
面向分布式计算的混合维度微粒群算法
2019-01-16 07:16桑渊博曾建潮
太原科技大学学报 2019年1期
桑渊博,曾建潮,2
(1. 太原科技大学 计算机科学与技术学院,太原 030024;2.中北大学计算机与控制工程学院,太原 030051)
微粒群算法从1995年被提出后,因为它的很多优越性在各个领域得到了广泛的应用,如函数的优化、工程界的系统优化、神经网络训练、深度学习等。优越性表现在算法结构简单、所要考虑的参数少、搜索性能稳定高效。对于求解问题上,问题的求解规模影响着微粒群算法的执行效率,如求解问题精度、时间消耗长短、问题的结果的收敛程度等方面体现出了些许不足。另外,在很多工程领域中常常会遇到局部最优解的影响,使得问题的求解达不到工程的要求。在此之前出现了针对微粒群算法上的诸多改进,例如引入惯性权重的微粒群算法[1]、带收缩因子的微粒群算法和基于岛屿模型的微粒群算法[2]等等。但这些改进同样都会遇到当求解大规模问题或大规模的问题变量时计算耗时的问题,所以算法的分布式计算[3]和并行计算[4]就会体现出诸多好处,不仅可以减少执行时间而且还能增加种群的多样性从而使得求得解更好。
分布式计算是利用集群计算对同一问题或者不同问题进行求解,和使用单机计算形成对比,可以在一定程度上解决计算耗时的问题。在分布式进化计算方面[5],主从式分布计算模型[6]、细粒度分布计算模型[7]、粗粒度分布计算模型[8]和混合分布计算模型等几类模型分别得到研究。研究是以这些模型为基础,结合具体算法和分布式计算环境的特点,围绕其实现方法和应用问题展开的。在现在的大数据时代背景下,分布式并行处理框架广泛应用于各个领域基于分布式并行处理框架的开源系统Hadoop、Spark应运而生,并在许多应用领域取得了巨大的成功。所以也可将进化智能算法和当前的分布式并行处理框架相结合,由程磊生,吴志健等人将微粒群算法在Spark集群中完成分布式计算,通过11个测试函数测试多种改进的PSO算法进行仿真实验得到该算法求解精度变高且加速效果明显。
1 微粒群优化算法
微粒群优化算法(Particle Swarm Optimization, PSO),它是一个模拟鸟群觅食过程的智能优化算法。PSO算法因为具有较强的全局搜索及全局收敛能力并且易实现的特点,所以在很多领域得到了成功的应用[9]。但是在做一些计算复杂性的优化问题时,会出现收敛速度较慢、计算时间长、求解精度不高等问题。算法描述如下:
假设种群P={p1,p2,…,pn},即种群是由N个粒子组成,N称为种群规模。粒子在d维空间的位置表示为xi={xi1,xi2,…,xid},粒子速度表示为vi={vi1,vi2,…,vid}.在粒子速度、位置变化过程中,当前个体粒子的最优解记为和 全局最优解记为Pg={pg1,pg2,…,pgd},其进化公式为(1)、(2).
Vid(t+1)=w*Vid(t)+C1r1(Pid(t)-Xid(t))+C2r2(Pgd(t)-Xid(t))
(1)
Xid(t+1)=Xid(t)+Vid(t)
(2)
其中,t表示代数,w是一个[0,1)的服从某种分布的随机数常量,称为惯性权重。惯性权重的大小代表了对当前粒子速度继承的多少,如果惯性权重大则能够使粒子的速度较大,从而可以提高粒子的全局搜索能力。C1,C2是粒子学习因子,C1代表粒子自身的学习能力,控制下一次会朝着自己最好位置的轨迹进化,C2则是控制着粒子向着全局最优解的位置进化。所以C1,C1的选取能够直接的影响PSO算法的性能,合适的C1,C2可以加速问题结果的收敛而不易导致陷入局部最优。r1,r1是两个随机数,在[0,1)且服从均匀分布。为了使粒子在进化过程中防止粒子速度过大而超越搜索区域,可以将粒子的速度进行限制,例如:可设置为在[-Vmax,Vmax]范围,其中Vmax=γxmax,0.1≤γ≤1.0.
