
增量学习的优化算法在app使用预测中的应用
2019-01-23 06:36李雯婷王庆娟周天剑
深圳大学学报(理工版) 2019年1期
韩 迪,李雯婷 ,王庆娟,周天剑
1)北京理工大学珠海学院,广东珠海 519000;2)澳门科技大学资讯科技学院,澳门 999078;3)贵州商学院计算机与信息工程学院,贵州贵阳 550014
智能手机在人们日常生活中的应用现已非常普遍.Google研究表明[1],全球一半以上的人拥有1部智能手机,而每部智能手机中平均约装有96个应用(application, app).大量的app和手机屏幕尺寸的限制,往往令用户花费大量时间来寻找特定的app.因此,急需一些能够帮助用户快速定位所需app的机制,这也是app使用预测技术成为目前手机操作系统研究热点的原因.但是,现有的大部分app预测机制都未考虑用户的历史数据是随用户爱好和app的状态改变而改变,一旦训练数据发生改变,部分app预测机制需要重建模型以保持预测的准确度,否则,预测准确度将大幅降低.
本研究首次提出app使用预测系统Predictor,利用优化后的增量模型IkNN(incrementalk-nearest neighbors)作为app使用预测的解决方案,通过对模型的空间优化排序,减少在app使用预测过程中的建模时间.值得注意的是,选择合适的k值能提高预测过程中的分类准确度[2].然而,随着app的特征越来越多,人们已经无法仅靠k值来提高准确度.这是因为IkNN模型通常使用欧氏距离等方法[3]来计算样本的相似性,当特征量超过阈值时,欧式距离很难发现样本与样本之间区别[4].本研究利用上下文的特征在预测中的特点,设计了聚类有效值(cluster effective value, CEV)方法,并用于IkNN算法中,以期区别噪声和小概率习惯(发生频率都很低),从而提高增量算法中的预测准确度.本研究首先实现了整套app使用预测系统Predictor,并用于真实环境中.该系统可根据不同的环境因素(如时间和地点等)和用户习惯(如是否插入耳机、蓝牙是否激活等),来预测用户期望打开5个apps预测结果,展现在用户手机的桌面上.大量实验表明, 与其他方法相比,Predictor方案能够减少建模时间的同时提高预测的准确度.
1 相关工作
目前的apps使用预测工作有两种优化方案.
第1类工作是优化组织数据.ZOU等[5]提出一些轻量级的预测方法(如LU和贝叶斯等算法),根据用户过往打开app的记录来预测下一个app的使用概率.PARATE等[6]增加了传感器的上下文来预测app启动序列.YAN等[7]提出的 FALCON利用与用户所处地点和空间信息有关的上下文来预测app的启动.HUANG等[8-9]强调app历史使用数据通过二次整理成上下文关系的数据比直接使用更准确有效.文献[10]介绍了基于时间、地点、硬件状态和环境等因素的上下文特征,作为预测app使用的数据.
第2类工作是优化数据的处理方法.PAN等[11]通过对用户社交网络上社交信息进行矩阵分解来实现app预测.KESHET等[12]通过对AUC(area under curve)模型最大化求解,动态预测一组最有可能启动的app集合.ZHANG等[13]提出app启动预测系统Nihao,利用朴素贝叶斯将日期、周次、地点和最近使用的app序列作为特征,实现了服务器客户端模型. Yahoo Aviate采用平行网络贝叶斯模型,利用并行网络结构解决了上下文关系中复杂的计算[1].
采用用户上下文关系特征作为输入数据时,默认的kNN算法会随着特征增加而变差.MILOUD-AOUIDATE等[14]介绍了此问题的解决方案,如BAILEY[15]提出的WkNN算法,在经典的kNN中增加了权重设置.WkNN和kNN的区别在于前者并非简单的取一个平均的k值,而是考虑了每个数据的权重,做了动态的k值规划.与此类似的方法还有压缩最近邻居规则(condensed nearest neighbour, condensed NN)算法[16]和减少邻居最近邻居规则RNN(reduced nearest neighbour)算法[17].这两种算法都通过多次优化训练数据来消除冗余数据,以此来减少默认kNN算法中的负面影响.
