
视频实时评论的深度语义表征方法
2019-02-20 08:33吴法民吕广奕何伟栋
计算机研究与发展 2019年2期
吴法民 吕广奕 刘 淇 何 明 常 标 何伟栋 钟 辉 张 乐
1(中国科学技术大学软件学院 合肥 230051)2 (中国科学技术大学计算机学院大数据分析与应用安徽省重点实验室 合肥 230027)

Fig. 1 Time-sync comments for videos图1 视频实时评论
随着互联网技术的进步,在线共享媒体已经得到了突飞猛进的发展,并极大地丰富了人们的生活.与此同时,一种被称作“弹幕”的新型视频实时评论在国内外视频共享平台中越来越受到大家的关注,如中国的bilibili、爱奇艺、优酷,日本的niconico等网站,弹幕在视频中扮演着极其重要的角色.在这些视频共享平台中,用户可以在观看视频的同时发送评论消息(称为弹幕).与传统评论不同,弹幕评论可以在视频的播放过程中实时呈现,增进了用户之间的互动,改善了用户的体验.弹幕不仅包含文本信息,还包含该评论在视频中出现的时间信息,即:允许用户针对视频中的某个片段进行实时评论,使得在播放视频时,评论像“大量子弹飞过屏幕”,“弹幕”也因此得名[1].
弹幕机制具有诸多特点.一方面,弹幕实时性的特点使得其与视频的联系更加密切,视频实时评论在很大程度上影响视频的流行程度[1-3].有研究表明,视频的流行程度和该视频之前的评论观点以及评论数据量呈正相关性[2,4].另一方面,在观看视频的同时阅读或发送弹幕,也成为了一种独特的社交方式,这种观众之间通过评论交流的方式极大地满足了现代人排解寂寞的心理需求,使得越来越多的用户更青睐于观看带有弹幕的视频.因此,作为一种众包短文本的代表,弹幕拉近了人与互联网信息的关系,也促进了人与人之间的交流,成为以人为中心的媒体信息交互纽带.总的来说,以弹幕为代表的众包短文本,对于在线媒体分享平台,甚至娱乐产业都有着重要意义,而针对此类短文本展开研究,为推荐系统、计算广告学以及人工智能等领域的发展提供了新的机遇,对于互联网、经济、教育、科研等行业具有巨大价值.
然而在弹幕带来新机遇的同时,这种面向视频的众包短文本分析也存在着诸多挑战,如图1所示.首先,由数以万计的用户生成的弹幕数据具有很高的噪声.弹幕的噪声主要源于2方面:一方面,用户的弹幕内容具有随意性.在共享视频评论的场景下,用户受到其他用户或者自身情绪的影响,可能发布与视频内容无关的弹幕,如:“看饿了…”、“Σ(° △ °|||)︴”等.另一方面,用户的表达方式具有随意性.在通常情况下,用户不会像一般的评论那样刻意严谨的对待所发布的弹幕内容,进而会产生一些输入的错误,比如“何晕东好堎”,事实上是用户想表达“何润东好嫩”,但由于拼写时带有方言导致产生了错别字.这些表达均具有偶然性,不属于用户约定行为,因此没有规律难以过滤,给弹幕的理解和研究带来了困难.其次,弹幕中充斥着大量网络用语.视频弹幕来源于网络共享视频平台,具有网络平台的共有特性,存在大量网络用语和不规范的表达.比如数字的谐音:“233”来源于“哈哈”笑的表情库,被用来指代“啊哈哈”,表示大笑的意思,“7456”则指代“气死我了”等;英语拼音的谐音:“海皮”在视频评论中可能就是指代“happy”缩写;汉字的谐音:由于为了增加幽默效果和方言种类繁多等导致的替用,比如“内流满面”指代“泪流满面”等.这些网络用语的大量使用进一步增加了弹幕相关研究的困难.最后,弹幕文本中普遍蕴含着隐含语义.这一点在以动漫为代表的ACG(animation,comic,game)视频中体现得尤为明显.由于视频观众中存在各种小众群体,这些群体经过长时间的交流,约定俗成了一系列独特的表达,如“前方高能”、“失踪人口回归”;与此同时,对于像“元首”、“哲学家”、“老师”等词语在某些特定剧情下则具有和原来完全不同的含义 ;而诸如“鬼畜”、“蓝蓝路”等则属于完全新造的词语.弹幕中的隐含语义,有悖于正常的自然语言,如何正确理解弹幕的深度含义是对弹幕及视频进行分析建模的最大挑战.综上所述,视频实时评论的高噪声、不规范表达和隐含语义等特性,使得传统自然语言处理(natural language processing, NLP)技术具有很大局限性,因此亟需一种容错性强、能刻画短文本的深度语义理解方法.
针对以上挑战,本文提出了一种基于循环神经网络(recurrent neural network, RNN)的深度语义表征模型.该模型建立在“相近时间段内的视频实时评论具有相似语义”的假设上,实现将离散的、不定长的文本序列映射为连续取值的、低维的语义向量,使得语义向量能够精准地刻画对应弹幕所表达的语义信息.特别地,该模型由于引入了字符级别的循环神经网络,避免了弹幕噪声对文本分词带来的影响;而在实现语义表征的过程中,通过使用神经网络,使得所得的语义向量能够对弹幕进行更深层次的刻画,表达其隐含语义.在此基础上,针对弹幕文本具有隐含语义的特点,本文进一步设计了基于语义检索的弹幕解释框架,同时作为对语义表征结果的验证.该框架利用语义向量创建索引,从而对于给定弹幕,通过检索与其语义相似但表达不同的弹幕来对其进行解释.
