
基于SEM算法的零一膨胀二项回归模型的研究*
2019-01-02 06:56吕敏红李文胜
计算机与数字工程 2018年12期
吕敏红 李 华 李文胜
(西安航空学院理学院 西安 710077)
1 引言
计数数据广泛存在于心理学、生物学、金融保险以及风险控制等领域,拟合计数数据的单用分布主要有泊松分布、二项分布等。但是在很多实际问题中零观测的比例远超过了拟合分布的允许范围。例如在医学研究中,室性早搏在用药后的PVC观测数据中,0出现的次数异常高,这样就使得室性早搏患者数的离差偏大。对于这些离差偏大的数据,运用单分布的结果往往不尽人意,所以我们便会考虑适合这类计数数据的零膨胀回归模型。自从Lambert提出了零膨胀Poisson回归模型[1]以来,关于具有零膨胀特征的计数数据已经有了多方面的研究,Greene(1994)在Lambert的思想下提出了零膨胀的可加性负二项回归模型[2],Lee对零膨胀泊松回归模型的检验问题进行了深入的研究[3];Xie系统研究了广义的Poisson混合效应模型的统计诊断问题[4];Ghosh研究了零膨胀回归的贝叶斯方法[5];陈异等关于零膨胀模型的实际应用做了研究[6~7]。
可是在一些实际问题时,我们遇到的数据集不仅在零点处膨胀而且在一点处也膨胀,例如Melkersson在对一组看牙医次数的数据进行研究时发现0和1出现的次数过高,这时如果还用零膨胀回归模型来做模拟,就会发现拟合的效果很不理想。为了考虑这类数据,Melkersson和Olsson首次提出了零一膨胀泊松分布[8],之后Guo-liang Tian等对零一膨胀泊松分布的性质进行了研究[9]。本文对零一膨胀二项回归模型建立了参数的极大似然估计,然后提出了SEM算法对传统的EM算法进行修正,避免了EM算法只能使得估计收敛到局部极大值这个缺陷,使得模型能够找到全局最优解。最后通过模拟研究说明该方法的有效性。
2 零一膨胀二项回归模型
零一膨胀模型是处理零点与一点过多的计数模型,计数数据中取值为0与1的部分与取值服从某些离散分布的部分是各按一定比例进行混合,具体形式如下:
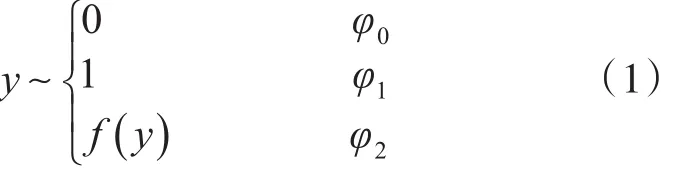
其中φ0,φ1分别表示数据中过多的0和1所占总体数据的比例,0≤φk<1,k=0,1,f(y)表示某种离散的分布,如泊松分布、二项分布、负二项分布等。φ2表示来自某种离散的分布的数据占总体数据的比例,显然φ0+φ1+φ2=1。可以看出零一膨胀数据中的0来自两部分,第一部分的0和第三部分离散分布中的0,数据集中的1也是同样的道理。
