
一种基于MinHash的改进新闻文本聚类算法
2019-02-25 13:14王安瑾
计算机技术与发展 2019年2期
王安瑾
(东华大学 计算机科学与技术学院,上海 200000)
0 引 言
随着互联网的发展,网络新闻中文本数量日益增多,每天用户面临的各个网站的新闻可以用数以万计来形容。出于用户对不同新闻的需求,近似新闻文本聚类已经是目前数据处理的一个重要研究课题。传统的文本聚类比如向量空间模型(vector space model,VSM[1]),一般是使用TF-IDF(term frequency-inverse document frequency)[2]提取出文本中的特征词,然后通过对特征词进行加权处理,用一个权重向量表示文本[3],构建特征词文本矩阵来进行聚类。但由于特征词权重向量维度高,且数据较为稀疏,因此利用向量空间模型进行文本聚类经常会占用很大内存且聚类速度慢。由Blei等[4]于2003年提出的基于贝叶斯模型的潜在狄利克雷分配(latent Dirichlet allocation,LDA)以概率分布的形式给出文档集中每篇文档的主题,通过分析文档的主题来进行主题聚类,这种聚类适用于大规模文本聚类,但是缺点也很明显,降维后维度太低,容易破坏文档的完整性[5]。因此,文中提出一种基于MinHash[6]的文本聚类方法。
现有的聚类方法主要有以下几类:
基于划分的聚类算法,如K-means[7]算法,一般通过给定K值,将N个待聚类样本构造成K个分组,每个分组就是一个聚类。算法通过反复迭代的方法使得同一分组中的记录尽可能近,而不同分组中的记录尽可能远。
基于密度的聚类算法,如DBSCAN[8]算法,该类算法中各个类别是通过样本分布的紧密程度决定的,同属于一个类别的样本之间紧密度较大,而与不同类别的样本之间联系较为疏松。只要某个区域中存在距离小于某个阈值的点,且该点周围的密度大过某个值,便能形成一个簇,从而实现聚类。
基于层次的聚类算法,如BIRCH[9]算法,顾名思义,该类算法对给定的数据集一层一层进行聚类,通过迭代的方法创建一棵分层的聚类树。层次聚类可分为自底向上的凝聚聚类和自顶向下的分裂聚类。
文中采用的是基于密度的聚类算法DBSCAN,相比其他聚类算法,该算法优点为无需给定最终聚类的个数,可以发现任意形状的簇且处理噪声能力强。
1 MinHash
