
毫米波NOMA系统的一种用户分簇及预编码算法
2019-01-21 10:39姜静,雷明
西安邮电大学学报 2018年6期
姜 静, 雷 明
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
和正交多址接入(orthogonal multiple access, OMA)相比,非正交多址接入(non-orthogonal multiple access, NOMA)[1-2]能够让5G系统中两个甚至多个用户共享相同的时频资源。NOMA技术在发送端利用不同功率对多个用户的信号进行叠加,在用户端利用串行干扰消除(successive interference cancellation, SIC)来消除用户间干扰以恢复目标信号。
多输入多输出(multiple input multiple output, MIMO)[3]能够通过多用户预编码来提高系统性能。将其与NOMA相结合,所得MIMO-NOMA技术[4-6]能够更显著地提升系统容量。由于其中簇间存在干扰,发送端先要借助如相关性用户分簇算法[4]和基于信道增益差的分簇算法[6]等,对系统用户进行分簇和选择,再由发送端利用预编码来降低簇间干扰,以提高系统频谱效率。
毫米波频段的频谱不仅资源丰富[7-8],而且,毫米波较强的方向性保障了毫米波信道更强的相关性,因此,将毫米波和MIMO-NOMA技术相结合,能显著提升频谱效率。针对毫米波MIMO-NOMA系统,基于相关性用户分簇算法的功率分配方案[9]能效较优,但是,并未更好地利用毫米波信道特性。
一些分簇算法和预编码算法[10-11]虽然充分考虑到了毫米波信道的特性,但却忽略了偏远用户对分类结果的影响,也没有对分类的结果进行用户选择,这样的纯模拟预编码方式并不能很好地消除簇间干扰。