最后,本文设计了序列自编码、词袋特征索引、编码器解码器等多种对比方法,并通过BLEU(bilingual evaluation understudy)、流畅度、多样性等多种指标以及人工评价对本文所提出的模型进行充分验证.实验结果表明这种基于循环神经网络的深度语义表征模型能够精准地刻画弹幕短文本的语义,也证明了关于弹幕相关假设的合理性.
1 相关工作
本节将从弹幕分析及应用、表征学习模型、文本表征模型这3个方面介绍视频实时评论(弹幕)的相关工作.
1.1 弹幕分析及应用
弹幕视频是一种新型视频互动方式,以其独特的互动交流方式备受广大互联网和视频爱好者的喜爱,并迅速风靡国内外视频共享平台,如对于中国的bilibili、爱奇艺、优酷,日本的niconico等网站,弹幕视频扮演着极其重要的角色.然而目前关于弹幕视频的研究还很少.国内外对于弹幕的分析大多停留在基于弹幕的统计特征,以统计和自然语言处理技术,研究视频实时评论情况以及视频评论和视频之间的关系.其中,基于统计的有:文献[5]提出基于统计的方法识别一个弹幕评论的词汇是否是个外来词或视频内容无关词.基于自然语言处理的有:文献[6]借助自然语言处理技术和统计学知识,研究视频评论的情感和视频流行度之间的关系;郑飏飏等人[7]利用自然语言处理技术,提取弹幕中的情感数据实现对视频的评论的情感可视化,获取网络视频的情感特征和走势,并通过给视频打情感标签的方式,达到从情感角度实现视频的检索.文献[8]提出基于时间的个性化主题模型(TPTM),该模型结合视频评论,为相应时间段的视频生成主题标签.文献[9]提出了基于语义关联的视频标签提取方法,通过对弹幕数据的相似度分析,建立语义关联图,根据关联图的模型获取视频的主题分布给视频打标签,同时根据提取的弹幕主题信息,过滤跟视频无关的弹幕.文献[10]提出了基于隐语义模型的网络视频推荐算法(video recommender fusing comment analysis and latent factor model, VRFCL),从网络视频入手,分析观看者对某特定视频的感情倾向值,抽取评论关键词作为视频元数据,从隐语义特征的角度建立用户-视频二元组.然而,目前这些基于统计和自然语言处理技术的研究,并不能解决视频实时评论的高噪声、不规范表达和隐含语义等问题.
1.2 表征学习模型
深度学习是一种多层描述的表征学习,把原始数据通过一些简单的非线性的模型转变成为更高层次的、更加抽象的表达.通过积累足够多的上述表征转化,机器能学习非常复杂的函数[11].深度学习中的重要思想就是自动提取特征,也就是表征学习,故深度学习有时也被称作表征学习或者无监督特征学习[12],通过设定所需达到的学习目标,自动地从原始数据学习有效的特征,而无需具体的领域知识作为先导[13].近些年,深度学习在语音识别、图像处理、文本处理等多个领域取得重大进展,证明了表征模型是个很有效的处理方式[14].
学术界和工业界的研究者,将深度学习、表征学习等算法应用在语音领域,通过将语音特征学习和语音识别的目标转化为对原始光谱或可能的波形的特征学习的过程[15],给语音识别带来巨大影响和突破性的成果.2012年,微软发布了新版本的音频视频搜索服务语音系统,正是基于表征学习[16].在音乐方面,表征学习的应用使得在复调转录中击败了其他技术,获得了极大改善,并赢得了MIREX音乐信息检索比赛[17].图像识别方面,早在2006年通过MNIST数字图像分类,以1.4%的错误率优势超越了支持向量机[18],从此在数字图像识别方面表征学习一直保持独特的优势.鉴于表征学习在数字图像识别方面的效果,相关专家学者利用表征学习从数字图像的识别,应用到自然图像的识别.比如在ImageNet数据集上,通过表征学习实现了将错误率从26.1%下降到15.3%的突破[19].
自编码器是深度学习中非常常见的一个表征模型框架.该框架最早使用在机器翻译领域,机器翻译是把一种语言转换成另一种语言的过程,即输入一个文本序列,输出另外一个语义相同但是结构不同的文本序列.随着自动编码框架在机器翻译领域的成功应用并取得不错的效果,该框架已经从机器翻译扩展到其他领域.输入数据到编码器,解码器还原出原始的输入数据,自动编码器可以分为2个部分,即编码器和解码器.编码器部分生成语义向量,当前使用最多的表示技术是循环神经网络,实际应用过程中根据处理问题的情况,经常用到是基于循环神经网络的变种模型:长短期记忆神经网络(long short-term memory, LSTM)、门控制单元循环神经网络(gated recurrent unit, GRU)、双向循环神经网络(bidirectional recurrent neural network, BiRNN)等模型.解码器是对编码器生成的序列进行解码的过程,最常见的模型是循环神经网络语言模型 (recurrent neural network language model, RNNLM)[20],在自然语言处理中具有很好的效果,越来越受到自然语言处理相关领域的人员的重视.Glorot等人[21]通过提取出评论的深层特征,解决了传统文本分类算法跨领域分类不理想的问题.文献[22]采用深度自编码器,通过改进词汇的翻译模型,从而有效地提取特征集,在机器翻译过程中取得很好的效果.
