
浅析人工智能在辞书编纂中的应用
——以收词立目为例
2019-01-24 01:23
新闻传播 2018年23期
(上海理工大学 上海 200093)
近年来,人工智能发展势头迅猛,对各行各业都产生了深远的影响,体现在辞书出版领域即人工智能技术在辞书编纂现代化中的应用。众所周知,传统的辞书编纂是一项劳力费时的工作,动辄“十年磨一剑”。尤其是收词立目,工作量巨大。因此,收词立目的智能化对辞书编纂现代化至为关键。本文试图对如何利用人工智能促进收词立目的智能化进行初步探讨。
一、收词立目是辞书编纂的基础
一部严肃编纂的辞书,基本上要经历“确定体例、收词立目、编写条目、编辑加工”等诸多知识创造的过程。新辞书的编纂体例确定之后,收词立目就成了辞书编纂的基础。《汉语大词典》的编纂中,动用了华东地区五省一市的专家学者,从1万多部典籍(报刊)中,制作了800多万张资料卡片,才编写出了5000万字、37万多条目的皇皇巨著。这1万多部典籍(报刊)中,《新民晚报》《鲁迅全集》《四库全书》各算1种。
(一)资料的积累
实际上一些中小型辞书的编写,是在作者平时资料的积累之上实现的。如王均熙先生的《汉语新词词典》,就是其积累了大量汉语新词的资料后,开始了这一辞书的编写。其编写和修订长达二三十年。
陈尚君先生在《我作〈辞海〉修订》一文中也曾阐述,“1989版《辞海》,唐宋文学部分修订费时在半年以上。此后几次费时没有这么多,因所涉问题已熟悉,且有长期关注积累。”
可见,收词立目是传统辞书编纂的重要一环,也就是说,资料的积累是辞书编纂的基础。
(二)收词立目是知识含量巨大的工作
在辞书的编纂中,收词立目是一项旷日持久、费力巨大的工作,也是知识含量巨大的工作。
如以《汉语大词典》为例,从1万多部典籍(报刊)中,制作了800多万张资料卡片,平均每部典籍(报刊)约收录了800张资料卡片。考虑到这些典籍中不乏《四库全书》《四部备要》《四部丛刊》《二十四史》《全唐诗》《全宋词》《鲁迅全集》等丛书、类书、合集等,因此一部书平均只制作800张资料卡片——其圈词率非常之低,所制作的资料卡片质量极佳。这与《汉语大词典》编纂初期,有大批被闲置的专家学者参与了《汉语大词典》的编纂工作有关。他们渊博的知识极大地提高了这批资料卡片的质量。在国家转入四个现代化建设后,专家学者纷纷回到了自己的工作岗位上。现在如果再有类似项目,将无法召集如此多的专家学者参与其中。
二、计算机技术的应用对收词立目的帮助
计算机技术中汉字显示技术、汉字输入法、数据库等技术的发展,极大地帮助了辞书编纂工作的数字化,推进了辞书编纂现代化的发展。国内多家出版社纷纷建立了各类辞书数据库,编纂平台的研究与应用也十分火热。尤其是计算机技术中统计与匹配技术的运用,解决了汉语词语的切词问题,使汉语新词的发现变得不费吹灰之力,从而解决了汉语新词的收词立目难题,极大地帮助了辞书编纂与修订工作。
例:2004年复旦大学宋国梁老师在易文网演示的汉语新词确认原理

计算机技术解决汉语新词的发现与确认,对于解决辞书编纂中新词的例证收集与语义分析有很大的帮助,解决了新词的收词立目问题。然而对于辞书编纂中旧词新义的发现,以及汉语高频词如何能精选出有典型意义的例证,目前的实际发展情况仍然是困难重重。
三、语义理解的瓶颈下收词立目的两大难题
(一)难题一:旧词新义的发现
旧词新义主要有两类。
一是旧词中被遗漏的义项。
数千年传承的中华民族文化博大精深,卷帙浩繁,在已经编纂的辞书中遗漏一些不常用的义项,是很正常的事。在渺如烟海的典籍中检索某个词,检索的结果可能会达数万个,甚至数十万个。这数万、数十万个用例中,有很多的义项都是相同的。从中找出被遗漏的义项,无疑是沙里淘金,需要花费大量的功夫。以前的这类工作,主要靠学者在平时的积累与发现。而面对浩繁的典籍,无法再用专家学者收词立目时的传统阅读辨识方法进行。
二是旧词在新环境下产生的新义项、新的语法功能。
在语言的发展中,很多新的义项的表达,往往采用旧词赋以新义的方法来实现。由于目前的辞书编纂平台中缺乏语义的辨析功能,因此还无法实现对这类旧词新义的发现。
旧词新义的发掘,是辞书编纂中,新辞书编纂和旧辞书修订的一个重要部分。目前仍是靠个别专家学者日常阅读中的发现进行记录保存。诚如陈尚君先生所言,只能靠“长期关注积累”。