为降低簇间干扰,提升系统性能,本文拟给出一种新的用户分簇及选择算法和预编码算法。为了保证K均值分类的性能并降低运算复杂度,所给算法先对系统用户进行筛选,将偏离用户筛除出用户集合,再对其余用户利用K均值进行聚类。考虑每簇容纳两个用户的情况,聚类后从每类中选择一对信道增益差最大的用户作为一簇用户。为减小硬件复杂度,预编码则利用混合模拟/数字预编码方式。基于分簇结果,通过簇内用户信漏噪比(signal-to-leakage-and-noise ratio, SLNR)最大的准则为每簇用户设计模拟预编码矢量,再利用每簇强用户的等效信道生成数字预编码矩阵。
1 系统及信道模型
考虑一个单小区下行毫米波大规模MIMO-NOMA系统。在小区中心位置配置一个具有NTX根天线和NRF条射频链路的基站来服务位于该小区内的M个单天线用户(NTX≥NRF)。在基站端采用全连接模式,即每个射频链路都通过多个移相器连接所有天线,如图1所示。
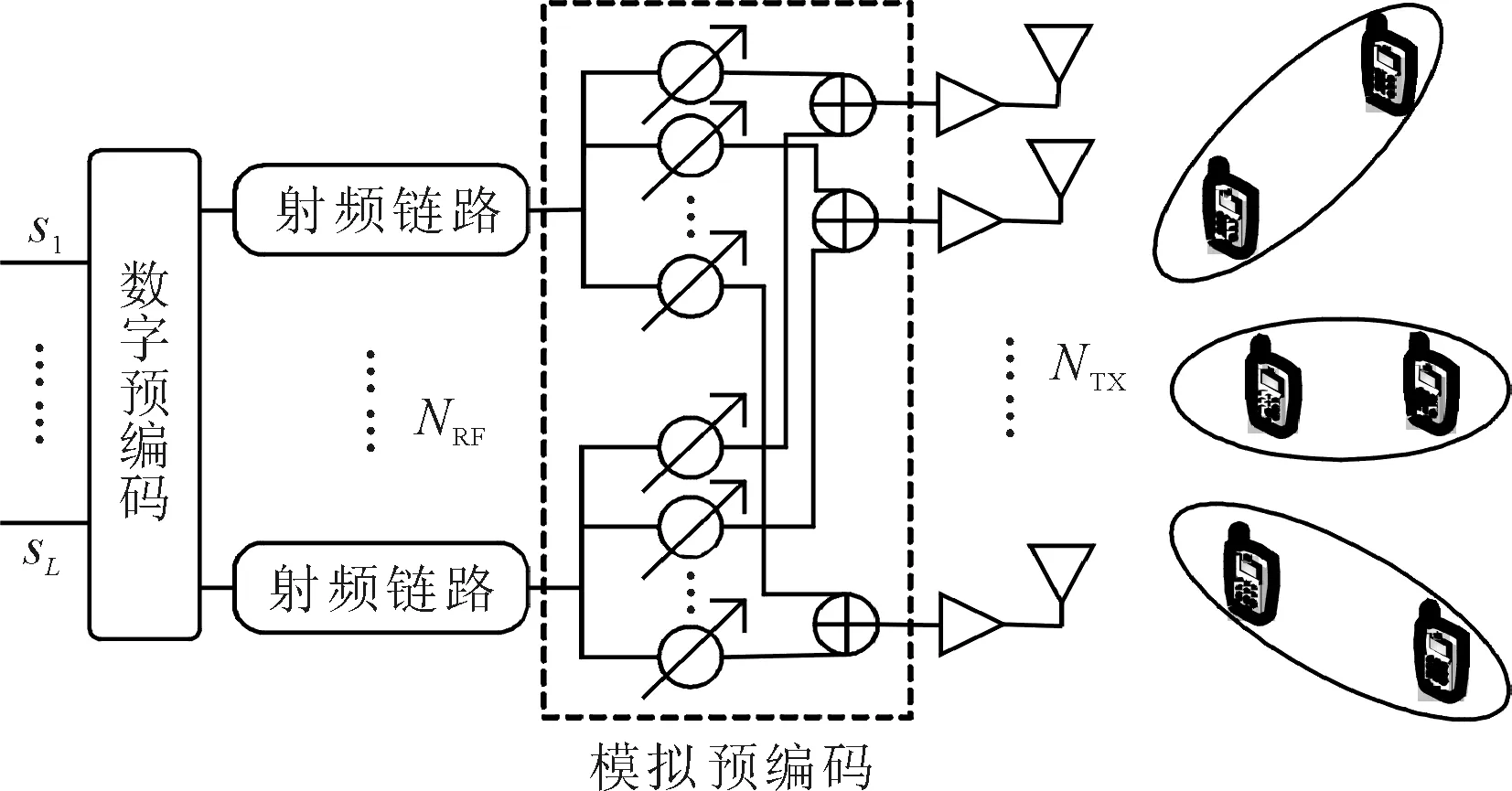
图1 下行毫米波大规模MIMO-NOMA系统
通过对小区用户进行选择及分簇,基站能够同时同频为L簇用户提供通信服务(L=NRF),每簇可容纳多个用户。不妨只考虑每簇包含两个用户的情况,这也和NOMA在长期演进技术升级版(long term evolution - advanced,LTE-A)中的实施标准相符合[9]。如此,属于同一簇的两个不同用户将由同一波束赋形矢量提供通信支持。假设在基站端能够获得各用户的信道状态信息。
针对L簇用户,基站产生的发射信号矢量为
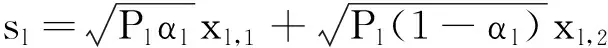
第l簇第i个用户端的接收信号
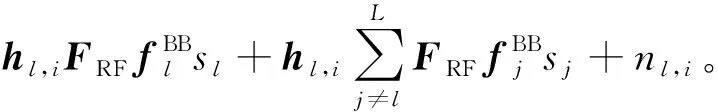
其中hl,i∈1×NTX表示基站到第l簇第i个用户的毫米波信道矢量NTX×NRF和NRF×L分别为模拟预编码和数字预编码矩阵。等式右端第二项为用户受到的簇间干扰。nl,i为高斯白噪声,它的均值是0,方差是σ2。不失一般性,对每簇皆可假定
其中‖·‖表示F范数,则用户1为强用户,用户2为弱用户。