以上工作分别对缩短建模时间或者提高预测准确度都有较好效果.然而,这些方法要么预测准确度不够理想,要么在移动设备上非常消耗计算资源,导致建模时间过长.我们认为在对app使用进行预测时,仅需区分噪点和小概率习惯,就能提高预测准度.所以,本研究首次将增量IkNN模型应用到app使用预测当中,并设计了聚类有效值CEV策略.本研究与以往工作主要区别在于:首先,本研究模型是动态更新的.在移动设备上,app训练数据随着用户的喜好和环境变化而经常发生改变.本研究提出的增量优化算法能够平滑且容易对新加入的和改变的数据进行重构,显著减少建模时间.其次,app使用预测的数据结构比较复杂.针对复杂结构设计一些复杂的策略虽然会带来更精准的分类,但也会造成分类中的过拟合现象.本研究通过增加CEV策略来减少多维度特征带来的分类错误,提高了分类的准确度,在不同的数据集的准度测试中,能够体现稳定的预测性能.
2 上下文特征
实现app使用预测的过程通常包含数据预处理和预测模型两部分.这里讨论数据预处理中上下文特征的处理,从app的使用数据中提取上下文特征,再将上下文特征转换为可计算的相似度值.
2.1 提取上下文特征
常见的app点击事件流水如表1.当某个app动作被执行,会有一组相应的“基本特征”随之产生[1].例如,此次点击事件的时间、地点,以及是否打开WiFi等.
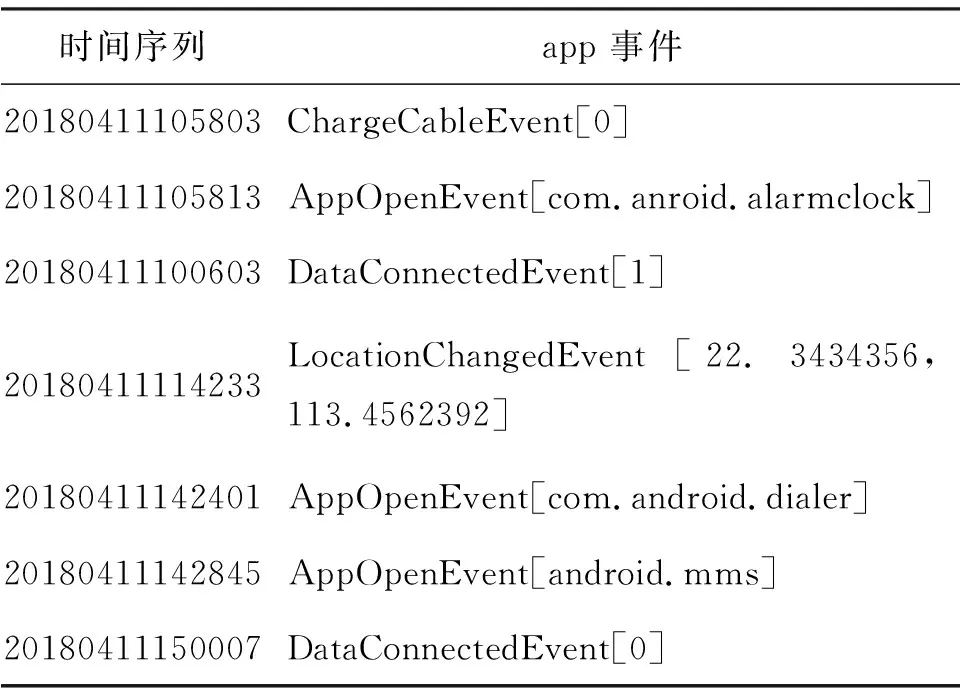
表1 一个app点击事件流水片段Table 1 A sequence of app events
值得注意的是,HUANG等[8]指出,若将以时间为顺序的“基本特征”整理为以事件为中心的“上下文特征”,则会提高预测结果的准确度.具体来说,就是要将发生的事件整理为“键-值”队的形式,即点击的事件为“键”,而围绕着事件发生的上下文特征为“值”.
