
基于Redis与SSM的大型设备数据运用系统设计
2019-01-07 02:40熊肖磊王春伟周奇才
现代机械 2018年6期
熊肖磊,王春伟,赵 炯,周奇才
(同济大学机械与能源工程学院,上海201804)
0 引言
对于大型设备运行数据采集并加以处理运用,进而实现设备生命周期管理是目前设备管理的研究重点,而本文以盾构设备为例,探讨其数据处理运用系统设计方案与实现。随着地铁隧道掘进技术的逐渐发展完善,一条隧道的掘进过程往往伴随着多台盾构机施工,如此会出现多台盾构分散施工而管理维护困难的问题,于是在管理成本的制约下,需要建立某种系统对盾构设备及施工进程数据进行有效运用,从而实现对盾构有效的监控管理。对此,国内外的盾构生产商,诸如铁建、海瑞克和小松等,都对自家盾构配置了数据采集系统,但大多数无法满足多盾构数据处理运用,多用户访问的情况。文献[1]利用方便开发的组态软件实现监控管理,但不利于后期扩展,其系统需要特定运行环境。文献[5]以C/S结构实现了多台盾构的集中监控与数据运用,并成功应用在大连地铁103和201标项目,但随数据量增大,会使数据库访问压力增大。文献[8]实现了网络化盾构自动监控系统,并未满足集中监控目的。文中给出了一种嵌入式网络化盾构自动监控及报表系统,着重阐述了硬件结构与网络协议移植,并未满足多盾构监控目的。
基于B/S架构来构建盾构监控与数据运用系统既可实现多台盾构集中监控,数据处理,分析等工作,且无需安装专用客户端,只需通过浏览器即可访问,实现了多盾构多用户的互联网监控管理目的[2]。因此本文则采用B/S模式构建盾构机的数据处理运用系统,以SSM(Spring MVC、Spring、Mybatis)框架作为B/S实现的基础与开发辅助。同时考虑到数据量快速增长,采用数据缓存技术实现较快速的数据处理能力,同时提供快速的并发访问。本文利用Redis作为内存数据库进行盾构实时数据缓存,并以MySQL进行数据同步,将盾构历史数据与固有信息持久化,并且围绕SSM框架技术,以分层方式设计系统,实现多盾构快速高效的数据处理运用。
1 相关技术介绍
Redis作为一种NoSQL类型的数据库,具备了NoSQL灵活的数据模型;可存储处理非结构化及半结构化数据;良好的可扩展性;快速的读写能力和低廉的成本等特点[3]。NoSQL(Not Only SQL)泛指非关系型数据库,常用于超大规模和高并发的数据存储处理场景中,其根据数据库存储类型分为键值(Key-Value)存储数据库、列式存储数据库、文档性数据库和图形数据库[3]。而Redis作为一种开源的Key-Value数据存储系统,支持存储的Value类型包括了字符串、链表、集合及哈希等类型,并且均支持push/pop、add/remove及取交集并集和差集等操作,同时Redis会周期性地把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现Master-Slave同步[4,10]。
SSM(Spring+SpringMVC+Mybatis)框架集由Spring、SpringMVC、Mybatis三个开源框架整合而成,常作为数据源较为简单的web项目的开发框架[6,9]。其中SpringMVC分离了控制器、模型对象、分派器以及处理器程序对象的角色,使其更容易进行定制;Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架,供表现层调用,充当了表现层与持久层间的接口;而Mybatis则进行数据的持久化操作,支持普通SQL查询、存储过程和高级映射,通过对象关系映射将Java对象与数据库中的数据记录相互转换。通过在开源框架配置文件中的引用与项目中依赖包的导入,即可将三个框架整合起来,实现完整的前后端通信流程[6]。
2 系统结构设计
本文旨在利用数据缓存Redis和SSM集成框架搭建一种适用于盾构机数据处理运用的系统,对此在盾构机数据采集的基础上对系统进行结构的分层设计。整个系统基于B/S模式进行开发,而盾构数据通过机载的数据采集器用PLC采集得来,需要解包、转换、缓存和持久化。因此整个系统的工作流程是先将机载系统采集的数据解析后进入Redis,然后按照前端请求进行实时的数据请求响应,同时将盾构固有数据和实时数据同步存储到MySQL中,为后续的故障预测、数据分析等大量数据运用处理过程事务提供数据源。所以根据数据流动和功能划分,本文将整个系统软件结构分为数据层、应用层和表示层[9],如图1。

