
基于自适应差分遗传算法的BP神经网络优化
2018-11-19 10:58张轩雄
软件导刊 2018年11期
蒋 璐,张轩雄
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
20世纪80年代,作为一种模仿脑神经功能建立的信息处理系统,人工神经网络迅速发展起来,其反映了生物神经系统处理外界事物的基本过程,因此被广泛应用于各个领域。其中使用最广泛的是基于误差反向传播算法的多层前向BP神经网络[1],而它在具有高度自学习和泛化能力等优点的同时,也存在不可避免的缺陷:无法同时满足精度和训练时间要求,易陷于局部最优解等。
遗传算法作为一种全局搜索最优解的算法,常用于优化BP神经网络,但其常表现出收敛慢等缺陷。自Srinivas等[2]提出一种自适应遗传算法以来,近几年研究人员提出将改进的遗传算法与蚁群算法或粒子群优化等智能算法相结合,对神经网络进行优化[3-4],但优化算法参数过多,而不同的参数设置对最终结果影响较大,增加了方案的不确定性。文献[5]提出一种基于向量元启发式的差分优化算法(Differential Evolution,DE),通过模拟生物群体内个体间的合作与竞争以产生启发式群体智能指导搜索,相比遗传算法,其向量化突变方式被看作是一种有更高效率的方法。
本文在遗传算法和DE算法利用后代适应度值更新群体等作用的基础上[6],提出结合差分进化与遗传算法优化BP神经网络,利用遗传算法基于混沌序列的交叉算子与差分进化的自适应变异等操作,以充分体现DE-GA算法的全局搜索能力和 BP神经网络的学习逼近、局部搜索能力[7-8]。实验表明方案收敛速度快、鲁棒性强、运行结果可靠,优化后的BP网络预测准确率保持在97%以上,可广泛应用于实践生活中。
1 BP神经网络
BP神经网络采用误差函数梯度下降法进行学习,体现在多层网络中两种信号的传播:正向输入信号和反向误差信号。其中输出值与期望值的差值反向逐层传递,促使网络不断修正权值以达到精度要求。当隐含层选择合适的神经元数时,单隐层的3层BP神经网络可以任意精度逼近非线性函数[9-10],故本文选用3层BP神经网络。
2 差分—遗传算法优化BP神经网络
实际应用中,BP神经网络不同权值和阈值极大地影响到网络训练,导致易陷于局部极值,所涉及神经网络的泛化能力不能保证。故本文在传统遗传算法基础上引入差分思想,通过调整种群规模、交叉算子、差分变异算子以优化网络权阈值[11-12]。
2.1 染色体编码与适应度函数
采用二进制编码,BP神经网络个体的维数将急剧增加,计算量也随之增加[13]。故将BP神经网络的权、阈值按照以下顺序级联编码为实数串:输入层与隐含层间的连接权值、隐含层与输出层间的连接权值、隐含层阈值、输出层阈值。
为方便计算,BP网络选择误差绝对值计算染色体的适应度值,如式(1)所示。
(1)
其中,Yi为BP神经网络第i个节点的期望输出,yi为实际输出。
2.2 种群规模适应性调节策略
在差分进化初始阶段,种群需要较强的多样性对解空间广泛探索,而后期需要对最好的个体改善。因此,需根据适应度值的在线改善情况,融合寿命机制和插入新个体的精英策略,动态调整种群规模。
GAVAPS[14]中提出个体的年龄和寿命概念。每进化一代,年龄增加一岁。当种群个体年龄大于寿命时,将其从种群中删除。寿命值根据每个个体特性,采用双线性分配策略计算,如式(2)、式(3)所示。
(2)
(3)
其中,avgfit、minfit和maxfit分别为当前种群适应度值的平均值、最小值和最大值;LFmax、LFmin分别为寿命可达到的最大值和最小值。
为了弥补种群多样性减弱问题,在种群中复制适应度值高的部分作为新个体补充。被复制个体的数目num和此时种群规模的大小变化如式(4)、式(5)所示。
num=ξ·(NPmax-NPg)
(4)
NPg+1=NPg-NPdead+num
(5)
其中,ξ为复制率;NPmax为种群最大规模;NPg、NPg+1和NPdead分别为当前种群、下一代种群的规模和执行寿命机制时淘汰的个体数目。
2.3 遗传交叉操作
针对传统遗传算法易陷入局部极值的缺点,提出一种基于Logistic混沌序列[15]的交叉算子,利用其良好的遍历性和随机性确定交叉位置,如式(6)所示:
(6)
式(6)中,λk为混沌变量λ迭代k次的结果;μ为状态控制参数;当μ=4、λ∉{0.25,0.5,0.75} 时,Logistic映射工作处于混沌状态[16],初始序列值呈现伪随机分布,在此状态下结合种群规模以确定实际交叉位置。
根据实数编码原则,交叉算子采用模拟二进制交叉法(SBX),染色体Xi和染色体Xj在选定位置上的交叉操作如式(7)。
(7)
其中r为交叉系数。
2.4 基于适应性调节的差分变异
作为一种基于群体差异的启发式随机搜索算法,差分进化利用种群中个体间的差分向量对个体进行扰动,以实现个体变异[17-18]。本文随机选取不同个体,将其向量差缩放后与待变异个体进行向量合成新个体。改进的适应性调节DE/rand/1变异策略如式(8)所示。
νi(g+1)=xr1(g)+F·(xr2(g)-xr3(g))
(8)
其中,F为缩放因子;低适应度值需采用较高的F值以增加寻求到最优解的概率,反之则需要较小的F值。因此本文借鉴文献[19]中调节遗传算法变异率的思想,根据进化过程中个体适应度值的变化情况调节参数F。自适应调节策略如式(9)所示。
(9)
其中,xbest、xworst分别为当前种群内具有最优、最差适应度值的向量;λ=10-13;当|f(xi)-f(xbest)|→0时,Fi→Fmin;当|f(xi)-f(xbest)|→∞时,Fi→Fmax,Fmax和Fmin分别为F值的上、下限。
2.5 算法基本流程
差分—遗传算法优化BP网络的主要内容分为两部分:其一,决定网络参数及编码初始化;其二,用DE-GA算法完成优化。如图1所示,本文采用DE-GA算法的种群适应性调整、种群个体之间交叉、差分变异等过程代替 BP神经网络的误差梯度下降方法。经过优化后的网络可以进行仿真预测等工作。