1.1 Jaccard系数
Jaccard系数[10]是衡量两个文本之间相似度的系数。Jaccard系数的定义为:给定集合A和集合B,A、B中共有的元素个数占A、B总元素个数的比重即为A与B的Jaccard相似系数。即
Jaccard(A,B)=|A∩B|/|A∪B|
该系数的值域为0至1,系数越接近1,两个文本之间的相似度越高。
1.2 MinHash算法
MinHash(最小哈希)是局部敏感哈希算法(locality-sensitive hashing,LSH)[11]的一种,局部敏感哈希是适用于大规模高维度数据的一种快速最近邻查找(nearest neighbor search)[12]算法,其实质是基于一种假设,相似度很高的两个数据映射成同一个hash值的概率较大,而相似度很低的两个数据则很难映射成同一个hash值。
MinHash的原理[13]为,假设存在集合A、B,将集合A、B中的元素经过哈希函数哈希之后,如果其中具有最小哈希值的元素既在A∪B中也在A∩B中,那么hmin(A)=hmin(B),集合A和B的相似度就可以表示为集合A、B的最小哈希值相等的概率,即:
J(A,B)=Pr[hmin(A)=hmin(B)]
MinHash算法用于文本聚类的一般流程是,先将提取到的特征值向量和文档组成矩阵,通过多个哈希函数将特征值向量矩阵哈希成“签名矩阵(signature matrix)”,签名矩阵中的数据都是降维后的结果,然后将该矩阵中的行号进行随机变换并排列,取出某一文档对应的列中排在最前面的1,“1”对应的单词可以代表该文档,经过多次哈希随机变换就可以选取出多个特征值来代表这个文档。从而对文档实现了降维,高维度的文档被压缩为n个整数表示。然后计算两两文档之间的Jaccard系数即可算出文档之间的相似度。
牛养殖业尚处于发展阶段,但为人们的生活带来较大的改变,逐渐使人们奔向小康社会。但养殖中常会出现各种疾病,尤其是结核病,该病属于人畜共患的疾病,不仅要密切关注牛的身体状况还要对工作人员的身体状况进行观察,一旦发现结核病,应该立即隔离治疗,减少病菌的感染。同时,对病牛的饲养环境、粪便等进行有效的消毒以及处理,彻底消灭病菌,促进牛养殖业的健康发展。养殖户在饲养中需要明确结核病的临床症状、诊断方式、处理方法以及向有关部门报告,做到及时发现、及时隔离处理,减少对健康牛或者人的传染,减少经济损失。