若式(1)中的离散分布 f(y)为二项分布P(y=k)=Cmkpk(1-p)m-k时,我们便得到了零一膨胀二项分布[10],具体形式如下:

其中0来自非二项分布中的零和二项分布中的零,1也是同样的道理,若φ0=0,φ1>0,表示数据存在1膨胀的现象;若 φ1=0,φ0>0,则表示数据只存在零膨胀;若φ1=0且φ0=0,此时表示数据服从标准的二项分布,不存在0和1过多的现象。下面我们对零一膨胀模型的参数部分引入协变量,模型形式为

其中γk表示回归系数,Z表示引入的协变量,这样我们便得到了零一膨胀泊松回归模型(ZOIB)的具体形式如下:
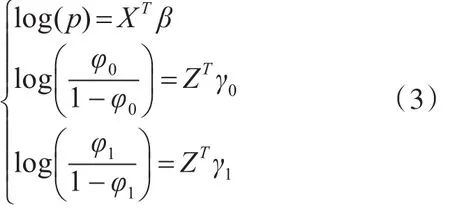
其中X与Z是协变量,β 和 γ0,γ1是回归系数,记θ=(βT,,)T,下面我们将用该模型来处理零一膨胀的数据。
3 参数的极大似然估计
本文受数据添加思想的启示[5],首先引入潜在数据 Ym=(w1i,woi),若 yi来自额外的1,记 w1i=1,否则 w1i=0。同样的若 yi来自额外的0,记woi=1,否则woi=0。这样就可以给出完全数据集Ycom=(Ym,Yo),其中 Y0=(yi,Xi,Zi)为观测数据。若用 I(yi=0),I(yi=1),I(yi>1)表示示性函数,基于完全数据的似然函数为
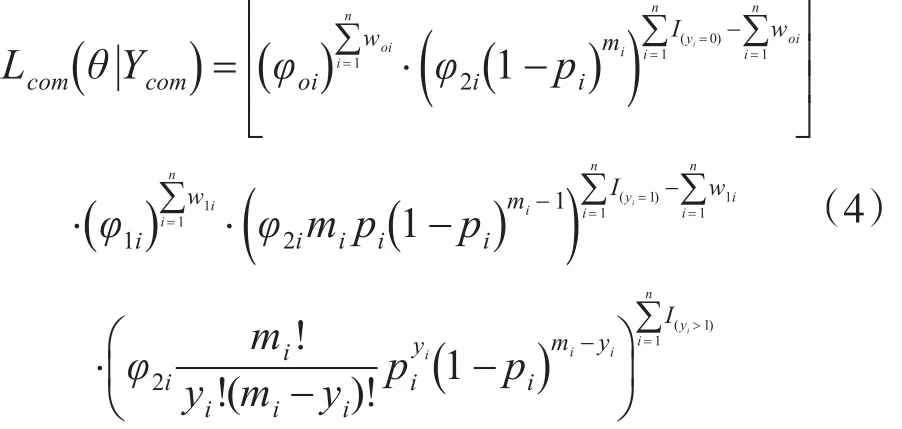
对式(4)两边取对数,进一步得到其对数似然函数为
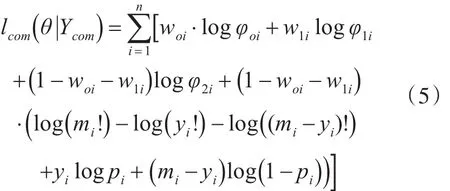
通过式(5)可以看出,基于完全数据的对数似然函数关于添加的潜在变量是线性的,这就为我们后面的计算提供了方便。
4 EM算法改进
传统的EM算法只能使得估计收敛到局部极大值[11~15]。针对这个缺陷,下面提出了一种SEM算法对传统的EM算法进行修正,使得模型能够找到全局最优解。SEM算法为了避免估计值落入局部极值中,对EM算法增加了随机步,使得估计结果每次收敛到不同的极大似然估计值,为我们最后求得全局最优解提供了保证。具体算法包括三个步骤:
第一步(E步):
计算Q函数:
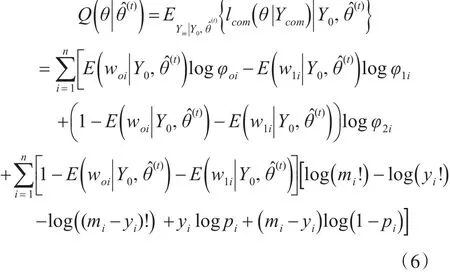
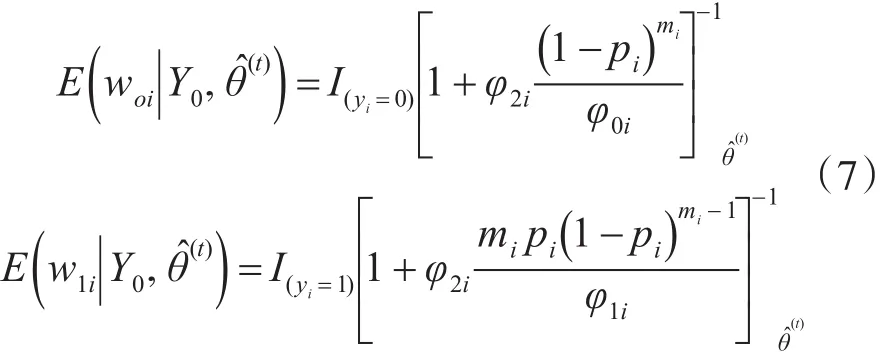
第二步(S步):
将观测数据集 Y0=(yi,Xi,Zi)划分成两个子集。划分规则是将每个观测随机的划分到两个子集中的任意一个中去。
第三步(M步):
分别在两个观测样本子集上将Q函数极大化,而这可以通过条件极大化的方案实现,我们利用迭代方程得出:

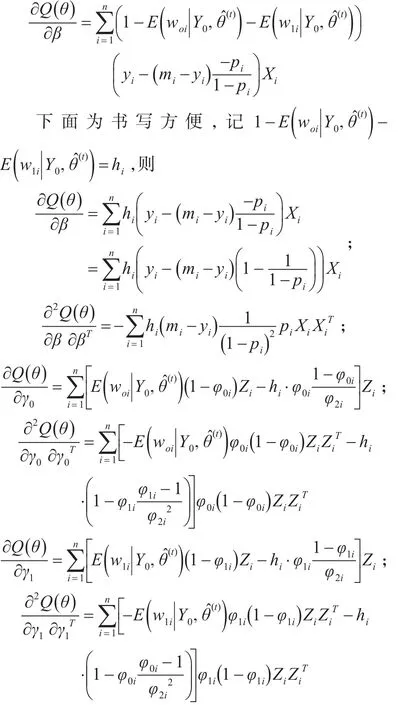