如此又会产生新的问题——设置多少个上下文特征才适合呢?为此,本研究随机选取了平均每个用户在3个月内近1 500条app点击事件中,关于特征数量与预测准确度和对应预处理时间的记录.特征数量理论上没有限制,但基于移动端的处理能力和处理时间在可接受的范围内,本研究选取了2~12个特征所对应的记录.

表2 预测准度和预处理时间对应在不同数量的上下文特征数据Table 2 The prediction accuracy and preprocessing time with different numbers of session features
由表2可见,上下文的特征设置越多,准确度就越高,但也需要更多的预处理时间.因为需要转换为计算的向量,所以为了均衡预测准度和建模预处理时间,本研究采用以下8个上下文特征作为最终的输入数据:① 上一个打开的app;② 是否连接音频;③ 是否连接充电线;④ 是否发生位置改变;⑤ 是否连接WiFi;⑥ 是否有网络数据连接;⑦ 是否有蓝牙连接;⑧ 是否有光暗变化.
2.2 相似度值
取得上下文特征的目的是找出这些特征之间的相似性.而相似性的值可通过计算上下文特征之间的欧氏距离获得.所以,需要将上下文特征转换为距离向量,通用的方法是利用word2vec工具进行处理[18-19].在word2vec中,如果两个词(特征)非常相似,它们相似度值就比较小.所以,为便于描述和理解,本研究将相似度值序列化为0到1,再用1减去实际相似度值作为最终的呈现结果.
具体来说,给定一组app事件序列E, 当app打开事件e1∈E, 且有事件e2∈E, 它们对应的上下文特征分别为s1和s2, 则两事件的距离为
(1)
其中,s1i∈s1,s2i∈s2,i∈{1, 2, …, 8};s1i和s2i的相似度值similarity(s1i,s2i)可通过word2vec计得.
表3是部分上下文特征的记录日志.基于演示的限制,在此仅罗列了事件编号为3025、3528和4115的索引.

表3 一个上下文特征片段Table 3 A snippet of session features
从表3可见,编号为3025的点击事件,启动的应用为Android.mms,它上一个打开的app为Android.setting.这次点击事件是在用户刚刚到达家,连接了WiFi名为CR502的无线网络后发生的,操作时屏幕变亮了.
结合表3和式(1)可见,图1显示了事件3025、3582和4115两两之间的相似度关系.其中,事件3025和3582之间的距离是0.173 5,非常趋近于0,说明这两个事件的操作类似.事件3582和4115之间欧氏距离是0.779 1,说明这两个事件之间的联系不是特别强.值得注意的是,图1显示是平面图,而在实际环境中,实例之间的关系是多维度的空间向量图.
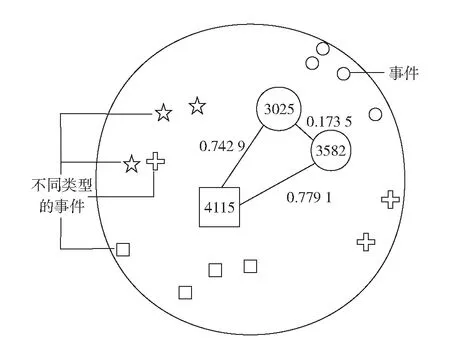
图1 事件3025、3582、和4115之间的距离关系Fig.1 The distance relationship between the events of 3025, 3582, and 4115
可见,本研究将上下文特征计算后的相似距离作为输入数据传送到预测模型.
3 预测模型
3.1 预测模型概述
在app使用预测模型中需要解决两个问题:
1)缩短建模时间.当增量数据到来时促使周期性重建预测模型,导致建模时间越来越长.
2)提高预测准度.调整预测模型中上下文特征的数量和特征权重在一个合适值.
对于问题1),带有增量的预测模型可节省建模时间.本研究通过与主流的增量模型对比,并根据实际环境特点,选取时间复杂度最小的IkNN模型[20],可缩短建模时间.
对于问题2),采用轻量级权重策略CEV,能够帮助区分在app使用过程中产生的噪声和真实小概率习惯的区别,从而提高预测准度.
