
基于CNN模型的遥感图像复杂场景分类
2018-12-20 11:03张康黑保琴李盛阳邵雨阳
自然资源遥感 2018年4期
张康, 黑保琴, 李盛阳, 邵雨阳
(1.中国科学院空间应用工程与技术中心,北京 100094;2.中国科学院太空应用重点实验室,北京 100094;3.中国科学院大学,北京 100049)
0 引言
随着对地观测技术的迅速发展,遥感图像的数据量显著增加,大量堆积的遥感图像中所蕴含的有价值信息亟待充分挖掘和利用。遥感图像的复杂场景识别和分类是提取并分析这些信息的重要内容之一,它能够广泛应用于土地利用[1]、全球环境污染监测[2]和军事领域目标检测[3]等方面,具有重要的理论意义和实践价值[4]。传统的遥感图像场景分类方法,例如贝叶斯模型和k-均值[5]等方法,都有一定的应用限制,通常要求样本足够大并且样本数据服从正态分布,才能得到较为理想的分类结果[6]。此外,虽然之后的支持向量机(support vector machine,SVM)方法在遥感图像识别与分类任务中取得了较优的效果[7-8],但其本质上属于浅层的结构模型,计算单元有限,难以有效地表达复杂函数,对于复杂的分类问题其泛化能力仍不足[9-10]。
为了克服浅层学习模型以及人工提取特征所带来的问题,Hinton等[11]于2006年提出了深度学习的概念。以卷积神经网络(convolutional neural net-work,CNN)为代表的深度学习方法,主要是用于识别二维形状而特别设计的一种多层感知器。CNN模型的卷积层可以实现自动化的图像特征提取,从而避免过多的人为干涉,同时其局部连接、权值共享等技术能够有效地减少网络参数,从而降低网络模型的计算量并提升模型的泛化能力[9]。目前,利用CNN模型在遥感图像领域已经取得了一定的研究成果,例如行人检测[12]、火灾识别[13]、船舰检测[14]等领域,但是对于遥感图像的复杂场景分类应用仍然较少。本文提出了一种基于CNN模型的遥感图像复杂场景分类方法,并在UC Merced Land Use和Google of SIRI-WHU这2组数据集中进行实验。由于上述2组通用数据集的样本量不是很大,为了提高小样本数据下的分类精度,本文采用对CNN中典型的AlexNet[15]模型进行预训练的方法来提取多尺度图像特征;为了使模型适应不同大小的遥感图像,模型前增加了预处理模块,该模块通过改变步长和随机裁剪尺寸的方式来获取最大图像输入,从而保证了滤波器的不变性,有利于特征提取;为了横向比较分类器的选择问题,在模型中采用了Softmax和SVM这2种分类器。
1 遥感图像复杂场景分类的CNN模型
遥感图像场景分类的核心在于图像特征的有效提取。相比于传统的特征提取方法(例如局部二值模式、尺度不变特征变换、梯度方向直方图和Gabor滤波器等方法),CNN具有旋转、平移、缩放不变性,并能够提取更加丰富的高层特征信息,充分地降低图像低层视觉特征与高层语义之间的“鸿沟”[16]。
基于CNN模型的遥感图像复杂场景分类的总体流程如图1所示。
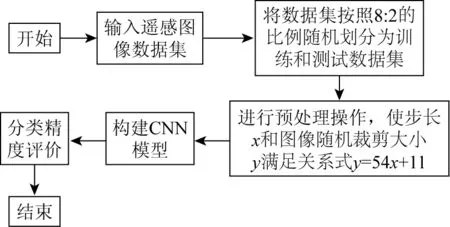
图1 基于CNN模型的遥感图像场景分类总体流程
本文构建了一个用于遥感图像复杂场景分类的CNN模型框架,如图2所示。该框架包括5个卷积层(C1—C5),3个池化层(S1—S3),以及一个由全连接层fc6,fc7和Softmax组成的神经网络。其中采用ReLu(rectified linear units)函数作为神经元的激活函数,以解决使用传统的Sigmoid及Tanh等激活函数易出现梯度弥散等问题。
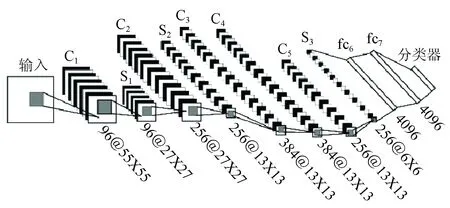
图2 遥感图像场景分类的CNN框架
图2中的Ci层为卷积层,相当于一个滤波器,该层的输入特征与卷积核进行卷积操作,然后通过一个激活函数就可以计算出输出特征。卷积层的计算公式为
(1)
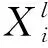
Si层为池化层,又称下采样层,主要用于将特征映射为一个平面。如公式(2)所示,它对公式(1)的计算结果进行下采样操作,并且加上权重和偏置项,最后通过激活函数获得了一个缩小的特征映射图,该操作能够减少网络模型参数,从而降低网络复杂性,提高网络的泛化能力,即