2 DBSCAN
DBSCAN(density-based spatial clustering of application with noise)是一种基于密度的聚类算法。该算法中各个类别是通过样本分布的紧密程度决定的,同属于一个类别的样本之间紧密度较大,而与不同类别的样本之间联系较为疏松。通过选取核心点,将与其联系紧密的样本归为一类,就形成了样本的其中一个聚类,通过对多个核心点的划分,形成围绕这些核心点的多个聚类类别就完成了一次数据聚类。该算法的特点是聚类速度快,不需人为设定聚类后簇的个数且可以发现空间中任意形状的簇。
在DBSCAN中样本集的紧密程度是通过邻域反映的。该算法有两个重要的参数,即邻域半径Eps以及形成一个簇所需要的最小点数MinPts[14]。
假设输入数据集是D=(x1,x2,…,xm),则得知:
(1)半径邻域:对于数据集D中的任意一个样本数据,假设xi∈D,如果存在另一个样本数据xj∈D,可以使得其与xi之间的距离小于等于半径Eps,即Nε(xi)={xj∈D|distance(xi,xj)≤Eps},则称其为xi的半径邻域,或ε邻域。所有在xi的半径邻域中的点构成了一个子样本集,该样本集中的个数为xi的密度,记为ρ(xi)=|Nε(xi)|。
(2)核心点:若存在某一样本xi∈D,且在其邻域半径Eps内至少包含MinPts个样本,即ρ(xi)≥MinPts,则xi是一个核心点。
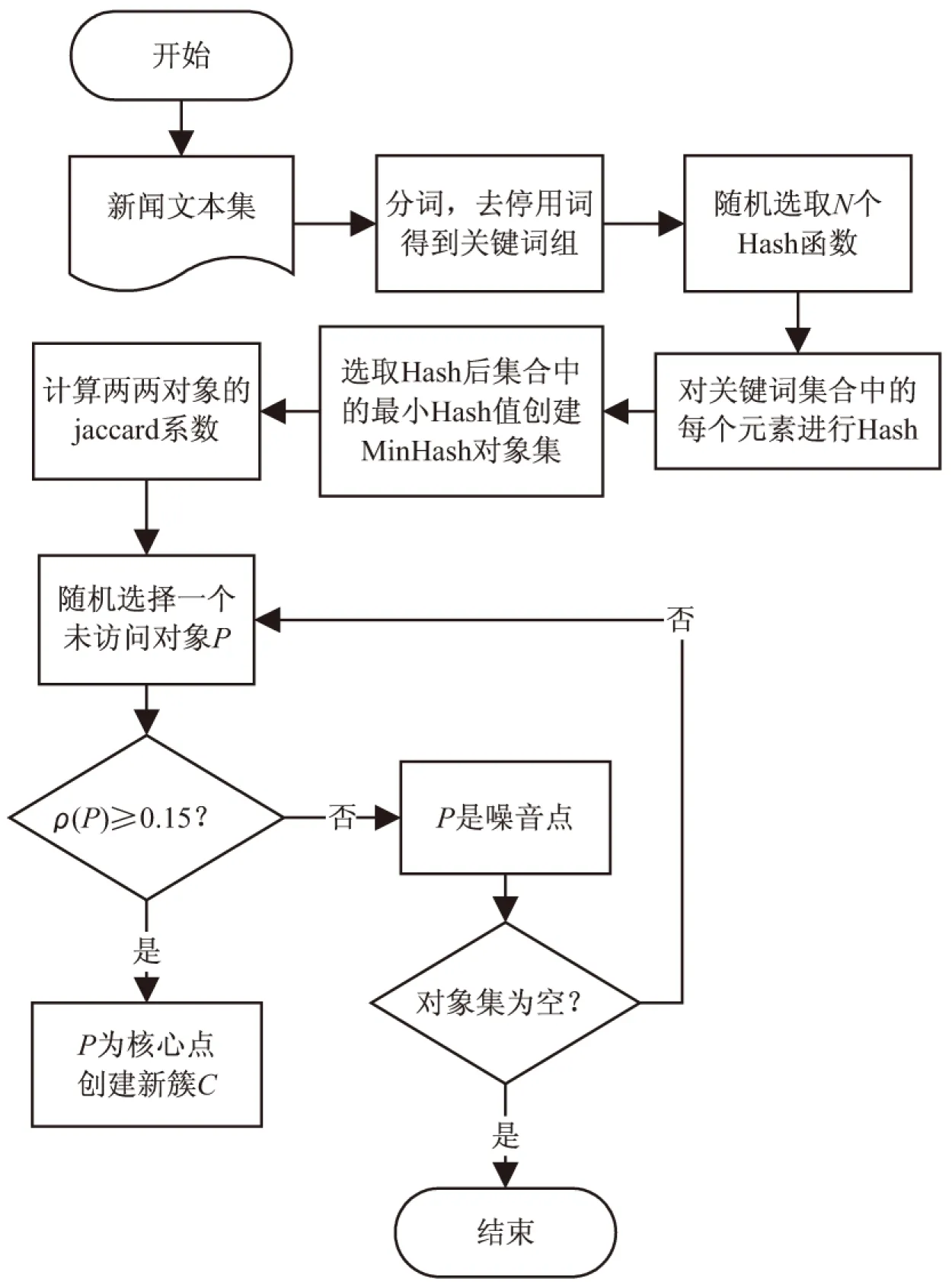
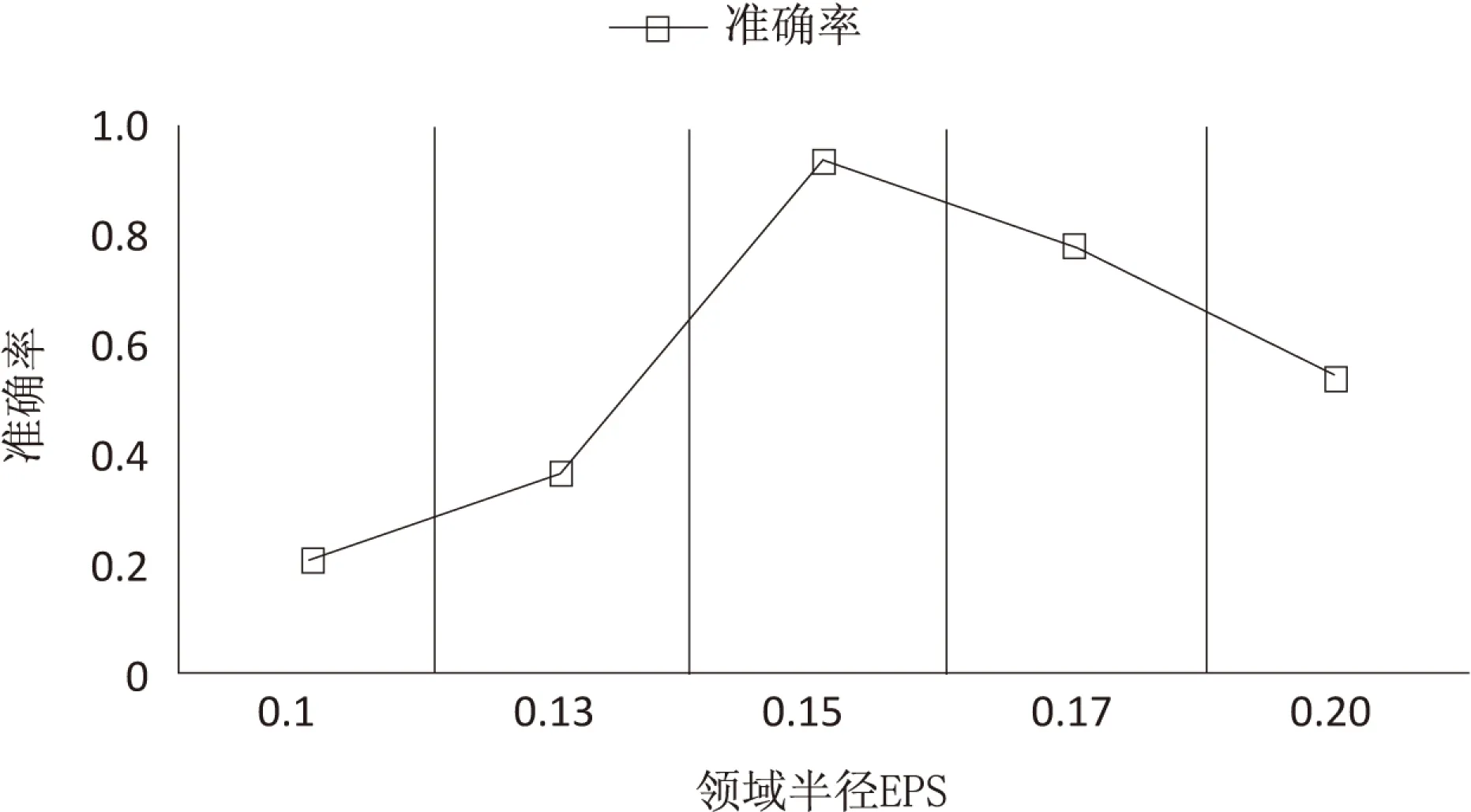
(3)边界点:若存在某一样本xi∈D,且在其邻域半径Eps内点的数量小于MinPts,即ρ(xi) (4)噪音点:数据集D中既不是核心点也不是边界点的点则为噪音点。 (5)密度直达:假设xi为核心点,如果xj位于xi邻域内,即xj∈Nε(xi),则称xj由xi直接密度可达。 (7)密度相连:对于xi∈D和xj∈D,如果xi,xj均是由核心点xk密度可达的,则称xi和xj密度相连。密度相连满足对称性。 其算法具体过程如下: 初始化核心点集和结果集,标记所有样本为未访问。遍历样本,确定每个样本邻域Nε(xi)并判断该样本邻域密度ρ(xi)是否大于等于MinPts,若是,将该样本加入核心点集合。