
基于DSD和剪枝的模型压缩与加速
2018-11-22 00:47褚莹凌力
微型电脑应用 2018年11期
褚莹, 凌力
(复旦大学 通信科学与工程系,上海 200433)
0 引言
随着ImageNet数据集的出现,学术界涌现出许多高性能的卷积神经网络模型。在过去几年中,卷积神经网络模型的结构愈发复杂,直接导致参数和卷积操作数大幅增加,使得模型体积增大、运行时间增长。当这些网络被布置到传感器和移动设备上时,由于有限的存储空间和计算资源,使得模型的运行效果无法达到最佳。因此针对卷积神经网路模型压缩和加速的研究成为卷积神经网络领域的一大热点。传统模型压缩研究的方法主要分为两种:
(1)通过剪枝去除冗余权重。如Denton[1]等人利用神经网络的线性结构,通过寻找一个合适的低秩逼近以达到到减少参数的目的。奇异值分解(SVD)和塔克分解同样可以减少权重的数目[2]。在此基础上,优化矩阵的存储方式可以进一步减少参数的存储空间。如Han提出的深度压缩[3]中利用聚类和哈夫曼编码大幅压缩了参数的存储空间。
(2)优化网络结构减少参数数量。近年来也涌现出不少神经网络结构的创新之作,如使用卷积层或全局平均池化代替全连接层。Network In Network[4]和GoogleNet[5]的网络结构都采用了替换卷积层的思想,从而获得了不错的成绩。
一般来说,我们通过将低于阈值的权重置为零来实现剪枝,此时再通过优化存储方式可以进一步减少存储空间,但若未引入针对稀疏矩阵的相乘方法,无法实现模型加速。
在此基础上,本文提出了剪枝和DSD(Dense-Sparse-Dense)训练技术相结合的模型压缩方法。其中剪枝采用裁去冗余卷积核的方式加速模型运行速度、压缩模型大小,并结合DSD训练方法提高剪枝后模型的正确率。