因毫米波信道散射体有限,在此考虑包含F个散射体的几何信道模型[12-13],并假定各散射体仅能产生一条从基站到用户端的传输路径。对于用户k来说,其毫米波信道矢量可表示为
(1)
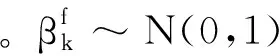
2 用户分簇及选择算法
用户分簇能够有效降低簇间用户干扰,合理地选择两个用户组成一簇在MIMO-NOMA系统中非常重要。
在MIMO-NOMA系统中,两个同簇用户使用一个波束。若同簇用户的信道相关性很强,不同簇用户间的信道相关性很弱,则可通过预编码设计,使簇内的两个用户都能获得更大波束增益,也能降低用户的簇间干扰。
对毫米波信道,NLOS径的路径损耗远大于LOS径,即LOS径的作用远大于NLOS径,故当LOS径存在于毫米波传输时,NLOS径的作用就可忽略不计[10],因此,式(1)可简化为
式中上标0也被省略。则毫米波用户i和j的信道相关性可表示为
其中,FNTX(·)是费耶尔核,它会随输入增大急剧减小到0。可见,两用户信道矢量的相关性可以用这其信道的归一化角度差来衡量,角度差越小,相关性越强。而K均值聚类算法就是找到一个分类,从而使类中所有点与该类中心距离的均方误差最小。若λk是第k类的平均值,则第k类内所有的点和λk的均方误差可表示为
其中,Ck表示第k类中所有点的集合。K均值算法的目的就是找到一个分类方法,从而最小化所有聚类中均方误差之和[11],即
那么通过对所有用户的角度进行K均值聚类,在同一类内的用户信道相关性会很强,而属于不同类的用户之间相信道关性则会较弱。
K均值聚类算法有一个缺点:如果系统中有某些异常点,即距离其他点比较远的点,就会导致均值偏离严重,聚类效果不理想。因此,在进行用户聚类之前,先将和其他用户相比角度差较大的偏离用户筛选掉,这样既能够降低偏离用户对K均值分类效果的影响,也能够减少运算量,加快收敛速度。
