
电子商务环境下多元个性化服务推荐研究
2019-01-11 06:03崔睿宇杨怀洲
智能计算机与应用 2019年1期
崔睿宇, 杨怀洲
(西安石油大学 计算机学院, 西安 710065)
0 引 言
随着通信技术和经济环境的改变,消费者的消费模式发生了迅速的变化,网购的趋势也在逐年增加。而购物网站上海量的商品信息对消费者快速选择目标商品起到了一定的限制作用[1]。在这种背景下, 推荐系统( recommender systems)应运而生。服务推荐算法作为推荐系统的核心组成部分,成为个性化推荐领域的研究热点。由于每种推荐算法都存在各自的优点和不足,所以,服务推荐算法的组合和多元化研究对于提高推荐系统的准确性和性能具有重要意义。
1 个性化推荐技术
1.1 推荐技术分类标准
目前,对推荐系统的分类并没有统一标准,很多学者从不同角度对推荐方法进行了不同的划分[2-3]。文献[4]给出了区别推荐技术的二维属性:
自动化程度(degree of automation)与持久性程度(degree of persistence)。
1.2 主流推荐算法
(1)基于内容的推荐算法。 基于内容的推荐,又被称为基于信息过滤的推荐,是由信息检索(Information Retrieve)领域提出来的,是指用户根据选择的对象,推荐其它类似属性的对象作为推荐结果。其核心思想是根据用户兴趣和物品特征的相似性进行推荐[5]。
(2)协同过滤推荐算法。协同过滤推荐(collaborative filtering recommendation)是目前研究最多的个性化推荐技术。该算法的基本思想是将用户按照兴趣的不同进行分类,同类用户具有极为相似的兴趣,因此可以由其它用户的偏好协同过滤得到对目标用户的推荐。
协同过滤主要分为两大类别[6]:Memory-Based Collaborative Filtering和Model-Based Collaborative Filtering。Memory-Based方法又进一步分为User-Based Collaborative Filtering(UBCF)和Item-Based Collaborative Filtering(IBCF )。
UBCF是一种基于用户最近邻(K-Nearest Neighbor, KNN)实现的推荐算法,该算法的关键过程在于对用户最近邻的查找——可以通过各种相似度计算方法进行度量。UBCF中常用的相似度计算方法有:皮尔森相关系数(Pearson Correlation Coefficient, PCC)、夹角余弦相似度(Cosine SIMilarity, COSIM)及Jaccard系数(Jaccard Coefficient)等。由于用户之间的相似度稳定性较差,需要对用户之间的相似度进行频繁更新等问题,UBCF不适用于用户量大的信息系统。针对这一问题,基于项目的协同过滤算法(Item-Based Collaborative Filtering, IBCF)被Sarwar等人[7]提出。
IBCF的关键在于挖掘项目间的相似性,分类相似项目,IBCF基本采用了与UBCF类似的相似性计算度量方法。常见的基于项目的相似度计算方法有以下几种:基于项目的皮尔森相关系数(Item-based Pearson Correlation Coefficient)、基于项目的夹角余弦相似度(Item-based Cosine Similarity)和基于项目的修正夹角余弦相似度(Adjusted Item-based Cosine Similarity)等。
由于基于内存的协同推荐直接应用评分数据进行相似度计算和评分预测,基于模型的协作推荐大量采用机器学习和数据挖掘算法。在基于模型的协同过滤推荐算法中常用的模型和算法有贝叶斯网络、聚类算法、回归算法、马尔科夫决策模型和关联规则挖掘等。
(3)基于关联规则的推荐算法。基于关联规则的推荐(association rule-based recommendation)是根据关联规则对项目排序产生的推荐[8]。电子商务领域中的购物车效应就是关联规则效应运用的典型,通过研究分析用户频繁购买的商品之间所存在的联系,再利用商品之间的这种关联关系为其它用户产生推荐。