算法流程:
1) 首先初始化一个粒子数为N的 种群,包括粒子位置、速度、个体最优解位置、全局最优解位置等;
2) 计算每个粒子目标函数适应值;
3) 将种群中的每个粒子的目标函数的适应值与该个体所经历过的最好位置pg的目标函数适应值相比较,若好,则将当前位置作为当前个体的最好位置pg;
4) 然后再比较种群中的每个粒子的目标函数适应值与种群的全局最好位置pg相比较,若较好,则将其作为全局最优解pg;
5) 根据进化公式(1),(2)对种群粒子的速度和位置进行进化更新;
6) 如果未达到终止条件则返回步骤2),(终止条件一般是是否达到最大进化代数或者达到足够好的目标函数适应值精度);
2 与Spark结合的MDPSO算法
分布式计算技术是研究如何将一个大的问题分解成多个小的任务,再将这些被分解的小的任务分配给多个计算机节点进行并行处理,然后将每个小人物计算的中间结果汇总在一起,如此反复,直到整个问题的解决,以此来达到成倍的缩减时间的消耗同时且不影响最终的结果的效果。
2.1 Spark分布式计算平台
分布式进化计算框架可以由进化算法、分布式模型、集群环境、物理平台4个基本条件组成,如图1所示。近几年在集群计算平台发展上,尤为突出的有Hadoop和SparK.而Spark是建立在抽象的RDD (Resilient Distributed Datasets)之上,RDD模型中的迭代计算是基于内存处理的模型,使得Spark在进行算法迭代运算时在计算速度上会快很多。

图1 分布式计算框架
Fig.1 Framework of distributed computing
综合以上描述,可以将微粒种群分割化,分割成多个子种群来进行独立的进化。一方面满足微粒群算法并行的思想,另一方面更符合Spark集群计算的模式。可以将子种群的粒子信息通过Spark的RDD化分发到各个计算节点,使得每个节点可以独立的计算一个或多个子种群且各个子种群间的影响很小。
2.2 MDPSO算法
MDPSO(Mixed Dimension Particle Swarm Optimization)算法是能够实现粗粒度下的并行算法[10]。采用多子种群的进化方式会将总的种群分割成n个子种群,在迁移周期内,每个子种群会在集群的各个节点上面进行独立的进化计算,当进化次数达到迁移周期时将各个子种群中的全局最优解收集起来,然后对收集后的最优解进行混合(混合的方式是把各个子种群的全局最优解对应维度上的数据混合,形成了D(粒子维度)个数据集合)。然后再通过随机发送的方式将各个维度上的数据随机的发到各个子种群,子种群得到新的全局最优解后再进行进化计算。直到达到所设置的终止条件。
对于分布式迭代算法来说,Spark的RDD并行计算模型具有高效的容错机制、基于内存计算、中间结果不需要写入磁盘等的优点。尤其是它的基于内存计算特别适合做一些算法的迭代计算,在集群环境下大大节省了很多的数据访问时间。为适应当前大数据计算、云计算的环境,本文提出了基于Spark的混合维度微粒群(MDPSO)算法。MDPSO算法流程图如图2所示。
算法的具体思路如下:先初始化N个子种群,每个子种群含有相同粒子数,然后通过Spark的输入算子makeRDD或者parallelize函数将N个子种群并行到集群中去。然后各个种群开始自己的独立采用微粒群算法的方式进行进化计算,当达到设置的迁移周期时通过collection算子进行收集各个节点上的全局最优解,其次采用混合维度的方法将数据拆分整合,最后再随机的发到各个子种群中的对应维度中去。各个种群信息交流完毕后再通过makeRDD或者parallelize算子使并行化,以此方式循环,直到达到终止条件,最后输出结果。
算法中的混合维度方法是:在各个子种群达到迁移周期时将各个子种群中的全局最优解通过Spark的collect函数收集起来,然后将全局最优解中各个维度上的粒子数据集合起来形成D(D为粒子维度数)个集合,然后通过随机发送的方式将数据集合中的数据不重叠的发送到各个子种群。例如:各个子种群的第1维数据组成一个集合,然后将这个集合中的数据再随机的发送到各个子种群中的第1维。
MDPSO算法可以并行执行的部分体现在以下几个方面:
1) 每个子种群可以独立进化计算。
2) 在子种群内部,粒子与粒子之间可以相互的独立进化计算。

图2 MDPSO流程示意图
Fig.2 MDPSO schematic diagram
3) 每个粒子中的各个维度之间并行进化。
MDPSO算法伪代码如下:
1:Initialize N population: objectPartical
2:generationNum = 0
3:While(generationNum< maxNum)
4:Parallel Population: objectParticalRDD
5:objectParticalRDD.map(elem =>
6:k = 0
7:while(k < migration cycle )
8:evolutionary computation the objectPartical
9:end while
10:)
11:collection the objectParticalRDD
12: mixed dimensions and send out randomly
13: end while
MDPSO算法说明:各个种群采用面向对象方式进行初始化,面向对象方式是将种群所有属性整合到一起,对象中的属性有粒子位置、粒子速度、当前个体粒子的最优位置、子种群中的全局最优位置、迁移周期等。
3 仿真实验
3.1 实验平台
实验采用3台相同配置的服务器组成Spark集群计算平台。每台机器配置如下:操作系统为Centos6.8,Intel(R) Xeon(R) CPU,主频1.80GHz,Hadoop和Spark对应版本分别为Hadoop2.6.5和Spark1.6.1.
