
一种调度区段晚点时长的神经网络预测模型
2019-02-22 09:56金博汇
铁道标准设计 2019年3期
曾 壹,陈 峰,金博汇
(1.中国铁道科学研究院集团有限公司研究生部,北京 100081;2.中国铁道科学研究院集团有限公司通信信号研究所,北京 100081;3.国家铁路智能运输系统工程技术研究中心,北京 100081;4.北京市华铁信息技术开发总公司,北京 100081)
列车在运行线路内受到异物侵入、设备故障、调度因素或恶劣天气影响后,会出现非预期的运行时分偏差,即晚点现象。晚点不仅会影响本列车的按图开行,还会在区段内以晚点传播的方式扩散。记录初始晚点发生的时间、地点与类型,并对晚点传播的路径进行分析,对调度员掌握特定时间内区段晚点情况,提高行车调度指挥质量具有重要的意义。
国内外学者在实绩运行图的分析方面进行了大量的研究,可划分为已有初始晚点数据的规律统计、运行线实绩数据的晚点传播分析以及列车运行时分预测三类。初始晚点的规律统计研究采用概率分布模型的方式,将调度区段的晚点时长概率分布建模为对数正态分布[1]、负二项分布[2]、相位型拟合分布[3]、指数分布[4]等概率分布模型,模型参数通过极大似然估计、Kolmogorov-Smirnov检验与Wasserstein间距等度量标准,完成数据拟合的实现与验证。晚点传播分析的相关研究围绕初始晚点定位与晚点传播链的数学和仿真方法开展。其中,数学方法包括决策树判定[5]、最长传播径路探索[6-7]等;仿真分析则通过累积记录初始晚点发生时列车运行位置的极大加代数推算实现[8-9]。由于列车在区段的开行事件存在关联关系,大范围列车运行时分预测的数据样本需要进行分类处理,减少事件关联导致的干扰,具体方法有卷积变换[10]、贝叶斯推理网络[11-12]等。小范围预测则通过机器学习算法[13-14]、最小修剪方差估计[15-16]的方法推测晚点恢复时间或区间运行时间。
本文在充分研究上述文献的前提下,设计了一种列车初始晚点、连带晚点的分类方法,同步推算得到了晚点的传播链。在晚点情况分类数据样本的基础上,进一步提出基于神经网络的晚点预测模型,实现了调度区段内晚点时长的有效预测,并对不同样本大小与允许误差条件下的模型推算效果进行了比较分析。
1 晚点传播的分类方法
1.1 晚点传播的有向图建模
在调度指挥业务中,列车在车站、区间的运行按照运行线的形式进行标示。运行线由从属于同一车次的节点v按照经由车站的先后顺序排列构成,各节点包含运输业务的计划信息,包括列车在车站的到达时间、出发时间、占用股道等内容。由于相同或不同车次列车在各车站的业务存在时序差异,根据计划执行时间的先后顺序,前方节点v与后方节点v′的时间关系可表示为有向连接的线段e(v,v′)。在一个班次内,所有有向线段的连接即构成了列车开行计划,可描述为有向图G=(V,E),其中V、E分别为全部节点v、有向弧e的集合。由于运输规划与实际完成情况存在差异,节点v具备计划时间T(v)与实绩时间Tadjust(v)两类时间属性,有向弧e对应的时间长度也同理可记做T(v,v′)与Tadjust(v,v')。
