
一种改进的自适应聚类集成选择方法
2018-12-05 05:34徐森皋军花小朋李先锋徐静
自动化学报 2018年11期
徐森 皋军 花小朋 李先锋 徐静
聚类分析的目标是依据对象之间的相似度对其自动分组/簇,使得簇内对象彼此相似度尽量高,而簇间对象彼此相似度尽量低[1−2].虽然已有上千种聚类算法,但没有一种能有效识别不同大小,不同形状,不同密度甚至可能包含噪声的簇[1].已有聚类方法主要分为:1)基于划分的方法,将聚类问题转化为优化问题,并采用不同的优化策略,例如,K均值算法(K-means,KM)[3]、非负矩阵分解(Nonnegative matrix factorization,NMF)[4]、近邻传播算法(Affinity propagation,AP)[5]、子空间聚类算法[6]以及基于深度学习[7]的聚类算法[8];2)层次聚类[2],例如单连接(Single linkage,SL)、全连接(Complete linkage,CL)、组平均(Average linkage,AL);3)基于模型的方法[1],将聚类问题转化为模型的充分统计量估计问题;4)基于密度的方法,通过寻找被低密度区域分离的高密度区域来进行聚类,例如密度峰值(Density peaks,DP)算法[9]、谱聚类方法[10];5)基于谱图理论将聚类问题转化为图划分问题.
2002年,文献[11]正式提出聚类集成(Cluster ensemble),通过组合多个不同的聚类结果能够获得更加优越的最终结果,具有传统聚类算法无可比拟的优势[12].早期的聚类集成研究主要围绕聚类成员生成和共识函数设计问题展开,目前已有较多聚类成员生成方法及共识函数设计方法[13−26].受“选择性集成学习”研究启发,文献[27]于2008年开启了选择性聚类集成研究,其关键问题为聚类成员选择问题,即如何从所有聚类成员集合(称为聚类集体)中选出部分聚类成员用于后续集成,获得比对所有聚类成员进行集成更加优越的结果.文献[27]提出了质量和多样性综合准则(Joint criterion,JC)、聚类并选择(Cluster and select,CAS)和凸包(Convex hull,CH)三种方法.文献[28]提出了自适应聚类集成选择(Adaptive cluster ensemble selection,ACES),依据聚类成员与初始一致划分π∗的归一化互信息(Normalized mutual information,NMI)将聚类集体分为稳定和不稳定两类,并选择不同的聚类成员子集.ACES方法存在两个问题:1)判定聚类集体稳定性的方法不客观,稳定性与初始一致划分π∗有关,在某些情况下容易将不稳定的聚类集体误判为稳定.当聚类成员之间差异性较低时,NMI值较大,且NMI值大于0.5的比例较高,聚类成员与π∗的NMI值也较大,此时聚类集体稳定;当聚类成员之间差异性较高时,NMI值较低,平均NMI值低于0.5,且NMI值大于0.5的比例低于50%,但仍然有绝大多数的聚类成员与π∗的NMI值大于0.5,此时虽然聚类集体不稳定,但ACES方法却判定聚类集体是稳定的.2)聚类成员子集的选择方法不够合理.当聚类集体稳定时,ACES简单地选择Full集并输出π∗,而没有进一步选择差异性较高的聚类成员来提高集成效果;当聚类集体不稳定时,ACES简单地选择High集,可能会选出少量聚类质量较差的聚类成员.
本文针对ACES存在的问题,提出了一种改进的自适应聚类集成选择方法(Improved adaptive cluster ensemble selection,IACES).本文把所有聚类成员的整体平均NMI值(Total average NMI,TANMI)作为判定聚类集体是否稳定的依据,若TANMI大于0.5,则聚类集体稳定;否则,不稳定.有效解决了上述第一个问题.当聚类集体稳定时,聚类成员提供相似的聚类结构,差异可能由聚类算法陷入局部最优值引起,π∗能够在一定程度上减小聚类成员之间差异引起的方差,可能比聚类成员更加接近于真实分类结果.与ACES选择Full集不同,本文首先选择与π∗的差异性最低(NMI值最大)的1/4的聚类成员,降低平均误差;然后选择与π∗的差异性最高(NMI值最小)的1/4的聚类成员,增加平均差异性;另外,为了避免选出离群点,通过约束聚类成员的平均NMI值(Average NMI,ANMI)排名高于某一阈值.此时,选出的聚类成员既具有较高质量,又具有适中的差异性,往往能够获得比π∗更加优越的结果.当聚类集体不稳定时,聚类成员提供了不同的聚类结构,差异可能由聚类算法本身的偏置或数据集的复杂结构引起,此时π∗偏离真实分类结果的可能性较大,因此应该尽量降低聚类成员的平均误差,选择与π∗差异性大的聚类成员(High集)往往会得到更好的结果.但High集里会存在一些质量较差的聚类成员,此时通过约束聚类成员ANMI值排名高于某一阈值,能够在很大程度上避免选出质量较差的聚类成员.有效解决了上述第二个问题.
1 聚类集成相关研究
本文在文献[11]提出的聚类集成框架上,增加聚类成员选择模块,形成选择性聚类集成系统框架,如图1所示,其中聚类成员选择是本文的研究重点.选择性聚类集成分为三步:第一步将数据集作为输入,运行聚类算法,输出聚类集体P={P(1),···,P(l)},这一步称为聚类成员生成;第二步将聚类集体作为输入,输出若干聚类成员构成的集合E={E(1),···,E(r)}⊆P,这一步称为聚类成员选择;第三步将E作为输入,对它们进行组合,输出最终的聚类结果,这一步称为聚类组合(Combination)/集成(Ensemble)/融合(Fusion),也称为共识函数(Consensus function)设计.下面对聚类集成相关研究予以阐述.