1 系统流程
本系统流程如下:
(1)以待压缩网络为基础,以每个卷积核权重的绝对值之和为排序标准,进行排序。
(2)根据设置的剪枝百分比裁去对应的卷积核,并调整后一层的卷积核权重。
(3)训练模型。
(4)恢复一定比例的卷积核,并再次训练模型。
(5)根据所需正确率可以重复进行(1)~(4)步骤,直到模型输出的准确率满足需求。
系统流程图,如图1所示。
2 DSD训练方法和卷积核剪枝策略
2.1 卷积核剪枝
卷积核剪枝是Li[6]等人提出的一种剪枝策略,是针对传统剪枝方法无法加速模型运行速度的改进方案。设第i层卷积层的通道数为ni,输入的特征图高为hi,宽为wi,将输入的特征图xi∈Rni×hi×wi转化为xi+1∈Rni+1×hi+1×wi+1,作为下一层的输入。第i层卷积层的卷积核表示为ni+1个三维卷积核Fi,j∈Rni×k×k,即每个卷积核由ni个二维滤波器K∈Rk×k构成。由此可得,第i+1层卷积层进行的运算量为ni+1nik2hu+iwi+1。如图2所示。
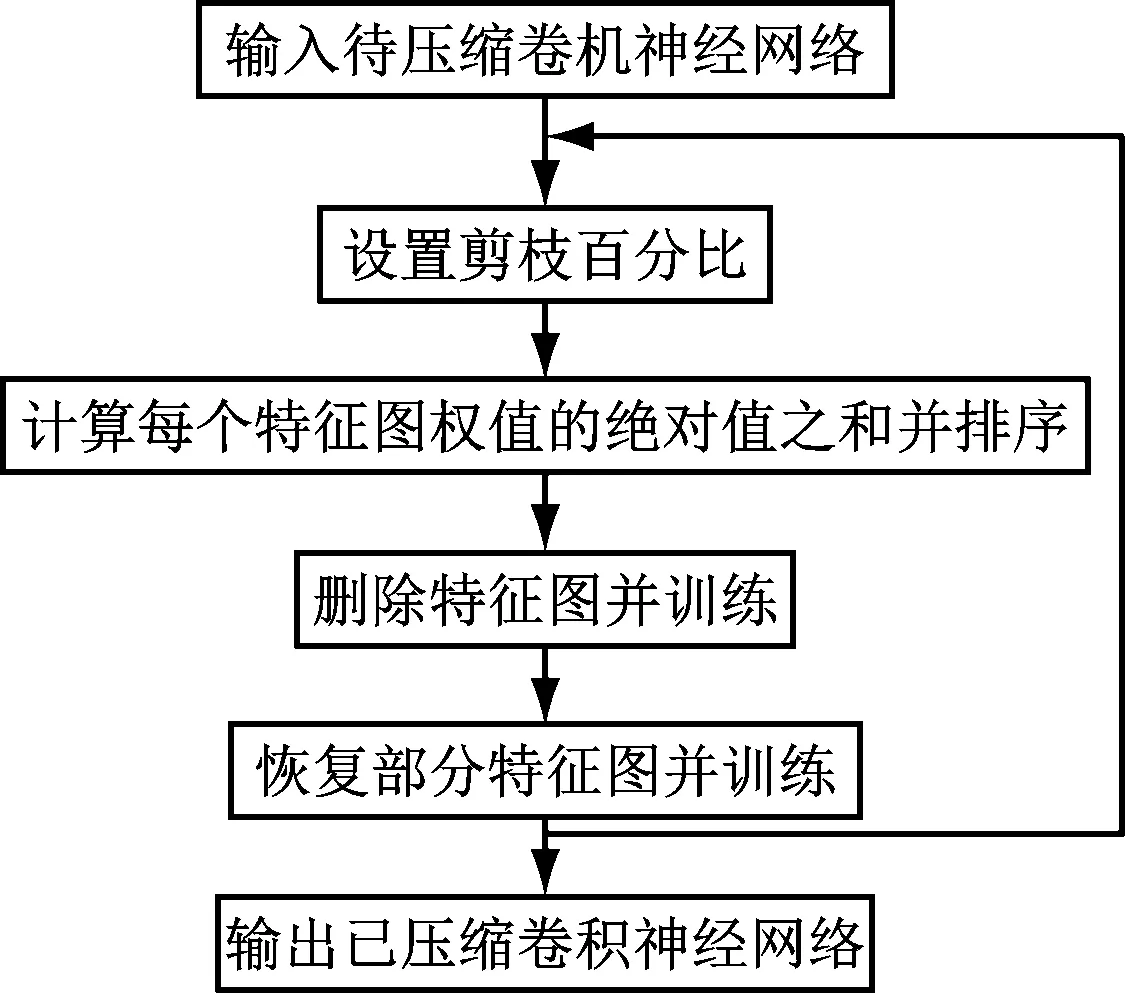
图1 系统流程图

图2 删去卷积核和特征图的对应关系
当卷积核Fi,j被裁剪后,对应的特征图xi+1,j会被连带删除,从而减少nik2hi+1wi+1次运算。并且下一层卷积层的卷积核中对应的部分也会被删去,进一步减少ni+2k2hi+2wi+2次运算。第i层卷积层剪去m个卷积核后,会对于第i层和i+1层都会减少比例为m/ni+1的运算量。如图2所示,当第i+1层删去第j个卷积核后,对应特征图的第j维被删去。
2.1.1 卷积核删除策略
为了减少正确率的下降,我们希望删去对最后结果贡献最小的卷积核。在本实验中,我们通过计算权重的绝对值之和来衡量卷积核的重要性,这是因为当特征图对应的权重绝对值较小时,说明该部分对产生的特征图贡献较小。