3.2 增量模型
在默认的kNN模型中包含了对形成分类簇描述的四元组〈Cls(Oi), Sim(Oi), Num(Oi), Rep(Oi)〉, 它们表述的属性为:① Cls(Oi)为聚类Oi的名字; ② Sim(Oi)为聚类Oi的半径; ③ Num(Oi)为聚类Oi的实例数量; ④ Rep(Oi)为聚类Oi的中心点.
默认kNN模型聚类示意如图2.一个聚类的半径距离是中心a点Rep(Oi)到边际b点的距离.其中,圆圈表示正确分类样本.
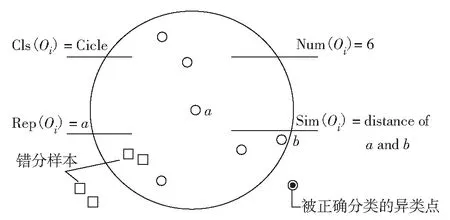
图2 kNN模型中的一个聚类示意图Fig.2 A cluster in kNN model
特别值得注意的是,若形成分类簇的过程中,包含的部分实例名与原类名不符,但又被划分在该类中,则称这些实例为“错分样本(erroneous classification instances, ECI)”,如图2中的方框,正确被分类在簇外的异类点为实心圆点.
初始时建模使用默认的kNN模型进行训练.当新数据到来时,利用带有增量的kNN模型(IkNN)去更新新模型.
IkNN模型在默认的kNN模型中添加了新的元组“层”(layer)概念[20],因此,IkNN模型属性包含了〈Cls(Oi), Sim(Oi), Num(Oi), Rep(Oi), Lay(Oi)〉五元组. 其中, Lay(Oi)为分类簇之间层级描述,通过此属性能够体现分类簇之间遍历的优先级.
在每一次IkNN模型处理增量的过程中,都需要判断新到增量数据是否能被已经形成的簇所覆盖.若增量数据满足被覆盖的条件,则标记为已覆盖集合(covered set, CS);否则,标记为未覆盖集合(uncovered set,US).
CS定义为:当新增实例到来时,若能被已经存在的分类簇所覆盖,则该聚类的五元组中的Num变量加1;否则,检查是否能够被最近扩展的簇所覆盖,若可以,则除了该簇的Num变量更新加1外,其半径Sim也需要更新.值得一提的是,当簇扩展时,关于该簇的错分样本ECI比例也会被更新,当该比例超过一定的阈值时,会被限定扩展.
US定义为:当新增实例不能被任何分类簇覆盖时,系统将收集这些实例做为一个新的分类簇,该簇内也许包含了新的习惯或噪点,并等待下一次增量数据到来后再做处理.同样,当未来该簇的ECI比例超过给定的阈值时,表明该分类簇需重新划分新的层值Lay来保证簇的ECI比例满足阈值.
为计算ECI比例,首先需计算ECI中关于实例Ej的权重
(2)
其中,dij是实例Ej距离簇Oi的欧氏距离;ri是Oi的半径.由于一个样本有可能被几个簇所覆盖,所以Qj表示Ej被覆盖所有簇的集合.
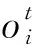
(3)
其中,ej为簇中的一个实例.
为缓和由于多维度带来的分类错误,本研究在形成新簇的过程中添加了CEV方法.
3.3 聚类有效值
值得注意的是,上下文特征在不同条件下对预测所起的作用不一样.为充分解释这一点,本研究分析了30位用户在100 d的数据集,结果如图3.

图3 打开所有app、浏览器和音乐播放器3种情况下,8个上下文特征的占比Fig.3 Percentage of the eight session features for all apps, browsers and music players, respectively
图3(a)给出了记录中每个特征总数分别在所有特征总数中的比例.如图3(a),在所有数据集中,不同的上下文特征比例是不相同的,如“上一个打开app”的属性是最高的,而“上一个蓝牙连接”属性是最低的,所以,不能采用相同的权重去处理不同属性.
图3(b)和图3(c)分别展示了浏览器和音乐app中不同上下文特征的不同影响.图3(b)显示了浏览器app中“上一个打开app”的属性是最高的,而图3(c)显示了音乐app中“上一个音频连接”是最高的.
