
基于分层注意力机制的神经网络垃圾评论检测模型
2018-12-14 05:26刘雨心
计算机应用 2018年11期
刘雨心,王 莉,张 昊
(1.太原理工大学 信息与计算机学院, 山西 晋中 030600; 2.太原理工大学 大数据学院, 山西 晋中 030600)(*通信作者电子邮箱591085595@qq.com)
0 引言
随着互联网的发展,人们越来越喜欢在网上发表自己的观点,并与其他网络用户分享他们的观点。 2016年,美国Yelp评论网站的评论超过108万(https://www.yelp.com/about),每年评论数量增加超过18万, 然而,虚假评论约占Yelp总评论的14%~20%,占Tripadvisor、Orbitz、Priceline和Expedia总评论的2%~6%。2011年美国Cone Communication的调查报告(http://www.conecomm.com/contentmgr/showdetails.php/id/4008)显示,64%的用户通过阅读相关评论获得产品信息,87%的用户在阅读肯定评论后购买了此产品,80%的用户在阅读否定评论后放弃购买,这充分说明评论对用户的购买决策起到举足轻重的作用,积极的评论可以提高产品口碑和品牌信誉进而提高商家的利润和声誉,垃圾评论在这种背景下应用而生[1-2]。
垃圾评论是垃圾评论者为了误导潜在客户,精心虚构的虚假评论[3-4],是商家或用户在个人利益驱使下亲自雇佣水军恶意发布的虚假评论。用户撰写评论的质量受各种因素的影响,如用户的文化背景和用户撰写评论时的情绪。本文垃圾评论不指用户的否定评论,即否定的低质量的评论不一定是垃圾评论。事实上,为了隐藏自己的身份并误导用户,垃圾评论者通常会确保评论的质量,以提高垃圾评论的影响。下面是两条来自公开垃圾评论数据集的评论。
1)如果你在芝加哥,艾尔雷格洛酒店对你来说是完美的。它位于市中心,有时尚的房间和细心的员工。我在酒店住了3个晚上,对一切都很满意。床很舒服,有很多蓬松的枕头,大的平板电视,收音机和iPad坞站和浴室是干净的。我接触的每个人都非常友好并乐于助人。我在那里的最后一天,我订了房间服务,不仅我的饭菜美味,并按时交付,厨房还打来电话,询问一切是否都好。我从来没有这样的跟进服务。
2)我在芝加哥希尔顿酒店逗留期间一直很不愉快。你怎么会这样问?好吧,我告诉你,那里的毛巾很脏没有消毒,服务也很糟糕,最糟糕的是,我登记的时候,他们甚至不在桌子上。另外,我从酒店订购了早餐、午餐和晚餐,但我收到的是错误的订单。所有的饭菜,吃完后想吐的感觉。最后,我还为我不想要的东西支付了账单。总的来说,这个酒店对我来说都是非常糟糕和不愉快的。我给它半星的评价。
第1)条不是垃圾评论,即来自顾客的真实的评论;第2)条是垃圾评论,来自土耳其人编写的虚假评论。从上面两条评论可以看出,靠人工从真实的评论中区分垃圾评论是很困难的。在以前的研究中,研究人员邀请三名志愿者识别160条垃圾评论,而志愿者误将垃圾评论判为真实评论,识别准确率仅为53.1%~61.9%[5],这个结果同样表明垃圾评论不易识别,这导致标注数据不足和难以评价检测结果的困境。因此,垃圾评论检测是一项紧迫必而必要的任务。
用户评论通常是短文本,垃圾评论检测是一个二分类问题, 该任务的目标是区分一条评论是否为垃圾评论。现有方法主要遵循文献[6]的工作,采用机器学习的方法来构建分类器,特征工程在这个方向很重要。大部分研究主要集中在从语言学和心理学的角度设计有效的特征以提高分类性能,尽管这些特征表现出强大的性能,但评论的离散型和稀疏性使得研究者们从语篇角度出发,挖掘评论的潜在语义信息变得异常困难。