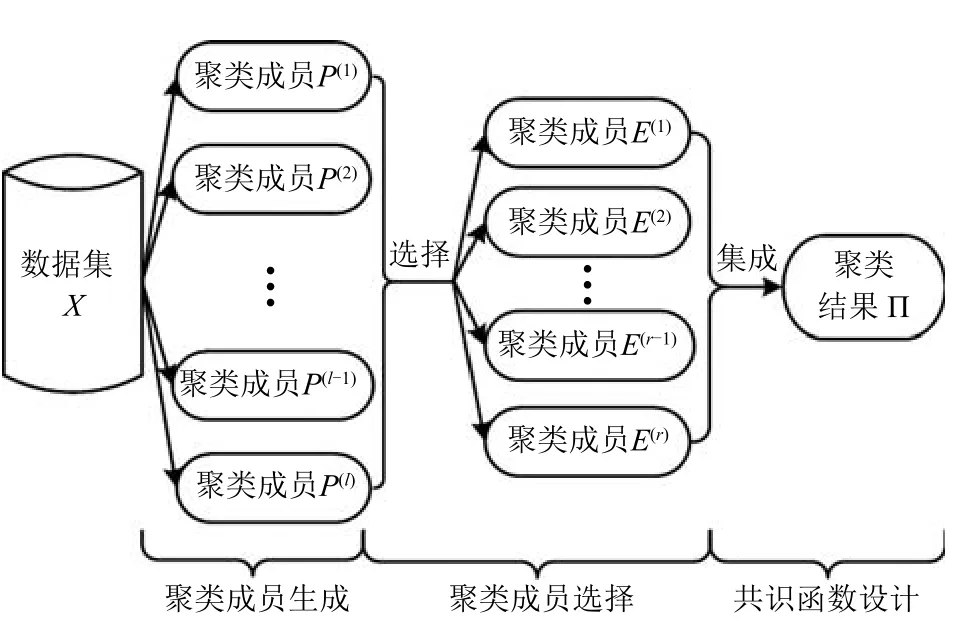
图1 选择性聚类集成系统框架Fig.1 Framework of selective cluster ensemble system
1.1 聚类成员生成
研究人员从聚类模型和数据集等角度入手提出了不同的聚类成员生成方法:1)采用同一种聚类算法[11−16,18−22,24−30].由于采用随机初始化的KM每次运行会得到不同的聚类结果,因此可通过多次运行来生成聚类成员.该方法计算复杂度仅为O(lknd),其中l为聚类成员的个数,k为簇个数,n为数据集大小,d为特征数,因此成为产生聚类成员最常见的方法[31].2)对不同的数据子集进行聚类,例如随机投影、投影到不同的子空间、采用不同的采样技术、选择不同的特征子集等[11,23].3)采用不同的聚类个数,例如设置多个不同的k值或在指定的区间随机选择k[17].
1.2 聚类成员选择
文献[32]指出当聚类成员多样性较高时能够获得更好的集成效果.与此不同,文献[33]指出适中的多样性能够获得最佳的集成效果.文献[28]认为不同数据集产生的聚类成员具有不同的特点,应该区别对待,提出了ACES:1)采用AL对聚类集体(Full集)进行集成,获得一致划分π∗;2)计算所有聚类成员与π∗的NMI值,若平均NMI值(Mean NMI,MNMI)大于0.5,则聚类集体稳定(Stable,S),否则,聚类集体不稳定(Non-stable,NS);若聚类集体稳定,则输出π∗为最终的聚类集成结果,若不稳定,则选择与π∗差异大的一半子集High(具体地,将所有聚类成员与π∗的NMI值按照降序排列,选择NMI值小的一半子集),采用AL对High集进行集成得到最终的聚类集成结果.
文献[27]提出了JC,CAS和CH三种聚类成员选择方法,其中每个聚类成员的质量与该成员和其他聚类成员的归一化互信息之和(Sum of normalized mutual information,SNMI)成正比,而聚类集体的多样性与所有聚类成员与其他成员的SNMI之和成反比.JC首先选择质量最高的聚类成员,然后逐一选择使得目标函数值最大的聚类成员,直到选出预设的K个聚类成员为止.CAS使用NJW谱算法[34]将聚类集体划分为K个分组,并从每个分组中选出一个质量最高的聚类成员.CH首先根据聚类集体绘制质量–多样性图,然后通过凸包创建该图的简要概括,其中包括质量最高、多样性最大的聚类成员所对应的点,最后选出有凸包内的点对应的聚类成员.该文使用CSPA(Cluster-based similarity partitioning algorithm)[11]作为一致性函数,对JC,CAS和CH进行了实验比较,总体来看,CAS获得了最佳聚类集成结果,但需要人工设置聚类成员个数.
文献[29]提出最有效一致划分(Best validated consensus partition,BVCP),采用不同的聚类成员选择方法选出不同子集,并对每个子集进行集成,获得多个候选一致划分(Candidate consensus partition,CCP),最后使用多个相对有效性指标评价每个CCP,得到最佳评价指标的CCP即为最终的一致划分.近期,文献[30]基于证据空间扩展有效性指标Davies-Bouldin(DB),利用聚类成员的类别相关矩阵度量差异性,以较高有效性和较大差异性为目标选择聚类成员.
1.3 共识函数设计
聚类分析过程中,对象标签是未知的,因此不同聚类成员得到的簇标签没有显式的对应关系.另外,聚类成员可能包含不同的簇个数,使得簇标签对应问题极具挑战[11].根据是否显式解决簇标签对应问题,聚类集成方法可分为以下两类:1)组对法(Pairwise approach),引入超图的邻接矩阵H将表示对象之间的两两关系,有效避免了簇标签对应问题.根据处理的矩阵不同,可以分为:a)对H(或其加权矩阵)进行处理,包括HGPA(Hypergraph partitioning algorithm)[11]和MCLA(Meta-clustering algorithm)[11]、基于NMF的方法[15]、基于KM 的方法[19]、结合KM与拉普拉斯矩阵的方法[26]、基于矩阵低秩近似的方法[35]等;b)对相似度矩阵S(或S的加权矩阵)进行处理,包括基于图划分算法的CSPA[11]、混合模型方法[12]、二部图模型方法[13]、层次聚类法[14]、链接法[17]、加权共现矩阵(Weighted co-association matrices)方法[20]、使用多蚁群算法的方法[22]、基于AP的方法[24]、基于DP的方法[25]、基于谱聚类的方法[36]等.组对法因其思想简单而成为解决共识函数设计问题的主要方法.2)重新标注法(Re-labeling approach),包括累积投票(Cumulative voting)[16]、PRI(Probabilistic rand index)[18]、选择性投票[21]等.
