
基于改进型SSD算法的目标车辆检测研究
2019-02-22 07:46陈冰曲
重庆理工大学学报(自然科学) 2019年1期
陈冰曲,邓 涛,b
(重庆交通大学 a.机电与车辆工程学院;b.航空学院,重庆 400074)
准确实时检测目标车辆能有效缓解交通监控压力和降低车辆违规行为。目前,基于计算机视觉的方法吸引了国内外学者广泛关注,如应用于车流统计、车辆检索和车辆行为分析等方面。
传统目标检测方法如HOG(histogram of oriented gradient)[1]、SIFT(scale-invariant feature transform)[2]等,利用手工设计特征,将特征送入诸如SVM(support vector machine)[3]、AdaBoost[4]等分类器进行分类实现目标检测。上述方法对于简单场景的目标检测效果不错,但是对于稍微复杂的场景或者光照变化的情况下检测精度就相对较差。即使采用星型结构的DPM(deformable part model)[5],虽可以检测出变形目标和部分重叠目标,但因采用滑动窗口提取特征再进行分类,导致计算量过大,实时性受到影响。
近年来,卷积神经网络在图片分类、目标检测领域取得了巨大成功。相比于手工设计特征,基于卷积神经网络的目标检测模型能够自主学习不同层级的特征,具有更加丰富的特征和更强的特征表达能力。目前两阶段的卷积神经网络算法有R-CNN[6]、SPPnet[7]、Fast R-CNN[8]、Faster RCNN[9]、R-FCN[10]等。与之相比,单阶段目标检测模型更加容易训练,计算效率更高,典型代表如YOLO[11]、SSD[12]等。其中,SSD检测性能更好,具有实时性好、检测精度高等优点。
1 SSD算法
1.1 SSD网络结构
作为目前最先进和实时的目标检测网络之一,SSD只用一个全卷积网络就完成了目标分类和定位任务。SSD结构框图如图1所示,它采用VGG-16[17]作为基础特征提取层,将 VGG-16网络结构的全连接层fc6和fc7层转换成两个卷积层,并去除VGG-16中的dropout层和分类层;再格外增加了4组卷积层,每一组都首先使用1×1卷积核降通道,再用3×3卷积核降尺度增通道。不同层次的特征图分别用于不同尺度目标的边框偏移以及不同类别得分的预测。最后通过非极大值抑制(NMS)得到最终的检测结果。SSD结合多尺度特征图共同检测,用浅层分辨率大的特征图检测小目标,深层大感受域的特征图检测大目标,保证不同尺度大小的目标都能得到检测。
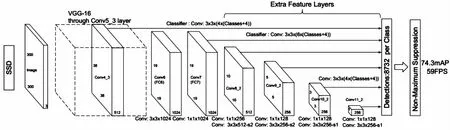
图1 SSD框架
1.2 SSD区域候选框
SSD采用多尺度特征图方法,在不同尺度特征图上都会设置不同大小和宽高比的区域选框,区域候选框定义如下计算。
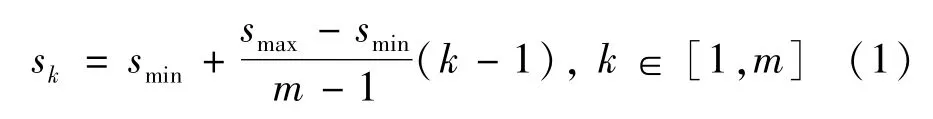
式中:m为特征层数;smin=0.2为最低特征层尺度;smax=0.9为最高特征层尺度;中间特征层尺度均匀分布。
区域候选框具有不同的宽高比 ar∈{1,2,3,。区域候选框的宽、高分别为同时对于宽高比为1的区域候选框增加一个尺度每个区域候选框的中心坐标为)。其中 w为第 k个fk特征图的宽,hfk为第 k个特征图的高,i∈[0,wfk),j∈[0,hfk)。
SSD把 conv4_3、fc7、conv8_2、conv9_2、conv10_2、conv11_2作为预测层,各层区域候选框参数统计如表1所示。从表1中可以看出:随着网络加深特征图尺寸逐渐减小,区域候选框的尺寸不断增大,所以SSD用浅层特征图检测小目标,用深层特征图检测大目标。
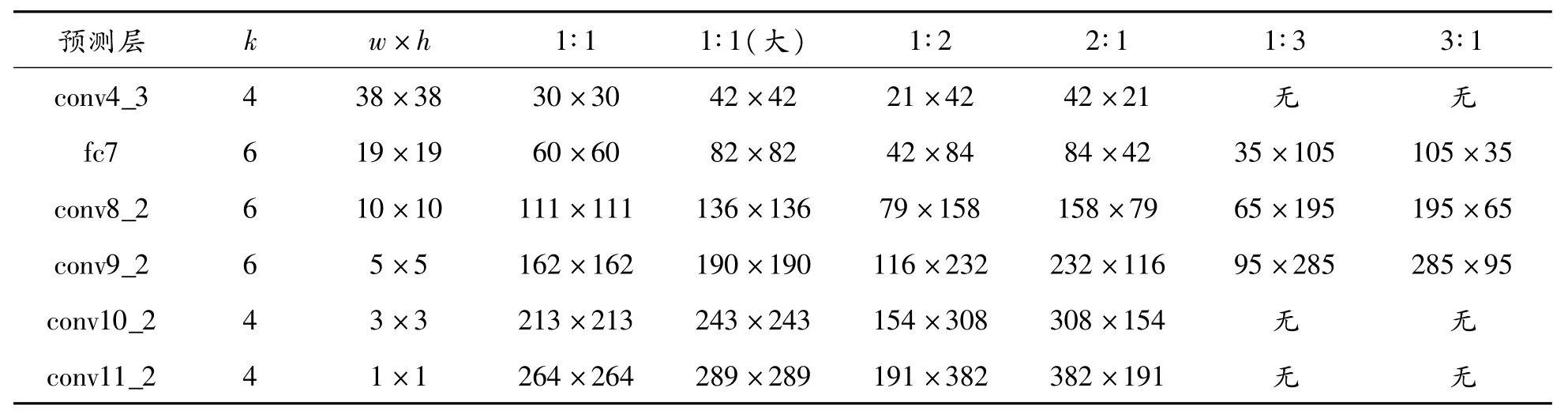
表1 SSD各预测层区域候选框
1.3 SSD损失函数
SSD训练过程中对位置和目标类别进行回归,它目标损失函数为定位损失(loc)与置信度损失(conf)之和,其表达式如下式。

