,差评},目标集是{华为,京东}。“京东”是一个与目标无关的对象,应该修剪。通过匹配语法路径库,我们发现“京东”和“差评”之间的路径有效,但“京东”和“不坏”之间的路径无效。我们根据算法1,从语法树中删除相应的结构,并在图3中用虚线标记。
3.4 目标依赖的递归神经网络
原始RNN模型使用一个全局矩阵W来组合向量。但在目标依赖情感分析中,组合矩阵可能与目标相关。对于图4所示的示例,当目标不同时,我们得到不同的情感标签。基本思想是根据不同的目标情境使用不同的合成矩阵。

图4 不同目标的情感标签
为了支持目标依赖的组合矩阵,我们将式(1)扩展为
(6)
Wt∈D×2D×4为组合矩阵,Ta是指示目标位置的1×4向量。Ta中只有一个元素可以是1。将元素1-4设置为1分别表示没有目标、目标在左子树中、目标在右子树中、两个子树中都有。图5对式(6)进行了进一步说明。

图5 目标依赖的组合
为了训练模型,令θ={Wt,b}是模型参数集合(可以另外学习softmax参数Ws)。代价函数定义为
(7)
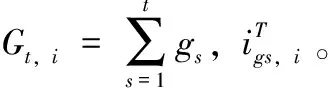
θt,i=θt-1,i-α[diag(Gt,i)]-1/2gt,i
(8)
其中,α是学习率。由于使用Gt,i的对角线,我们只需要存储很少的值,并且更新速度变得更快。我们的方法也可以用于扩展MV-RNN和RNTN模型。
4 实验研究
我们首先构建语法路径库。利用中科院NLPIR中文分词系统进行分词和POS标记,并使用斯坦福语法分析器进行语法树构建。我们使用的意见词典是台湾大学的NTUSD词典,其中包含2810个正面意见词和8276个负面意见词。此外,我们将50个常用的正面互联网词和53个负面词纳入词典。构建语法路径库的语料库是从腾讯微博获取的36 042个微博帖子获取的,其中涉及汽车,智能手机,购物网站等众多领域。5个最频繁出现的路径及其发生频率见表1。