图1 DE-GA优化BP网络算法流程
具体实现步骤如下:
(1)编码及初始化。采用实数编码,并对初始种群规模NPinital、最大迭代次数G、差分缩放因子F、交叉概率Pc等参数进行初始化。
(2)设计BP神经网络的结构,包括隐含层节点数、神经网络层数等。
(3)对种群个体执行基于Logistic的交叉操作以及差分变异操作,计算个体的适应度值,选择当前群体中的最佳个体作为最优解。
(4)当不满足迭代结束条件时,使用寿命机制以及精英复制策略对种群规模进行适应性调整,返回步骤(3);若满足算法停止条件,则算法结束。
3 实验结果与分析
为了对差分遗传算法的性能进行定性评价,本文选用典型的Rastrigr和Sphere函数,对差分遗传算法和传统遗传算法的适应度函数值收敛性进行对比[20]。图2和图3分别为DE-GA算法与遗传算法在Rastrigr和Sphere函数下的适应度值及种群的迭代进化曲线。设定种群初始规模NPinital=100,个体编码维数为10,最大迭代初始值G分别为7 000和500,交叉概率Pc=0.7。由图2和图3可见,在迭代初期,两种方法下的适应度值变化幅度大、收敛快;随后浮动幅度逐渐减缓,直至收敛到稳定状态。