(二)难题二:如何精选出高频词的经典例证
高频词在语料库中大量存在。编纂一部新的辞书,如果仅仅依靠对语料进行切词处理来解决高频词的义项和例证,一些高频词的数量将是成千上万。筛选的工作将不堪之重。如副词“的、地、得”,在语料库中的数量非常多,筛选的工作量非常之大。
从目前来说,旧词新义的发现以及如何精选出高频词的经典例证,仍然是辞书编纂现代化中还没有逾越的一个顽障,计算机语义理解的瓶颈阻碍了辞书编纂现代化的发展。
四、运用人工智能高效率解决收词立目难题的可行性
与辞书出版界在词汇的语义分析前踌躇不前相反,中文信息的计算机处理却在高歌猛进。2014年的中国计算机学会中文信息处理专业委员会的学生会员比赛中,已经能对140字的微博进行情感分析。因此运用中文信息处理的人工智能,将之与辞书编纂平台技术相结合,可以高效率地解决收词立目中旧词新义的识别难题。
在辞书编纂现代化中,人工智能施展的舞台极其广阔。仅从收词立目的角度来看,起码可以在两个方面着手,解决收词立目的瓶颈问题。
(一)可以帮助发现旧词新义
上面谈到了在浩繁的典籍中,寻觅旧词新义的难度在于对语义的分析。而在下面的工作流程中,添加了人工智能对语义的分析,就可以帮助实现旧词新义的辨析。
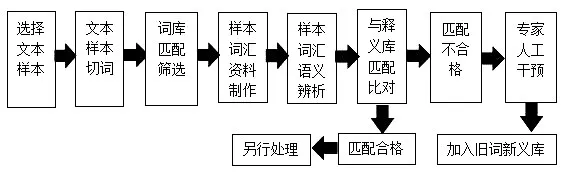
上面的处理过程中,在完成词库匹配并确认为一个词时,智慧系统可以自动进行该词的资料卡片制作。
如果是初级的智慧系统,在制作资料卡片时可以自动截取出现该词部分的前80字和后80字(此处80字仅为举例说明),并自动将这段文字中最早出现的表示句子完成的标点符号(如句号、感叹号、问号等)之前的文字和该标点符号剔除,再剔除这段文字最后出现的表示句子完成的标点符号之后的文字和符号。然后自动配上该文本的篇名、作者名、章节等基本信息,即完成了该词的资料卡片制作。
如果是高级的智慧系统,可以直接对该词的前后文字进行截取和分析,然后完成该词资料卡片的制作。
完成资料卡片的制作后,智慧系统将自动进行语义的辨析,随后与已有的释义库进行匹配比对。如果释义库已经有了该项释义,则该词将被另行处理或直接放弃。如果释义库中没有该词(即匹配不合格),即呈送专家进行人工干预,确认为旧词新义后,归入旧词新义数据库。
(二)可以解决高频词经典例证的精选
之所以说辞书编纂过程中的圈词是含金量非常高的工作,在于专家圈词时可以自动将一些高频词的出现忽略,但同时对具备典型义项的高频词例证非常敏感,不会疏漏。这就对模仿人工智能的智慧系统提出了更高的要求:既要能自动筛选掉高频词中无典型语义的例证,又要能迅速抓取高频词中具有典型语义的例证。
上面的处理过程中,要求智慧系统能够自动分析高频词在具体语境中的语义,然后自动与释义库该词条下的所有义项进行语义的匹配比对。如果释义库中已经有了该项释义,则该词将被另行处理或直接放弃。而解决高频词义项的精选,正是“另行处理”中的一例。例如可以补充某个词的某个义项的更早出处,或更典型的用例。
结语
在计算机技术的推动之下,辞书编纂的现代化已经有了长足的发展。但应该说,还没有充分利用计算机学界已经研发的新技术和新成果,导致在辞书编纂的某些环节中遇到了瓶颈,阻滞了辞书编纂现代化的进程。而从本文的初步探讨中,我们可以看到,充分运用人工智能技术对语料进行语义的智能分析,从而突破旧词新义的发现和高频词经典例证精选的两大难题,是切实可行的。可以说,人工智能是新时代背景下推进辞书编纂现代化的最佳利器,其发展空间极为广阔,有待业内人士进一步探索。
猜你喜欢
辞书研究(2022年2期)2022-03-19
小康(2022年7期)2022-03-10
小康(2022年7期)2022-03-10
汉字汉语研究(2021年1期)2021-06-11
小康(2021年7期)2021-03-15
小康(2021年7期)2021-03-15
疯狂英语·新悦读(2020年1期)2020-02-20
铜仁学院学报(2018年7期)2018-09-08
文学教育(2017年11期)2017-10-23
阅江学刊(2015年5期)2015-06-22