图1 系统框架结构图
如图1所示,数据层将底层盾构机载系统采集的数据在传输到数据中心的服务器后进行解析和存储,提供更加结构化的数据源;应用层则是利用数据库中存储的数据进行模块化的功能处理,诸如状态监测显示、设备关系、故障分析预测等,并使用SSM框架进行设计解耦,独立封装各模块功能,对客户端的数据请求给予正确响应;而表示层通过浏览器页面对盾构数据的诸多处理运用结果进行可视化的显示。
3 数据层
在前面提到数据层主要对后续应用层功能表现提供数据支持,即数据层是系统的基础环节,该层通过对底层机载系统采集传输的数据进行解析和存储,并在存储之前做一定程度的预处理,使存储的数据更具有结构性。本文将数据层实现分为两个部分:Redis实时缓存与MySQL持久化,以分别应对实时监测与大数据量分析运用的功能实现。
3.1 Redis实时数据解析缓存
盾构机在掘进隧道的过程中,需要将采集监测的量按类型分为数字量和模拟量。其中数字量对应某个限位开关的开闭或者千斤顶的伸缩,而模拟量则对应千斤顶压力、电机电压、旋转速度以及注浆压力等具有数值意义的量。同时数据遵循一定的协议格式传输,因此接收到数据之后,同样按照此种协议格式进行解析,通过数据包的起始地址加上偏移量的方法,得出各个测点或者数据量的真实数据,解析过程如图2。

图2 源数据解析流程
源数据进行解析后按照是否超过上下限进行缓存,对于实时数据的存储则按照测点配置表中的信息进行对号入座,根据底层数据采集的约定协议生成各个测点的配置表,如表1与图3。

表1 各测点的偏移量对应关系

图3 测点信息配置表
如表1所列测点偏移量对应关系,解析程序即按此进行数据包解析,同时生成一项测点信息的配置表存储在数据库中,便于之后作为某台盾构的特征信息查看。在生成测点信息配置表过程中,以各测点所属盾构机子系统分组,如此在后续对盾构机子系统部件进行分析时提供便利,如图3。
如此实时数据经解析之后便可以进行Redis缓存了,在Redis缓存中以Key-Value的数据形式存储[10],对于实时数据而言,每一个时刻的数据均是有区别的,这种区别存在于每一个传输的数据包上带有的时间戳(TIMESTAMP),于是对于两个实时数据包即可通过TIMESTAMP进行区分,并可作为Key来标识缓存中的Value。结合Key-Value存储无表概念的特点,实时数据的存储时,以盾构ID为Key,以hash作为Value存储此台盾构的数据,如此便可以Key区分不同盾构的数据。对于Value部分的hash,以TIMESTAMP作为Key,以数据list作为Value,如此便可区分同一盾构不同时刻的数据,在数据list中,以Key-Value的形式存储各个测点的名称及对应的数值[4]。因此存储结构如表2所示。从表2中可以看出,根据盾构的标识ID及某个时刻的TIMESTAMP即可以唯一的确定某台盾构某一时刻的各个测点的实时数据,根据底层数据发送的时间间隔进行实时数据的解析缓存,并将一段时间内的旧数据同步至MySQL中,而后删除,保证内存不被占满。

表2 实时数据缓存结构
3.2 MySQL数据持久化
通过前面内容所述,盾构实时数据在经过Redis缓存之后,同步持久化至MySQL中,用于后续的数据分析工作,而且盾构机的某些固有特征数据也要存储到数据库中,由于这些数据一般是结构化数据,所以可直接利用MySQL存储。对于盾构机特征数据和故障记录等并不会由底层数据采集系统传输,而是访问特定的接口得到,而此种访问是以JSON字符串作为数据传输的格式,因此在访问特定接口获得盾构机特征数据和故障记录信息的处理流程如图4。

图4 接口数据处理存储流程
对于实时数据的持久化存储时需要考虑盾构机组成特点和系统的功能需求,然后设计存储的表结构。盾构机是一种集机械、电气和液压系统与一体的大型设备,其结构复杂,系统众多,每个大的部件或者子系统中包含诸多零部件,并且零部件之间存在某种父子关系。所以在设计表结构时考虑零部件的父子关系将其按照树形结构存储,即一台设备包含多个子系统,一个子系统包含多个部件,一个部件包含多个零件或测点,即它们之间是1∶n的关系;同时考虑到多台盾构的集中监控与数据运用,所有数据存储在一张数据表中会因为记录太多导致查询某台盾构的运行数据时缓慢,因此采用单盾构单表的形式,即单张数据表中只存储一台盾构的运行数据,并使用配置表维护,使各台盾构名称与数据表名关联起来,从而将多台盾构的运行数据分散到多张表中存储,减轻了单张表存储记录过多的压力。于是综合信息后得出其中的关联如图5。