图2 Rastrigr函数进化曲线
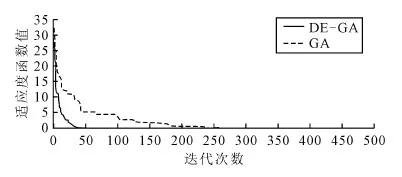
图3 Sphere函数进化曲线

函数名函数表达式Rastrigr函数f(x)=∑100i(x2i-10cos(2πxi)+10) |xi|≤5.12Sphere函数f(x)=∑100i=1x2i |xi|≤5.12Rastrigin函数f(x)=20+x21+x22-10(cos2πx1+cos2πx2)
由图2和图3可以看出,在同样的环境条件下,DE-GA算法在适应度值收敛于0时,迭代速度明显快于传统遗传算法。对拥有多个局部极值点的Rastrigr函数进行测试时,图3中遗传算法在迭代中期处于几乎不收敛进化的状态,收敛速度缓慢,而同时间的DE-GA算法已收敛至稳定状态。从程序运行速度来看,DE-GA算法与传统遗传算法运行时间分别为20.904ms和65.146ms。而较简单的Sphere函数经过50代左右差分遗传迭代就可得到较好的优化结果。由此可知,使用差分进化遗传算法时,程序运行速度明显快于遗传算法,降低了时间复杂度,性能更优。
本文选用Rastrigin函数作为测试函数验证差分遗传算法优化BP网络的性能,自变量和对应的函数值随机选取2 000组作为样本点,其中1 900个用于训练,100个样本点作为测试数据。按照步骤建立差分遗传算法基本结构和参数,设置最大迭代次数为200,算法误差阈值为1e-6。DE-GA算法的参数具体设置为:初始种群规模NPinital=100,最大迭代次数为50,交叉概率Pc=0.7,学习因子为0.1,初始差分缩放因子F=0.5,BP网络均采用2-20-1的结构。图4和图5分别为原BP网络与经过差分遗传算法优化后网络100个样本的误差。

图4 BP神经网络样本误差

图5 DE-GA优化的BP网络样本误差
由图4、图5可见,100个样本点的误差分布较均匀,但同时部分点误差较其它样本点偏大,证明其存在一定的不稳定性。本文以所有测试样本的平均误差评估此次训练水平,其中经过BP网络和基于DE-GA算法优化网络训练的平均误差分别为17.42%、1.78%,由此可见,经过差分遗传算法优化后的预测精度得到了大幅提高。
在本文给出的算法中,初始染色体的选择等流程中都具有一定随机性,因此评估算法的可靠性尤为重要。本文进行了一系列仿真测试算法稳定性,对基于DE-GA算法的BP网络仿真50次,其误差如图6所示。

图6 算法稳定性测试平均误差
由图6可以看出,50次仿真中最大训练误差为2.5%,最小误差为0.2%,误差均匀分布在1.5%左右,没有出现误差极大的情况,可见该算法具有良好的可靠性,对于迭代具有很强的鲁棒性。
4 结语
本文提出一种改进的差分遗传算法BP神经网络模型,将遗传算法中的交叉操作、差分变异算子等结合起来,用于BP神经网络的权阈值优化。通过一系列仿真,证明DE-GA算法收敛速度快,具有很好的稳定性,且优化后的 BP网络取得了不错的预测效果。下一步研究工作将考虑在样本数量少、样本分布不均匀而造成神经网络预测误差大的场景下进行,以期得出更为实用的方法。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
新世纪智能(数学备考)(2021年5期)2021-07-28
小学生导刊(低年级)(2016年6期)2016-07-02
中国塑料(2016年11期)2016-04-16
计算机工程(2015年8期)2015-07-03
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
振动、测试与诊断(2014年6期)2014-03-01
四川生理科学杂志(2014年2期)2014-02-28
教育与职业(2014年16期)2014-01-19