列车对线路中各类股道、区间设备的使用必须依据运输组织要求,满足开行方案规定的时序限制。当列车在区段内发生晚点后,由于后续节点受到时序条件约束,时刻表会出现偏移,晚点时分在运行线内部或站间传播,在有向图模型内表现为初始晚点沿着有向弧扩散的过程。按照时序限制的具体条件分类的有向弧e(v,v′),e∈E如表1所示,l、i、m分别表示车次、车站编号、会车车次。其中时序条件根据有向弧节点关系又分为同车与同站两类,用于记录节点内部晚点传播的范围。

表1 有向弧的时间关系类型
1.2 晚点列车的状态分析方法
列车在受到非预期车流、施工、机车设备故障或不适当调度指挥的影响后,会在区间或车站产生时刻表延误。延误发生后,列车通过区间赶点、车站早开、待避非晚点车的方式,能够缓解部分晚点现象。路网内的实绩数据中包含了晚点的产生、恢复与传播过程,且不同类型过程可以同时发生在单个有向弧内。晚点静态分析方法必须建立在列车运行状态的准确判断之上,才能排除路网内复杂的干扰数据影响,得到初始晚点及其传播路径。为此,本文提出计划时间饱和度的概念如下
P=
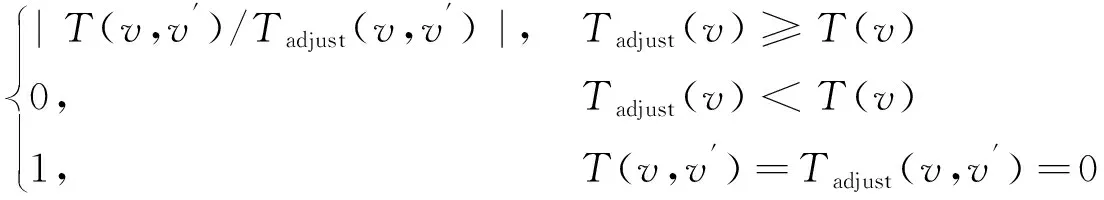
(1)
由式(1)可知,饱和度小于1时,晚点列车的有向弧相关计划的执行时间超过了预定时间,列车受到初始或连带晚点影响低速运行或延时停站。饱和度大于1时,晚点列车计划的执行时间小于预定时间,列车处于加速赶点或车站早开的状态。饱和度等于1时,晚点列车按照预定时间运行,晚点在路网内传播。由于运输组织的需要,列车在非营业站存在提前发车,并在到达营业站前主动降速的运行策略。该过程内的列车计划执行时间与预定时间存在差值,但不存在晚点传播现象,此时计划时间饱和度为0。如列车在车站通过,有向弧的计划与实绩时间长度均为0,计划时间饱和度按照1的情况处理。
列车有向弧的计划时间饱和度不仅反映了当前列车的运行状态,还可以表现晚点传播的状态。当饱和度大于或等于1时,列车处于正在缓解晚点,但晚点仍旧存在的状态中,此时的时刻表扰动沿着有向弧传播,并不断减少。当饱和度小于1并大于0时,列车在区间内受到正常行车之外的因素影响,导致晚点增加。当有向图的实绩长度Tadjust(v,v′)<0时,表示列车的开行顺序相对原运行计划发生了变动,具体情况包括计划会让的取消,列车待避等,时刻表扰动从后向列车向前方列车传播。
1.3 晚点传播分析与分类
运行图内晚点与其传播链的反向搜索流程依据有向弧的内部节点关系与饱和度分析展开,局部范围的晚点分析操作步骤陈述如下。
(1)检查属于选定车次且内部节点关系为同车的有向弧,计算饱和度,同车关系节点依据计划时刻顺序,由先至后依次确定各弧线内的列车运行状态与晚点传播情况。所有检测到的晚点增加情况按照发生的位置,标记为区间初始晚点与车站初始晚点。
(2)检查属于选定车次且内部节点关系为同站的有向弧,计算饱和度,同站关系节点依据计划时刻顺序,由后至先依次确定各弧线内的列车运行状态与晚点传播情况。如果初始晚点前方有向弧的饱和度大于1,可认为该晚点来源于其他列车,为连带晚点。如果后向追踪饱和度小于0,按照前向追踪的情况判定晚点情况。