2 本文方法
2.1 聚类成员之间的差异性计算
在没有先验知识的情况下,衡量聚类成员差异性大小的一种思路是依据聚类成员彼此之间的“相似”程度:两个聚类成员越相似,差异越小,反之差异越大.本文采用源自信息论的NMI值[11]来度量聚类成员之间的相似度,NMI值越大,两个聚类结果的匹配程度越高,其相似度越大,差异性越小.通过计算聚类成员两两之间的NMI值,即可得到聚类成员之间的相似度矩阵.
2.2 聚类集体稳定性判定方法
假设l个聚类成员构成的聚类集体P={P(1),···,P(l)},ACES首先采用AL对聚类集体进行集成,获得一致划分π∗;然后计算所有聚类成员与π∗的NMI值,若MNMI大于0.5,则聚类集体稳定,否则,不稳定.MNMI的计算方法如下:

与ACES不同,本文根据所有聚类成员之间的相似程度判定聚类集体的稳定性,当所有聚类成员的TANMI大于0.5(或NMI值大于0.5的比例Proportion较高,例如Proportion≥50%)时,说明聚类集体的整体相似度较高,差异性较低,聚类集体稳定;否则,不稳定.TANMI的计算方法如下:
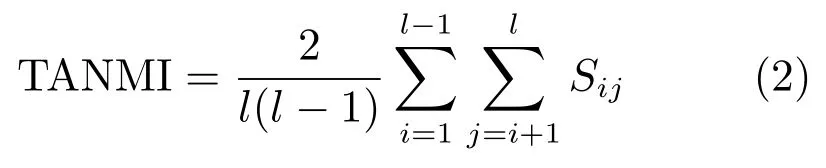
其中,Sij表示聚类成员P(i)和P(j)之间的NMI值,Sij越大,其相似度越大,差异性越小.Proportion的计算方法如下:
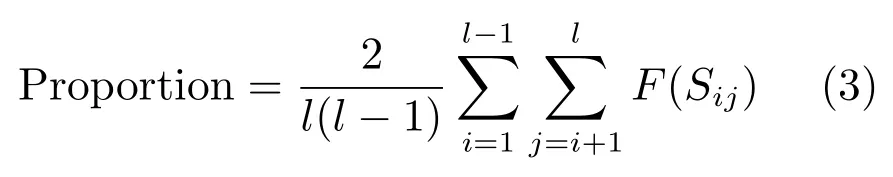
其中,F(x)为指示函数:当x>0.5时,F(x)为1,否则为0.
由式(1)可知,MNMI的大小不仅与聚类集体有关,还与π∗有关.由式(2)和式(3)可知,TANMI统计聚类集体的整体平均NMI值,Proportion统计聚类成员之间NMI值大于0.5的比例,对于给定的聚类集体,TANMI和Proportion是固定不变的.聚类集体稳定性分为两种情况:1)聚类集体稳定,此时,多数聚类成员之间的相似度较高,差异性较低(NMI值大于0.50),Proportion>0.5,TANMI>0.5,多数聚类成员与π∗的NMI值也大于0.5,故MNMI>0.5,因此,ACES与IACES方法都能正确判定聚类集体为稳定.2)聚类集体不稳定,此时,多数聚类成员之间的相似度较低,差异性较高(NMI值小于0.5),Proportion<0.5,TANMI<0.5,IACES方法能够正确判定聚类集体为不稳定,而ACES判定聚类集体是否稳定与π∗有关.当多数聚类成员与π∗的NMI值大于0.5时,MNMI>0.5,ACES方法会将聚类集体误判为稳定;当多数聚类成员与π∗的NMI值小于0.5时,MNMI<0.5,ACES方法判定聚类集体不稳定.
2.3 聚类成员选择方法
根据集成学习理论[37],集成的泛化误差E等于集成中各基学习器的平均泛化误差与平均差异性之差,即.因此,要提高集成学习的性能,可从两个方面着手:1)尽量降低各基学习器的误差;2)尽量增加基学习器之间的差异性.
文献[28]通过实验对比了4种聚类成员集合,分别是所有聚类成员构成的集合Full,与π∗差异性最低的一半聚类成员构成的集合Low,与π∗差异性最高的一半聚类成员构成的集合High,与π∗差异性适中的一半聚类成员构成的集合Medium,实验结果显示,当聚类集体稳定时,选择Full集合进行集成获得了最佳结果;当聚类集体不稳定时,选择High集合进行集成获得了最佳结果.
本文在ACES基础上进行了改进,提出以下聚类成员选择方法:当聚类集体稳定时,本文首先选择与π∗的NMI值最大的1/4的聚类成员,尽量降低聚类成员的平均误差;然后选择与π∗的差异性最高(NMI值最小)的1/4的聚类成员,尽量增加平均差异性,构成聚类成员集合LaH(Low and high);另外,为了避免选出精度较低的聚类成员(离群点),在LaH集合中剔除部分平均NMI值较低的聚类成员.具体地,本文对每个聚类成员与其他聚类成员的ANMI进行排名,限制选出的聚类成员排名在前θ以内,0%<θ≤100%.不妨假设聚类成员P(i)的ANMIi排名为Rank(i),则符合条件的聚类成员集合为C={P(i)|Rank(i)/l≥θ,1≤i≤l},因此,选择的聚类成员集合为LaH∩C,其中∩表示集合的交运算.此时,LaH∩C既具有较高质量,又具有适中的差异性,对其进行集成往往能够获得比π∗更加优越的结果.当聚类集体不稳定时,聚类成员提供了不同的聚类结构,差异可能由聚类算法本身的偏置或数据集的复杂结构引起,此时π∗很可能偏离了真实分类结果,因此应该尽量降低聚类成员的平均误差,选择与π∗差异性大的聚类成员(High集)可能会得到更好的结果.但High集里可能会存在一些质量较差的聚类成员,此时可通过约束聚类成员的ANMI排名在某一范围内.本文对每个聚类成员与其他聚类成员的ANMI进行排名,限制选出的聚类成员排名在前θ以内,0%<θ≤100%,因此,选择的聚类成员集合为High∩C.