大部分相关工作对上下文特征并没有区分对待.为此,本研究提出聚类有效值CEV方法来解决这个问题,在原有的IkNN模型中添加新的元组“贡献度(contribution)”,从而使新模型的属性包含了〈Cls(Oi), Sim(Oi), Num(Oi), Rep(Oi), Lay(Oi), Crb(Oi)〉六元组.本研究设计的最后一个元组包含高频性和稳定性两部分.以分类簇Oi的上下文特征m为例,其高频性定义为,上下文特征出现的频率gm和该簇内所有实例Num(Oi)的比值, 即
(4)
稳定性定义为上下文特征m变化的次数hm和该簇内所有实例Num(Oi)的比值.为让比值结果和高频性比例保持正相关,可用1减去该比值,即
(5)
最后如式(6), Crb(Oi)由发生频率最高和稳定性最好的特征加和决定.
(6)
当Crb(Oi)高于给定的阈值,则设CEV=1;否则,设CEV=0.
3.4 带有聚类有效值的增量模型
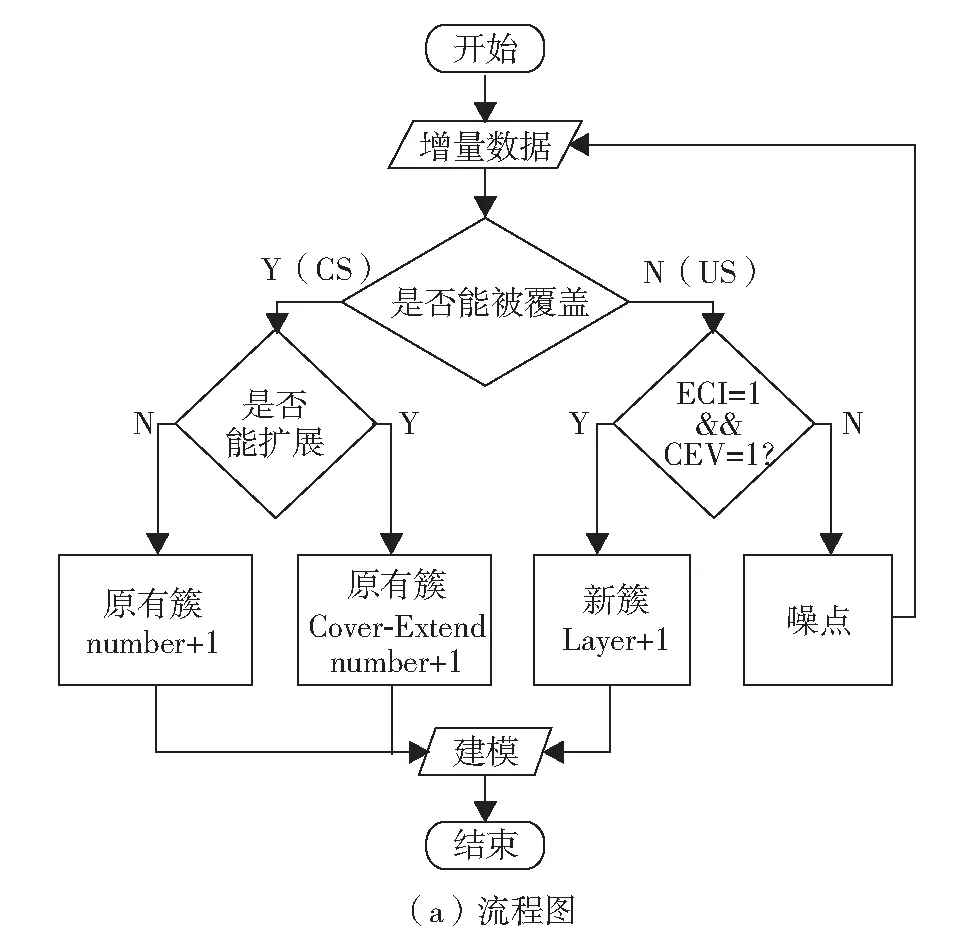
本研究将在增量学习的元组属性中添加Crb(Oi)参数,即添加带有CEV策略的增量模型,称为ICkNN模型.将该模型应用在实际环境中的解决方案Predictor,其流程如图4(a),对应的算法执行过程如图4(b).