(4)基于知识的推荐算法。基于知识的推荐(Knowledge-based recommendation)不是建立在用户需要和偏好上的推荐,即无需考虑用户-项目矩阵的历史信息[9]。在某种程度上可以看做一种推理技术。
(5)基于人口统计学的推荐算法。基于人口统计学(Demographic-based Recommendation)的推荐算法是基于用户个人属性对用户进行分类,再按照类别的不同对各类中的用户进行推荐[10]。
1.3 各推荐技术优缺点比较
每种推荐技术的优缺点对比见表1。

表1 各推荐算法优缺点对比
1.4 组合推荐技术
组合推荐(hybrid recommendation)的一个最重要原则就是通过组合后应能避免或弥补各自推荐技术的弱点。理论上有很多种推荐组合方法,不同的组合思路适用于不同的应用场景。
混合推荐的分类方法大致有2种,一种按照不同推荐技术混合发生阶段的不同分为前融合、中融合和后融合[9];另外,根据不同的结合方式,Robin[11]提出7种组合思路:加权组合、变换、混合、特征组合、层叠、特征扩充以及元层次组合[12]。
1.5 推荐算法的评价
推荐算法的评价要综合考虑实验数据集和评价标准2方面的选择。
1.5.1 推荐算法的实验数据集
推荐算法评价依赖的实验数据集有2种选择——真实数据集或者人工加工数据集。真实数据集可反映目标推荐系统的真实数据分布,但成本高,时效性差,缺乏统一的评价参考性。人工加工数据集往往具有较好的一致性,可人为控制数据的分布特征,但只能对特定应用领域的算法评价,数据分布特征难以反映实际应用环境中的数据特征。
推荐系统经过多年的发展,收集和累积了大量的真实数据,这些数据既具有一定的数量规模,又在一定程度上反映了各领域中真实数据的分布特征 ,具有较强的代表性。常用的具有参考意义的数据集有:MovieLens数据集、EachMovie数据集、Book-Crossing数据集、Jester Joke数据集和Netflix数据集。
1.5.2 推荐算法的准确性评价
推荐系统及算法准确性的度量至今仍无统一的标准,一般可从预测准确性和分类准确性2个方面度量推荐算法的推荐质量。
1.5.2.1 预测准确性
针对评分预测推荐任务,预测准确性是主要的度量标准。常用的预测准确性度量标准包括平均绝对误差(Mean Absolute Error, MAE)、归一化平均绝对误差(Normalized Mean Absolute Error, NMAE)和均方根误差(Root Mean Squared Error, RMSE)。
MAE通过统计预测评分与真实评分之间绝对距离的均值来实现准确性度量,与推荐的预测准确性呈反比,对于n个真实评分R={r1,r2,…,rn},推荐算法生成的预测评分为P={p1,p2,…,pn},则MAE可表示为:
(1)
MAE是一种绝对误差评价标准,其往往因为评分范围的不同而造成不可比。而NMAE的提出通过使用评分范围对MAE进行了归一化处理,从而实现相对误差度量,克服了MAE的不可比性。对于评分上、下限分别为rmax和rmin数据集,NMAE可表示为:
(2)
而RMSE可以提高预测准确性的区分度,RMSE可表示为:
(3)
1.5.2.2 分类准确性
分类准确性度量标准是对推荐算法进行正确或错误决策的频率统计,分类准确性的度量与分类问题有着密切的关系,所以其度量标准大量借用了分类算法研究中使用的标准,常用的分类准确性度量标准主要有准确率、召回率和F1评分。
准确率量化了在推荐系统所生成的推荐中,符合用户信息需求的相关推荐结果所占比重,召回率反映了推荐系统实现推荐的全面性。
系统可能实现旳正确推荐和错误推荐状态可以见表2的混淆表格表示,对应不同推荐状态的数量统计见表3。
则准确率可表示为:
(4)
召回率可表示为:
(5)
F1评分是对准确率与召回率的一种综合度量,通过二者的协平均将推荐系统的分类准确性度量表示为单一评价标准,数学表达式如下:
(6)
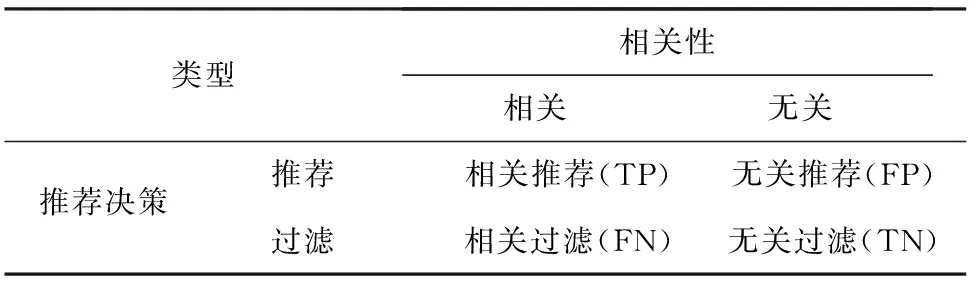
表2 推荐系统混淆
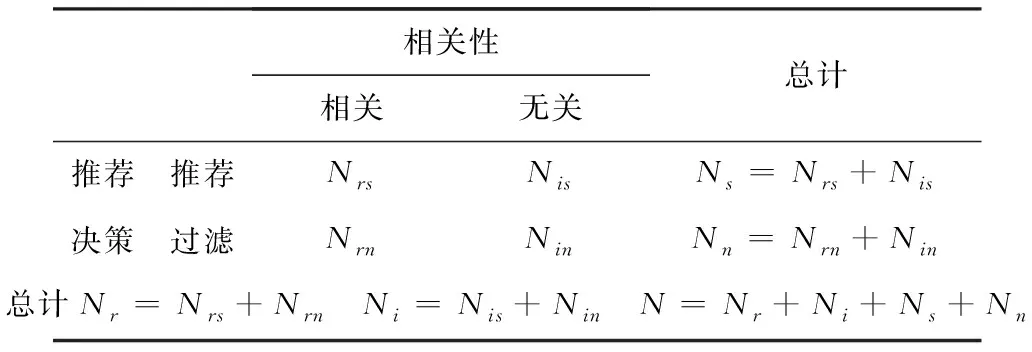
表3 推荐系统推荐状态数量混淆
2 推荐系统存在的问题
随着推荐系统在电子商务领域的广泛应用,其面临的一系列挑战也得到了越来越广泛的关注。推荐系统面临的主要问题有以下几点:
(1)特征提取问题。虽然在信息检索中,文本特征的提取技术已经比较成熟,但是推荐系统的对象不一定具有文本特征或者利用文本不足以作为描述[13]。对于多媒体数据,如视频、音乐、图像等的特征提取方法需要结合多媒体内容分析领域的相关技术。另外,大规模数据情况下对特征的区分性要求提高。
(2)数据稀疏性问题。在大型的推荐系统中,对于一个用户,总有大量的对象没有经过评价或者查看,而且这类数据常常比己经有此用户评价的数据量更大[14]。此外,用户之间选择的差异性大,也会加重数据的稀疏性问题。
(3)冷启动问题。冷启动问题是稀疏性问题的特例[5-14],冷启动问题可以细分为新用户问题和新项目问题[15-17]。
当系统中出现新用户时,该用户没有对项目进行评分,推荐系统缺乏关于新用户的兴趣信息和知识。对基于内容的过滤算法,推荐系统无法建立关于新用户的兴趣模型;对基于用户的协同过滤算法,推荐系统也无法确定该用户的相似邻居;对于基于项目的协同过滤推荐算法,尽管系统可以确定不同项目之间的相似程度,但由于缺乏新用户的兴趣评分,所以仍无法对项目进行评分预测。
对于协同过滤算法来说,新项目评分的缺失将造成相似度计算和评分预测无法完成。冷启动问题的主要成因在于推荐系统对于评分数据的依赖性,所以需要在推荐系统中引入其它参考信息和知识[18-19],用来克服评分数据的缺失对推荐系统的影响。
(4)概念漂移问题。用户在与推荐系统交互的过程中,其兴趣与偏好会受到外部各种因素的影响,如社会、家庭、重大事件都会导致用户模型发生变化,从而造成用户兴趣的概念漂移[20-23]。
作为一种动态人机交互系统,推荐系统的概念漂移问题无法避免,因此应建立感知概念漂移的机制[24],对用户兴趣变化进行主动跟踪。在用户兴趣模型更新、相似度计算和评分预测等各关键过程中引入关于评分的时间特性,对用户的历史评分进行区分,从而保证推荐结果符合用户需求。
(5)算法伸缩性问题。由于推荐系统的推荐精度和实时性是一对矛盾。目前大部分推荐技术的实时性是以牺牲系统的推荐质量为代价的[24-26]。推荐系统可采用基于模型的推荐算法来提高其伸缩性,将大计算量的计算任务以离线方式进行,如推荐系统中的特征抽取、用户建模、相似度计算等都可以事先或定期进行离线计算,但是基于模型的推荐算法往往会牺牲一定的推荐准确性,造成推荐质量的下降。
3 研究展望
对目前电子商务个性化推荐方面的研究,笔者认为,协同过滤算法在未来一段时间内仍会是电子商务领域中的主流算法,而该算法自身存在的诸如数据的稀疏性问题和冷启动问题始终是国内外学者的研究热点。除了对协同过滤算法本身进行算法改进之外,数据挖掘技术的兴起无疑为克服协同过滤算法的短板提供了更多可能。
随着人们对推荐系统认识的逐步深入,用户需求也将更易于被研究者理解,更加符合用户需求的协同过滤算法也终将被提出。同时,评估协同过滤算法的度量也将随着认识的变化不断改进。此外,随着移动终端的普及,对诸如位置、时间和终端等上下文信息进行充分利用也必将成为未来推荐系统的研究重点。
猜你喜欢
社会科学战线(2022年9期)2022-10-25
现代仪器与医疗(2022年2期)2022-08-11
北京航空航天大学学报(2022年6期)2022-07-02
上海文化(文化研究)(2022年3期)2022-06-28
中国典型病例大全(2022年12期)2022-05-13
新班主任(2022年4期)2022-04-27
中国典型病例大全(2022年7期)2022-04-22
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
