
运动员训练专家系统知识库的设计与实现∗
2019-02-27 08:31张鹏海
计算机与数字工程 2019年2期
毕 璐 刘 斌 张鹏海
(1.陕西科技大学电气与信息工程学院 西安 710021)(2.西藏民族大学院体育学院 咸阳 712082)
1 引言
运动员训练知识的获取、分析与提炼任务对实用专家系统的开发是一个比较复杂的过程,不同的研究人员由于个人的背景、专长及所研究问题的领域不同,他们会采用不同的知识获取方式、知识表示方式、不同的推理控制方式和解释机制。此外,不同的开发人员根据自己对开发工具掌握的熟练程度不同,会选取不同的开发工具。但用不同的开发工具进行开发,工作的难度(主要体现在推理机的实现)会大不相同[1]。因此进行运动员训练专家系统的开发,从工程应用上来说应该是选取开发周期短、程序代码相对简洁、实用性强的开发方案。专家系统的知识获取一直是人工智能领域的一个“瓶颈”。
2 运动员专家训练系统简介
在设计运动员训练专家系统之前,首先需要广泛收集运动员教练的执教经验和运动员的比赛经验,主要获取的途径有访问运动员教练,查询与运动员训练、运动员比赛有关的论文和书籍,从Internet上搜索如何训练运动员的信息[2]。在收集完所需的资料后,下一步的工作是提取和鉴别,我们从中选出有价值的资料,在这里主要选择运动员的选拔、运动员的训练计划安排、训练和比赛中的故障排除这三大模块,然后在这个基础上又进一部细化,将运动员的选拔模块又细分为身体形态、生理机能指标选拔。具体划分如图1所示[3~5]。

图1 运动员训练专家系统树状逻辑结构图
这里采用了层次划分法,逐层细化,层层深入,可以将运动员训练知识以有效的方式组织起来[6]。运动员训练计划安排模块是知识介绍性的模块,根据运动员的生理机能指标,专家系统就会给出详细而准确的训练计划安排,将运动员的身体机能指标训练到最佳状态。训练和比赛中的故障排除的主要任务是根据训练和比赛过程中可能出现的特殊状况给出解决方案,如比赛的赛场、天气、环境、运动员的操作技能、器材的调整能力、对比赛规则的掌握程度以及他们在竞赛期间的饮食、心理状况等,采用了判断树的方法来描述判定流程,从故障现象出发,列出所有可能产生此类现象的原因,再由用户根据现象逐一排除,最终确定问题产生的原因,并给出专家建议[7~8]。
3 知识库设计
3.1 知识库构建步骤

图2 知识库的构建步骤
知识库构建流程如图2所示,主要步骤描述如下[9]:
1)运动员训练专家归纳总结训练高水平运动员的知识经验;
2)知识工程师对运动员训练专家归纳总结的训练高水平运动员的知识进行分析处理,转化为计算机的语言加以表示;