2.1.2 卷积层敏感度衡量方法
本文中,卷积层敏感度是指对于不同的卷积层,删除相同数目的卷积核对正确率的影响。我们认为正确率下降越多的卷积层越敏感。通过观察VGG-16后我们发现,同阶段的卷积层(即相邻且生成的特征图大小相同的卷积层)敏感度相近。为了避免增加更多的参数,对于同阶段的卷积层,我们采用相同的删除比例,对于较敏感的卷积层,我们的策略是降低删除比例,甚至避免删除这部分卷积层的卷积核,从而减少正确率的降低。
2.2 DSD训练
DSD(Dense-Sparse-Dense)是Han[7]等人提出的一种去除卷积层冗余连接的训练方法。流程如图3所示。
在DSD训练过程中,稀疏化是通过在权重更新的过程中忽略较小的权重实现的。但由于在之后的再密集过程中,为了恢复信息、提高正确率,会恢复这部分权重进行再训练,导致最后生成的模型在运行时并不能达到加速的效果。
所以在我们的方案中,我们使用卷积核剪枝替代稀疏化的过程,相当于忽略n个卷积核的所有节点,从而实现加速的目的。并在再密集过程中,恢复m个原卷积核的所有节点,即恢复一部分信息,通过再训练,进一步提高正确率。
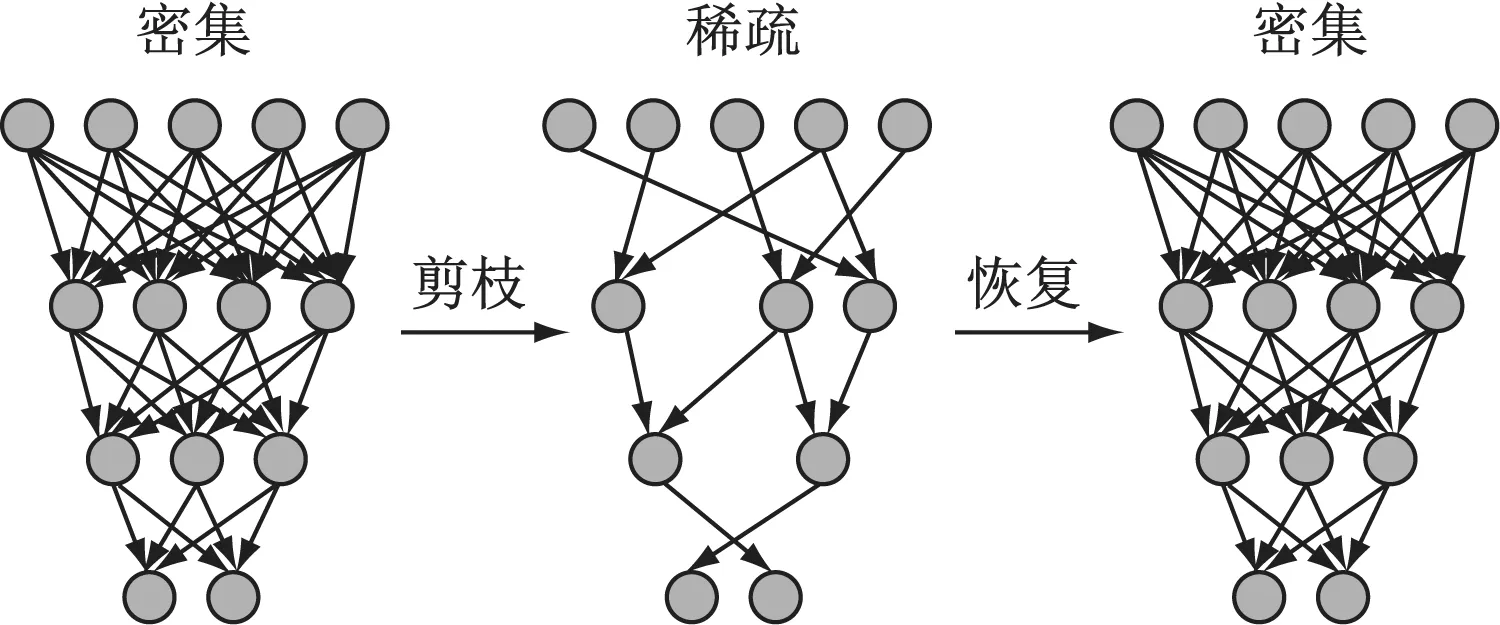
图3 DSD训练过程
3 实验性能测试与分析
3.1 DSD测试与分析
为了获取DSD的性能基准,我们将DSD训练应用到了VGG-16(Simonyan & Zisserman(2014))中。VGG-16通常用于目标检测,语义分割和迁移学习。在本实验中,我们将每层删除比例设置为30%(第一层不删)。如表1所示。
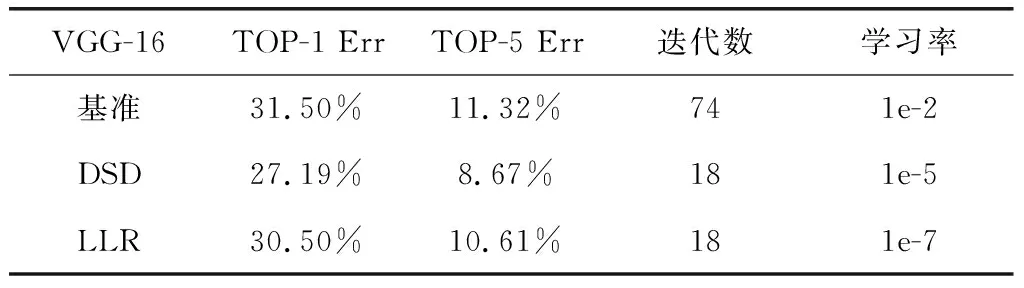