当没有增量数据到来时,使用kNN模型做第1次分类.当有数据改变或增加时,首先判断这些新的数据是否能够被已有的模型所覆盖(CS),如果可以,则更新模型半径和数量等元组参数;如果不能被覆盖(US),就需要通过阈值判断是否形成新的模型簇,没有满足阈值条件,则等待下一次增量到来再做计算;如果阈值满足条件,即CEV=1,且ECI=1时,新的分类簇才会从顶层簇再次分离.最后,输出的模型作为下次数据到来时建模依据.
若分类严格,则形成簇的数据量增加,建模时间也会增加;反之亦然.所以簇的数量在算法复杂度中扮演非常重要的角色.图5分别显示了在ICkNN和IkNN模型中,簇的数量和k值之间的关系.在IkNN模型中,k的取值范围通常为5~13[14].若k<5, 则模型的预测准确度会较高,也会产生较多的簇,从而增加建模时间;若k>13, 产生的簇数量会较少,从而模型的预测准确度也会较低.因此,在ICkNN模型中可将k设置在5~7内,则Predictor不仅提供了平滑的分类,且不增加建模时间.

(b)ICkNN增量模型建模过程伪代码
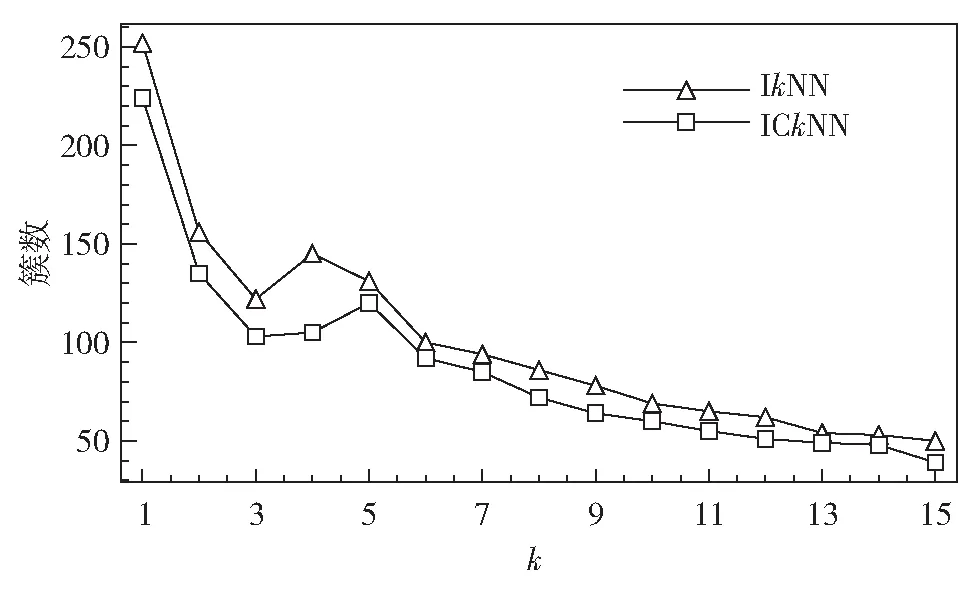
图5 ICkNN模型的簇数量Fig.5 The number of cluster in ICkNN
3.5 App使用的预测方案
Predictor对下一个app使用的预测方案如图6.当事件e作为输入数据送入ICkNN模型中,首先计算事件e和所有簇之间的距离.然后,若e被单个簇所覆盖,模型输出该簇的名字,如图6(a)中输出“电话”的app应用预测;若e同时被2个以上(含2个)的簇所覆盖,模型输出所有覆盖簇中较高层簇的名字,如图6(b)中输出“短信”的app应用预测;若事件e不被任何簇所覆盖,则模型输出距离最近的簇名,如图6(c)中输出“邮件”的app应用预测结果.