为了确定合理的θ,本文首先采用不同的θ选出不同的聚类成员子集,然后对每个子集进行集成,获得多个CCP,最后使用内部有效性指标DB对每个CCP进行评价,得到最低DB值的CCP即为最终的一致划分.考虑到要确定最佳的参数θ需要运行l次,而DB的计算复杂度较高,当聚类成员个数l较大时,需要耗费极其高昂的计算代价.因此,为了提高算法效率,本文仅设置θ=10%,20%,···,100%,比较这10种情况下获得的最佳结果,获得一个较优解.在本文实验中,绝大多数情况下,当θ等于70%,80%或90%时获得了最低的DB值.
3 实验
实验平台为Intel Xeon E5-1650六核处理器,频率3.50GHz,内存16.00GB,程序在MAT-LAB2016b下运行.
3.1 实验数据集和评价指标
实验采用13组公共文本测试集,具体描述如表1所示,数据集中的文本数(nd)从204~8580不等,特征数(nw)从5832~41681不等,类别数(k∗)从3~10不等,平均每个类别包含的文本数(nc)从34~1774不等,平衡因子(Balance)从0.037~0.998不等(Balance等于最小类别包含的文本数除以最大类别包含的文本数,值越小,数据集越不平衡,反之越平衡).对于每个数据集,使用停用词表移去停用词,并且去掉出现在少于两个文本中的词.数据集tr11,tr23,tr41和tr45取自TREC-5TREC-6和TREC-7数据集la1,la2和la12取自TREC-5,由洛杉矶时报(Los Angles Times)上的文章构成.数据集hitech,reviews和sports取自报纸San Jose Mercury,它们是TREC文本集的一部分.数据集classic由用于评估信息检索系统的四种摘要构成,每个摘要集合构成单独的一类.数据集k1b来自于WebACE project[38],每个文本对应于Yahoo!主题层次下的一个网页.ng3为NG20的子集,包含了有关政治的3个不同方面,每方面分别包含约1000条信息.
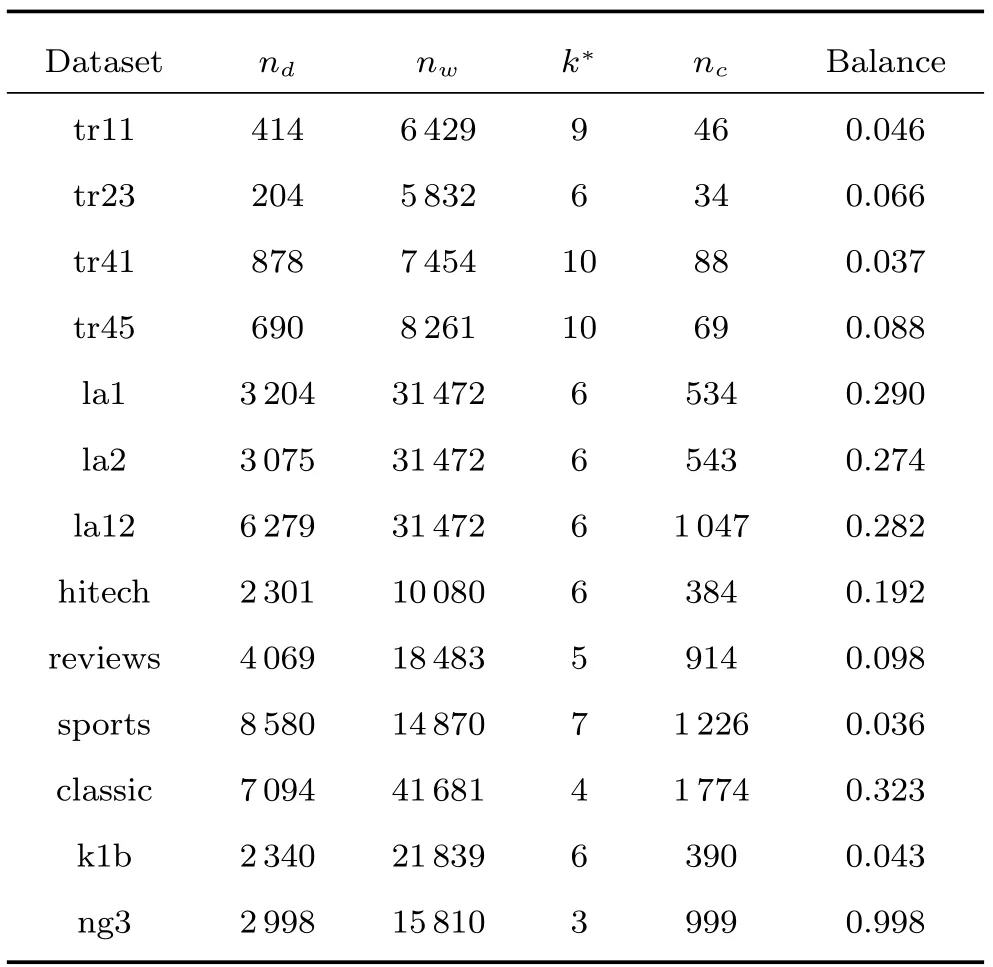
表1 实验数据集描述Table 1 Description of datasets
因为文本类别标签已知,本文采用NMI值量化聚类结果和已知类别的匹配程度.当两个类别标签一一对应时,NMI值达到最大值1.另外,本文还采在信息检索领域常用的综合指标,F值(F-measure).F值越大,聚类质量越高,反之越低.
