
基于K近邻的增量式聚类算法*
2019-01-15 08:15钱雪忠姚琳燕
传感器与微系统 2019年2期
樊 路, 钱雪忠, 姚琳燕
(1.江南大学 物联网工程学院 智能系统与网络计算研究所,江苏 无锡 214122;2.物联网技术应用教育部工程研究中心,江苏 无锡 214122; 3.江南大学 物联网工程学院,江苏 无锡 214122)
0 引 言
如今互联网的信息迅速增长,而大多数聚类方法只能处理静态数据,这意味着在运行聚类算法之前,输入数据必须完整。当聚类算法运行时,无法向该算法添加任何新数据。然而,在大多数情况下,信息随时都会出现,在这种不稳定的情况下简单的聚类数据方法是,当新数据来临时,将原始数据和新的数据一起使用来构建新的聚类模型。但会浪费很多时间,且没有使用已经从这些原始数据中获得的知识。
Ester M等人[1]最早提出了基于密度的聚类算法(density-based spatial clustering of application with noise,DBSCAN)的增量聚类算法,在DBSCAN算法的基础上,针对数据仓库环境中增量式数据加载要求而改造的。该算法依次将更新表的一条当前记录与数据仓库中的记录比较,更新聚类结果,但算法在增量聚类过程中,更新对象依次单独处理,而没有考虑更新对象之间的关系,效率较低。
传统增量聚类算法往往是通过增量与质心的距离来判断增量的归属性,该单一条件并无法较好地判定增量数据与已有类的相似性,而且无法聚类出噪声点或者新的簇。而在现有的关于增量聚类的文献中[3,4],大部分依然注重的是对初始聚类算法的改进,而针对增量部分数据的处理往往是根据传统的距离判别方法将其划分到已有的簇中,鲜有针对增量聚类的创新。因此,本文考虑使用新的数据和原始数据中的几个样本来改变从原始数据获得的聚类模型,使得该模型适合原始数据和新的数据。
本文在K近邻(K-nearest neighbor,KNN)算法的基础上结合簇特征概念提出了一种新的动态增量聚类算法,即基于K近邻的增量聚类算法,改进增量聚类算法的有效性和可扩展性,实验证明该算法能够较为准确地处理增量数据点,包括划分为已有的簇、生成新簇、合并分裂部分簇、识别噪声点。
1 增量式聚类算法
1.1 增量聚类
增量聚类算法首先使用原始数据构建初始聚类模型,当新数据来临时,使用新的数据来改变这个聚类模型,使其适合新的数据。本文提出的增量聚类算法是在K近邻的思想上,融合了划分与层次的聚类方法中优点[2,6]。首先计算增量数据最近k个近邻样本,判断这k个近邻样本所属的簇,计算k个近邻中样本点所属各个簇的比重,这是进行增量数据划分的首要依据,比重最大的优先考虑将增量数据划为该簇。然后结合增量与K近邻中的样本数据的相似性比较和各自对应的簇特征的变化情况,对增量数据进行进一步的处理。因为噪声点相对其他样本的距离都较远,在增量过程中,其所在簇中样本数目的增长就会非常缓慢,甚至不增长。第一阶段的工作中,是将聚类过程中增长非常缓慢的簇作为噪声点除去。第二个阶段的工作(聚类基本结束的时候)是将数目明显少的簇作为噪声点除去。一般增量处理过程包含以下三种情况:
1)增量按K近邻原则插入到与之最近的簇中,(图1(a))。
2)增量与现有簇相似性较低,独自形成新簇,(图1(b))。
3)增量在逐步增加的过程中改变了原有簇的相似性,使之合并成一个簇。如图1(c)所示或者分裂成两个簇,如图1(d)所示。其中A,B为原始簇,A',B'是增量后的簇,C是新形成的簇。

图1 增量处理过程
1.2 相似度度量
相似度度量主要依据数据间的距离关系,本文统一采用欧氏距离来表示样本与聚类中心之间的距离d12,即
(1)
式中x1和x2为样本,n为两个数据样本的维度数。对于任意两个数据样本p和q,dist(p,q)为p和q间的相似度。
在处理增量的过程中,每个簇的质心都会随之变化,更新每个簇的质心为
(2)