1.3 文本表征模型
近年来,随着深度学习技术在自然语言领域的发展,词表征模型由于其低维、连续的特征表示方式和挖掘文本潜在语义的能力,在自然语言处理领域越来越受到重视.通过对文本数据进行深层次的抽象和挖掘,建立数据表征来进行特征表示和复杂映射,从而训练有用的表征模型.Hinton等人[23]引入分布式表征用于符号数据的分布式表示,Bengio等人[24]首次将词分布式表征通过神经网络模型应用于上下文的统计语义模型.基于学习词的分布式表征又称词嵌入,Collobert等人[25]通过增加卷积层开发了senna系统,实现了在语言建模、词性标注、命名实体识别、语法分析等任务中共享表征.文献[26-27]指出自然语言处理领域通过将词、字符转化为低维的实数向量的词嵌入技术,使得处理结果得到明显改进和提升.文献[28]设计了一个字符级别的双向LSTM的循环神经网络(RNN)模型,该模型在语言表征和词性标注(part-of-speech tagging, POS)标签方面展现出强大的性能.在机器翻译领域,文献[29]对原输入数据或目标输出数据使用字符级别的RNN结构,产生一个“字符-字符”的翻译生成结构.在隐含语义表示方面,深度语义匹配模型(deep structured semantic models, DSSM)[10]利用多层神经网络把搜索关键词和文档注入到低维空间,通过计算相似度,挖掘隐含语义.在信息检索领域,使用字符的n-gram作为神经网络的输入,进行信息检索模型的训练[30].
2 问题定义与方法
传统自然语言处理技术具有很大局限性,无法解决视频实时评论的高噪声、不规范表达和隐含语义等特性,因此亟需一种容错性强、能刻画深度语义的短文本理解方法的需求.本文基于“相近时间段内的视频实时评论具有相似语义”的假设,提出了一种基于循环神经网络(RNN)的深度语义表征模型,并设计了基于语义检索的弹幕解释框架.本节对相关问题、深度语义表征模型、基于语义检索的弹幕解释框架进行介绍.
2.1 问题定义
弹幕跟视频和时间具有高度关联性,按如下格式符号化一个弹幕:D=Vid,Did,s,t,其中Vid是弹幕所在视频的标识符,Did是弹幕的标识符,s是弹幕的文本内容,t为弹幕的时间,该时间为弹幕在视频中出现的时刻.
定义1. 视频实时评论的深度语义表征.给定的弹幕D=Vid,Did,s,t,该表征的目的是通过D学习一个表征模型(编码器)φ,使得对于任意弹幕Did可获取相应的语义向量vi=φ(si),并且满足对任意的si,sj的真实语义相似或具有相关性,则vi,vj具有相近的距离,否则vi,vj距离较远.
视频实时评论的深度语义表征模型学习过程中,需要使用语义相似或相关弹幕进行训练,关于语义相似性弹幕的获取存在如下2个挑战:
1) 若语义相似或相关弹幕的获取采取人工标注的方式获取,将会带来巨大的人力成本,同时也会限制模型的实际应用范围.
2) 鉴于模型的实际应用性,需能自动获取语义相似弹幕.然而,如何使选取的语义相似弹幕具有最佳近似语义相似性,是语义相似弹幕获取的最大挑战.
鉴于语义相似弹幕获取的挑战,本文从弹幕的特征出发,分析弹幕数据的特点.弹幕实时性的特点,使得其与视频的联系更加密切,导致视频的同一个情节、一个画面出现的弹幕大多数都是基于这个情节或者画面的评论;另一方面,在观看视频的同时阅读或发送弹幕,也成为了一种独特的社交方式,有时候,弹幕的内容不一定是针对视频内容的评价,很可能是弹幕发送者之间的对话,也有可能出现某个观众很感兴趣的弹幕,其他弹幕发送者对该弹幕的评价.然而,不管是对视频内容的评价还是弹幕发送者之间的交互,特定时间内的弹幕一般都具有相似性.通过对弹幕特性的研究和大量的统计,本文提出弹幕语义相似性假设.
假设1. 弹幕数据语义相似性假设.基于视频的实时评论是对视频内容的评价或弹幕发送者之间的交互,往往一个情节、一个画面中一起出现的评论具有语义相似性,相近时间段内的实时评论具有语义相似.
视频中会有视频场景突然转换的场景,往往伴随着弹幕的语义也会跟着转换.同时,当出现观众感兴趣的弹幕,往往也会伴随着弹幕话题的转变.这种弹幕语义的突然转变,是弹幕语义相似性假设的一大挑战.然而,无论视频情节、画面还是弹幕发送者的话题都具有连续性,当弹幕数据量达到一定时,这种干扰情况比例很少.接下来,通过定义对语义相似弹幕的获取进行量化,以便能通过实验对弹幕语义数据语义相似性假设的合理性和科学性进行验证.