3.2 实验设计与结果分析
本节通过实验对文献[28]提出的ACES、本文提出的IACES、文献[27]提出的CAS进行比较,其中ACES和IACES根据聚类集体的稳定性自适应选择不同的聚类成员,CAS通过人工设置的方法选择不同个数的聚类成员(分别设置为聚类集体大小的5%~25%,以5%递增,本文沿用该方法).实验分为两部分:1)聚类集体稳定性判定方法对比,分别根据ACES和IACES判定出聚类集体的稳定性结果,并进行分析比较,验证本文提出的聚类集体稳定性判定方法的有效性;2)聚类成员选择方法对比,分别根据ACES,IACES和CAS选择不同的聚类成员集合并采用不同的共识函数设计方法进行集成,比较不同算法获得的NMI值和F值,验证本文的聚类成员选择方法的有效性.下面对实验中采用的聚类成员生成策略和共识函数设计方法进行介绍.
首先对经过预处理的文本数据集进行TF-IDF(Term frequency-inverse document frequency)加权,然后运行使用余弦相似度的KM算法l次,每次生成k0个簇,采用如下两种不同的策略分别生成l=1000个聚类成员:1)k0=k∗;2)k0随机选自区间[2,2×k∗],由此分别构建聚类集体P1和P2.策略1是聚类集成研究中最常见的方法,由于采用了相同的聚类算法,每个算法生成的簇个数相等,因此聚类成员的差异性仅由不同初始聚类中心引起,聚类集体往往会缺乏多样性.策略2试图通过约束聚类成员具有不同的簇个数来提高聚类成员多样性.
常见的共识函数设计方法有基于图划分算法的CSPA,HGPA,MCLA(其中CSPA总体聚类效果最好),基于层次聚类SL,CL,AL,WL的方法(其中AL总体聚类效果最好),基于谱聚类(Spectral clustering,SC)的方法,基于KM的方法.因此,本文采用CSPA,AL,SC和KM进行集成.CSPA调用了图划分算法METIS,不平衡因子UB取默认值0.05,得到稳定的聚类结果.AL获得了稳定的聚类结果.谱聚类方法由于调用了KM算法,在部分数据集上获得的聚类结果不够稳定,本文重复运行KM算法10次取最优结果.基于KM的方法获得的聚类结果极不稳定,受初始聚类中心影响较大.为了提高聚类结果的稳定性和聚类质量,本文引入K-means++(KM++)算法,运行KM++10次取最优结果.
3.2.1 聚类集体稳定性判定方法对比
表2给出了分别根据ACES和IACES方法判定的聚类集体稳定性结果,其中MNMI值根据式(1)计算,Number表示与π∗的NMI值大于0.5的聚类成员个数,TANMI根据式(2)计算,Propor-tion根据式(3)计算,Stability为“S”表示聚类集体稳定,Stability为“NS”表示聚类集体不稳定.

表2 分别根据ACES和IACES判定的聚类集体稳定性结果Table 2 Stability results of cluster ensemble according to ACES and IACES
根据表2,可以进行以下比较:
1)因为在所有数据集上MNMI值都大于0.5,所以ACES将由不同聚类成员生成策略产生的聚类集体都判定为稳定.当k0=k∗时,在hitech和ng3上,聚类集体的TANMI值小于0.5,所以IACES将其判定为不稳定,而在其他11个数据集上,聚类集体的TANMI值大于0.5,所以IACES将其判定为稳定;当k0∈[2,2×k∗]时,在la2,la12,hitech和ng3上,聚类集体的TANMI值小于0.5,所以IACES将其判定为不稳定,而在其他9个数据集上,聚类集体的TANMI值都大于0.5,所以IACES将其判定为稳定.
2)如果以Proportion是否高于0.5来判定聚类集体稳定与否,那么在所有数据集上的判定结果都与依据TANMI判定的结果一致,而在部分数据集上与依据MNMI判定的结果不一致.究其原因,当半数以上的聚类成员之间的NMI值大于0.5时,聚类集体的差异性相对较低,聚类集体稳定.此时,TANMI值也大于0.5,绝大多数聚类成员(Number>500)与π∗的NMI值大于0.5,故MNMI也大于0.5.因此,根据TANMI和ANMI判定的结果都是聚类集体稳定.然而,当半数以下的聚类成员之间的NMI值大于0.5时,聚类集体的差异性相对较高,聚类集体不稳定.此时,TANMI值也小于0.5,但仍然有绝大多数聚类成员(Number>500)与π∗的NMI值大于0.5,故MNMI仍然大于0.5.因此,根据TANMI判定的结果是聚类集体不稳定,而根据ANMI判定的结果依然是聚类集体稳定.
综上,由于IACES依据TANMI判定聚类集体稳定性,只客观地依赖于聚类集体本身的特性,因此能够准确判定其稳定性;而由于ACES依据MNMI判定聚类集体稳定性,与初始一致划分π∗有关,因此会将某些不稳定的聚类集体误判为稳定.
3.2.2 聚类成员选择方法对比
1)分别根据ACES和IACES选择聚类成员并进行集成获得的结果对比.
图2和图3分别显示了采用聚类集体P1和P2时根据ACES和IACES选择聚类成员,并采用CSPA,AL,SC,KM++进行集成获得的NMI值和F值,其中Average统计了8种算法(以“聚类成员选择方法_共识函数设计方法”命名)在13组数据集上的平均结果.
根据图2,分别比较不同共识函数根据ACES和IACES选择聚类成员并进行集成获得的NMI值和F值,可以发现:
a)对于聚类集体不稳定的2种情况(hitech和ng3),IACES_CSPA,IACES_AL,IACES_SC和IACES_KM++获得的NMI值和F值都分别高于ACES_CSPA,ACES_AL,ACES_SC和ACES_KM++.