另外,在下行NOMA系统中,基站分配给强用户较少的功率,给弱用户分配的功率较多。如果簇内两个用户的信道增益差较大,那么基站分配给这两个用户的功率差也会增大。因为在强用户接收端要进行SIC,两个用户间的功率差越大,强用户的SIC性能就会越好;同时,随着功率差的增大,分配给强用户的功率就会降低,因此,对于弱用户来说,受到的干扰也会降低。
综上,基于K均值的用户分簇及选择算法可以描述如下。
步骤1将小区内所有M个用户的归一化角度从小到大排列,计算出每个用户和相邻用户的角度差,如果角度差大于预先设定的门限μ,则该用户为偏离用户,将其从用户集合T中剔除。
步骤2从剩余的用户集合T中随机挑选L个用户做为每类的中心。
步骤3计算T中每个用户和这L个中心的角度差,并将每个用户划分到具有最小角度差的类中。直到T中的所有用户都被划分完毕。
步骤4重新计算划分完毕后每类的中心
步骤5重复步骤2至步骤4,直到所有类中的用户不再改变,或目标函数V(C)没有显著改变。
步骤6在每类用户中挑选出信道增益最大的作为该簇的强用户,信道增益最小的作为该簇的弱用户。
通过上面的分簇及选择算法,簇内两个用户将会有较强的信道相关性以及较大的信道增益差,不同簇用户之间的信道相关性则会相对较弱。
3 预编码矩阵设计
3.1 模拟预编码
OMA系统中,每个模拟预编码矢量只为一个用户设计[14]。而在MIMO-NOMA系统中,同簇两用户需共享一个预编码矢量,故其设计要兼顾簇内两个用户。为增大每簇用户的目标信号功率,同时减小该簇用户信号对其他簇用户造成的干扰,考虑基于SLNR最大准则的模拟预编码设计方案。
针对第l簇用户,基站从码本中选择令该簇用户的SLNR最大的波束作为该簇的模拟预编码矢量,即

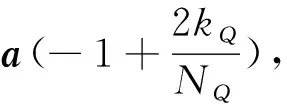
3.2 数字预编码
由于每簇容纳两个用户,故数字预编码不能彻底消除两个用户受到的簇间干扰。由于强用户端要进行SIC,为了保证强用户SIC的正确性,利用强用户的等效信道进行迫零(zero forcing,ZF)预编码,表示为