3)在知识获取过程中,运动员训练专家系统指标知识可直接存储到知识库中;
4)在知识库的设计过程中,知识工程师通过特定的计算机录入语言,将运动员训练专家系统规则性知识存入规则库中;
5)知识获取机构作为沟通机制,通过与运动员训练领域专家地相互作用,不断地把知识库构建的相关问题传达给运动员训练领域的专家,并把处理意见传输回知识获取机制[10];
6)知识工程师又是运动员训练领域专家和知识获取机构沟通的桥梁和纽带,某一部分修改意见需要知识工程师的转换处理方可写入知识库[11]。
3.2 知识库结构组织
树(tree)是由结点(node)和分枝(branch)组成的层次数据结构,结点用于存储信息或知识,分枝连接各结点。有时分枝也称为连接(link)或边(edge),而结点称为顶点(vertice)。一棵普通的二叉树,每个结点有0、1或2条分支。在一棵有向树中(oriented tree),根结点(root node)处于最顶层(hierarchy),而叶结点(leaf)在最底层[12]。树可以看作是一种特殊类型的语义网,其中,除根结点外,每个结点只有一个双亲结点(parent)以及有0个或多个子结点(child node)。
由于具有层次特性,即双亲在子结点之上,所以树通常用于对象分类,如家族树,它表明家族的祖先和家庭成员之间的关系。树的另一个重要的应用是做判定,此时称之为判断树(decision trees)。我们将用“结构”(structure)一词来表示树,一个判断结构既可以作为知识表示模式,也可以作为推理方法。
判断树结构可以很好地解决某些类别的分类问题。判断树的解决方法是通过一系列问题和判定来调整搜索区域以减少可能的解决方案而得到的。适合用判断树解决的问题可由其特征描述,该特征值从一组预先决定的可能的解决方法中提供一个答案给这个问题[13]。判断树的叶结点代表能从树派生出来的所有可能的解决方案。这些结点称为答案结点(answer nodes),树上所有其它结点被称为判定结点(decision nodes)。每个判定结点代表一个问题或判定。当回答问题或作判定时,它决定选取一个合适的判定分支继续下去。在简单的判断树中,问题可以是“yes”或“no”的问题。例如:“该动物是暖血动物吗?”如果回答是“yes”,则结点的左分枝代表继续的路径;如果回答是“no”,则结点的右分枝代表继续的路径[14]。通常,如果选择过程总是只产生一个单独的分支的话,判定结点可使用任何准则来选择接下去的分歧。因此,判定结点可以选择一条分枝,它可对应于一组值或一个值范围、一系列情况或对应于一些从判定结点状态映射到分枝的功能[15]。