式中u为某一簇,m.meannew为增量后的质心,u.meanold为增量前的质心,u.num为簇u中样本个数,u.xnew为属于簇u的增量数据。
1.3 增量过程
本文提出的算法步骤详细介绍如下:
步骤1 采用K-means算法对原始数据集聚类[7,8],得到原始聚类结果并对结果进行统计。包括聚类数,各个簇的样本数、质心和凝聚度。
步骤2 利用K近邻算法的思想,利用步骤(1)的结果计算寻找增量数据的k个近邻样本,单独存储为一个K近邻矩阵,并统计K近邻矩阵中簇的分布情况以及各个簇所占比重。
步骤3 根据步骤(2)中得到K近邻矩阵的统计信息。
对于增量的处理方法:
1)如果增量的k个近邻全部属于同一簇时,这时候可能会出现两种情况,一是增量数据属于该簇,二是增量数据可能产生一个新簇。此时计算k个近邻之间的相互距离的均值k.mean和增量与个近邻之间距离的均值in.mean,用两者的差值来衡量增量和k个近邻的紧密度关系。
a.若k.mean-in.mean>=τ(τ为紧密度系数,针对不同数据集取值不同),则增量数据属于该簇。为增量数据添加该簇的簇标签,并更新簇的特征CF。
b.若k.mean-in.mean<τ,则增量数据产生新的簇,簇标签为maxLab+1(maxLab为目前已有的最大类标签),并计算新簇的簇特征CF。如果最终新形成的簇的样本数量过小,则认为是噪声点。
2)如果增量数据的k个近邻属于n(n≤k)个簇,这时可能会出现3种情况,属于近邻中某个的簇;形成一个新簇;可能需要合并一些原始聚类数据中的样本。接下来需要判断该增量数据是否为关键增量点(key of incremental data,KID),如果是则合并K近邻,否则,继续计算增量数据与近邻中各个簇间的平均距离in1,in2,…,inn和所有近邻之间的平均距离k.mean,若min{in1,in2,…,inn}>k.mean则生成新簇,否则,增量属于min{in1,in2,…,inn}簇。
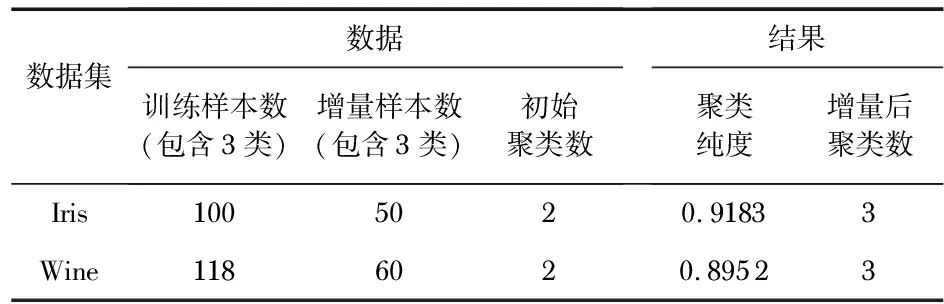
判定KID:首先增量数据的k个近邻中出现属于这样两个簇,第一这两个簇所占比重相当(|A%-B%| 图2 关键点 判定为关键增量点后,合并增量数据和K近邻中比重次高样本点的到比重最高的簇中去。最后每条增量数据处理完后即成为原始数据。 步骤4 适时判断是否需要执行簇分裂操作。 为了进一步准确地处理增量聚类,在增量的数量增加到一定的情况下,簇分裂的可能性逐步增大,因此在增量的过程中适时需要执行簇分裂操作。 1)判断类分裂条件:根据子簇的簇特征检查各个子簇是否满足需求,主要从子簇的质心和子簇的凝聚性两方面来判断是否需要分裂某子簇。首先判断子簇的样本数N是否达到可以进行分裂的数目,达到,则计算该簇中所有点均值与簇凝聚度差,大于阈值t,即dist(u.mean,u.R)>t,则说明增量破坏了该簇的簇特征,需要对该簇分裂。 2)实施分裂:确定需要分裂后,使用K-means算法分裂子簇[9],在实施分裂中K-means算法的初始点设为该子簇中距离相对较远的两个点,聚类数k=2。 综上所述,该算法伪代码如下: input:Original data setX; Incremental data InX; output:Clustering resultidx; 1)(idxold,C,CF)=kmeans(X); 2)for each InXdo 3)knn[k]=Findknn(OriginalResult,InX); 4) if(knn全部属于同一个簇) 5)k.mean= AverageDist(knn[1],knn[2]…knn[k]); 6)in.mean=AverageDist(InX,knn[1],knn[2]…knn[k]); 7) if(k.mean-in.mean>=τ) 8)knn[k].cluster←InX; 9) Update(cluster.CF); 