(2)
然后将最后一个特征图(S3)进行光栅化操作,即将一系列的特征图像转换为神经网络所能接收的向量形式。fc6,fc7和Softmax是一个全连接的神经网络,主要是充当分类器的角色,用于对特征进行分类。
将CNN模型应用于UC Merced Land Use图像数据集和Google of SIRI-WHU图像数据集的具体过程如下:首先第一个卷积层使用96个11×11大小的卷积核对227×227的UC Merced Land Use图像数据集的场景图像进行步长为4的滤波操作,而对173×173的Google of SIRI-WHU图像数据集的场景图像进行步长为3的滤波操作,均生成96个55×55(计算过程:(227-11)/4+1=55和(173-11)/3+1=55)的特征图;然后对生成的特征图进行核大小为3、步长为2的Max-Pooling操作,产生96个27×27(计算过程:(55-3)/2+1=27)的特征图。第二个卷积层使用256个5×5的卷积核对27×27的特征图进行零填充大小为2、步长为1的滤波操作,产生256个27×27(计算过程:27+2×2-5+1=27)的特征图;然后对生成的特征图进行核大小为3、步长为2的Max-Pooling操作,产生256个13×13(计算过程:(27-3)/2+1=13)的特征图。第三个和第四个卷积层均使用384个3×3的卷积核对13×13的特征图进行零填充大小为1、步长为1的滤波操作,产生384个13×13(计算过程:13+2×1-3+1=13)的特征图。第五个卷积层使用256个3×3的卷积核对13×13的特征图进行零填充大小为1、步长为1的滤波操作,产生256个13×13(计算过程:13+2×1-3+1=13)的特征图;然后对生成的特征图进行核大小为3、步长为2的Max-Pooling操作,产生256个6×6(计算过程:(13-3)/2+1=6)的特征图。经过第一个全连接层,产生4 096个神经元,再将经过ReLu激活函数产生的神经元作为第二个全连接层的输入;第二个全连接层也产生4 096个神经元,同样将ReLu激活函数产生的神经元作为Softmax层的输入,对于UC Merced Land Use图像数据集,最终的输出结果即为21类的概率结果,对于Google of SIRI-WHU图像数据集的输出结果为12类的概率结果。
由于CNN训练需要大量的带有标签的样本数据,而实际中获取如此庞大的遥感图像场景分类的样本数据较为困难,成本也很高。因此,采用迁移学习[17]的方法,将目前世界上最大的图像识别数据库ImageNet[15]学习到的权重作为框架的初始权重,而不是随机确定初始化权重从头开始训练。该方法能有效地解决小样本数据训练模型易产生的过拟合问题,同时能够大大缩减模型训练的时间。CNN模型的训练和分类过程如图3所示。

图3 基于CNN的遥感图像场景分类方法
训练过程中,首先将带标签数据随机分为2类,作为测试数据集和训练数据集,训练数据集输入CNN模型后,经过前向传播(feed forward, FF)得到模型输出,再计算模型输出和实际数据标签的误差,根据误差求导计算梯度,通过反向传播(back propagation, BP)更新网络,如此往复便可训练出优化的CNN模型。在对模型训练的过程中,引入了镜像和随机裁剪方法(通过对每个图像进行旋转,然后随机选取位置裁剪n×n大小作为新的图像数据)来增加样本数据量,以避免过拟合现象。此外,在全连接层采用“dropout”技术随机使隐含层的某些节点的权重不工作,也能有效地防止过拟合,同时很大程度地降低模型的训练时间。在对测试数据集进行分类的过程中,使用基于CNN模型进行遥感图像复杂场景分类的2种策略:①使用Softmax分类器直接对测试集数据进行分类;②将Softmax替换为采用基于经典核函数径向基函数(radial basis function,RBF)的SVM分类器,然后使用SVM分类器对CNN模型fc7层的特征进行分类,从而代替CNN模型的输出层。
2 遥感图像场景分类实验
2.1 实验数据集的选取和处理
