
基于于频繁模式挖掘的共享单车数据分析
2019-01-03 02:30邢一丹
电子制作 2018年24期
邢一丹
(西安市第七十中学,陕西西安,710000)
0 引言
共享单车作为一种环保节能、方便快捷的绿色公共交通工具,十分经济实用。共享单车拥有与政府为主导的公共自行车相同的目的一通过将自行车 与其他几种交通方式相结合,吸引居民从私家车出行依赖向公共交通方式出行转变减少私家车出行量,缓解城市交通拥堵问题,使这一方式成为城市公共交通的一部分实现城市交通'最后一公里"的无缝有效衔接的绿色交通模式,并最终成为居民交通出行的主要选择。共享单车的出现,在一定程度上多元化居民的出行选择,降低居民出行成本,道路资源利用率得以提高的同时也有利于交通拥堵问题的改善,共享单车出行还拥有环保节能,降低有害气体排放,加快公共交通循环,完善公共交通体系,有助于提高市民的生活环境提高居民低碳环保出行的意识与诚信观念等优点。
根据共享单车的发展,可以划分为四个阶段:萌芽阶段、成长阶段、泛滥阶段、洗牌阶段。在各个单车分别完成了多轮融资之后,单车投放量也都在不断加大,开始出现单车扎堆,影响交通,管理混乱的现象。除此之外由于有桩的公共自行车容易出现“租/还难”问题,不同区域间的流量不平衡造成了公共自行车利用率的下降,无桩的共享单车虽然理论.上可随时随地租还,但也由于潮汐现象的存在,造成某些时候用户在租车时发现附近没有一-辆可以借的车(或者只有坏车),而在还车的时候,虽然没有还车难的问题,但是会出现乱停放、目的地车辆扎堆等问题(在地铁站、公交站等地尤为严重),这会造成一定的交通拥堵和城市管理混乱。在本文的研究中,尝试使用频繁模式挖掘来解决摩拜单车停放点预测的问题,提出了较为新颖的创新思路和创新方法。
1 模式介绍
2.1 术语介绍
项:我们分析的最小元素;项集:若干项组成的集合;事务:一种特殊的项集,作为输入数据,常用ti表示一个事务;事务的集合叫事务集,用T表示;支持度计数:这个项集在所有事务集中出现的次数;支持度:支持度计数与事务的总数N的比值;规则:形如X→Y的表达式就是一个规则,X叫这个规则的前件或左件,Y叫这个规则的右件或后件,其中X∩Y=∅;置信度:描述一个规则可信程度的量;最小支持度阈值min_sup:这个阈值就是判断一个项集是否足够频繁的标准,满足最小支持度阈值的项集就是频繁项集,有k个项的频繁项集就是频繁k项集;最小置信度阈值min_conf:这个阈值是判断一个规则是否足够可信的标准;一般情况下的阈值设定,支持度阈值: 0.2/0.3 ,置信度阈值: 0.6/0.75。
2.2 模式引入
采用关联分析算法、聚类分析算法,并使用Python编程语言实现。
数据来源2017摩拜杯(Mobike CUP)算法挑战赛。

表1 数据含义
易知该模式中项包括订单号,用户ID,车辆ID,车辆类型,骑行起始日期时间,骑行起始区块位置,骑行目的地区块位置,通过数据中由项所组成的项集进行分析即使用频繁模式挖掘来解决摩拜单车停放点预测的问题。
3 数据处理
3.1 数据介绍
对于数据挖掘而言,需要从海量的数据中挖掘出有用的模式和信息,也就是“沙里淘金”的过程。数据虽然是抽象概念,但是,它也具有规模和属性。通俗来讲,数据规模就是数据的多少,数据越多,规模就越大,现在所说的大数据就是规模极大的数据;数据属性就是数据所具有的性质,数据具有的性质越多,我们称其属性越多,或维度越大,人们常说的数据降维处理就是尽可能地减少数据的无关属性,以达到筛选的目的。
同样,数据也有用来描述自己的单位,这个人们就接触的比较多。数据的单位常常被称作数据的宽度,日常生活中的网络速度、下载速度、存储空间等等都应用到了数据的单位方面的内容。
3.2 数据预处理的方法
数据预处理的主要方法就是数据清洗和数据归约。
数据清洗主要包括对数据集进行异常检测、识别并消除数据集中近似重复对象、对缺失数据进行清洗。数据集的异常检测主要就是消除少数异常数据对总体的影响,常常运用均值和标准差进行检测;重复记录的清洗主要就是筛掉重复的数据,使数据集更加精简,减少不必要的数据分析; 对缺失数据的清洗与灰色预测模型有些相似,旨在对缺失数据进行预测,其中涉及了许多高级的理论方法,这里就不再一一描述。
数据归约主要包括高维数据的降维处理和离散化技术减少给定连续属性值的个数。高维数据降维处理其本质就是删除数据的冗余属性,避免其对预测过程造成影响,简化对数据分析的过程;而离散化技术减少给定连续属性值的个数这种方法大多数是递归进行的,看似花费了大量的时间,其实却节省了后面步骤的时间。
3.3 分析Mobike单车数据
在此,本文以摩拜公司提供的北京市的2017年5月10日至2017年5月24日的部分共享单车真实用户抽样数据为例进行分析和探索,该数据包含了几十万个摩拜单车用户的出行信息,如订单编号、用户编号、车辆编号、车辆类型、骑行初始时间、骑行起始区块位置、骑行目的区块位置等信息,其中包含接近300万条的真实用户租还记录。
在预测共享自行车的用户出行目的地之前,需要先根据用户的历史骑行规律,构建出用户最可能去往的目的地集合,称作用户出行候选地预测。在预测候选地的时候,需要根据用户历史的行为,分析出最有可能去的地方,这就需要挖掘用户与初始地、目的地的频繁模式项。实现代码如表1所示。
首先,在数据集上统计出用户的出行热门地点,将目的地区块作为分组进行统计,计算用户骑行目的地次数最多的5个地点和所对应的地理位置经纬度。如表2所示。