定义2. 语义相似弹幕.对有Vid,Did,s,t格式的弹幕,若Vidi=Vidj,|ti-tj|<δ,则si,sj为语义相似弹幕.其中,δ的取值需根据实验结果,选取合适的大小.
由语义相似弹幕的定义,可以得到语义相似弹幕集合G={s1,s2,…,sn},∀si,sj∈G,i,j∈{1,2,…,n},有|ti-tj|<δ.
接下来介绍实现深度语义表征的方法和损失函数.根据语义相似弹幕的定义,可以对弹幕按时间切分,寻找语义相似弹幕.基于自编码是深度学习领域非常常用的框架,已成功用于降维和信息检索任务并且在机器翻译、文本生成方面具有独特的优势,为了挖掘语义相似弹幕的深层语义表征,本文采用自编码方法,学习输入弹幕数据的特征,生成语义向量.下面介绍弹幕的自编码.
对于弹幕文本s,自编码过程如下:

其中,φ表示编码过程,φ(s)为对弹幕s的编码,生成s的语义向量v;ψ表示解码过程,ψ(v)为对弹幕语义向量v的解码,解码生成弹幕s′.
实现深度语义表征,必须保证弹幕在经过自编码进行重构的同时,保证语义相似弹幕的语义向量距离相近,通过选取合适的损失函数,使得对任意的语义相似的弹幕si,sj,其语义向量vi,vj具有相近的距离.下面介绍深度语义表征的损失函数.
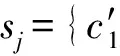
定义3. 深度语义表征的损失函数.深度语义表征的损失函数由弹幕重构的损失函数Lrec和相似弹幕语义向量的距离损失函数Lsem构成.其中弹幕重构的损失函数为每一步的似然函数的负对数之和,如式(2)所示:
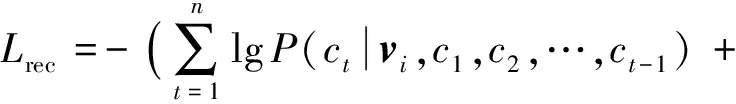
(2)
语义向量之间的距离采用余弦相似度,两语义向量余弦距离越大越相似.语义向量距离的损失函数Lsem如式(3)所示,以达到训练过程中可以不断最小化损失率.
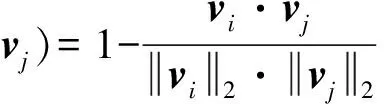
(3)
深度语义表征的训练过程就是不断地最小化Lrec+Lsem的损失率以达到收敛.
在语义相似弹幕深度语义表征的基础上,针对弹幕文本具有隐含语义的特点,本文进一步设计了基于语义检索的弹幕解释框架,同时作为对深度语义表征结果的验证.本文对基于语义检索的弹幕解释框架的语义相似弹幕检索过程给出如定义4所示的定义.
定义4. 基于语义的相似弹幕检索.初始弹幕s+,使用已经训练好的深度语义表征模型进行编码φ(s+),生成s+的语义向量v+,在深度语义表征空间中检索与语义向量v+距离最近的k个语义向量,组成语义相似向量集合{v1,v2,…,vk},分别对检索到的语义向量使用已经训练好的深度语义表征模型进行解码,生成s+的语义相似弹幕集合ss+.
基于语义检索的弹幕解释框架可以检索初始弹幕的语义相似弹幕,以解决弹幕文本具有隐含语义不易理解的问题,同时,通过比较初始弹幕与初始弹幕检索到的语义向量之间的语义相似性,对语义表征结果的应用验证进行验证.
2.2 深度语义表征模型结构
基于假设1:同一个视频的弹幕,如果时间间隔小于δ,为语义相似弹幕.本节对深度语义表征模型训练过程和模型结构进行相关介绍.
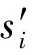
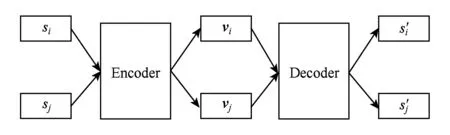
Fig. 2 Deep semantic representation training图2 深度语义表征训练

接下来从字符表征层、GRU单元、编码器、解码器4个方面,对基于字符级别编码解码的循环神经网络模型进行介绍.

Fig. 3 RNN model based on character-based encode-decode图3 基于字符级别编码解码的循环神经网络模型
1) 字符表征层.字符表征层是一个线性(linear model)结构模型.字符表征输入为字符ci,转化成字符ci的one-hot向量xi,向量的维度等于词表的大小m,是个高维稀疏向量,其中词表为模型训练数据和测试数据中所有字符的无重复的集合,词表的大小即集合的字符个数.通过分布式表示(distributed representations)将高维稀疏向量xi转化为α维分布式表示向量li,以达到降维.弹幕逐字符输入字符表征层,通过转化one-hot向量并进行分布式表示,最终字符表征层的输出为该字符的分布式表示向量,作为GRU单元的输入.