选取任意一个核心点q,将其标记为已访问,如果该点ε邻域内至少有MinPts个样本,则新建一个簇C,并将q加入C中。对于核心点q邻域Nε(q)内样本集合中的任意一个点qi,如果该点未访问,则标记为已访问,判断其邻域内点的数量是否大于等于MinPts,若是,则将这些样本添加到Nε(q)中。如果qi还不是任何簇的成员,则将其加入到C中。重复上述步骤,直到所有核心点均被访问过。 新闻文本有一个鲜明特征,不同题材新闻之间的关键词基本不相同,而同类新闻关键词相似度较大。这个特点决定了利用Jaccard系数来判断两个新闻文本之间的相似度是个不错的选择。因此,文中提出了基于MinHash的DBSCAN新闻文本聚类算法。MinHash是基于Jaccard相似系数的局部哈希算法,适用于文本聚类,该算法结合了MinHash算法和DBSCAN算法的优点,实现了将高维文档转化为低维数据并将相似文档进行聚类的功能。 对于给定的文本集D={d1,d2,…,dn},对集合中所有文档依次进行读取并分词。去除“你”、“我”、“日”、“的”等常用停用词并按照所得分词的权重大小提取该文档的关键词集合K={k1,k2,…,km},其中m≥10,即只有由10个以上的关键词组成的新闻文本才认为是有效的文本。 得到文本关键词之后构建一个文本-关键词矩阵,矩阵的行代表关键词,列代表文档,若关键词i在文档中j出现,则将该矩阵中i行j列标记为1,否则为0,这样就可以得到一个稀疏的特征矩阵。通过多个hash函数将特征矩阵的所有行进行映射,如果该行当前值为0,跳过,如果为1,取哈希值与原始值之间的最小值来构造一个签名矩阵,从而实现对特征矩阵的压缩。 将降维之后的矩阵作为DBSCAN聚类算法的输入集,对于矩阵中的每一列,即文本的特征哈希集合分别两两计算它们的Jaccard系数,并与给定的阈值Eps进行比较,并判断该点周围所有与其距离大于阈值的点的个数是否大于MinPts。如果某一点与其他任一点的Jaccard系数大于Eps且其周围与它的Jaccard系数大于Eps的点的个数大于或等于MinPts,则该点为核心点,与核心点密度可达的所有点均为一类,否则,为另一类别或噪音点。算法流程如图1所示。 图1 算法流程 所用的实验数据是来自复旦大学计算机信息与技术系国际数据库中心自然语言处理小组的中文文本语料库,共包含350篇新闻,分为艺术、体育、经济、计算机、环境五个大类,各个类别的新闻篇数为70篇,如表1所示。 