3.2 实验设计方案
为了验证MDPSO算法的性能,选取了6个无约束优化的测试函数,其中F1、F2函数是单峰函数,F8-F11是多峰函数。具体函数定义参照文献[11]。实验测试的算法包括MDPSO和IPPSO[2]算法。为了验证MDPSO算法的性能,设计了两个实验方案:
实验方案1 比较上述两种算法在粒子维度D=30的情况下求解上面的6个测试函数的效果,另外选取F8、F11函数记录中间结果,通过分析中间结果集来查看函数的收敛情况。由于MDPSO算法求解过程中全局最优解是波动的,所以对求得的中间结果用拟合的方式画出算法收敛图。
实验方案2 针对MDPSO算法设置不同的迁移周期来查看对F9、F10函数结果的影响情况。方法:分别计算不同迁移周期30次,算出各自的平均值来查看结果。
在实现方案中的参数选择上采用相同的原则,目的是保证实验结果对比的有效性,另外算法中的参数设置参考了文献[12]中的设置。种群个数等于集群中的计算节点的CPU总核数,以实现真正的并行计算,所以两个算法的具体参数设置如下:将种群分为8个子种群,每个子种群中的粒子数设置为15个,粒子维度D=30,权重因子w是[0,1)的随机数,学习因子C1=C1=1.4962,Vmax在每一维度的值设置为对应维度变化范围的0.15倍,进化总代数设置5 000为代,所以总的评价次数FEs = 120*5 000 = 600 000次,种群间的信息交流采用混合对应维度信息的方式进行。
3.3 实验结果及分析
对于方案1,分别用两个算法对每个测试函数分别运行30次,记录测试结果的最好值、最差值和平均值,实验结果如表1所示。F8、F11函数分别在IPPSO算法和MDPSO算法迭代进化过程中的收敛图如图3、图4所示。
表1 两算法求解函数结果
Tab.1 The results of two algorithms solve functions

函数Functions算法Algorithm最好值Best value最差值Worst value平均值Mean valueF2IPPSOMDPSO9.9E-2314.23E-1981.11E-2272.48E-1968.46E-2297.91E-197F8IPPSOMDPSO1.04E+041.23E+048.40E+038.49E+03-9.35E+03-1.15E+04F9IPPSOMDPSO31.8381.989 9114.42958.984 362.68232.305F10IPPSOMDPSO7.55E-153.99E-151.46E-143.99E-158.49E-153.99E-15F11IPPSOMDPSO0.00E+000.00E+000.0294980.00E+000.0077150.00E+00

图3 F8函数收敛图
Fig.3 F8 function convergence diagram

图4 F11函数收敛图
Fig.4 F11 function convergence diagram
图3、图4说明:设置每个子种群迁移周期是10代,对于F8函数的收敛情况途中只展示到了280*10次进化结果,F11函数的收敛情况展示了58*10代,因为后面的都收敛于这个结果。为了使图像结果更清晰,所以就选择了代表性的代数。