式中:N为区域候选框与真实框的匹配个数,如果N=0则设置Loss=0;x为区域候选框与不同类别的真实框匹配结果,如果匹配x=1,否则x=0;c为预测物体类别置信度;l为预测框位置偏移信息;g为真实边框与区域候选框的偏移量;α为位置损失权重参数通常设为1。
SSD采用SmoothL1作为位置损失函数,对区域候选框(p)的中心坐标(cx,cy)、宽(w)、高(h)的偏移量进行回归,按下式计算:

式中i、j分别表示第i个区域候选框与第j个真实框匹配。
SmoothL1函数计算如下:

类别置信度损失函数采用Softmax损失函数用下式计算:
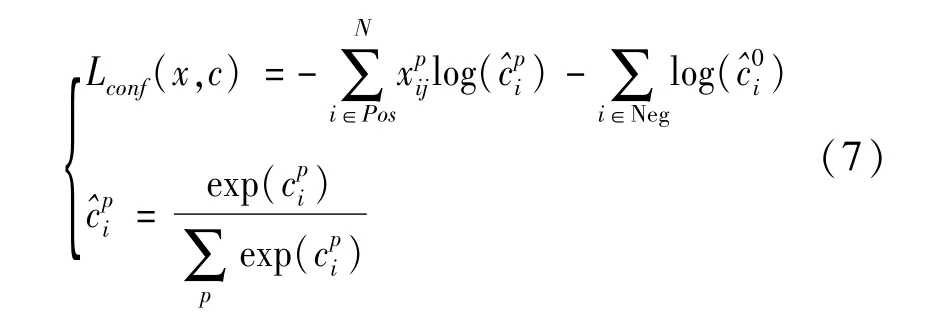
2 改进型SSD算法
2.1 SSD检测车辆目标存在的不足
SSD目标检测性能好坏在很大程度上取决于特征提取的好坏,而特征提取是由训练数据所驱动的。SSD中训练数据是由区域候选框决定的,因为只有区域候选框与真实的目标边框的IOU>0.5时被标注为正样本,反之为负样本。区域候选框的设置应该根据真实框的变化范围而定。一般来说,候选框与真实框匹配度越高就越能减少背景噪声的影响从而提高检测的准确度。并且区域候选框与真实框差异小,更利于位置回归,因为区域候选框与真实框相近时是个线性回归,如果两者差异太大则必须建立复杂的非线性模型求解。原始SSD区域候选框与车辆数据集分布,如图2所示。图中黑色“点”代表数据集中车辆宽高分布,彩色直线为原始SSD中不同宽高比直线,彩色“三角形”为原始SSD中设置的区域候选框。从图中可以看出SSD中大部分区域候选框离车辆数据集分布较远,直接将SSD应用于车辆数据集不能得到很好的检测结果。

图2 区域候选框尺度分布
SSD存在对于有重叠的车辆目标检测比较弱的现象。如图3,蓝色框为目标A真实框,绿色框为目标B真实框,红色虚线框为目标A的预测框。当目标车辆A被目标车辆B重叠时,由于两辆车有相似的特征,检测器很容易被混淆,结果目标A的预测边框向B偏移,导致定位不准确。对原始的检测结果进行非极大值抑制(NMS)处理时,目标A的预测框可能被B的预测框所抑制,导致A漏检。

