
基于文本数据分析的大数据审计方法研究
2018-11-28 13:05陈伟勾东升徐发亮
中国注册会计师 2018年11期
陈伟 勾东升 徐发亮
一、引 言
近年来,大数据技术的研究与发展为审计工作带来了机遇和挑战,目前国内外高度关注大数据技术在审计工作中的应用,探索在审计实践中运用大数据技术具有重要的应用价值和理论意义。由于目前被审计单位信息化程度高,信息系统复杂,需要采集和审计的各类数据较多,且不仅仅是数据库中的电子数据,还包括一些政策文件、项目信息、董事会会议记录、董事会会议决议、总经理办公会记录、会议决议单、办公会通知、办公文件,以及内部控制手册、信息系统使用手册等非结构化材料。因此,如何对文本格式的非结构化数据进行分析是开展大数据审计的一项重要内容。本文结合目前大数据审计的研究与应用现状,探索基于文本数据分析的大数据审计方法。
二、常用审计方法的不足
常用的审计数据分析方法包括账表分析、数据查询、审计抽样、统计分析、数值分析、数据相似检测等,这些方法多是针对结构化数据进行分析,而对于文本数据等非结构化数据则不能进行有效的分析。以统计分析方法和数据相似检测分析为例,其特点分析如下:
1.统计分析方法
常用的统计分析方法的应用示例如图1所示,这种统计分析方法多是针对数值型字段进行分析,而不能针对字符型字段中的文本数据进行统计分析。
2.结构化数据的相似检测方法
对于数据库中的结构化数据,通过数据相似检测,可以判断两个数据表中的两条数据是不是相似重复数据,目前在审计中已有相关应用,例如,大数据环境下从不同地方采集来的被审计数据中,被审计数据A中出现的数据不应该出现在被审计数据B中。通过数据相似检测技术可以有效地发现舞弊案件。其中,两个数据表中对应字段的相似度计算是关键,对于不同类型的字段,一般采用如下不同的计算方法:
(1)布尔型字段相似度计算方法:对于布尔型字段,如果两字段相等,则相似度取0,如果不同,则相似度取1。
(2)数值型字段相似度计算方法:对于数值型字段,可以采用计算数字的相对差异算法:

(3)字符型字段相似度计算方法:对于字符型字段,一个字段可以看成是一个字符串,字符串的相似检测最主要的方法是基于编辑距离算法。通过采用编辑距离算法,可以计算出两个字段间的编辑距离,进而计算出字符型字段的相似度(图1)。
综上可知,目前常用的审计数据分析方法多是针对结构化数据。大数据环境下,需要审计的不仅仅是数据库中的结构化数据,还包括一些政策文件、项目信息等非结构化数据。因此,常用的审计方法不能满足大数据环境下审计工作的需要,其中,研究如何对文本数据进行审计非常重要。
三、基于文本数据分析的大数据审计方法
(一 )基于文本数据分析的大数据审计方法原理
大数据环境下大量的文本数据使审计人员分析的难度越来越大,传统的浏览和筛选等方法无法满足大数据环境下文本数据等非结构化数据审计的需要,对非结构化数据进行可视化分析,是大数据审计研究与应用的重要内容。将文本数据中的内容或规律以视觉符号的形式展示给审计人员,有助于审计人员利用视觉感知的优势来快速获取大数据中蕴涵的重要信息,从而发现审计线索。对大数据审计来说,文本内容可视化主要是为了快速获取文本数据内容的重点,快速理解文本的主要内容,可以采用基于词频的可视化技术,如采用TFIDF技术、标签云的可视化形式进行展示。
基于文本数据分析的大数据审计方法原理可概述为:根据对被审计单位的调查,在访谈和现场观察等基础上,采集被审计单位的内外部相关信息如政策文件、项目信息、董事会会议记录、董事会会议决议、总经理办公会记录、会议决议单、办公会通知、办公文件、项目安排、相关年度资金计划安排、项目工作总结、相关项目绩效评价报告等非结构化数据,以及从外部网上公开数据源采集来的相关文本数据;然后,在审计大数据预处理的基础上,基于“总体分析、发现疑点、分散核查、系统研究”的审计思路,采用大数据工具对相关文本数据进行分析,审计人员通过对可视化的分析结果进行观察,快速从被审计大数据信息中发现异常数据,获得审计线索;在此基础上,通过对这些结果数据做进一步的延伸审计和审计事实确认,最终获得审计证据。综上分析,基于文本数据分析的大数据审计方法原理如图2所示。
(二 )相似度分析
1.相似度分析方法的原理
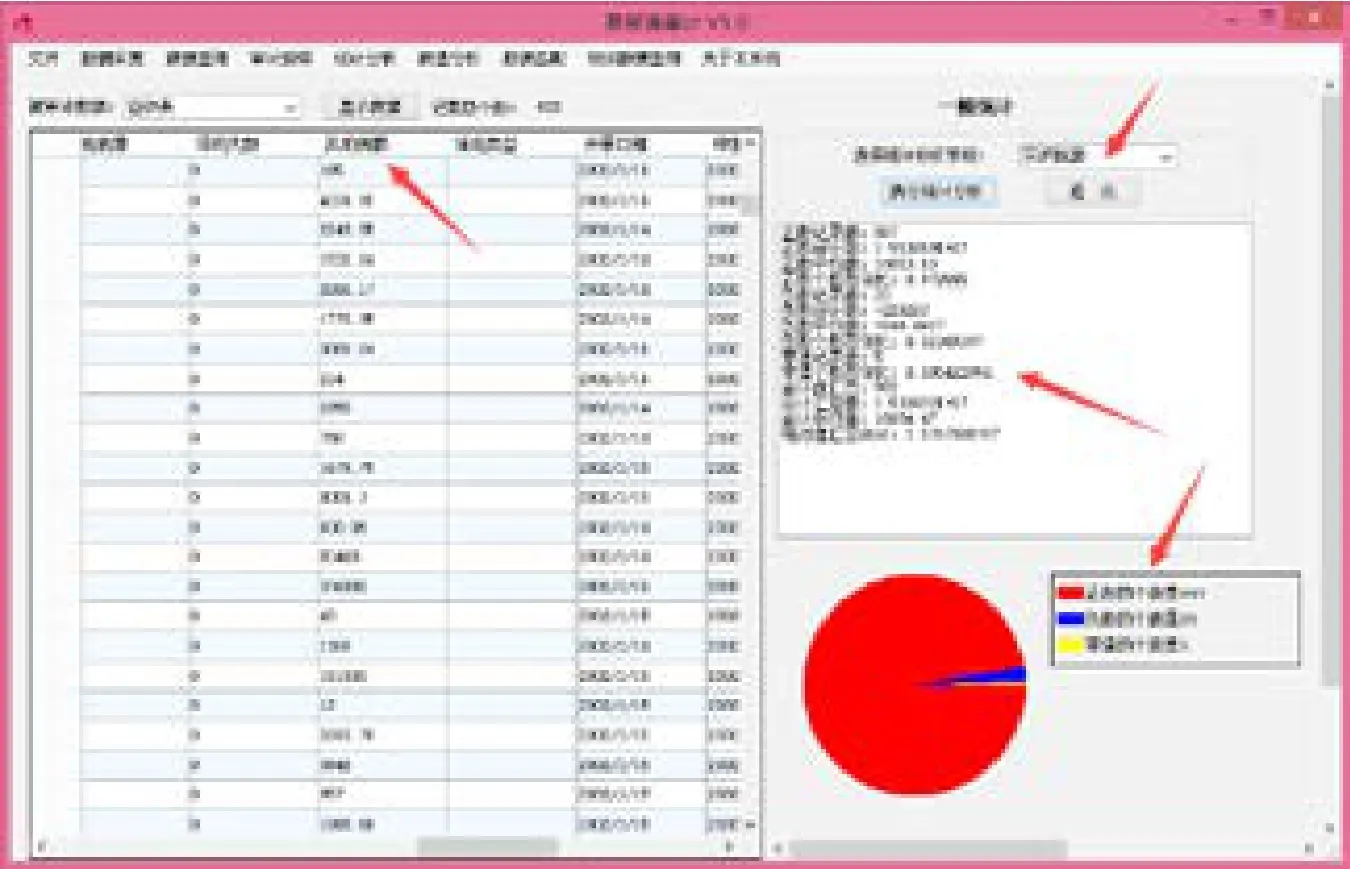
图1 统计分析方法的应用示例
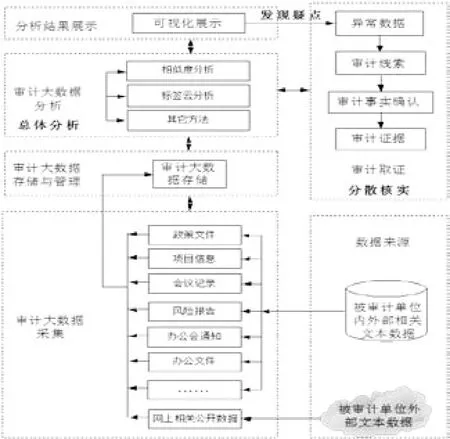
图2 基于文本数据分析的大数据审计方法原理
大数据环境下,相似度分析是目前有效的一种文本数据审计方法。大数据审计环境下,有时需要分析文本数据之间是否相似,成熟可行的方法可以采用 T FIDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)技术,它是一种常用的自然语言处理(NLP,Natural Language Processing)方法,TF-IDF的主要思想是:根据字词的在文本中出现的频率和在整个文本库中出现的频率来计算一个字词在整个文本库中的重要程度。如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文本中出现的很少,则认为该词或者短语具有很好的代表性,适合用来分类。TF-IDF可用于比较两个文本文件相似程度、文本聚类、文本分类等方面。 TF-IDF的计算步骤如下:
(1)计算TF(词频)
TF(Term Frequency,词频)表示某个词组在整个文本中出现的频率,其计算公式如下:

(2)计算IDF(逆文档频率)
IDF(Inverse Document Frequency,逆文档频率)计算逆文档频率。文档频率是指某个关键词在整个文本库所有文件中出现的次数。逆文档频率又称为倒文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。为防止分母为0(即词语在文本库中不存在),使用“包含该词的文本数+1”作为分母。IDF的计算公式如下:

(3)计算TF-IDF(词频-逆文档频率)
综上,T F-I D F的计算方法如下:

不难发现:TF-IDF值越大,表示该特征词对这个文本的重要性越大。
由以上分析可知,TF-IDF的优点是能过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要词语,该方法简单快速,结果比较符合实际情况;缺点是有时重要的词语可能出现次数并不多,仅仅以词频衡量一个词的重要性还不够全面,另外,这种算法无法体现词语的位置信息。

图3 基于Python语言的文本数据相似检测方法运行代码示例

图4 基于Python语言的标签云分析方法运行代码示例
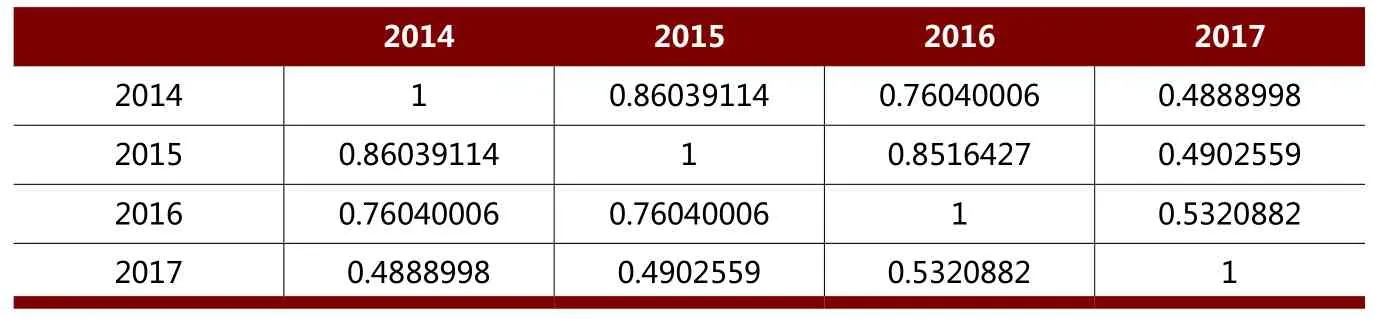
表1 某省2014-2017年扶贫项目内容相似度分析结果
综上分析,如果同时计算一个文件中所有词组的TF-IDF,将这些词的TF-IDF相加,可以得到整个文本文件的值,从而可用于文本文件的相似度比较。
2.相似度分析方法的实现
根据前文对TF-IDF方法的分析,采用Python语言实现了文本数据相似检测方法,运行代码实现示例如图3所示。
(三 )标签云分析
1.标签云分析方法原理分析
标签云(Tag Cloud)是常用的可视化分析方式之一,它由一组相关的标签以及与标签相对应的权重组成,这些标签按字母顺序或其他顺序,或者再结合颜色深浅进行排列,呈现出来供用户浏览的文本可视化方法。其中,权重值的大小决定标签的字体大小、颜色或其他视觉效果。
通过对被审计文本数据进行标签云可视化分析,可以整体把握被审计文本数据的主要内容。实现标签云分析的主要步骤包括:(1)分词;(2)统计词频;(3)根据词频自动设置颜色深浅、字体大小并进行可视化展示。
2.标签云分析方法的实现
基于以上分析,采用Python语言实现了文本数据的标签云分析方法,其运行代码示例如图4所示。
四、基于文本数据分析的大数据审计方法应用
(一 )应用思路分析
扶贫审计是目前审计领域研究与应用的一个重点,为了便于审计人员从整体上把握扶贫项目内容等情况,快速发现可疑问题,提高审计效率,实现“集中分析、分散核查”的审计方式,本节以扶贫审计为例,分析如何应用基于文本数据分析的大数据审计方法。其基本思路为:为了总体了解被审计单位对扶贫政策的执行情况,可以通过对某一时期内每年的扶贫项目内容进行相似度分析,检测每年扶贫项目内容的变化情况,如果每年的项目内容相似度高,说明扶贫项目内容变化不大,在此基础上,进行扶贫项目内容标签云分析,检查相关扶贫项目关注的重点,检测关注的重点是否有变化。另外,对扶贫资金使用情况进行标签云分析,检查是否存在违规使用的问题
(二 )扶贫项目内容相似度分析
基于以上分析,以某省扶贫项目审计为例,采用本文研究的基于文本数据的相似度分析方法分别对该省2014到2017年的扶贫项目内容进行相似度分析,分析结果如表1所示。