近年来,在自然语言处理领域,神经网络模型取得了较好成果。基于其良好的性能,一些研究采用神经网络模型来学习文档表示,从而实现从语义的角度检测垃圾评论。例如,Ren等[7]建立了一个门递归神经网络模型来学习文档表示,虽然取得了较好的效果,但准确率仍有待提高。
基于以上研究,本文提出一种基于层次注意力的神经网络(Hierarchical Attention-based Neural Network, HANN)垃圾评论检测模型, 该模型主要由两部分组成:Word2Sent 层 (见2.1节),在词向量表示的基础上,采用卷积神经网络(Convolutional Neural Network, CNN)[8]生成连续的句子表示;Sent2Doc 层(见2.2节),基于上一层产生的句子表示,使用注意力池化的神经网络生成文档表示,生成的文档表示直接作为垃圾评论的最终特征,采用softmax分类器分类。本文的贡献主要包括以下3个方面:
1)创新性地提出HANN模型来区分垃圾评论与真实评论,所提模型不需要外部模块,采用端到端的方式进行训练。
2)HANN模型完整地保留了用户评论的位置和强度特征,并从中提取重要的和综合的信息,包括文档中任何位置的历史、未来和局部上下文,从而挖掘用户评论的潜在语义信息。
3)实验结果表明,与Li等[9-10]的方法相比,本文方法准确率平均提高5%,在最好的情况下,准确率高达90.9%,比Li等的方法高出15%,分类效果显著改善。
1 相关工作
与其他类型的垃圾检测,如邮件垃圾[11]、网页垃圾[12-13]等相比,由于用户评论具有数量大、噪声多、更新快、主观性高和针对性强等特点,使得用户垃圾评论检测更困难,所以先进的各种垃圾检测方法不能直接用于用户垃圾评论检测。垃圾评论检测被认为是自然语言处理(Natural Language Processing, NLP)领域的一个复杂问题。
2008年,Jindal等[6]首次提出了垃圾评论这个问题,采用评论内容、评论者和商品本身的特征来训练模型。Jindal等将垃圾评论分为3类,即虚假(负面)评论、仅讨论品牌而非产品的评论以及不存在评论(如广告)的评论,第一类危害性最大也最难识别[3]。
研究者提出许多垃圾评论检测的方法[14-15]。大多数研究表明,垃圾评论与真实评论在情感、语言、写作风格、主观性和可读性方面不同[16-19]。大多数方法在Ott等[5]最初介绍的合成数据集上进行; 但是,文献[20-21]采用相同的方法分别在合成的和真实的数据集上实验,发现合成的数据集是有缺陷的。因为它们没有如实反映真实的垃圾评论,且合成数据集的技术存在问题。
Yoo等[22]收集了42个虚假的和40个真实的酒店评论,并手动比较了他们的语言差异。Ott等[23]通过雇佣土耳其人撰写虚假评论来创建数据集,后续研究大都在这个数据集上进行。最近,Li等[9]在Ott等工作的基础上发展了一个范围广泛的黄金标准垃圾评论数据集,这个数据集通过众包和领域专家生成,包括3个领域(“酒店”“餐馆”和“医院”),由于此数据集数据量大、覆盖性广,所以本文实验采用这个数据集。
许多方法已经证明,关注评论的上下文相似性是有益的,在这些方法中,重复和近似重复的评论被认为是垃圾评论。Lau等认为垃圾评论者不仅发布虚假评论,而且会以不同的身份复制这些评论作为不同品牌或同一品牌的多种产品的评论,因此,内容相似性比较是研究人员众所周知的技术[16, 24]。