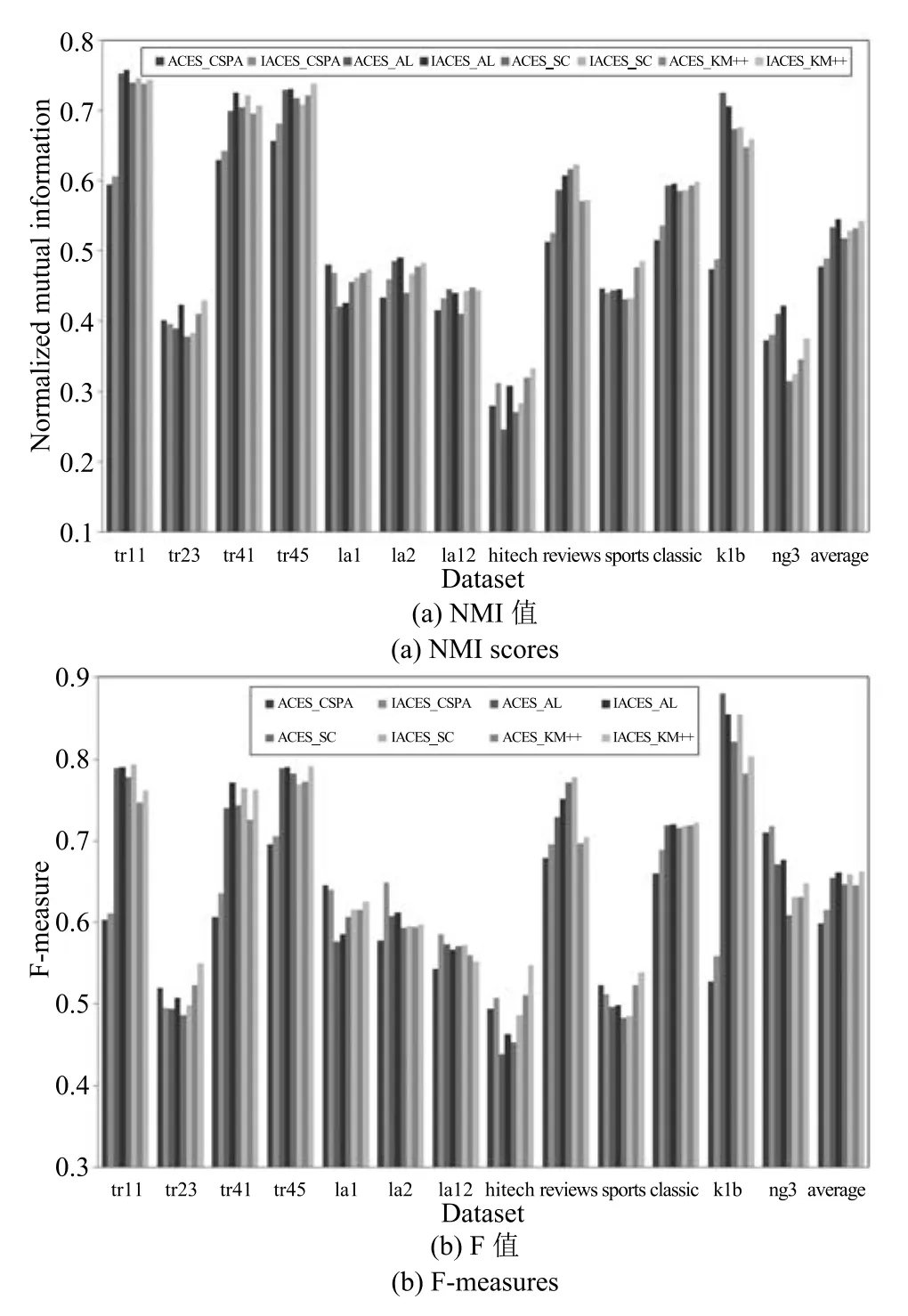
图2 采用聚类集体P1时获得的聚类结果(NMI值和F值)Fig.2 Clustering results obtained when using cluster ensembleP1(NMI scores and F measures)
b)对于其他11种聚类集体稳定的情况,IACES_CSPA仅在tr23,la1,sports上获得了比ACES_CSPA低的NMI值和F值,而在其他8组数据集上都获得了高于ACES_CSPA的NMI值和F值;IACES-AL仅在la12和k1b上获得了比ACES_AL低的NMI值和F值,而在其他9组数据集上都获得了高于ACES_AL的NMI值和F值;IACES_SC仅在tr45上获得了比ACES_SC低的NMI值,而在其他10组数据集上都获得了高于ACES_SC的NMI值,IACES_SC仅在tr45和k1b上获得了比ACES_SC低的F值,而在其他9组数据集上都获得了高于ACES_SC的F值;IACES_KM++仅在la12上获得了比ACES_KM++低的NMI值和F值,而在其他10组数据集上都获得了高于ACES_KM++的NMI值和F值.
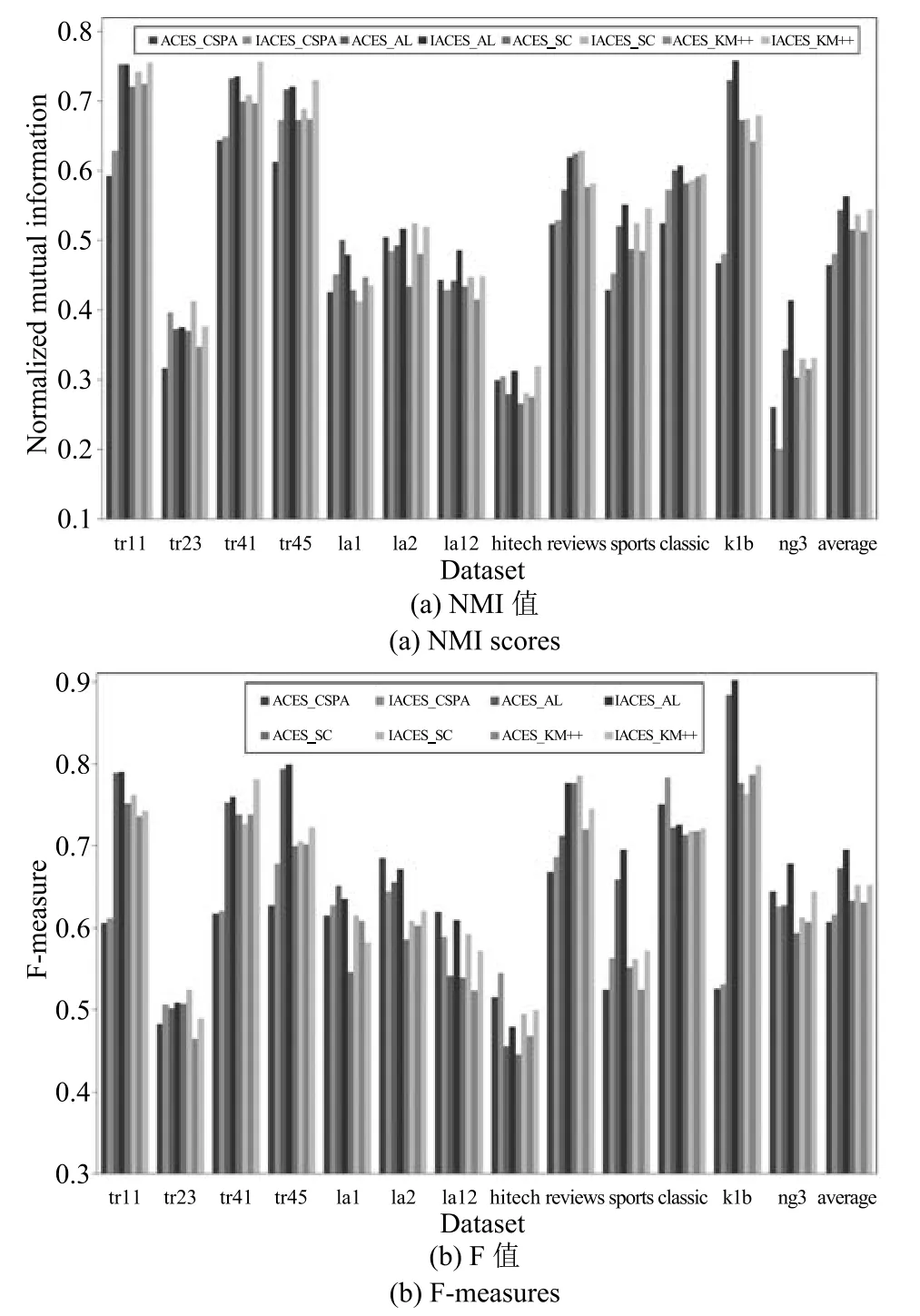
图3 采用聚类集体P2时获得的聚类结果(NMI值和F值)Fig.3 Clustering results obtained when using cluster ensembleP2(NMI scores and F measures)
c)总体来看,当采用聚类集体P1时,与ACES相比,采用IACES进行成员选择,CSPA分别以10/13和10/13的比例提高了NMI值和F值;AL分别以11/13和11/13的比例提高了NMI值和F值;SC分别以12/13和11/13的比例提高了NMI值和F值;KM++分别以12/13和12/13的比例提高了NMI值和F值;CSPA,AL,SC,KM++获得的平均NMI值和F值都有不同程度的提高.
根据图3,分别比较不同共识函数根据ACES和IACES选择聚类成员并进行集成获得的NMI值和F值,可以发现:
a)对于聚类集体不稳定的4种情况(la2,la12,hitech和ng3),IACES_CSPA在la2,la12和ng3上获得的NMI值和F值低于IACES_CSPA,在hitech上获得了比ACES_CSPA高的NMI和F值;IACES_AL,IACES_SC和IACES_KM++获得的NMI值和F值都分别高于ACES_AL,ACES_SC和ACES_KM++.