2) GRU单元.在传统RNN模型中,输入li,第i步的值为gi=σ(Uli+Wgi-1),其中U为li作为输入时的权重,gi-1为上一步的值,W为上一步值gi-1作为本步输入时的权重,σ为非线性激活函数.针对传统RNN难以保存长距离信息的缺点,LSTM和GRU,通过在隐藏层计算时,引入门(gate)的机制来解决RNN的梯度消失的问题,以达到处理长序列依赖.GRU[31]可以看作是LSTM的变种,它的门单元结构与LSTM非常相似,都在一定程度上解决了长距离依赖问题,使梯度可以更好地传播而不用面临太多梯度衰减的影响.GRU将LSTM中的遗忘门和输入门用更新门替代,GRU需要的参数较少,训练速度较快,而且需要的样本也较少.LSTM具有较多的参数,当大量样本的情况,可能会很难训练得到最优模型.因此采用GRU处理弹幕数据,GRU通过更新门,决定是否保留上一步的状态和是否接受此本步的外部输入.GRU单元接受字符表征层的输出和GRU单元上一步的值作为输入,输出是维度为β的向量.
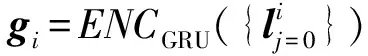
2.3 基于深度语义表征的弹幕检索
在基于循环神经网络(RNN)的深度语义表征模型的基础上,进一步设计了基于语义检索的弹幕解释框架.该框架利用语义向量创建深度表征空间,从而对给定的初始弹幕,通过检索与其语义相似但表达不同的上下文相关弹幕来对其进行解释,同时作为对语义表征结果的应用验证.
对弹幕数据,划分为训练数据和测试数据,训练集用于建立深度语义表征空间,测试数据中的弹幕作为初始弹幕,通过基于空间划分的索引,对深度语义表征空间检索其上下文相关的弹幕.其中上下文相关弹幕为初始弹幕通过基于语义检索的弹幕解释框架检索所得的语义相似弹幕.
弹幕语义检索的弹幕解释框架如图4所示,分为如下过程:
1) 建立深度语义空间模型
通过训练好的深度语义表征模型,对训练数据进行编码,生成语义向量,组成语义向量集合.
2) 基于空间划分的索引
高维空间中的近似最近邻(approximate nearest neighbor, ANN)[32]查询问题是一个基本的查询范式,尤其是在在数据挖掘、信息检索、推荐系统等领域的相似性查询上有重要的应用价值.局部敏感散列(locality sensitive hashing, LSH)是近似最近邻搜索算法中最流行的一种,它有坚实的理论依据并且在高维数据空间中表现优异[33].由于能够克服维度灾难,且算法的精度和效率能够满足应用需求,因而在许多应用中都被使用,比如图像、视频、音频和DNA序列等相似性查询[34].

Fig. 4 Time-sync comment for videos explanation framework based on semantic retrieval图4 基于语义检索的弹幕解释框架
对生成的语义向量集合,使用局部敏感散列(LSH)算法建立高维数据空间索引,按照语义向量之间的距离,进行高维空间划分.
3) 初始弹幕语义检索
依次从测试数据中逐条选取弹幕作为初始弹幕,使用训练好的深度语义表征模型进行编码,生成语义向量.利用初始弹幕生成的语义向量通过基于空间划分的索引,查找最近的k个语义向量,使用训练好的深度语义表征模型解码生成上下文相关弹幕,作为初始弹幕的解释.
3 实验验证
3.1 数据集介绍
实验数据来源于国内知名视频共享平台bilibili(https:www.bilibili.com)爬取的真实的弹幕数据,弹幕数据集如表1所示:

Table 1 Bullet-Screen Data Set表1 弹幕数据集
所有的弹幕数据随机划分为训练数据和测试数据,训练数据用于训练深度语义表征模型和建立深度语义表征空间,测试数据作为初始弹幕,用于弹幕语义检索.其中训练数据取弹幕数据的90%,剩下的10%作为测试数据.
3.2 实验步骤
实验步骤分为数据预处理、模型训练过程、语义检索.
1) 数据预处理
鉴于弹幕数据存在高频、热点等重复出现的情况,如“哈哈哈哈哈”、“前方高能”、“23333”等,为防止语义检索出现检索的上下文弹幕存在大量与初始弹幕完全相同的弹幕,给语义检索的验证带来困难,同时考虑对比方法中检索出上下文相关弹幕完全和初始弹幕一样的情况,影响实验评测的科学性,本文对弹幕进行去重.
根据语义相似性定义,存在δ使得得到的语义相似弹幕集合G={s1,s2,…,sn}里面的弹幕语义相似.此时面临的问题为δ取值的选取,若δ过大,语义相似弹幕集合G中无关弹幕过多,导致G中的弹幕平均语义相似度低,影响模型的表征效果;若δ小,语义相似弹幕集合G中弹幕过少,导致噪声占的比重反而更大.因此,需要选择合适的δ对弹幕进行切分,使得所得到的语义相似性集合G的平均语义相似度最高.然而,δ的取值获取需要根据模型训练的结果进行定量分析,即其他参数不变的情况下不断改变δ的取值,使得模型损失函数的损失率最低,选取此时的δ作为最终的δ.虽然一开始无法确定最优的δ的大小,但是数据预处理部分必须对弹幕进行按δ切分,得到当前切分时间片δ的语义相似度弹幕集合.本文,在δ选取时,最初通过人为观察选择一个δ值,在此δ的情况下,根据模型训练结果进行调整.考虑最初δ的选取,过大或者过小,都会给最终δ的拟合带来大量的训练次数,所以最初δ选择为3 s.