V=HH(HHH)-1。

其中,V(l)表示矩阵V的第l列向量。
经过数字预编码,强用户能够完全消除簇间干扰,而弱用户仍会受到簇间干扰。同时强用户可以通过SIC消除簇内干扰,则第l簇强、弱用户的SINR分别为
因此,这两个用户的和速率可表示为
Rl,i=log2(1+Tl,i) (i=1,2)。
4 功率分配
针对簇间功率分配,因为每簇包含用户数相同,且每簇用户的信道增益差别不大,故采用较简便同时能够达到次最优的平均功率分配准则[16],即
其中Pt为总发射功率。
簇内功率分配借鉴基于和速率最大的功率分配准则[4],则第l簇强用户功率分配系数为
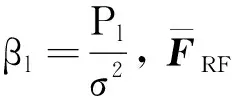
5 仿真结果及分析
在毫米波大规模MIMO-NOMA系统中,通过Matlab仿真来评估所给用户分簇以及预编码算法的有效性。设所有用户均匀分布在小区内,信噪比(signal noise ratio,SNR)从-20 dB到10 dB。表1是仿真具体参数设置情况。

表1 仿真参数
在不同筛选门限μ下,系统和速率随SNR变化的情况如图2所示。MIMO-OMA系统采用时分多址系统,即在用户分簇之后,令基站在前1/2个时隙服务所有簇内的强用户,后1/2时隙服务弱用户。从中可见,在μ=0.035时,所给算法可使MIMO-NOMA系统高于MIMO-OMA系统和速率。通过比较在门限μ变化时系统的和速率变化,可知随着μ的提高,系统和速率也随之提高。这是由于当门限提高时,分簇算法中的第一步对用户的筛选更加严格,更多偏离用户被筛选出来,K均值聚类效果更好,簇内用户信道相关性更强,通过ZF预编码之后弱用户受到的簇间干扰也随之降低,因此系统和速率提高。

图2 筛选门限对系统和速率的影响