图5 盾构运行数据存储表关联示意
如图5(a),通过配置表中表名字段与盾构数据表名关联,实现数据分散至多表存储,而图5(b)则是对某台盾构而言的设备、部件、测点和数据的关联示意,如此则实现了树形存储。
4 应用层
应用层主要是以数据层为基础,通过调用数据层向上提供的接口,对该层提供的盾构运行数据和特征数据进行对应的加工处理,实现相应的业务逻辑,并向表示层提供接口,将实现的业务逻辑通过表示层可视化表现。如此处于系统中间层的应用层是系统核心,起着承上启下的作用,系统的功能实现则主要在这层实现。
对于盾构机而言,其在运行过程中积累大量的工程数据,包括关键部件测点的监测参数、掘进隧道的地质数据、设备故障信息和维护信息等,这些数据是监测管理盾构的重要依据。因此对于盾构管理而言,应该是全周期的,即对盾构施工前期、施工中期和施工后期的信息都需要进行管理。而盾构机工作环境较为恶劣,如果出现零件损坏,则势必会影响整个盾构的运行,因此对于盾构数据的处理运用包含了实时数据监测、测点历史统计、故障信息记录以及基于历史运行数据的故障预测与诊断等,便可以时刻关注盾构的健康状态,使得在零部件出现损坏前给出预警,及时更换,从而不会影响整个系统的正常运行。在这些功能的实现上,利用SSM框架进行应用系统解耦,以模块独立化的方式开发,简化了开发流程,达到在模块内部可以更加专注于逻辑实现,高度内聚,而在模块之间专注于接口调用,低度耦合的目的。应用层结构如图6。
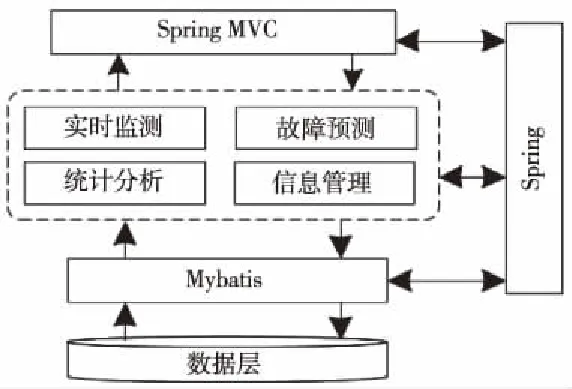
图6 应用层结构示意图
如图6,应用层中包含多个功能模块,并且各模块之间相互独立,通过Spring MVC向表示层提供统一的访问接口,在接收到表示层请求之后,根据Spring MVC的控制器分发请求,直接调用对应的模块进行其中的业务逻辑处理,同时这一过程有着Spring的管理与Mybatis对象关系映射,从而能够完成接收请求,分发请求,业务处理,访问数据源,模型生成,视图填充以及给予响应的完整过程[9]。
在过程实现中,Spring整合Mybatis,进行数据通道、映射与事务的管理,通过在Spring容器中注册DataSource、SqlSessionFactory和MapperScannerConfigurer的实例bean,将数据源属性文件载入,从而加载数据通道和关系映射原则,并制定Mapper接口的扫描路径,使得在访问数据库时自动扫描Mapper接口进行数据的持久化操作,把Java对象与数据表记录映射起来,从而完成在应用层中的对象传递。而Spring MVC则主要加载了请求映射器和适配器的驱动,配置了基于注解@Controller的控制器扫描路径,使得Spring MVC在拦截请求之后,根据拦截路径,自动扫描@Controller类,匹配拦截路径,从而可以执行对应的业务逻辑,调用对应的接口方法,访问对应的数据库表[6]。
之后则是在项目启动文件中设置Spring及Spring MVC的入口文件,从而在系统启动时,框架功能也随之准备就绪,即在web.xml中设置Spring配置文件applicationContext.xml路径以及Spring MVC的请求控制分发器DispatcherServlet和Spring-mvc.xml的路径,并在web.xml中配置好请求拦截HTTP请求的基础路径[9]。
5 表示层
表示层作为系统顶层,主要是将盾构数据处理应用后的结果以某种方式呈现出来,即通过文字、图片、表格和视频等元素构成的网页显示在用户的浏览器上,从而使用户更加直观的感受各种数据处理后的结果。对于表示层而言,其通过应用层取得业务逻辑处理后的结果数据,填充到经过HTML、CSS和JavaScript美化过的页面中,形成最终的网页。但是这样在结果数据变化时,为了体现这种变化,前端表示页面也需要不断刷新载入,这对于实时数据监控显示或者根据条件查询的应用来说很不友好,每次整体页面刷新不仅体验不好,同时也对系统资源造成了浪费,所以就使用AJAX进行页面的局部刷新。通过AJAX[7]向服务端请求数据时,一般有长轮询和短轮询两种方式,其中长轮询就是建立浏览器与服务器之间的链接持续保持下去,多次请求使用同一个连接,而短轮询则是每次请求都会建立新的链接,请求结束后链接也随之中断;但由于长轮询需要服务器维持链接,导致系统资源多余耗费,同时实时数据监控显示间隔在秒级单位,因此本文采用短轮询的方式请求数据。
对于实时监测数据显示,每次AJAX请求为盾构机标识ID和当前时间戳TIMESTAMP,服务器端接收参数之后,从Redis数缓存中查询出数据,并以AJAX请求中常用的JSON数据传输格式返回数据,对实时监测页面进行局部的数据更新,从而达到盾构运行数据实时变化的目的。AJAX数据请求流程如图7。