据对弹幕数据的人工观察,进一步,本文发现一定时间段内,弹幕数量越多,这段时间内弹幕的语义相似度越高;一定时间段内,弹幕越少,噪声的可能性越大,语义相关性越小.同时如果一定时间内,弹幕数据越多噪声弹幕的所占比重也越少,所造成的干扰的影响也越小.结合此规律,对按一定时间段切分的语义相似弹幕集合,根据长度排序并筛选.
为了便于字符级循环神经网络的处理,弹幕长度设置为定长.鉴于过短或者过长的弹幕,所占比重很少、对模型意义不大,通过人工对弹幕数据的观察,选取长度在(5,20)之间的弹幕.同时对于弹幕数据设置成定长21,不足部分补0.
2) 模型训练过程
① 模型初始化
② 数据输入
每次取batch_size个语义相似弹幕集合,并在其每个弹幕集合中随机取2条弹幕,作为模型的数据输入.
③ 参数选取
结合模型训练过程,不断调整弹幕切片时间(slice time)T、字符表征向量的维度(word repre-sentation dimension)α、GRU单元弹幕表征向量的维度(bullet-screen representation dimension)β、每轮训练所取语义相似度集合数据数量(batch size)、学习率(learning rate),使语义表征模型的损失率最低并保持一定范围内变动.经过多次训练,最终选取的参数如表2所示,记录此时的训练次数(nloop)、损失率(loss rate),保存此时的训练模型.
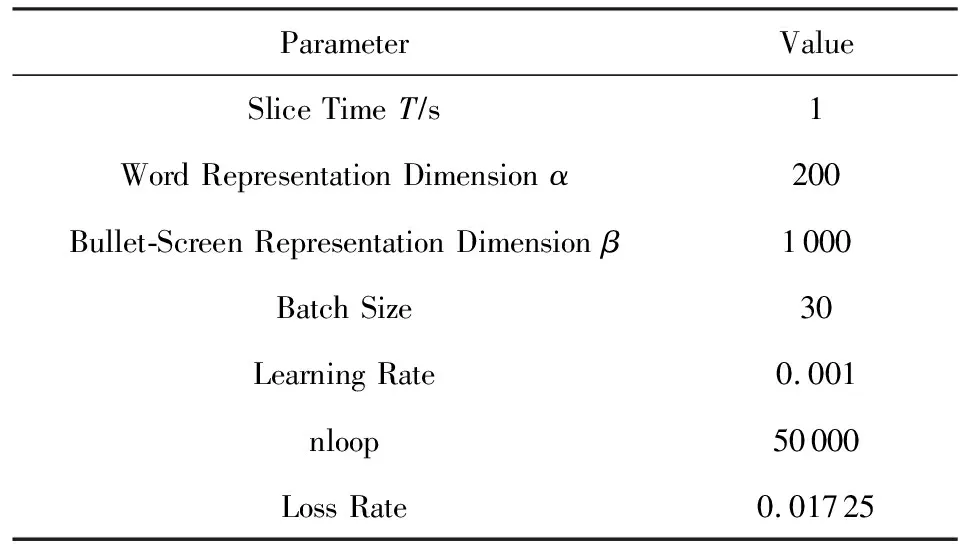
Table 2 The Parameter of Model表2 模型参数选取
3) 语义检索
利用训练好的深度语义表征模型,对训练数据解码生成深度语义空间,深度语义空间是所有训练数据的语义向量在空间的分布.对深度语义空间的语义向量建立基于空间划分的索引.对测试弹幕逐条选取作为初始弹幕,经过训练好的深度语义表征模型进行解码,生成初始弹幕的深度语义向量,并基于空间划分的索引检索与初始弹幕语义相近的语义向量,对检索到的语义向量经过训练好的深度语义表征模型的解码,解码生成上下文相关弹幕,其中上下文相关弹幕即为检索到的与初始弹幕语义相似的弹幕.本实验根据检索的相似语义距离,每条初始弹幕选取语义距离最近的10条语义向量.最终,每条初始弹幕存在10条上下文相关弹幕,并且语义相似度依次递减.
3.3 对比方法
为了验证基于语义检索的弹幕解释框架,本文设计了如下3个对比方法.
1) 序列自编码.si∈G,G为相似弹幕集合,si={c1,c2,…,cn},si的语义向量vi,序列自编码模型损失函数为如式(4)所示,训练弹幕自编码语义表征模型.初始弹幕通过训练好的序列自编码模型解码,解码生成语义向量,利用基于语义检索的弹幕解释框架,检索与初始弹幕语义距离最近的10个向量作为语义相似向量,并对检索到的语义相似向量使用训练好的序列自编码模型进行解码生成上下文相关弹幕.
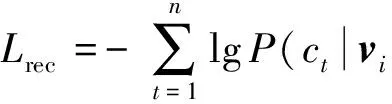
(4)
2) 词袋特征索引.使用词袋模型将训练数据中的弹幕转化为向量,建立语义向量空间.通过初始弹幕的语义向量在语义空间寻找相似向量.
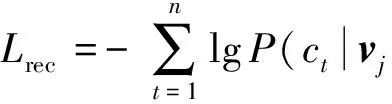
(5)
3.4 评价指标
本节通过BLEU-4、流畅度、多样性、人工评测对实验结果进行评价.