重复S步及M步,利用式(8),直到算法收敛求出全局最优解。EM算法对于一个相同的初值会收敛到相同的估计值上,但是对于相同的初始值,EM算法每次却会收敛到不同的估计值上,这样就保证了改进后的算法能找到全局最优解。
5 模拟研究
为了说明本文方法的有效性,下面的模拟研究来对比EM算法和改进后的EM算法。我们考虑如下模型:
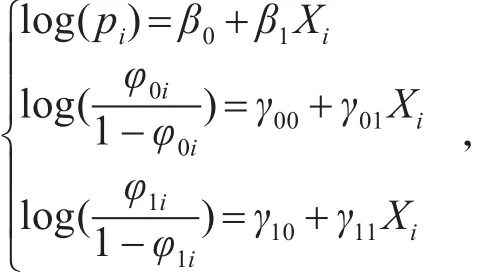
首先设定参数:β0=6,β1=1, γ00=5, γ01=2,γ10=3,γ01=1,然后从标准正态分布中产生200个随机数,协变量Xi的值由这些随机数产生,接着从零一膨胀二项回归模型(2)中产生200个随机数yi。
具体的模拟过程中,我们在M步中规定迭代次数以确保算法收敛,由于EM算法的估计值会受到初始值的影响,所以本文随机给定一组初始值β0=2,β1=2,γ00=2,γ01=2,γ10=2,γ01=2 作为代表(I),然后再用真值作为初始值作为代表(II),EM和SEM算法结果见下表。
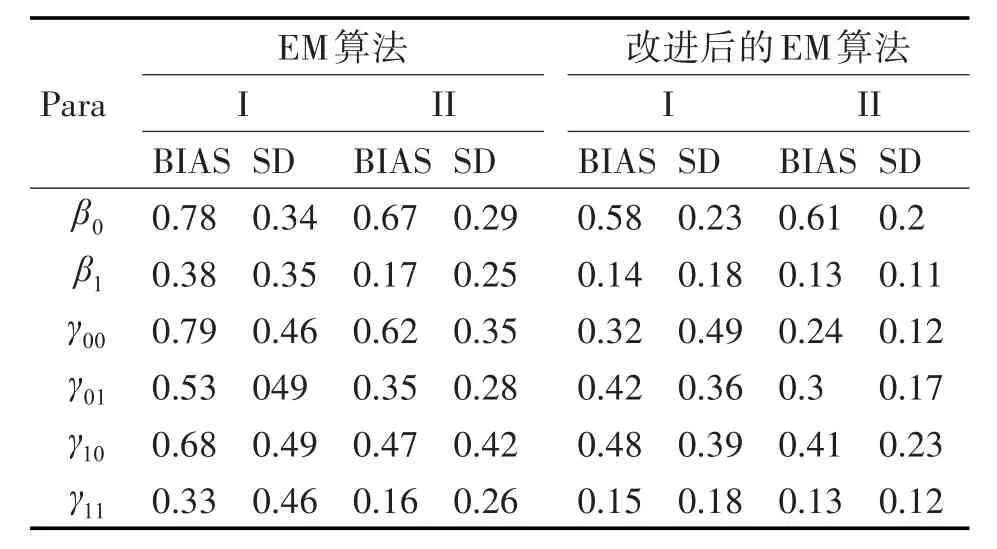
表1 两种算法下的参数的极大似然估计
从表中可以看出,不管用哪种算法,用真值作为初始值是优于其他值作为初始值的估计,这和现实是相符的。在(I)这种情况下,改进后的EM算法(SEM)明显优于经典EM算法;而在(II)这种情况下,若用真值作为初始值SEM算法是略优于经典EM算法;但是在实际生活中,对于参数的真值预先并不知道,所以现实中对模型参数进行估时,SEM算法比经典EM算法更有效。
6 结语
本文首先对零一膨胀二项回归模型模型建立了参数的极大似然估计,然后针对传统的EM算法只能使得估计收敛到局部极大值这个缺陷,提出了一种随机EM算法对传统的EM算法进行修正,使得模型能够找到全局最优解。最后通过一个模拟研究说明了该方法的有效性。但是在实际中,随机效应和随机误差可能不是正态分布,若对其做正态假设可能会导致无效的统计结论,这就有待我们进一步的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
中学生数理化(高中版.高二数学)(2022年5期)2022-06-01
西南交通大学学报(2022年1期)2022-02-11
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中学生数理化·高三版(2021年3期)2021-05-14
现代计算机(2019年19期)2019-08-12
科教导刊·电子版(2019年12期)2019-06-12
无线电工程(2019年6期)2019-05-29