图3 SSD检测结果与真实值的偏差
2.2 SSD区域候选框设置
本文对训练数据集运行 k-means聚类[14],令k=5得到5个聚类中心,具体步骤如下:① 获取训练样本,并随机选择k个初始聚类中心;②计算每个样本与这k个中心各自的欧式距离,按照最小距离原则分配到最邻近聚类;③使用每个聚类中的样本均值作为新的聚类中心;④重复步骤②和③直到聚类中心不再变化;⑤结束,得到k个聚类。k-means算法聚类后的结果见表2。

表2 k-means聚类结果
将SSD区域候选框和宽高比都设置在聚类中心周围,使得区域候选宽与真实框更加匹配,并对SSD作如下更改:①删除宽高比为1/3的框;②只保留预测层conv4_3、fc7、conv8_2,删除后面的所有卷积层。③conv4_3设置4个区域候选框,fc7、conv8_2分别设置5个区域候选框。
更改后记为SSD_change,其区域候选框w-h分布如图4。

图4 修改后区域候选框尺度分布
2.3 排斥损失
针对SSD对有重叠的目标检测效果不佳的问题,本文在原始SSD损失函数的基础上再增加一项排斥损失[13],最终SSD损失函数如下:

设P+={P}表示至少与一个真实边框匹配(IoU>0.5)的区域候选框的集合,G+={G}表示所有真实边框集合。对于给定的候选框P∈P+,分配一个与它IoU值最大的真实框,作为它的指定目标,如下。
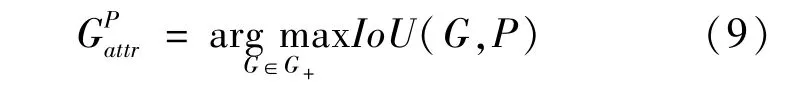
由于排斥损失是使区域候选框与除它指定目标以外的相邻真实边框产生排斥,因此对于P∈P+,它排斥的目标是除它指定目标外,与它IoU值最大的那个真实目标。

设BP为候选框P回归出的预测框。BP与间的IoG计算如下:

3 实验分析
3.1 数据集
本文使用KITTI数据集中的车辆对模型进行训练与评估。KITTI数据集包含7 481张图片用于训练与验证,另外还包含7 518张图片用于测试。该数据集中有许多相互之间严重重叠、遮挡的车辆目标,检测难度较大。训练中,数据增强方法与原始SSD一样,即随机改变图片的亮度、对比度、饱和度、色调,对图片进行随机剪切、镜像。
3.2 训练过程
本文目标检测网络基于VGG16,首先在ImageNet1000类数据集上对该网络进行10轮训练得到预训练参数。使用预训练分类网络获得的训练参数对检测网络结构进行微调,微调时采用随机梯度下降法(SGD),初始学习率设为0.001,并在迭代次数为80 000、100 000次时让学习率减小10倍。参数momentum和weight decay分别设置为0.9和0.000 5,训练批量大小为32,训练120 000次。
3.3 评价方法
本文对汽车和其他目标的检测是一个二分类问题,最终目的是正确检测出所有车,且没有将其他目标当作车。为了更好地评价模型,设置TP代表正确检测出的汽车,FP代表将其他目标当作汽车,FN代表将汽车检测为其他目标,TN代表其他目标没有被检测为汽车。准确率和召回率计算如下:
设某一类有N个样本,其中M个正例,那么可以得到 M个召回率:{1/M,2/M,…,M/M}对于每个召回率r,其最大准确率计算公式如下:

AP是衡量模型在每个类别上好坏,mAP衡量模型在所有类别上检测性能的高低,计算如下:

3.4 实验结果与分析
分别训练原始SSD,和改进型SSD_change+排斥损失,两个模型检测性能如表3所示。可以看出,mAP分别从87.54%、83.59%提高到了91.97%、86.36%,检测性能分别提高了约4.3%、3%。

表3 检测的mAP值
图5为原始SSD(左)和SSD_change(右)的单张图片检测效果图。显然,相比与原始SSD,SSD_change在重叠目标的检测上有一定的提高,对于远处小目标的检测有很大的提高,这是因为在conv4_3层中设置的区域候选框更好地匹配真实目标边框,降低了环境噪声的影响,网络可以更好地学习目标特征。同时删除了无用的区域候选框和特征提取层,降低了网络参数,提高计算速度。

图5 KITTI数据集样本举例
4 结论
1)重新设计SSD的区域候选框,使其分布在数据的聚类中心,因此区域候选框与目标真实边框重叠度高,提高目标检测性能,同时删除了多余的区域候选框和目标预测层,相比于原始SSD参数量更少,速度更快。
2)鉴于SSD对重叠目标检测较弱,在SSD原有损失函数的基础上,增加一项排斥损失,提高其对重叠目标的检测。
然而,车辆目标尺度与人、自行车之类的目标尺度相差较大,如果直接用一个网络对这些目标进行检测,网络需要学习复杂的特征映射关系,导致检测准确度不高。如何使单个网络对于尺度分布大的多个目标检测依然有很高的准确度,还需进一步研究。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
计算机技术与发展(2020年2期)2020-04-15
铁道通信信号(2019年6期)2019-10-08
火力与指挥控制(2018年3期)2018-04-19
雷达学报(2017年6期)2017-03-26
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