(3)检索搜索范围内所有完成检查的有向弧和节点,即可确定初始晚点的时长与位置,并根据晚点传播状态和方向,得到晚点传播链。
以某调度区段晚间开行的3个车次为对象的分析结果如图1所示。图中节点包含信息依次为车次编号、车站站码与晚点时分,有向弧的标示依次为晚点增量与计划时间饱和度。指向节点内部的有向弧表示列车在车站的到开。部分同站关系的有向弧不存在晚点情况,在图1中未绘制。

图1 晚点传播链的有向图模型表示
通过对图1中的所有列车应用步骤1检查可知,列车1,2,3在车站3010分别发生了6,4,1 min的晚点。晚点随后各车内部节点传播,列车1在车站3009通过早开的方式缓解晚点,而列车2,3在邻接的区间赶点恢复时刻表。继续应用步骤2检查,3个车次的列车在车站3010存在追踪时间过饱和现象,3个晚点增量之间存在传播关系,标记在列车2,3的初始晚点应为车站连带晚点。最后,检索所有有向弧和节点信息可知,初始晚点在车站3010发生,连带晚点传播到列车2,3的节点内,得到图1所示的晚点传播链。将步骤中的选定车次扩大到当天开行的全部列车,即可将当天全部计划信息区分为无晚点、初始晚点、连带晚点3种情况。
2 晚点时长预测模型
晚点时长预测模型建立在晚点分类数据的基础上,通过广泛应用于分类识别的反向传播神经网络进行各类晚点情况的数据预测。由于大风、泥石流、地震等自然灾害或危及铁路行车安全的重大事故[17]等大规模晚点致因不具有明显的规律性。模型只针对在运输组织计划、运用车辆、站内设备和线路设施不发生明显变化的前提下的中小规模晚点进行预测。
2.1 反向传播神经网络原理
神经网络是一种通过多个节点之间的权重配置与激活函数构成的数据拟合模型,分为输入层、隐藏层和输出层,如图2所示[18]。根据求解问题的规模,网络可具备多个隐藏层。神经网络内部节点之间存在相互的连接关系,每条连接线代表上一层输入值的权重。根据数据拟合或数值缩放的需要,节点使用logSig函数作为激活函数,将结果输出到下一层网络。
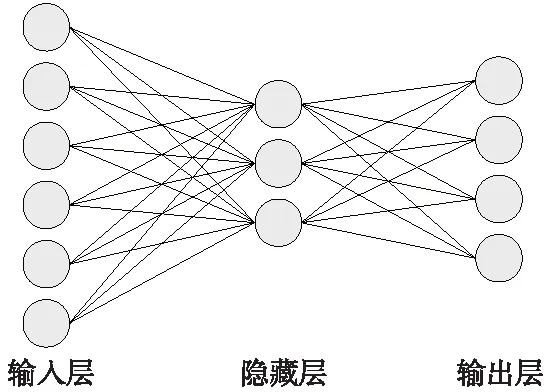
图2 三层神经网络模型
神经网络通过改变内部权重调整输出,直至计算结果与样本间的误差降低到满足要求为止的过程,称为神经网络的训练。反向传播是一种有效的神经网络训练方式,将输出值与样本值的差异按照神经连接传递并求导,分层得到每个权重的调整量并实现误差的梯度下降。分别设输入层、隐藏层的参数变化量为Δwij、Δwjk,采用logSig激活函数的三层神经网络权重调整量计算方法[19]可表述如式(2)。为加快拟合速度,公式内各变量均进行了归一化处理。
(2)
2.2 晚点预测模型的神经网络设计
中小规模初始晚点时长的预测模型采用反向传播神经网络的结构,并根据有向图的节点特性进行了改进设计。
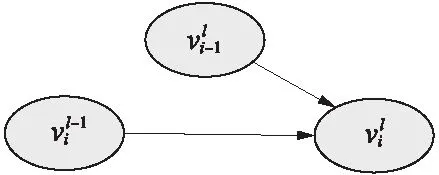
图3 同车、同站节点的前向时序关系
(3)
式中,I、J、K分别为输入层、隐藏层、输出层的节点数量;a为可调整参数,为1-10之间的整数。