为了验证CNN模型分类方法的有效性,选用2组数据集进行实验,分别是包含21类场景的UC Merced Land Use图像数据集[18]和包含了12类场景的Google of SIRI-WHU图像数据集[19],如图4和图5所示。UC Merced Land Use数据集通过从美国地质调查局的国家地图城市图像中手工获取。该数据集的每类场景包含100幅256像素×256像素的图像,图像的空间分辨率为0.3 m;Google of SIRI-WHU数据集从Google Earth获取,主要覆盖中国的城市地区,由武汉大学的RS_IDEA团队设计建成。该数据集的每类场景包含200幅200像素×200像素的图像,图像的空间分辨率为2 m。在本文的2类实验中,每类场景随机选取80%的图像作为训练数据集,剩余的图像作为测试数据集。

图5 Google of SIRI-WHU遥感图像数据集
对于本文所使用的网络模型来说,在图像输入前需要增加预处理模块,以适应不同的图像大小。首先设置模型中第一层的滤波器大小为11×11,卷积特征图C1大小为55。为了使模型在具有通用性的同时有利于特征提取,需要保证滤波器和特征图C1的大小不变。因此对于输入大小为a像素×a像素的图像,预处理模块要使步长x和图像随机裁剪大小y满足关系式y=54x+11(其中y为不大于a的最大值,从而尽可能保留更多图像信息)。所以第一个数据集UC Merced Land Use的图像大小为256像素×256像素,经过预处理模块后的输入为227像素×227像素的随机裁剪图像和步长值为4。Google of SIRI-WHU数据集的图像大小为200像素×200像素,经过预处理模块后的输入为173像素×173像素的随机裁剪图像和步长值为3。
然后设置2个数据集的训练参数如下:①UC Merced Land Use训练和测试数据集的批量处理大小分别为56和42,测试集迭代次数为10次(测试集数据量420/42),完整训练一次需要迭代30次(1 680/56),因此设置每迭代30次测试一次;②Google of SIRI-WHU训练和测试数据集的批量处理大小分别为64和48,测试集迭代次数为10次(测试集数据量480/48),完整训练一次需要迭代30次(1 920/64),因此仍然设置每迭代30次测试一次。
2.2 实验结果与分析
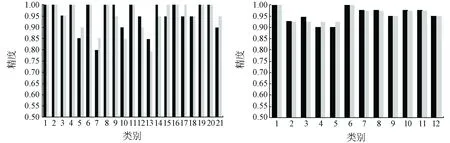
2组数据集的分类结果如图6所示。
(a) UC Merced Land Use数据集的分类结果 (b) Google of SIRI-WHU数据集的分类结果
本文采用CNN+Softmax算法和CNN+SVM算法对UC Merced Land Use和Google of SIRI-WHU2个数据集的遥感图像场景分类的混淆矩阵如图7所示。由图7可以得出以下结论:整体而言,如图6所示,Google of SIRI-WHU数据集的分类结果要优于UC Merced Land Use数据集。在Google of SIRI-WHU数据集中所有类别的分类精度都达到了90%以上,图7(c)和(d)中也可以看出2种算法对Google of SIRI-WHU数据集分类的各个类别之间的错分率不超过5%;而UC Merced Land Use数据集中的建筑(类别5)、稠密住宅区(类别7)、高尔夫球场(类别10)和中等住宅区(类别13)等场景的分类精度较差,只能达到80%左右。这主要是因为不同类间的相似性较大(例如UC Merced Land Use数据集中的建筑(buildings)、稠密住宅区(dense residential)和中等住宅区(medium residential)场景,如图8(a)所示),或者相同类之间的差异性大(例如高尔夫球场(golf course),如图8(b)所示)。这一问题根据图7(a)和(b)的混淆矩阵也可以看出。不论是Softmax还是SVM分类器,都能取得很好的分类效果。例如在第一个数据集中的中等住宅区类,使用CNN分类精度为85%,而使用CNN+SVM的分类精度为70%;然而在建筑类中,使用CNN的分类精度为85%,而使用CNN+SVM的分类精度为90%;在第二个数据集中,CNN和CNN+SVM的方法对每类的分类精度基本相差不大。因此,Softmax和SVM分类器没有明显优劣之分,可以根据需求针对具体类别选择合适的分类器。尽管2组数据集的分类结果有所不同,同一数据集下不同类别的分类结果也有差别,但总体而言,分类精度还是较高的,基本能保持在90%以上。