图5 2014年项目内容分析示例

图6 2015年项目内容分析示例

图7 2016年项目内容分析示例
由表2不难发现:2014年、2015年、2016年项目内容相似度较高,与2014年、2015年、2016年项目内容相比,2017年项目内容变化较大。由此可见,该省2017年扶贫项目内容发生了重大变化,值得审计人员进一步关注。

图8 2017年项目内容分析示例

图9 某地污染高能耗项目分析示例

图10 某省扶贫资金使用情况内容分析示例
(三 )扶贫项目内容标签云分析
在扶贫项目内容相似度分析的基础上,为了进一步了解该省2014-2017年扶贫项目的主要内容,掌握扶贫政策的变化情况,审计人员可以采用标签云对采集来的扶贫项目数据进行综合分析,总体掌握扶贫项目内容情况,以及某一时期内扶贫项目内容的变化情况,从而可以帮助审计人员判断被审计单位的扶贫政策执行情况。
1.扶贫政策执行情况分析
基于以上分析,以某省扶贫项目审计为例,采用基于文本数据的标签云分析方法对该省2014到2017年的扶贫项目内容进行标签云分析,其示例结果如图5—8所示,其中,标签云中字体的大小表示扶贫项目内容出现的次数情况。图5—8的分析结果表明,与前文的相似度分析结果一致,该省2017年扶贫项目内容发生了变化,比如,建档立卡等工作成为2017年扶贫项目关注的重点,从而表明被审计单位有效地执行了国家的扶贫政策。
2.扶贫内容合理性分析
通过对扶贫项目内容进行分析,可以整体把握一些扶贫项目内容是否符合国家产业政策,例如,分析扶贫项目是否投向一些高污染、高能耗等国家禁止的行业项目,如果存在,则需要审计人员进一步关注。
基于以上分析,以某地扶贫项目审计为例,采用基于文本数据的标签云分析方法对该地扶贫项目内容进行标签云分析,其示例结果如图9所示。分析结果表明,该省扶贫项目内容中存在“制革”、“有色”、“冶炼”等关键词,从而表明被审计单位可能存在扶贫项目内容属于高污染、高能耗行业,需要审计人员做进一步的延伸分析。

(四 )扶贫资金使用情况的标签云分析
为了掌握扶贫资金的整体使用情况,确认扶贫资金的使用是否合理、合规和合法,需要对某一时期内扶贫资金使用内容进行总体分析。针对这一需要,基于文本数据的标签云分析方法对从被审计单位采集来的相关扶贫资金支出数据进行分析,根据分析结果可以初步发现扶贫资金是否存在违规使用的问题。例如,采用标签云对从某省采集来的扶贫资金进行综合分析,其示例结果如图10所示。
图10的分析结果表明,该被审计单位一部分扶贫资金用在了餐费、高尔夫、中介费、烟酒等方面。根据这一分析,审计人员可以对这些扶贫资金数据做进一步的详细分析,查找所有含有“餐费、高尔夫、中介费、烟酒”等方面的支出,从而发现审计线索。
五、总 结
对文本数据进行分析是大数据审计的一项重要内容,但由于目前常用审计软件中缺少针对文本数据的审计方法,审计人员无法采用这一方法进行审计。本文采用易于实现的大数据开源分析语言Python实现了文本数据审计方法,包括文本相似度分析和标签云分析,采用该方法不需要开发或购买专门的审计软件,审计人员能够在低成本、易实现的情况下实现对文本数据的分析,从而为大数据审计的广泛应用打下了基础。
猜你喜欢
电脑爱好者(2021年23期)2021-12-08
老年教育(2021年5期)2021-05-25
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
办公室业务(2019年13期)2019-08-01
娃娃乐园·3-7岁综合智能(2016年2期)2016-10-24
娃娃乐园·3-7岁综合智能(2016年6期)2016-09-19
新世纪图书馆(2014年7期)2014-09-19