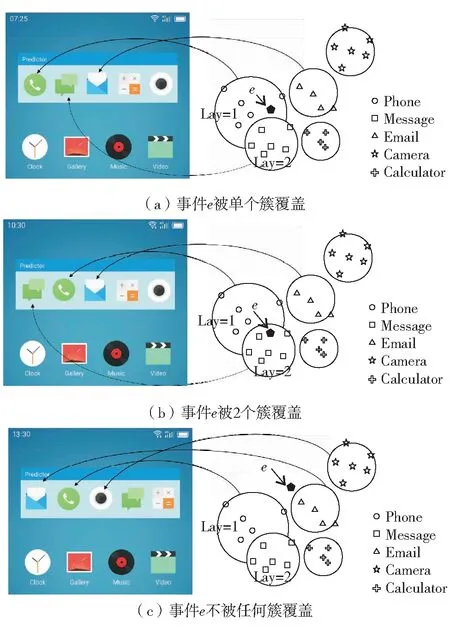
图6 App使用预测场景Fig.6 (Color online) Scenarios of app usage prediction
4 实 验
为验证ICkNN模型的性能,本研究选取30个活跃用户在100 d内用Predictor记录的数据.用户群体为大学在校师生,年龄在18~55岁,且每位用户所安装的app超过50个.本研究在这些用户的手机端以每5 s(不停止)1次的频次记录该手机的使用情况,并将所提取的上下文特征向量在电脑上利用VM ware模拟器来仿真分析主流手机的处理能力.
4.1 测 试
使用交叉验证的方式测试不同算法的性能,这些算法包括lastest used (LU)算法[5]、most frequently used (MFU)算法[5]和tree augmented Naive byes (TAN) 算法[1].将日志数据平均分为10份,在第1次测试中,将第1~5份数据作为训练数据去建立app使用预测模型,并将第6份作为增量数据.而在第2轮测试中,将第1~6份作为训练数据,第7份数据作为测试数据,依此类推.通过分析在此过程中的建模时间和平均准确度两个推荐系统评价指标[10],其结果如表4.
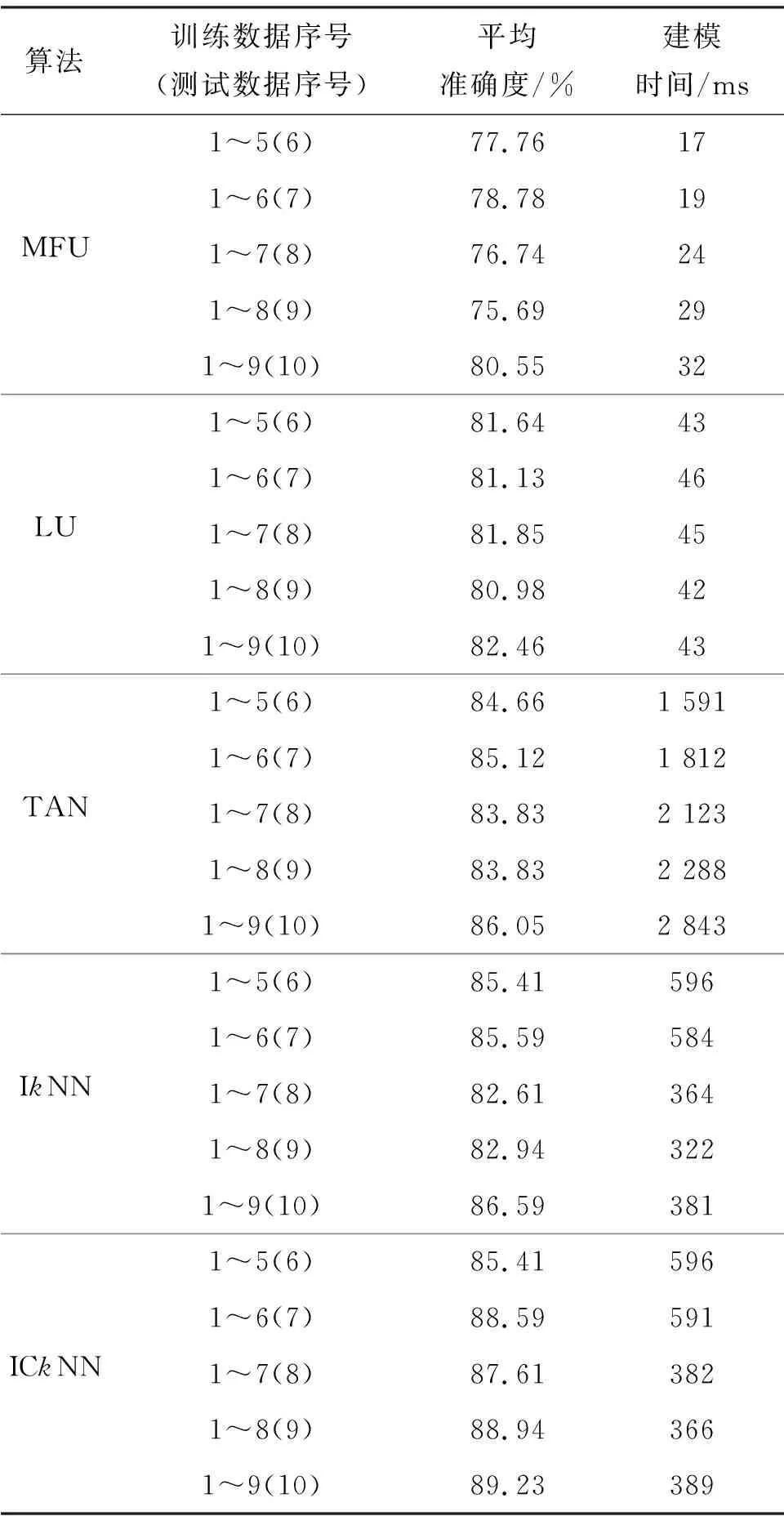
表4 不同app使用不同预测算法时的性能Table 4 Performance of different algorithms on app usage prediction
4.2 分 析
由表4可见,① LU和MFU算法的建模时间比其他算法更短,这是因为IkNN、ICkNN和TAN算法需要建模的计算时间,但是LU算法和MFU算法仅需简单地计算app的使用频率并排序; ② ICkNN算法的平均准度最高,且其在5轮不同的数据集中表现的预测准确度变化不大,亦即预测结果比IkNN算法显得更稳定一些.