表1 语法路径库中5个最常出现的路径
我们选择了两个关键字作为目标,即“华为”和“唯品会”,并从腾讯微博中抓取包含目标的帖子。每个目标的帖子数为30 000个。我们为每个目标随机选择3500个帖子,并手动将每个帖子分类为目标的正面或负面。“华为”的语料库包含1643个正面帖和1379个负面帖,目标为“唯品会”的语料库包含1412个正面帖和1583个负面帖。我们选择2000个样本作为训练集,300个样本作为开发集,其余作为测试集。
采用7种评估方法如下:
(1)SVM卷积:具有卷积核和语法树特征的SVM分
类器。
(2)SVM复合:SVM分类器使用一元文法和语法树作为特征,复合内核如下
K=(1-α)·Tree_kernel+α·Vector_kernel
(9)
其中,α∈(0,1)是权重因子。我们只给α的最好结果。
(3)RNN:原始RNN方法。
(4)AdaRNN:Dong等提出的自适应递归神经网络分类器[12]。我们实现了在他们的论文中“AdaRNN-comb”方法。由于缺少关于实现AdaRNN的详细信息,我们基于我们的理解实现该方法。
(5)TD-RNN-basic:无树修剪和基于簇的样本选择的TD-RNN。
(6)TD-RNN-prune:具有树修剪但没有基于簇的样本选择的TD-RNN。
(7)TD-RNN:具有树修剪和基于簇的样本选择的TD-RNN。
使用这种方法,我们对总样本进行聚类,分别得到“华为”的5个簇和“唯品会”的8个簇。然后对于每个目标从簇中均匀地选择2000个样本。
评价结果如表2所示。根据结果可以得出以下结论。
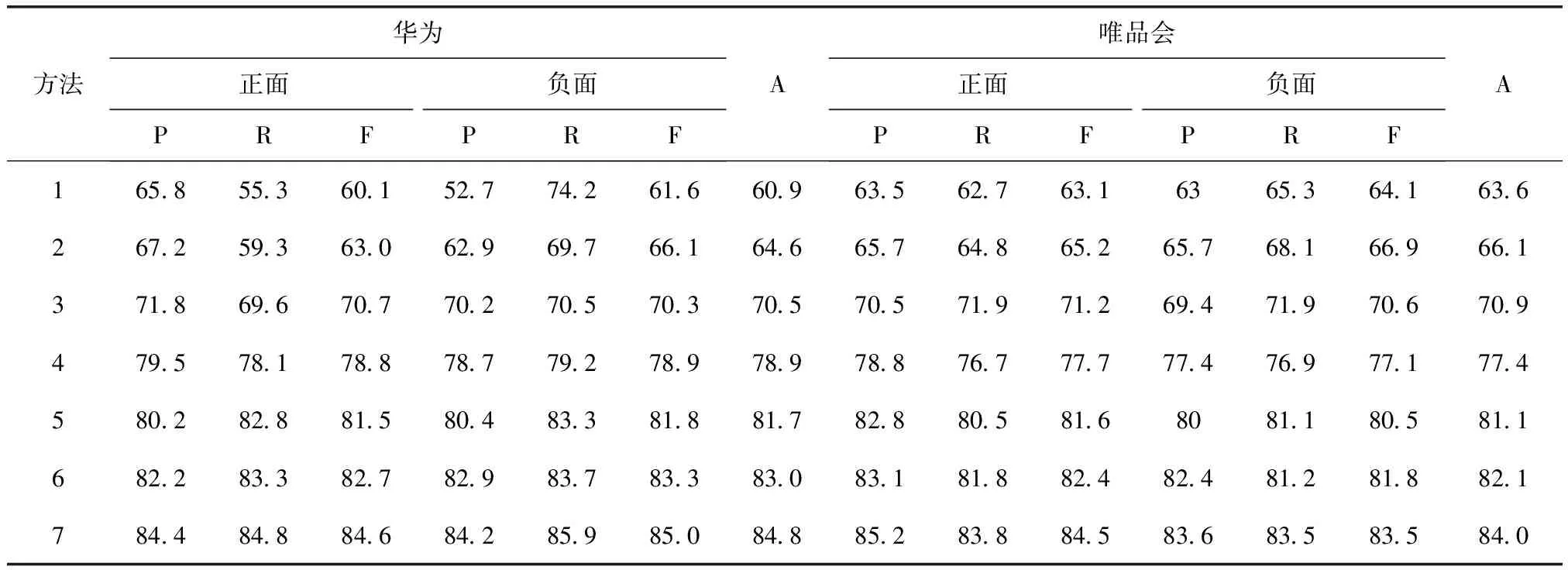
表2 7种方法的评价结果 A:精确度,P:精度,R:召回率,F:F-score
(1)我们的方法在正面和负面微博集中都达到最佳效果。我们的方法的准确度,精度,召回率和F-score都是所有方法中最高的。这个结果表明,TD-RNN模型,树修剪方法和基于聚类的样本选择方法对于微博的目标相关情感分析工作良好。
(2)传统的基于SVM的分类器在用于目标依赖情感分析时效果较差。基于复合内核的方法表现出更好的效果,因为它可以捕获结构和特征。
(3)虽然原始的RNN分类器在目标无关的情感分析方面有更优的效果,但无法得到可接受的目标依赖情感分析的效果。原因是它使用全局合成矩阵时不考虑目标。TD-RNN模型使用了可以提高准确度的目标依赖组合矩阵。
(4)AdaRNN是基于RNN的目标依赖情感分类器。因为它根据语境和它们之间的语法关系自适应地传播词的情感到目标,所以其准确性优于SVM和原始RNN。
(5)本文将RNN模型扩展为目标依赖,而AdaRNN的组合矩阵不是目标依赖的。所以TD-RNN的基本方法性能优于AdaRNN。
(6)树修剪方法提高了TD-RNN的效果,因为它可以删除一些不相关的部分,这使得接下来的工作更容易执行。
(7)基于聚类的样本选择方法可以提高TD-RNN的性能,因为它使训练样本均匀分布在数据空间上。
5 结束语
微博是情感分析的重要资源,但是目标依赖的情感分析有较大难度。RNN是一个发展前景良好的情感分析模型,它能获得高精度的目标无关的情感分析。本文对RNN方法进行了扩展,包括TD-RNN模型,基于聚类的训练样本选择和树修剪。实验结果表明,该方法适用于微博流的目标依赖情感分析。
目前,我们对RNN模型只是做了简单的扩展。我们认为目标和情感表达之间的深层关系仍然没有很好地揭示出来。今后我们将应用新的方法来进一步改进TD-RNN模型。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
时代英语·高一(2019年1期)2019-03-13
知识经济·中国直销(2018年8期)2018-08-23
新高考(英语进阶)(2017年10期)2017-12-23
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