表2
接下来按照骑行地与目的地的组合对进行统计,观察分析起始地和目的地之间都有哪些规律。

图1

图2 北京城区GeoHash编码区图北京郊区GeoHash编码图
起始地描述目的地描述轨迹数如表3所示。
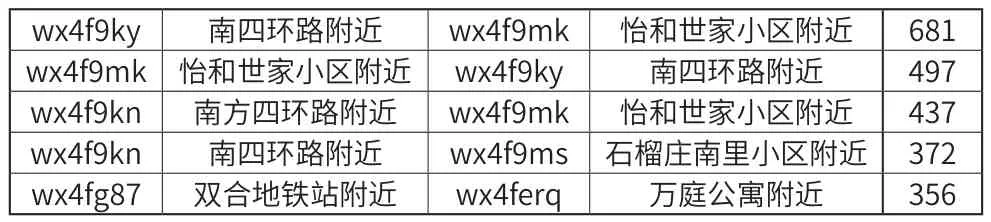
表3
其中起始地与目的地对应关系涉及到的区域的经纬度信息如下:
首先,可以发现频繁度比较高的模式对主要是出现在环路附近、居民区以及地铁站附近等地方,他们之间关系抽象出来主要有:环路-居民区、居民区-地铁站等。这也与日常生活中的情况比较吻合,用户经常由于工作需要往来于居民区、地铁站或者环路等附近。因此这些规律性比较具有普遍意义。
在预测共享自行车的用户出行目的地之前,结合上面的分析,需要先根据用户的历史骑行规律,构建出用户最可能去往的目的地集合,称作用户出行候选地预测。在预测候选地的时候,需要根据用户历史的行为,分析出最有可能去的地方,这就需要挖掘用户与初始地、目的地的频繁模式项。首先我们需要对所有项的出现个数进行统计,其次是只考虑对频繁项集进行扫描。具体步骤如下:
(1)首先创建根节点,用Null来表示;
(2)统计所有的项中各个类型的总支持度,如起始地或目的地的总个数;
(3)遍历每个项,按照总支持度计数进行降序排列,然后挂在根节点下方;
(4)遍历后续的项,以相同方式顺着根节点加入到树结构中,并更新支持度计数。
根据用户出行的历史规律,可以考虑挖掘出“起始地-目的地”的频繁项集,以历史集合中出现频次最高的,作为用户出行目的地的候选集。总计为以下几种:
(1)用户-起始地-目的地频繁项集(User-Start-Destination): 用户、起始地和目的地在训练集的组合中出现频率较高的频繁项作为该起始地对应的候选目的地。
(2)用户-起始地频繁项集( User-Start): 根据分析,用户的历史出行地也是用户出行范围的一-部分,因此历史的出行地也可能是未来的目的地,因此要考虑将用户、起始地在训练集的组合中出现频率较高的频繁项作为该起始地对应的候选目的地。
(3)用户-目的地频繁项集(User-Destination):根据分析,用户的历史目的地必然是用户出行范围的一部分,因此历史的目的地很也可能是未来的目的地,此可能性比起始地还要高,因此要考虑将用户、目的地在训练集的组合中出现频率较高的频繁项作为该起始地对应的候选目的地。
(4)起始地-目的地频繁项集(Start-Destination):不挖掘具体用户的频繁项集,将整体的思考范围调整到全部用户,考虑仅仅将起始地、目的地在训练集的组合中出现频率较高的频繁项作为该起始地对应的候选目的地。




4 结论
4.1 模型优势
本文以北京摩拜单车的数据集为例分析了共享自行车用户出行规律和影响共享自行车用户出行的因素,然后采用常用的关联分析算法、聚类分析算法,并使用Python编程语言实现,构建了用户候选地预测模型。按照不同角度,如用户与目的地、用户与起始地、起始地与目的地、起始地附近地与目的地、起始地与目的地附近低等多种组合的频繁项集,构建出来的预测模型召回率较高。
4.2 改进方向
由于能力及时间有限,对问题的考虑及处理方法上仍有很多不周的地方需要改进或后续进行深入研究,共享单车数据较难获取,目前的研究是基于有限的数据集进行的,因此效果可能会有些影响,在真实场景下能够有更大量的数据集用来训练模型,效果应该会好很多。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
悦游 Condé Nast Traveler(2022年2期)2022-02-18
小天使·三年级语数英综合(2021年4期)2021-06-15
计算机技术与发展(2019年7期)2019-07-23
计算机与数字工程(2018年10期)2018-10-23
21世纪商业评论(2018年5期)2018-05-24
小猕猴学习画刊·下半月(2018年9期)2018-05-14
中国经济周刊(2017年47期)2017-12-13
商周刊(2017年6期)2017-08-22