10) end if 11) if(k.mean-in.mean<τ) 12)New.cluster←InX; 13) Update(cluster.CF); 14) end if 15) if((knn全部属于多个簇)) 16) if(InXis KID) 17) merge(knn[i],knn[j]); 18)knn[k].max.cluster←InX; 19) Update(cluster.CF); 20) end if 21) if(InXisn’t KID) 22) in[n]=dist(InX,knn.cluster[1], knn.cluster[2]…knn.cluster[n]) 23) if(min{in}>k.mean) 24)New.cluster←InX; 25) Update(cluster.CF); 26) end if 27) end if 28)end for 30) split(cluster); 31)end if 实验中采用加州大学尔湾分校(UCI)中提供的Iris数据集和Wine数据集,两种数据集常常被用来检测分类聚类算法的有效性,分别拥有150个数据样本和178个数据样本,描述属性分别是4个和13个,类别数都是3类。为了实现增量聚类过程,需要人工筛选出初始聚类数据集和增量聚类数据集,为了全面检测本文中增量聚类算法的实效性,对增量数据聚类设计了三种实验。 为了验证算法对噪声点的识别,分别模拟了Iris数据集和Wine数据集的噪声点数据,并进行如下实验。 实验1分别从各个类中各选出部分样本数据,组成一个增量数据集,以此来检测该增量聚类算法整体有效性[11]。实验数据和结果如表1所示。 表1 实验1数据与结果 实验2将原始数据集中的3类样本,取其中两类作为初始聚类数据,另外一类作为增量数据,并加入模拟的噪声点,检测该增量聚类算法是否能有效聚类出新增的簇和识别出噪声点[12]。实验数据和结果如表2所示。 表2 实验2数据与结果 实验3将初始数据集的三类聚成两类,然后再聚类增量,检测算法是否能有效分裂聚类结果[13]。实验数据和结果如表3所示。 表3 实验3数据与结果 通过以上实验可以看出,在实验1中本文算法的聚类纯度分别是0.891 1和0.692 5,都高于传统增量K-means。在实验2中本文算法的聚类纯度分别为0.907 2和0.891 2,不仅聚类出了新的簇而且较好地识别出噪声。在实验3中本文算法的聚类纯度分别为0.918 3和0.895 2,并且准确地实现类分裂操作。实验证明该算法可以有效处理增量数据,不论是插入现有的簇中还是产生新的簇还是分裂某些簇,都拥有较高的准确率。 本文利用K近邻的细想结合簇特征这一概念设计并实现了一种全新的增量式聚类算法,在处理增量过程中,不仅能准确划分为现有簇,而且也能正确合并或分裂某些簇和识别出噪声点。并通过实验证明该算法的有效性和可行性。但该算法不足之处在于执行增量过程中依赖初始数据集的聚类结果,初始聚类结果的准确性对增量聚类的准确性影响较大。而且该算法中对增量的处理是逐一进行,没有采用批处理方式,在面对增量数据过大时可能会导致算法效率大大降低,这也是接下来需要进一步研究的内容。
2 实验分析
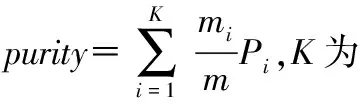


3 结束语
猜你喜欢
China Report Asean(2022年8期)2022-09-02
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
北京航空航天大学学报(2021年4期)2021-11-24
物联网技术(2020年12期)2021-01-27
中学生数理化·中考版(2019年9期)2019-11-25
汽车零部件(2017年4期)2017-07-12
电信科学(2016年9期)2016-06-15
应用科技(2015年5期)2015-12-09