实验方案1的结果表明,在进化代数相同的情况下,MDPSO算法在求解多峰函数时,求解的结果比IPPSO算法求解的结果更接近于理论最优解。但对于单峰函数在相同的进化代数下MDPSO算法求得的解要弱于IPPSO算法求得的解。从F8、F11函数的收敛效果图来看,MDPSO算法和IPPSO算法相比,MDPSO算法虽然收敛的速度要比IPPSO算法要慢,但它能跳出局部最优而能找到更接近于理论最好值的全局最优解的能力要强很多。因为当其中一个子种群中如果陷入了局部最优,那另外若干子种群未陷入局部最优,那这些子种群的全局最优解通过信息交流就会帮助陷入局部最优的子种群跳出而继续寻找全局最优解。
对于实验方案2,对MDPSO算法设置不同的迁移周期观察对F9、F10函数进化结果的影响如图5、图6.从图5可以看出迁移周期由1增大到10时,求解的结果越来越好,之后随着迁移周期的增长求解的结果则越来越差,到了60代时求解结果最差。再随着迁移周期的增长,求解的结果虽然变得好了但变化不大。图6显示对于F10函数迁移周期由1到5时,求解效果越来越好,之后一直到迁移周期为150时求解效果变化不大,再之后求解效果则越来越差。出现上述结果原因是当迁移周期由1变到10时各子种群之间的相互影响越来越小,增加了种群的多样性,从而能够找到更优的解。但随着迁移周期的继续增加,子种群间的相互影响虽然越来越小但信息交流却被弱化,使得其中一个子种群寻找到更好的解时无法及时通知其他子种群。那就等价于自己独立进化计算,使得整体的种群多样性减小,那最终的寻优效果就会变差,所以找到合适的迁移周期是关键。所以合适的迁移周期能够使MDPSO算法对于复杂问题的求解会有着很好的效果。

图5 不同迁移周期对函数F9结果影响
Fig.5 The effect of different migration cycle on function F9
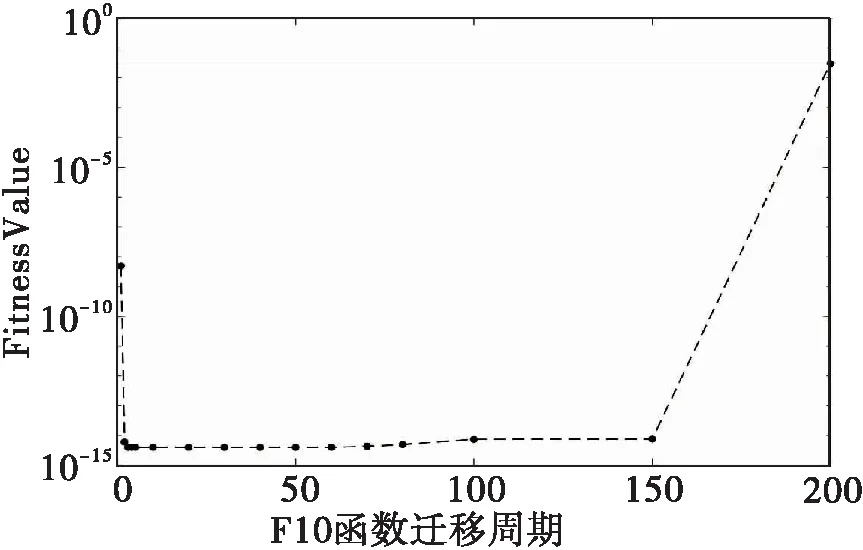
图6 不同迁移周期对F10结果影响
Fig.6 The effect of different migration cycle on function F10
4 结 论
微粒群算法本身具有并行性,本文划分了若干个子种群并以集群计算的形式 进行了实现,增加了种群的多样性有利于问题的求解,在子种群信息交流时采用了对所有维度进行随机选取的方式,进一步增加了种群的多样性。通过不同的测试函数模拟求解问题来验证MDPSO算法的可行性。由于算法提高了种群的多样性使得求解问题时更容易跳出局部最优解而更容易找到全局最优解。当遇到计算量大的问题时,即使采用了粗粒度的分布式计算技术,对于单机计算也是很费时,所以将来可以采用GPU细粒度计算模式来减少单机计算时间,从而进一步减少整个集群计算时间,以达到更好的效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
原子能科学技术(2022年4期)2022-04-25
金桥(2018年4期)2018-09-26
中学生数理化·高三版(2016年11期)2017-03-02
软件导刊(2016年12期)2017-01-21
软件导刊(2016年11期)2016-12-22
科学与财富(2016年15期)2016-11-24
北京航空航天大学学报(2016年9期)2016-11-16
中学生数理化·高三版(2016年2期)2016-09-10