利用3种分簇算法,即相关性用户分簇算法[4]、所给用户分簇算法以及随机分簇算法,系统和速率随SNR变化的情况如图3所示。其中随机分簇算法指的是从所有用户中随机地挑选两个用户作为一簇。观察可见,随机分簇算法最简便,但其性能最差,这是由于随机分簇算法没有考虑到用户受到的簇间干扰。另外,相关性用户分簇算法只是将信道相关性强的用户分为一簇,并没有考虑簇间用户的信道相关性。而所给用户分簇算法通过K均值降低了簇间用户的相关性,使弱用户受到的簇间干扰降低,从而提升了系统和速率。
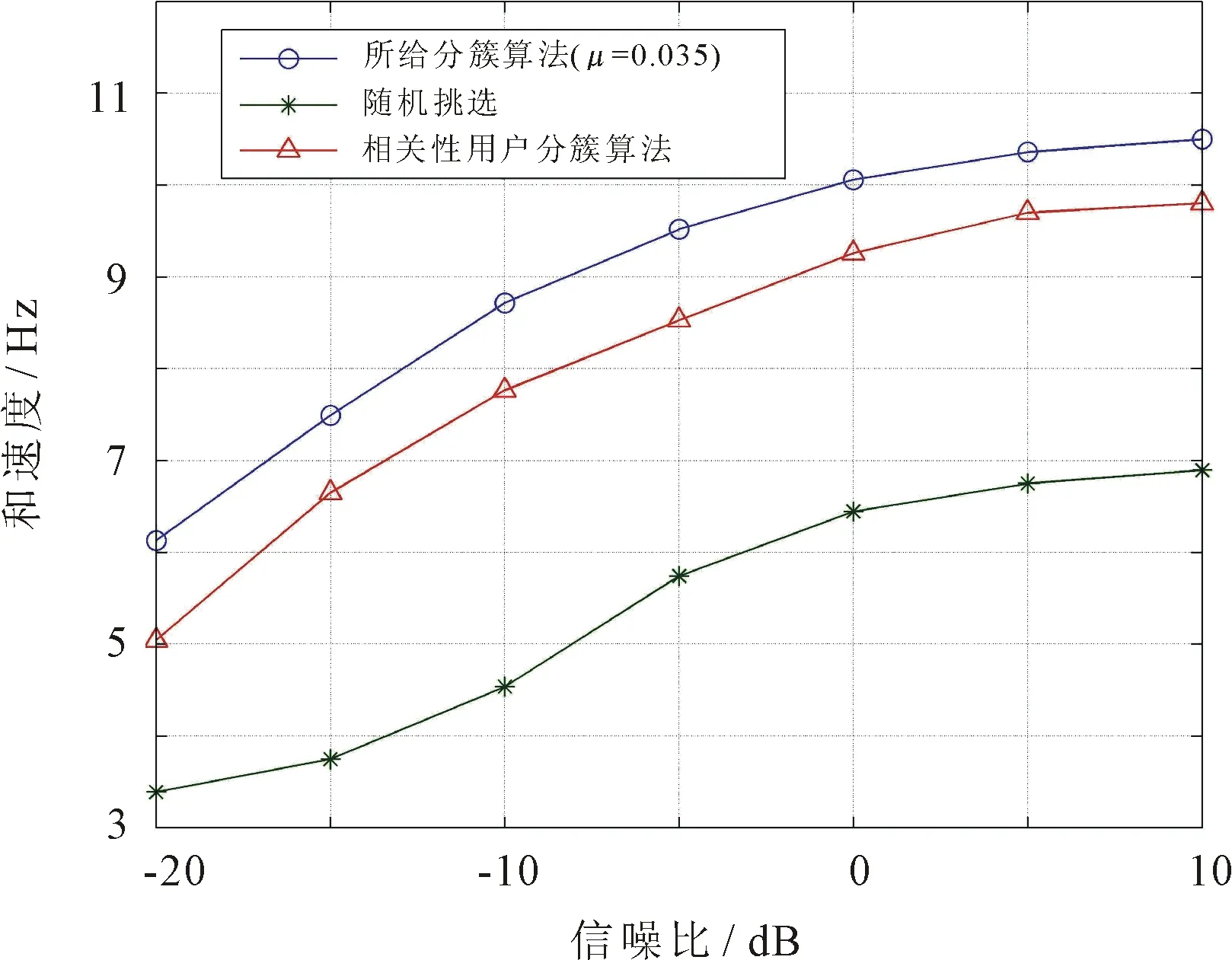
图3 分簇算法对系统和速率的影响
所给混合预编码算法和纯模拟算法[11]对系统和速率的影响结果如图4所示。从中可见,所给混合预编码算法性能要好于模拟预编码。这是由于模拟预编码只能够对信号进行相位上的改变,消除簇间干扰的效果不如提出的混合预编码,因此和速率性能较差。
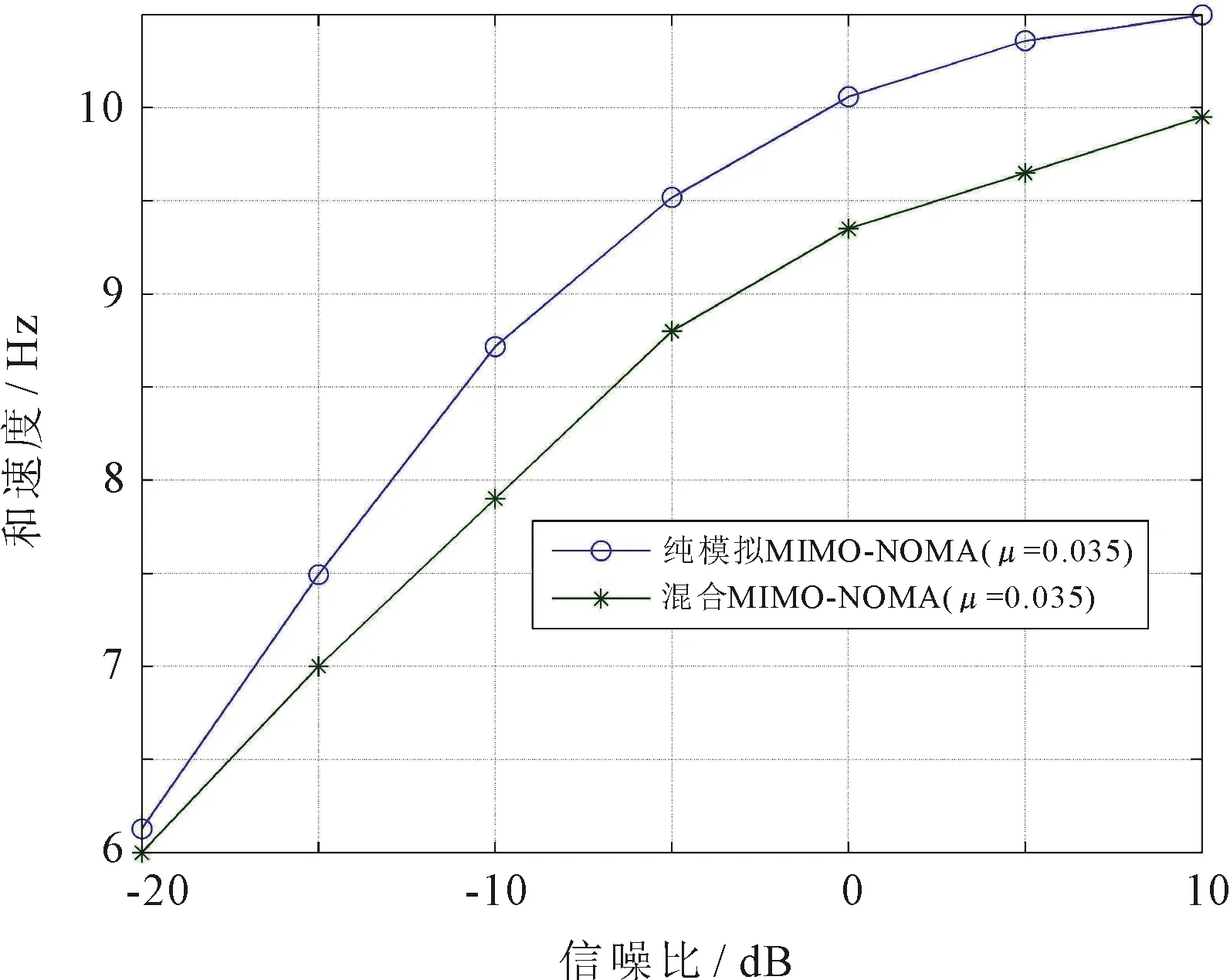
图4 预编码算法对系统和速率的影响
6 结语
MIMO-NOMA技术能够为系统提供更高的容量以及更大的接入量,是5G系统的关键候选技术之一。针对毫米波大规模MIMO-NOMA系统,本文给出了一种基于K均值的用户分簇及选择算法和基于SLNR最大的混合预编码算法。仿真结果表明,所给MIMO-NOMA系统比原MIMO-OMA系统具有更好的和速率性能;所给基于K均值的用户分簇及选择算法的和速率性能优于相关性用户分簇算法;所给混合预编码算法的和速率性能比纯模拟预编码更好;所给算法可降低用户的簇间干扰,进而提升系统性能。
猜你喜欢
火控雷达技术(2021年2期)2021-07-21
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
北京航空航天大学学报(2017年3期)2017-11-23
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
中国交通信息化(2016年8期)2016-06-06
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