3 模型应用算例
为验证模型预测效果,算例采用北京铁路局调度区段半个月的行车数据制作。使用晚点分类方法处理后的样本情况如表2所示,各项数据为相应分类下的有向图节点个数。

表2 调度区段样本数据分类结果
预测模型的检验方法为首先通过历史样本组建神经网络,然后使用网络预测后一天的晚点情况,比较晚点类型的预测值与行车数据并记录匹配程度,允许误差为5 min。
为检验神经网络在不同数据条件下的预测性能,各区段的行车数据被划分为时间连续且大小不同的样本如表3所示。由于3 d以上行车数据受到更多突发因素影响,模型输出的规律性不显著,本文未做进一步研究。

表3 神经网络训练样本的划分
由于神经网络内部权重的初始配置存在随机性,误差达到可接受范围后,网络对样本数据的拟合情况存在差异。为保证预测的有效性,实验中用于判定后一天晚点情况的神经网络均达到90%以上的样本拟合度。
模型对单份样本进行有效组网后预测晚点,为验证预测结果的可靠性,实验先对单份样本进行10次组网预测,后取准确度的无加权平均值与标准差作为该样本的最终性能判定指标。根据样本数据量大小,神经网络的学习率存在微小调整,隐藏层固定为10个节点。
根据上述步骤进行的模型预测准确率与标准差结果如图4、图5、表4所示,N为按照天数表示的样本大小。
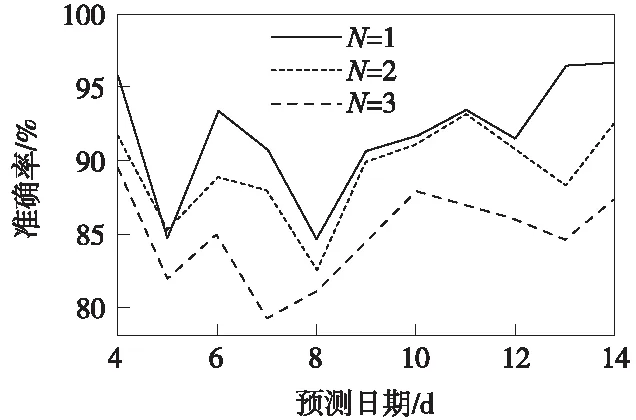
图4 区段1的模型预测准确率

图5 区段2的模型预测准确率
图4、图5、表4的结果表明,训练样本大小为1 d时,模型预测的准确率和稳定性最佳。由于路网内出现车辆设备故障、邻台接入车晚点的突发情况,预测模型在相应日期的准确率出现下降。不同允许误差下的准确率如表5所示。
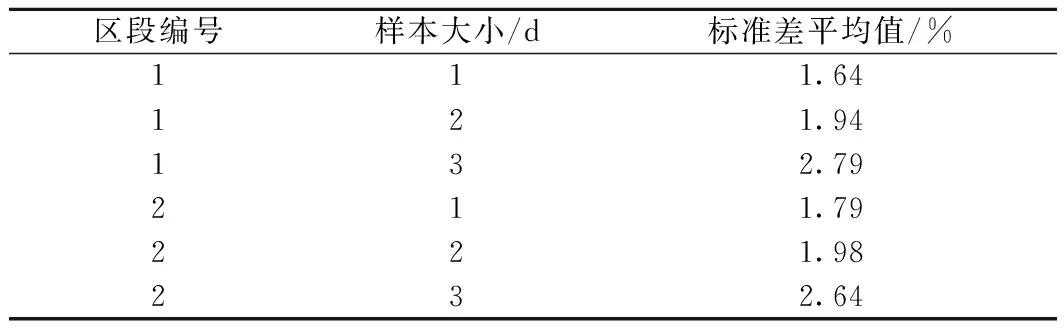
表4 模型预测的标准差
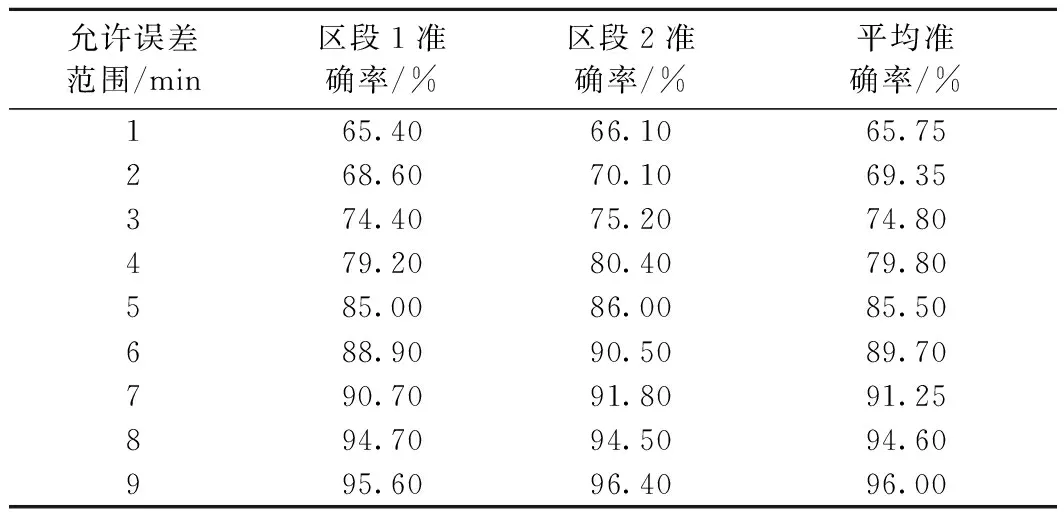
表5 不同允许误差下的预测成功率
4 结语
提出了一种列车运行实绩数据的初始晚点、连带晚点分类与晚点传播链构建方法,并在此基础上建立了神经网络晚点预测模型。数据实验的结果表明,模型在允许误差为5 min时准确率为85.5%。由于神经网络模型无法很好的拟合路网内部数据的复杂关联关系,路网内出现突发事件后,模型准确度会不可避免地出现下降,应用能够完整表述并拟合复杂关系的模型,如强化学习、随机森林算法拟合建模,才能实现更高的预测率。
猜你喜欢
铁道科学与工程学报(2022年10期)2022-11-30
金沙江文艺(2022年4期)2022-04-26
小资CHIC!ELEGANCE(2021年25期)2021-07-29
智慧少年·故事叮当(2021年4期)2021-05-06
环球时报(2019-01-17)2019-01-17
领导决策信息(2017年17期)2017-06-21
少儿科学周刊·儿童版(2015年7期)2015-11-24
理科考试研究·高中(2014年11期)2014-11-26
优雅(2014年4期)2014-04-18
中华少年(2009年9期)2009-09-14