Heydari等[25]提出了一个垃圾评论检测系统,评论者的积极性、评价行为和评论的上下文相似性这些特征被综合考虑。从评论的时间序列角度出发,在可疑时间间隔内采用模式识别技术,捕捉垃圾评论; Ahsan等[26]通过使用评论内容的词频-逆文本频率指数(Term Frequency-Inverse Document Frequency, TF-IDF)特征引入主动学习方法来检测垃圾评论;Zhang等[27]提出一种基于熵和协同训练算法的CoFea方法,在无标签数据上,采用熵值对所有词汇进行排序,提出两种策略,即CoFea-T和CoFea-S,对比这两种策略后发现CoFea-T策略准确率更高,而CoFea-S策略时间开销少。其他研究也有采用评论内容本身之外的特征,例如,何珑[28]提出基于随机森林的垃圾评论检测方法,即对样本中的大、小类有放回地重复抽取同样数量样本或者给大、小类总体样本赋予同样的权重以建立随机森林模型,解决只考虑评论特征的选取,忽略了评论数据集不平衡性的问题; Wang等[29]提出了一种松散的垃圾评论者群体检测技术,该技术采用双向图投影。
以上研究取得了较好的成果,但都表现出一个共同问题:依赖人工设计的、基于特定任务的语言和心理特征,未从文档语篇的角度有效挖掘用户评论的潜在语义信息。本文提出HANN模型,从语篇的角度有效提取文档连续的语义信息,并从中获取重要的和综合的信息,从而提高垃圾评论识别准确率。
2 虚假垃圾评论检测方法
用户评论具有层次结构(单词形成句子,句子形成文档)[30]。另外,文档中的不同词和句子具有不同的信息量和不同程度的重要性。基于此,本文构建了一个分层注意力神经网络模型来学习文档表示。图1描述了模型的结构,主要由两部分组成: Word2Sent 层(见2.1节),基于词向量的表示;Sent2Doc 层(见2.2节),基于上一层产生的句子表示。生成的文档表示直接作为垃圾评论的最终特征,采用softmax分类器分类用户评论。
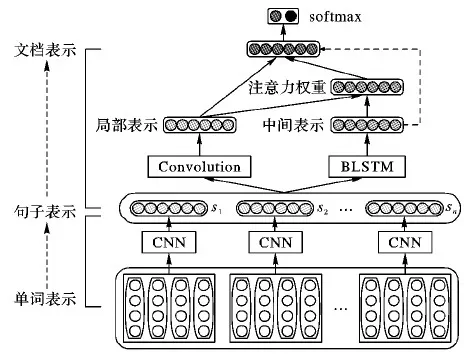
图1 基于层次注意力机制的神经网络垃圾评论检测模型
2.1 词到句子的表示(Word2Sent layer)
卷积神经网络(CNN)是建模句子语义表示最先进的方法[31]。CNN不依赖于外部解析树[31-32],可用于学习句子的连续表示。卷积操作已被广泛用于合成N-gram信息[33]。N-gram对许多自然语言处理任务(NLP)有用[18, 34],本文将N-gram应用于HANN模型。如图2所示,使用3个卷积滤波器生成句子表示,因为它们可以捕捉不同粒度的N-gram局部语义信息,包括unigrams、bigrams和trigrams。N-gram在一些NLP任务中很强大,比如情感分类[35]。HANN模型使用3个宽度(width)分别为2、3和4的卷积滤波器。
正式的定义由n个词组成的句子为(w1,w2, …,wi,…,wn)。每个词wi映射用一个词向量e(wi)∈RL表示,卷积滤波器是具有共享参数的线性层列表。L1、L2、L3表示3个卷积滤波器的宽度。
以L1为例,W1和b1是该滤波器线性层的共享参数。线性层的输入是在固定长度窗口L1中的词向量表示(word embedding)的连接,表示为I1,i=[e(wi);e(wi+1);…;e(wi+L1-1)]∈RL×L1。
线性层的输出为:
H1,i=W1·I1,i+b1
(1)
其中:W1∈Rloc×L×L1,loc是线性层的输出大小。将它提供给一个平均池化层,产生一个固定长度的输出向量:
(2)
进一步添加一个激活函数tanh以合并非线性,滤波器O1的输出如下:
O1=tanh(H1)
(3)
类似的,分别得到宽度为2和3的其他两个卷积滤波器O2、O3的输出。为了捕捉句子的全局语义信息,用3个滤波器的平均输出作为句子的最终输出S。
S=(O1+O2+O3)/3
(4)
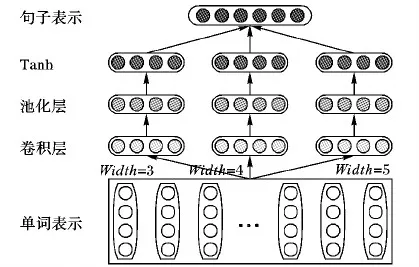
图2 词到句子的模型
2.2 句子到文档的表示(Sent2Doc layer)