表1 传统训练方法和DSD的错误率比较
DSD训练使错误率下降了4.31%(Top-1)和2.65%(Top-5)。和LLR(降低学习率,再训练与DSD相同的迭代次数)相比,DSD训练得到的结果也更为优异。
3.2 卷积核剪枝测试与分析
同样的,我们将卷积核剪枝技术应用到VGG-16中。以CIFASR-10为数据集的VGG-16由13个卷积层和2个全连接层构成,其中运算量主要集中在卷积层中。对于生成512维特征图的卷积层,在保证不降低正确率的情况下,能够删去至少60%的卷积核。我们推测是因为对于4×4或2×2的特征图,存在更多的冗余连接。并且我们发现对于CIFAR-10数据集,第一层可以删去的比例比之后的3~7层更多。这对于CIFAR-10数据集是合理的,因为第一层即使被删去80%的卷积核,剩下卷积核的数目(12)依然大于类别数(10)。但是若移去第2层卷积层80%的卷积核,生成的特征图将由64降到12,可能会丢失重要信息,从而导致正确率的下降。最后我们实验发现,在保证正确率不下降的条件下,对于第1层和8~13层可以删去50%的卷积核,减少共34%的运算量,和1.5E+07的参数数量,相当于减少了34%的运行时间。
3.3 剪枝和DSD相结合的模型压缩与加速测试与分析
我们使用卷积核剪枝替代DSD中稀疏化的过程,以直接删除最终的卷积核比例为基准,通过观察本策略在VGG-16网络中的表现,如图4所示。
我们发现对于同一卷积层而言,当保持剪枝比例相同时,恢复不同比例的卷积核,模型的正确率在60%以后缓慢上升。这是因为通过剪枝后的再训练,重要的连接得以加强,替代了一部分低权重的作用,因而此时剩余40%的卷积核对正确率的影响较小。

图4 恢复不同比例卷积核错误率比较