BLEU[35]是一种流行的机器翻译评价指标,用于分析候选词和参考序列中n元组共同出现的程度,不考虑词的位置.本实验用初始弹幕检索所得上下文弹幕和初始弹幕所在的语义相似集合的弹幕的n元单位切片(n-gram)进行比较,并通过计算出匹配片段的个数来计算得分.匹配的片段数越多,检索的上下文相关弹幕越好.BLEU值的取值范围是0~1的数值,只有2个弹幕完全一样的情况下才会取值1.本实验n=4,即BLEU-4标准.
除此之外,流畅度和多样性也是评价上下文相关弹幕的重要指标[36],其中流畅度衡量了检索的上下文相关弹幕在表达上与人类自然语言相似程度,多样性衡量了检索的上下文相关弹幕表达的丰富程度.具体而言,流程度和多样性指标的定义如下:
定义5. 流畅度.T0表示所有弹幕(训练数据和测试数据)的n-gram划分块集合,T表示检索的上下文相关弹幕n-gram划分块集合.

(6)
本实验对流畅度的n-gram中n设置为n∈{2,3,4,5,6}.
对于初始弹幕检索出来的10条上下文相关弹幕随机取3条进行n-gram划分,得到该初始弹幕上下文相关弹幕的n-gram划分块集合T.逐个取T中的元素t,并将t的权重设置为len(t),若存在T0中则取1,若不存在取0,得到该初始弹幕上下文相关弹幕的流畅度.本实验最终的流畅度为所有初始弹幕的上下文相关弹幕的流畅度的求和均值.
定义6. 多样性.对初始弹幕的上下文相关弹幕两两选取,进行n-gram划分.
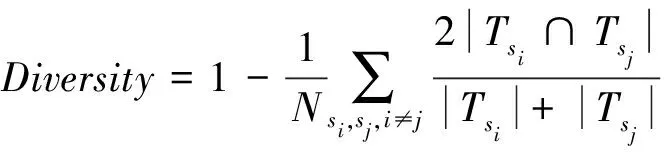
(7)

本文结合弹幕这类短文本特点,多样性的n-gram中n设置为n∈{1,2,3}.
为了更好地从语义的角度评测检索的上下文相关弹幕与初始弹幕的语义相似性,进一步,本文提出了人工评测[26],具体指标的定义如下:
定义7. 人工评测.
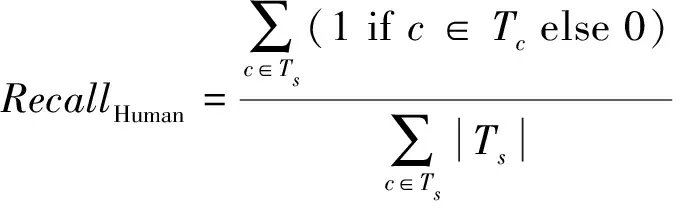
(8)
其中,Ts表示所有上下文相关弹幕,|Ts|为上下文相关弹幕的数量.Tc表示为所有初始弹幕,c∈Tc表示弹幕c与初始弹幕相似.
通过人工对上下文相关弹幕进行标注,若与初始弹幕语义相似则为1,否则为0,得分为所有取值之和除以所有上下文弹幕个数.鉴于语义相似性,无法单纯从字面进行判别并且不同评测者对相似性的判定和理解可能存在偏差,人工评测部分采取多人评测.评测过程中,对于每条上下文相关弹幕若有一半以上结果认为与初始弹幕语义相似,则此弹幕判定为语义相似弹幕.
3.5 结果分析
实验的结果如表3所示,深度语义表征模型从BLEU、流畅度、多样性、人工评测方面都取得了较好的效果.其中多样性、人工评测2项指标得分高于其他模型,可见基于语义检索的弹幕解释框架,能检索与其语义相似但表达不同的弹幕,从而验证深度语义表征模型的合理性.其中BLEU、流畅度2项指标词袋模型得分高于其他模型,是由于词袋模型是通过向量检索,所得到的弹幕是原有检索空间存在的弹幕而非根据初始弹幕生成的上下文相关弹幕,所以BLEU和流畅度得分取值较高,超过其他模型的得分.同时,考虑到词袋模型可能存在多条上下文弹幕与初始弹幕相同,影响结果的科学性和合理性,在数据预处理部分对重复弹幕进行了剔除.因此,词袋特征索引模型人工语义相似度评测结果的得分优于编码器解码器模型和序列自编码,低于深度语义表征模型.
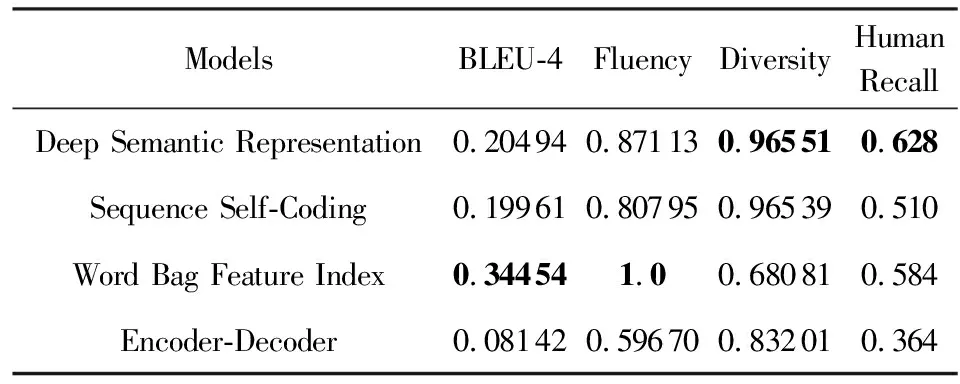
Table 3 Performance of These Models表3 实验验证结果
综上所述,通过在BLEU、多样性、流畅性、人工评测,对本文所提出的模型进行了充分验证.结果表明这种基于循环神经网络的深度语义表征模型能够精准地刻画弹幕短文本的语义,也证明了关于弹幕相关假设的合理性.