有各种文档表示的方法,如:平均所有的句子表示作为文档的表示,但这种方法不能有效捕捉句子间的语义信息。CNN采用线性层的共享参数来建模局部句子关系,但CNN不能直接对长范围的语篇结构建模,而这对一个文档的表示非常重要。基于上层生成的句子表示,Sent2Doc层采用注意力池化的CNN[8]和双向长短时记忆(Bidirectional Long-Short Term Memory, BLSTM)[36]模型的组合,实现从语篇的角度提取文档重要的和综合的语义信息。
CNN是一个功能强大的语义合成模型,卷积操作可以独立地捕获包含在文档中任何位置的信息,但不能捕捉文档长范围的语篇结构,如图1所示,卷积滤波器只能对上层产生的文档矩阵执行卷积操作,产生局部表示(Local Representation),再将这个局部表示通过注意力权重(Attention Weight)集成到最终的文档表示中。而注意力权重是通过对比局部表示与BLSTM生成的中间句子表示(Intermediate Representation)、在训练阶段进行优化而获得的。生成的文档表示作为最终的特征向量输入到顶层softmax分类器。在测试阶段,中间句子表示也作为softmax分类器的输入,如图1中的虚线所示。
在HANN模型中,卷积操作是在k个滤波器wc∈Rmd×k和一个连接向量xi:i+m-1之间进行的,xi:i+m-1表示从第i个句子开始的m个句子的窗口。每个滤波器的参数在所有窗口中共享。使用具有不同初始化权重的多个滤波器来提高模型的学习能力。通过交叉验证决定滤波器的数量k。卷积运算由ci控制:
ci=g(WcTxi:i+m-1+bc)∈Rk
(5)
其中:xi∈Rd,bc是一个偏向量,g(·)是一个非线性激活函数。本文采用LeakyReLU[37]非线性激活函数,与ReLU相比,LeakyReLU有助于提高学习效率,并且在单元处于非活动状态时允许小的梯度消失。
假定文档的长度为T,当句子窗口滑动时,卷积层的特征映射表示如下:
c=[c1,c2,…,cT]∈RK×T
(6)
卷积层的输出作为文档的局部表示,每个元素ci都是相应位置的局部表示。
中间文档表示由BLSTM生成。BLSTM是循环神经网络的变体,通过用门控记忆单元代替循环神经网络的隐藏状态,解决LSTM的“梯度消失”问题;此外,还可以学习文档任何位置的历史和未来的信息。BLSTM架构与其他组件一起训练。在训练阶段,损失函数的梯度通过中间文档表示反向传播来优化。
通过对比由卷积操作生成的局部表示与由BLSTM生成的中间文档表示来计算注意力权重。为了对比这两种表示,应把局部表示和文档的中间表示映射到同一维空间,本文通过控制BLSTM的输出维度与卷积过滤器的数量相同达到这个目的。
(7)
其中
(8)
术语ai是一个标量,函数sim(·)用于度量两个输入之间的相似度。本文采用余弦相似度。获得注意力权重后,最终的文档表示如下:
(9)
在识别垃圾评论和真实评论时,评论中的句子在语义表达中扮演着不同的角色,一些句子比另外一些句子更重要。本文中,每个句子的权重代表句子对整个文档含义的贡献,注意力可被视为获得所有句子标注的加权和来计算文档标注。这种方法借鉴了著名的注意力机制思想,将较大的权值赋给较重要的特征,从而提取文档包含的重要信息。
2.3 softmax分类器
文档表示d作为顶层分类器的输入。在模型的顶部添加线性转换层将文档表示转换为实值向量yc,softmax函数将实值向量转换为条件概率,计算如下:
(10)
为了避免过拟合,在模型的倒数第二层,使用掩码概率为p的dropout,dropout的关键思想是在训练阶段从神经网络中随机丢弃神经单位[38]。
(11)
其中,⊗是一个元素乘法运算符;q是dropout 率为p的掩码向量。在训练阶段实现输出权重Ws的l2范数约束。