图7 基于CNN模型的遥感图像场景分类的混淆矩阵

(a) 不同类间的相似性

(b) 相同类间的差异性
为了更好地比较本文提出方法的优势,针对于UC Merced Land Use数据集和Google of SIRI-WHU数据集,表1和表2列出了现有的几种其他方法的分类效果。
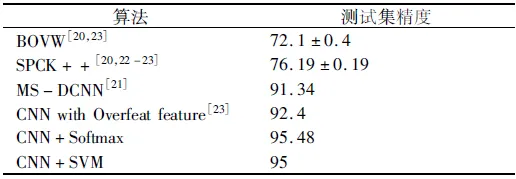
表1 不同算法UC Merced Land Use数据集的分类精度
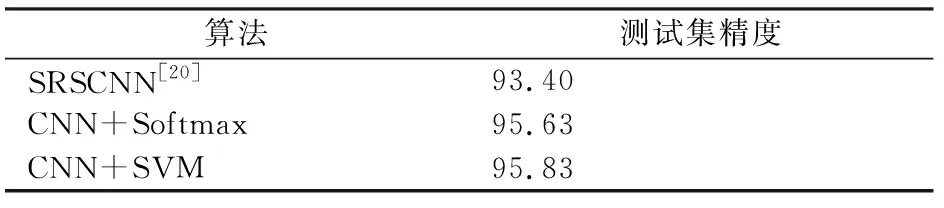
表2 不同算法Google of SIRI-WHU数据集的分类精度
从表1与表2中可以进一步得到以下结论:
1)利用本文提出的方法对UC Merced Land Use数据集进行分类,Softmax和SVM这2种分类器下的分类精度分别高达95.48%和95%,相比于现有的最优方法,精度分别提升了3.08%和2.6%;而对Google of SIRI-WHU数据集进行分类的精度也分别高达95.63%和95.83%,相比于现有的最优方法,分类精度分别提升了2.23%和2.43%,从而说明本文所提出的方法是十分有效的。
2)结合图6的各类别分类结果可以看出,Softmax和SVM分类器都能得到很好的分类结果,因此在使用CNN模型对遥感图像的场景分类中,可以根据自己需要是否使用SVM替换CNN的Softmax层。
上述分析说明了本文采用的CNN方法的有效性,而图9则展示了2组数据集中训练数据集的损失函数变化曲线和测试数据集的精度变化曲线,其中训练数据集的损失函数变化曲线能够反映出模型的输出结果与实际结果的误差,因此损失函数越小,说明该模型被训练得越好;测试数据集的精度变化曲线能够反映模型泛化能力的好坏,因此,测试数据集精度越高,说明该模型的泛化能力越好。
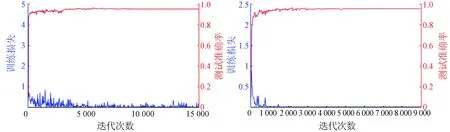
(a) UC Merced Land Use数据集 (b) Google of SIRI-WHU数据集
从图9中可以看出,UC Merced Land Use数据集通过约7 000次迭代后,数据分类精度趋于稳定,并保持在95%以上,而数据集的损失函数也降低至0.005左右,并保持稳定;Google of SIRI-WHU数据集通过约5 000次迭代后,数据分类精度趋于稳定,并保持在95%以上,同时数据集的损失函数也降低至0.000 1左右,并保持稳定。然而,第一组训练数据集的损失函数比第二组的值大,正如图8所描述的原因,第一组数据集中存在类间相似性大以及类内差异性大的数据。即使如此,2组测试数据集的精度都能取得很好的效果,由此可见使用迁移学习的方法在提高时间效率上也具有明显的优势,能有效地降低训练成本,同时仍然保持很好的分类效果。
3 结论
本文提出了一种基于CNN的遥感图像场景分类方法。通过从ImageNet数据集中迁移知识,利用CNN来训练自己的数据集,解决了小样本训练的问题,同时提高了时间效率;通过增加预处理模块,提升了模型的适应能力;最后以UC Merced Land Use数据集和Google of SIRI-WHU数据集的实验验证了该方法的有效性。实验结果与现有方法的比较表明,本文方法能够有效地提高遥感图像场景分类的精度。此外,还比较了该模型分别选择Softmax和SVM这2种分类器时的分类精度。2种分类器均能取得很好的分类结果,精度都达到95%以上。因此在使用该CNN模型进行遥感图像的场景分类时,可以选择SVM或Softmax分类器。在后继研究中,可以利用高光谱遥感图像,通过引入更多的光谱信息来替代目前的RGB三通道输入,从而实现对目标更加准确的识别与分类。
猜你喜欢
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中国惯性技术学报(2018年4期)2018-11-08
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