图7显示了平均准确度和预测的app数量之间的关系.由图7 可见,IkNN、ICkNN和TAN算法在输出5个app时预测结果的平均准确度要比LU和MFU算法的准确度更高一些.IkNN、ICkNN、TAN、LU和MFU算法之间平均准确度随着预测的app数量减少而变大.特别是TAN算法,在预测单个app时最准确.
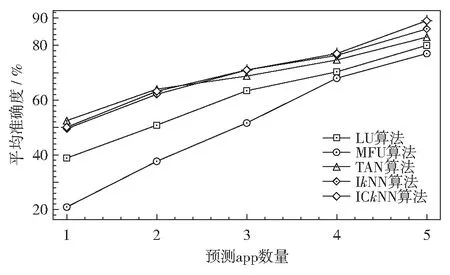
图7 不同算法下预测app的平均准确度和预测app数量间的关系Fig.7 The average accuracy versus the number of predicated apps for different algorithms
结 语
本研究关注当用户偏好和app状态发生变化时,如何减少预测的建模时间和提高预测的准度.通过引入增量学习算法避免新到数据需要重新建模的问题.同时,提出带有CEV策略的ICkNN模型来区分小概率实践和噪点之间的区别,从而提高了预测的准确度.通过实验测试了ICkNN模型和主流预测算法LU、MFU,以及TAN模型的性能.结果表明,MFU和LU有比较高的准确度和很短的建模时间,但是当预测的app较少时,他们的预测准确度很低,IkNN和ICkNN模型要比TAN的建模时间要短,而ICkNN模型平均预测准确度在所有主流预测算法中是最高的.
下一步我们将结合云计算,当用户第1次使用Predictor时,提供app使用预测的冷启动工作,为新用户在云端寻找最相似用户作为该用户的冷启动的app推荐列表.
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
中学生数理化·中考版(2019年9期)2019-11-25
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
中国交通信息化(2016年5期)2016-06-06
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