图7 实时数据监测显示页面AJAX请求流程
如图7所示,前端浏览器获取盾构标识ID和当前时间戳TIMESTAMP之后作为参数发起AJAX请求,服务器接收AJAX请求后解析出盾构标识和时间戳参数,并按此查询Redis数据缓存,并将查询结果以JSON格式返回至浏览器,浏览器解析JSON数据,填充页面实现局部刷新。而实现代码如下[7]:
$.ajax({ type : "POST",url : "xxx",dataType : "json",
data : {"shieldID" : ID,"Timestamp" : Timestamp},
success : function (data) { …//更新页面部分},
error : function () { …//异常处理部分代码}});
实时数据监测页面示意如图8,图中通过纯数据显示方式将盾构各子系统关键参量的数据变化直接表示,包括了千斤顶系统、刀盘系统、螺旋机系统和注浆与泡沫系统,并结合折线图和仪表板插件强调某些参量的变化趋势与变动情况。
而对于盾构固有特征信息查询或者统计分析、故障统计、地表沉降预测等结果显示同样是基于AJAX短轮询实现,即通过不同业务逻辑处理或根据模块配置即可同样原理实现。诸如图9所示的故障统计,通过柱状图显示数量,表格显示详细记录。
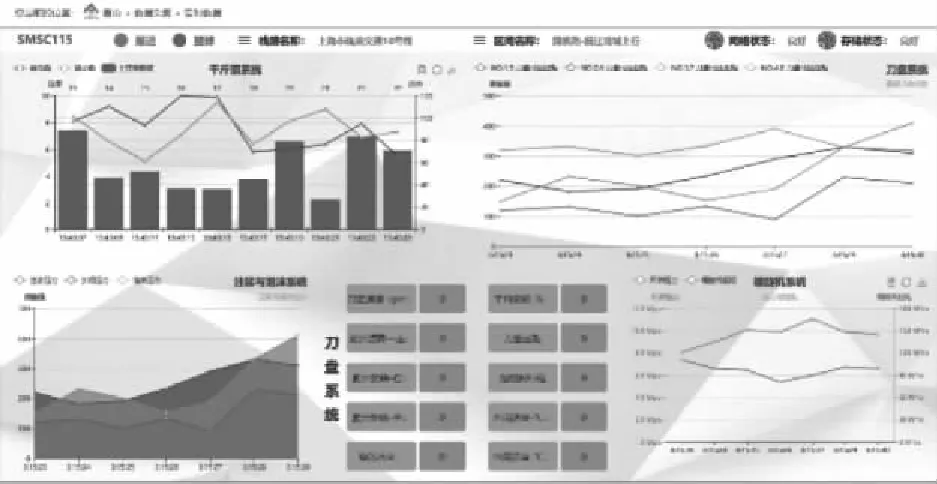
图8 盾构运行数据实时监测显示示意图

图9 盾构故障信息统计
6 结论
本文使用Redis数据缓存和MySQL持久化,对盾构运行数据和结构化特征数据进行存储,并通过SSM框架搭建了基于B/S模式的盾构数据处理运用系统。系统总体结构分为三层,分别是数据层、应用层和结构层,在数据层中使用Redis对实时数据进行缓存,以满足实时监控的要求,并且将历史数据及时同步至MySQL中,对后续一系列的数据处理应用提供数据源。虽然目前可以实现多台盾构的集中监控,但为了提供数据处理能力和系统交互能力,后续可进一步搭建Redis集群,以应对高并发系统访问;同时在数据处理方面应用机器学习、数据挖掘等方法进一步增强对盾构数据的处理效果,从而能够完整的实现盾构的全生命周期管理。
猜你喜欢
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
水泵技术(2021年3期)2021-08-14
建材发展导向(2021年11期)2021-07-28
教育教学论坛(2016年49期)2017-02-27
中国房地产业(2016年9期)2016-03-01
中国惯性技术学报(2015年1期)2015-12-19
物联网技术(2015年8期)2015-09-14
中国工程咨询(2015年9期)2015-02-25
中国质量与标准导报(2014年7期)2014-02-28