(12)
其中:C是类别数,Si表示第i个句子。
卷积过滤器、BLSTM和softmax 分类器中的所有权重和偏置都由模型来决定。注意力权重在训练阶段优化。文献[39]的Adadelta更新规则是一种有效且高效的反向传播算法,本文采用此算法来优化模型。
3 实验结果和分析
在公开的垃圾评论数据集上评价了本文方法的性能,并将该方法与已有方法进行比较,进行了3种类型的实验,即领域内、跨领域和混合领域。
3.1 数据集和评价指标
本文采用Li等[9]发布的公开黄金标准垃圾评论数据集,其具体分布见表1。该数据集包含3个领域,即“酒店”“餐馆”和“医生”, 每个领域都有3种数据类型,分别是“顾客”“专家”和“土耳其人”。真实评论来自具有实际消费体验的“顾客”。垃圾评论由土耳其人和专家编辑,这些专家具有专家级的领域知识。

表1 三个领域的数据统计
本文采用准确率作为评价指标, 所有(顾客/土耳其人/专家)评论都被用于酒店领域中的分类。在餐馆和医生领域中,只有顾客/土耳其人评论被采用,因为专家评论有限。本文使用数据集的90%作为训练集,10%作为测试集。
3.2 Word embedding
本文采用Word2Vec工具来表示单词向量。用skip-gram和最大化所有词[40]的平均对数概率的方法,在包括1 000亿个不同单词的Google新闻数据集上训练。每个单词和短语都用300维向量表示,词向量矩阵相对较大(3.6 GB),但包含许多不必要的词。具体公式如下:
(13)
其中:c是上下文窗口大小,T表示文档的长度。词向量值包含在参数中,在训练过程中优化。
3.3 实验结果分析
3.3.1 领域内结果分析
领域内,根据Ren等[7]的实验设置进行了一组测试并与之对比,顾客/土耳其人/专家评论都用于酒店领域;对于餐馆和医生领域,只有顾客/土耳其人评论被采用,实验结果见表2。

表2 两种方法领域内结果
3.3.2 跨领域结果分析
在交叉领域进行两种类型的实验来验证本文模型的泛化能力和领域适应性。在第1个实验中,在一个领域上训练,分别在另外两个领域测试; 在第2个实验中,在两个领域训练,在剩下的领域测试。
本文通过在标注丰富的酒店领域数据集上训练模型,然后分别在餐馆和医生领域测试,从而评价本文模型的泛化能力和领域适应性。
从表3可以看出,Ren等的方法,在餐馆领域的测试准确率为83.5%,但在医生领域的测试准确率却降到57.0%。Li等[10]方法的准确率在餐馆和医生领域都不太好。本文方法的准确率都优于他们的方法。在餐馆领域,本文方法获得了最佳结果,准确率达到了87.5%; 在医生领域,准确率最高的是Li等[9]采用离散特征的传统方法。两个先进的神经网络模型的准确率低于Li等传统模型的准确率,而本文模型的准确率与之相近。
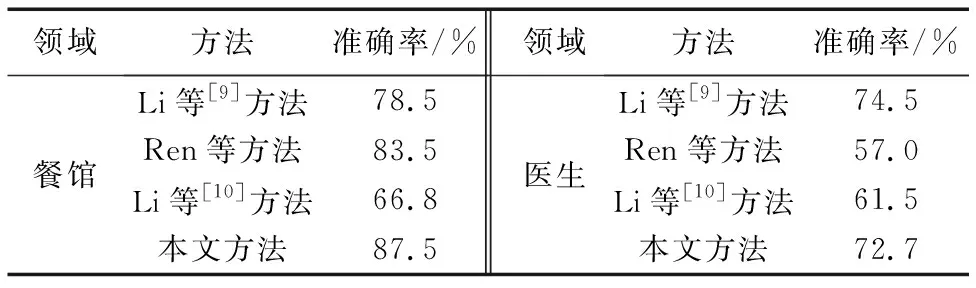
表3 四种方法跨领域结果(在酒店领域训练)
由于餐馆和酒店之间有许多相似属性,如环境和位置,而医生领域与酒店的相似属性少一些,词汇差异也较大,这导致在酒店领域训练的模型,在医生领域的测试结果不如餐馆领域结果。这些结果与以往研究结果一致。
另外,本文第一次在两个领域上训练,在剩下的领域测试。例如,本文在医生和酒店两个领域训练,在餐馆领域测试。
表4显示,通过使用医生和酒店领域的两组数据进行训练,在餐馆领域的测试准确率为77.5%。当只采用酒店领域的数据用于训练时,在餐馆领域的测试准确率提高了大约10个百分点,因为餐馆领域和酒店领域有许多相似属性,但与医生领域的相似属性较少,所以通过在训练过程中添加医生领域的数据,在餐馆领域的测试准确率不会提高反而降低,这充分验证了不同的主题在评论中具有不同程度的重要性。例如,健康信息通常可以成为餐馆评论的强大特征,因此,再次验证了本文采用注意力机制方法来挖掘评论中的重要信息是可取的。