表1 复旦大学中文文本语料库 由于邻域半径Eps对聚类效果有一定的影响,于是经过多次实验对聚类结果进行比较观察最佳Eps参数。最后确定了在周围最小点数MinPts取15时,文中算法能得到较好的聚类效果。当MinPts=15时,不同邻域半径下聚类的准确率如图2所示。 在文本聚类算法中,经常使用以下评估方法对算法进行评估。 准确率=正确识别出的文本数目/识别出的文本总数 召回率=正确识别出的文本总数/语料库中的文本总数 F值(F-Measure)=(2×正确率×召回率)/(正确率+召回率) 图2 不同邻域半径下聚类的准确率 通过文中算法,对上述350个近似新闻文本进行聚类后得到如下结果,见表2。 表2 聚类结果 从表2可以得知,基于MinHash的DBSCAN聚类算法对于新闻文本有着不错的聚类效果,准确率和召回率分别为0.93、0.81,平均F值达到0.86。图3为文中聚类算法与其他传统文本聚类算法(VSM、LDA)的评价指标比对情况,可见,相比于传统的新闻文本聚类算法,文中算法具有更高的准确率和召回率。 图3 不同算法的评价指标对比 文中提出的基于MinHash的文本聚类算法是基于不同类型新闻文本特征词不同的特点提出的,利用MinHash算法对表示新闻文本的特征词进行降维,从而减少内存的消耗以及加快聚类速度,而利用DBSCAN算法不需事先指定簇的个数,可以发现任意形状的类别,两种算法结合对于新闻文本聚类有着很好的效果。由于实验所使用的文本集数量不多,所以在今后的实验中将进行大数据新闻文本的聚类研究,并结合Shingling[15]算法提升聚类的效果。3 基于MinHash的改进DBSCAN聚类算法
3.1 文本处理
3.2 对关键词组进行降维
3.3 DBSCAN文本聚类
4 实验结果与分析
4.1 实验数据

4.2 结果分析


5 结束语
猜你喜欢
大数据(2022年4期)2022-07-25
农业工程学报(2022年7期)2022-07-09
客联(2022年3期)2022-05-31
逻辑学研究(2021年3期)2021-09-29
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
电脑爱好者(2017年7期)2017-05-06