b)对于其他7种聚类集体稳定的情况,IACES_CSPA在所有7组数据集上都获得了高于ACES_CSPA的NMI值和F值;IACES_AL仅在tr11和la1上获得了比ACES_AL低的NMI值,而在其他5组数据集上都获得了高于ACES_AL的NMI值,IACES_AL仅在la1上获得了比ACES_AL低的F值,而在其他6组数据集上都获得了高于ACES_AL的F值;IACES_SC仅在la1上获得了比ACES_SC低的NMI值,而在其他6组数据集上都获得了高于ACES_SC的NMI值,IACES_SC仅在tr41上获得了比ACES_SC低的F值,而在其他6组数据集上都获得了高于ACES_SC的F值;IACES_KM++仅在la1上获得了比ACES_KM++低的NMI值和F值,而在其他6组数据集上都获得了高于ACES_KM++的NMI值和F值.
c)总体来看,当采用聚类集体P2时,与ACES相比,采用IACES进行成员选择,CSPA分别以10/13和10/13的比例提高了NMI值和F值;AL分别以11/13和12/13的比例提高了NMI值和F值;SC分别以12/13和11/13的比例提高了NMI值和F值;KM++分别以12/13和12/13的比例提高了NMI值和F值;CSPA,AL,SC,KM++获得的平均NMI值和F值都有不同程度的提高.
综上,与ACES相比,根据IACES选择聚类成员进行CSPA,AL,SC和KM++集成在绝大部分情况下都获得了更高的NMI值和F值,每个共识函数设计方法在所有数据集上获得的平均NMI值和F值都更高.
2)聚类成员选择方法CAS,ACES,IACES综合比较
本文实验中聚类集体大小为1000,CAS分别选择s=50,100,150,200,250个聚类成员,每个s对应一种聚类成员选择方法,例如CAS(s=50)表示根据CAS选择50个聚类成员.图4和图5分别显示了当采用聚类集体P1和P2时,根据CAS,ACES和IACES选择聚类成员并采用CSPA,AL,SC,KM++进行集成获得的NMI值和F值的平均值(例如,图4中的IACES表示4个聚类集成算法IACES_CSPA,IACES_AL,IACES_SC,IACES_KM++获得的NMI值的平均值),其中Total average统计了7种不同聚成员选择方法在13组数据集上的平均结果.
由图4和图5可见:
a)IACES在每个数据集上获得的NMI值和F值的平均值都高于ACES和CAS.
b)ACES在某些数据集上获得的NMI值和F值的平均值低于CAS(例如图4中的tr23和ng3),但在绝大部分情况下都高于CAS.