由图4可见,当恢复60%的卷积核时,本文提出的方案得到的TOP-5错误率为9.01%,虽然比只使用DSD的错误率高0.44%,但纯DSD方案没有加速的效果,而本方案能够减少40%以上的运算量,所以0.44%的错误率上升仍在可接受范围内。
当采取60%的恢复策略时,和未采用DSD训练方法的方案相比,在保持相同准确率的情况下,运算量进一步减少了11%,达到45%。如表3所示。
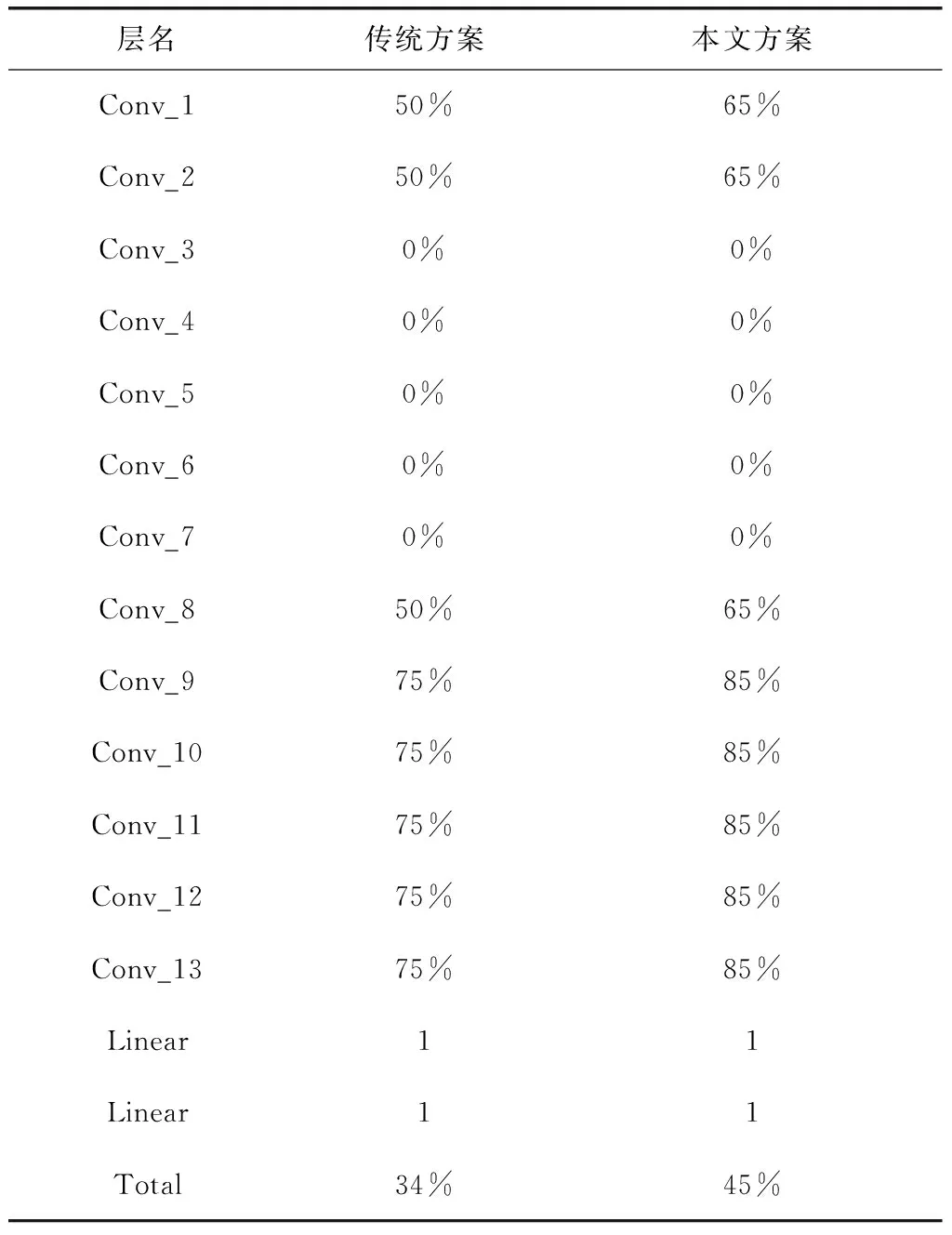
表3 运算量降低结果对比
这是因为采用DSD的方案后,相当于我们将卷积核的重要性进行了区分,稀疏化后留下的卷积核最为重要,通过稀疏化后的训练和恢复后的训练得到了二次加强。而恢复的卷积核通过恢复后训练得到了一次加强,权重较小的卷积核则被舍去,得以提高最终模型运行速度。
4 总结
针对传统的卷积核剪枝方案,本文提出了一种结合DSD训练方法的模型压缩与加速方法。通过将DSD训练过程中的稀疏化过程替换成卷积核剪枝,并在再密集过程中只恢复部分卷积核的方法,使得模型兼具卷积核剪枝和DSD训练方法的优点,减少了模型45%的运行时间。未来的工作中,还可以进一步区分卷积层的重要性,通过轮番运行稀疏化和再密集过程,提高准确率。
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
中学生理科应试(2019年3期)2019-07-08
新课程·上旬(2019年1期)2019-03-18
湖南教育·C版(2018年3期)2018-06-05
教师·中(2017年3期)2017-04-20
天津诗人(2017年2期)2017-03-16
福建中学数学(2016年7期)2016-12-03
试题与研究·教学论坛(2016年27期)2016-08-11