3.6 案例分析
在实验结果的基础上,通过案例对检索的上下文相关弹幕和初始弹幕语义进行分析.首先通过初始弹幕与上下文相关弹幕的语义关系,利用上下文相关弹幕对初始弹幕进行解释,使用语义相似弹幕集合分析解释的合理性.然后,结合弹幕语义和弹幕视频之间的关联,通过弹幕视频分析检索弹幕和初始弹幕的语义关系.
结合案例使用上下文相关弹幕解释初始弹幕,使用语义相似弹幕集分析解释的合理性.如图5所示,黄色为初始弹幕,白色为初始弹幕的语义相似弹幕,红色为基于语义检索的弹幕解释框架检索出的上下文相关弹幕.初始弹幕“五毛…五毛”,包含隐含语义,很难理解语义.通过检索出来的上下文相关弹幕,很好地解释了“五毛”的语义,同时根据语义相似弹幕也验证了解释的合理性.对于如初始弹幕为“哈哈哈哈”,检索出来的上下文相关弹幕中出现了“噗哈哈哈哈,结局很赞呢!”、“23333我不行了”、“哈哈哈哈哈哈哈达”.检索的上下文弹幕和初始弹幕存在大量重复的字符,恰恰正是初始弹幕的相似语义的表达.其中“2333”正是代表初始弹幕“哈哈哈”的语义,如图6所示.

Fig. 5 Case study figure 1图5 案例展示1

Fig. 6 Case study figure 2图6 案例展示2
结合弹幕语义和弹幕视频之间的关联,对检索得到的上下文相关弹幕,通过结合视频进行解释分析,比如弹幕“这才是开始”,从弹幕文本的自身角度,很难理解此句弹幕所表达的真实语义,通过深度语义检索出来的相似弹幕为“不敢放大看”、“这个最吓人”等令人费解的语句.结合初始弹幕“不敢放大看”的视频标识符和时间,定位到所在视频的出现地方.通过人工验证,此视频为一部恐怖片,弹幕所出现的情节是灵异事件的开场部分.通过视频本身的内容,很好地验证了初始弹幕检索出来的上下文弹幕的合理性.
综上所述,通过具体案例分析得到的上下文相关弹幕大多是初始弹幕和视频情节的语义相似解释和表达,从而也验证了检索的上下文相关弹幕的合理性和准确性.
4 结论和展望
针对视频实时评论的高噪声、不规范表达和隐含语义等特性,使得传统自然语言处理技术具有很大局限性,本文提出了一种基于循环神经网络(RNN)的深度语义表征模型.该模型由于引入了字符级别的循环神经网络,避免了弹幕噪声对文本分词带来的影响,在实现语义表征的过程中,通过使用神经网络,使得所得的语义向量能够对弹幕进行更深层次的刻画,表达其隐含语义.在此基础上,针对弹幕文本具有隐含语义的特点,本文进一步设计了基于语义检索的弹幕解释框架,同时作为对语义表征结果的验证.本文设计了包括序列自编码、词袋特征索引、编码器解码器等多种对比方法,并通过BLEU、流畅度、多样性等多种指标以及人工评测对本文所提出的模型进行了充分地验证,表明这种基于循环神经网络的深度语义表征模型能够精准地刻画弹幕短文本的语义,也证明了关于弹幕相关假设的合理性.
本文在研究弹幕深度语义表征的基础上,提出基于弹幕深度语义表征的弹幕语义检索,用于解决高噪声、不规范表达和隐含语义等特性.针对视频实时评论的研究未来可进一步从以下4点更深入的研究:1)弹幕数据较传统的短文本最大区别在于用语的随意性,任何人都能发表自己的看法,而不同的人拥有不同的风格,因此利用用户ID信息对语义的分析可能有一定的帮助,更好地体现弹幕的价值.2)若对视频类型进行分类,分析不同类别视频中用户行为的差异性,将具有巨大价值.3)未来的工作进一步将通过实验对诸如搜索引擎搜索结果、论坛评论、微博等短文本适用性进行探究,并将本文中对视频短文本的分析推广到搜索引擎搜索结果、论坛评论、微博等短文本.4)若考虑引入文本生成模型,在弹幕深度语义表征模型的基础上,进行弹幕生成,设计弹幕自动回复、评论自动生成,将具有重大实际应用价值,也是未来的研究方向之一.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
学生天地·小学中高年级(2018年8期)2018-10-11
青春美文CUTE(2017年1期)2017-11-14
传奇故事(上旬)(2017年6期)2017-06-17
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