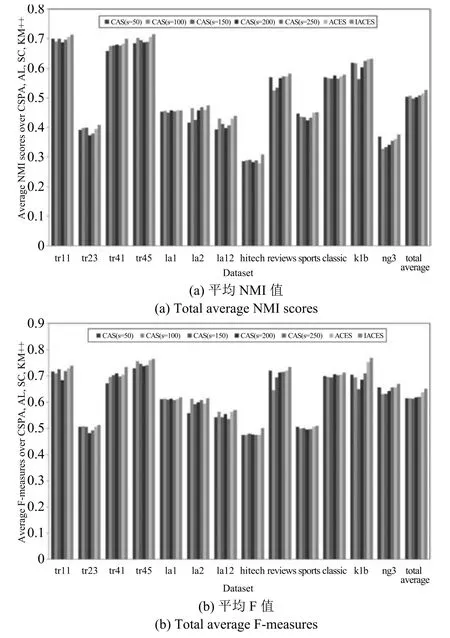
图4 当采用聚类集体P1时获得的聚类结果(平均NMI值和平均F值)Fig.4 Clustering results obtained by combining cluster members selected by ACES and IACES via CSPA,AL,SC and KM++when using cluster ensembleP1(Total average NMI scores and total average F measures)
c)总体来看,IACES在所有数据集上获得了最高的平均结果,ACES次之,即自适应聚类成员选择方法ACES优于CAS方法,而本文的方法则比ACES更加优越.
4 结论
本文提出了一种改进的自适应聚类集成选择方法(IACES),有效解决了ACES存在的聚类集体稳定性判定方法不客观和聚类成员选择方法不够合理的问题.在多组基准数据集上进行了实验,实验结果表明:1)IACES能够准确判定聚类集体的稳定性,而ACES会将某些不稳定的聚类集体误判为稳定;2)与其他聚类成员选择方法相比,根据IACES选择聚类成员进行集成在绝大部分情况下都获得了更佳的聚类结果,在所有数据集上都获得了更优的平均聚类结果.
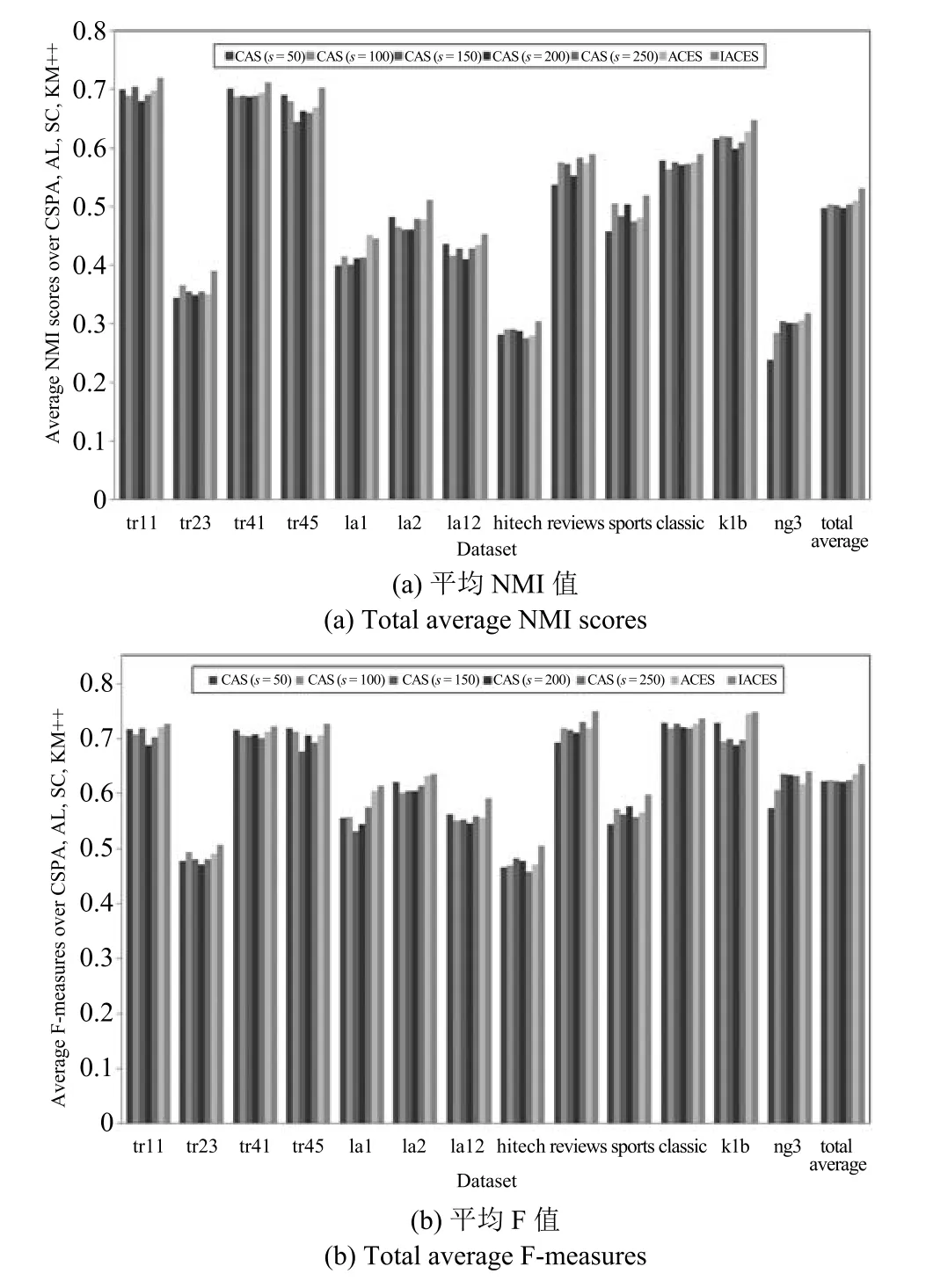
图5 当采用聚类集体P1时获得的聚类结果(平均NMI值和平均F值)Fig.5 Clustering results obtained by combining cluster members selected by ACES and IACES via CSPA,AL,SC and KM++when using cluster ensembleP1(Total average NMI scores and total average F measures)
猜你喜欢
少先队活动(2022年4期)2022-06-06
四川大学学报(自然科学版)(2021年6期)2021-12-27
铁道通信信号(2019年6期)2019-10-08
唐山师范学院学报(2018年6期)2018-12-25
学苑创造·A版(2017年12期)2018-01-17
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
爆笑show(2015年11期)2015-12-17
文苑(2015年9期)2015-09-10