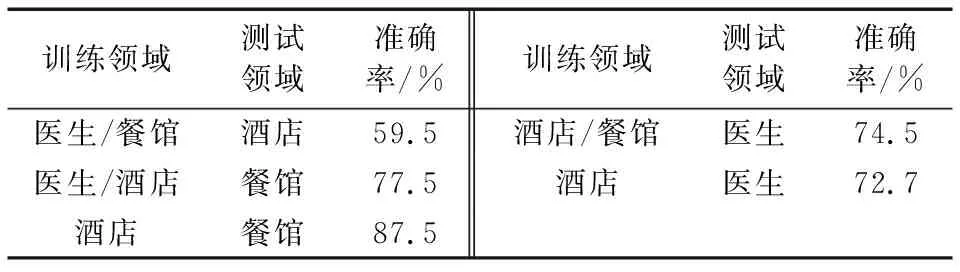
表4 本文方法跨领域结果
而当采用酒店和餐馆领域的两个数据集训练时,医生领域的评价准确率为74.5%,但是,如果只采用酒店领域数据训练,则在医生领域的准确率降低2%。这表明,当训练领域的数据集极性与目标评价领域相似度较低时,使用大量训练数据集可以提高目标领域的评价精度。
3.3.3 混合领域结果分析
在混合领域,与Li等[10]的方法进行了比较,其采用来自土耳其人和专家的所有虚假评论以及顾客的真实评论。同样为了和Li等的方法对比,本文实验设置与他们的方法一致。
Li等的方法包括段落均值(paragraph-average)、加权平均(weight-average)、句子卷积神经网络(Sentence Convolutional Neural Network, SCNN)、句子加权神经网络(Sentence-Weighted Neural Network, SWNN)以及这些方法和特征的组合。SCNN是一个基本的文档表示学习模型,由两个卷积操作组成: 句子卷积通过一个固定长度的窗口为每个句子创建一个组合; 文档卷积把句子向量转换为文档向量。SWNN是SCNN的变体。Li等采用KL(Kullback-Leibler)散度作为一个词的重要性权重来计算一个句子的权重。
本文采用所有句子标注的加权和来计算文档标注。句子的权重衡量句子对整个文档含义的贡献,评论中的不同句子在文档的语义表示中扮演着不同的角色。从真实的评论中区分垃圾评论时,一些句子比另一些句子更重要,因此,当一个句子对整个文档的含义贡献较大时,给它分配较大的权重。
表5显示本文模型在混合领域取得了最好的结果,其准确率明显高于其他神经网络。SWNN模型的准确率为80.1%,SWNN+特征2的准确率为82.2%。在垃圾评论检测中,POS(Part-Of-Speech)[9]和“第一人称”是强大的特征, 特征1指POS特征,特征2指POS+“第一人称”。因此,可大胆地假设:如果将这两个特征与本文模型结合,那么准确率将比对比模型的准确率高出更多。

表5 各方法混合领域结果
3.3.4 参数分析
在实验中,本文研究了3个参数的影响,即句子窗口大小、学习率和句子级卷积过滤器的数量。实验结果表明当句子窗口大小设置为2、3和4,学习率为0.5,Word2Doc卷积滤波器数量为100时,准确率最高。
4 结语
一种新的基于分层的注意力机制的神经网络被成功地用于垃圾评论检测。通过使用层次注意力机制,使评论的位置和强度信息被完整地保留下来。Word2Sent和Sent2Doc的组合使本文模型能从保存的特征中提取重要的和全面的信息,挖掘用户评论的潜在语义信息,从而提高垃圾评论识别准确率。本文方法分别在领域内、跨领域和混合领域三个领域上进行了检测对比实验。本文方法准确率比Li等[9-10]的方法准确率平均提高5%,最好的情况下,准确率高达90.9%,比Li等的方法高出15%,总体来说,本文方法的准确率更高,泛化能力更强。
将来,将进一步考虑把从垃圾评论中提取的语言学和心理学特征作为先验知识加入到本文所提出的模型中,以充分利用两者的优势达到增强分类效果的目的; 另一方面,可以将这个新模型扩展到其他NLP任务,如情感分析[4],甚至计算机视觉和图像识别等领域。
猜你喜欢
客联(2022年3期)2022-05-31
北京航空航天大学学报(2021年9期)2021-11-02
中国新闻周刊(2021年26期)2021-07-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