将运动员选拔的经验知识汇总整理,按照层次结构建立的运动员选拔判断树的一部分如图3所示。
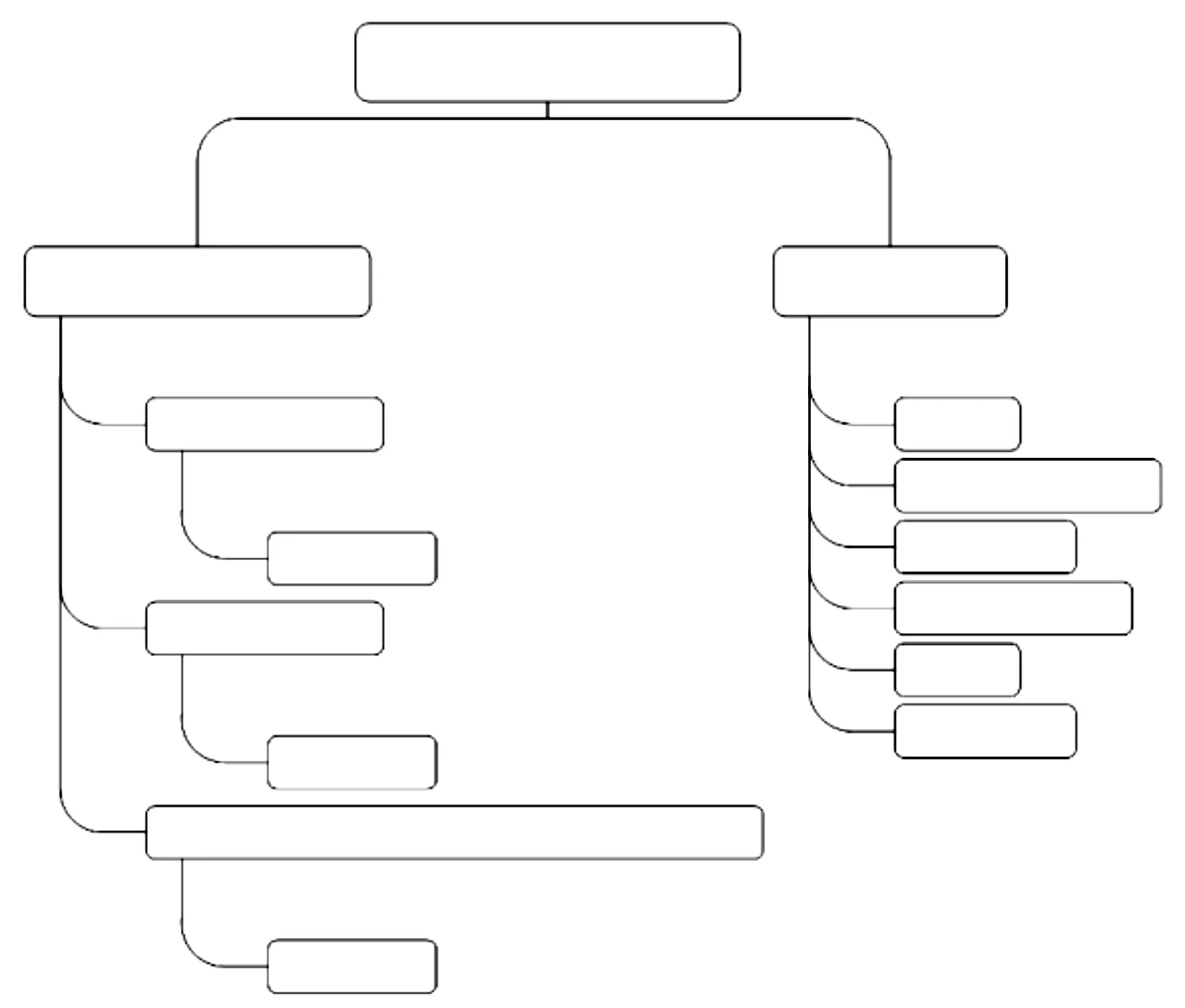
图3 运动员选拔判断树
判断树的操作过程,采用了试探的方法来解决问题:
IF身体形态不达标
Then询问不达标原因是什么
IF身体形态达标
Then生理机能测评
IF体重超重或不足
Then选择解决方案1
IF身高超高或不足
Then选择解决方案2
IF体重/身高×1000、下肢长/身高×100无优势
Then选择解决方案3
4 知识获取与写入
知识是专家系统的核心,知识表示技术是专家系统乃至人工智能的重要研究内容之一。在建立某个特定任务的专家系统时,首先要考虑的就是要选用合适的知识表示策略。专家系统中考虑的是所谓“知识”,知识的含义要更丰富,当然数据、信息也可认为是知识。这如同程序设计中对数据结构的选择。一个好的程序设计必须选择简洁的变量、数组、链表、队列、树、图、网络,甚至外部数据库如Microsoft Access,SQL Server或者Oracle。在Prolog中,KR可以是规则、自定义模板、对象和事实。
如图3所示的判断树,判断树的叶结点代表能从树派生出来的所有可能的解决方案,这些结点称为答案结点,树上的其他结点则被称为判定结点。在本系统中,答案结点所包含的内容是专家的建议,判定结点所包含的内容是专家询问和备选答案。而要表示一棵判断树除了记录各结点储存的数据信息外,还必须记录父结点与子结点之间的联系及父结点转到子结点的条件。
在判断树中,每个结点将被表示为一个事实。下面的自定义数据结构(1)将既用来表示答案结点又用来表示判定结点:
node(name,type,question,answer,[node1,node2,node3,…])—自定义数据结构(1)
该数据结构由结构名和5个参数构成,参数可以是简单的数据类型或另一种结构。name参数是对应于此结构的唯一的名字,type参数表示结点的类型,它包含值—answer(答案)或decision(判定)。question参 数 和 列 表[node1,node2,node3,…]都只能用于判定结点。question参数表示遍历某个判定结点时所问的问题。列表[node1,node2,node3,…]表示对问题作出回答后所有可能经历的结点,具体要经历哪一个结点要依据用户的回答。answer结点只能用于答案结点,它是遍历一个答案结点时对判断树的答案。我们从图3运动员选拔判断树中取出一个分支并将结点命名,如图4所示。
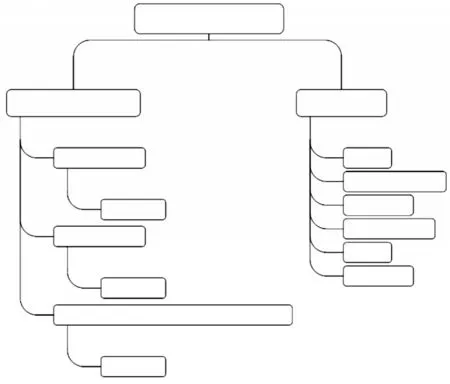
图4 判断树的一个分支
用自定义数据结构(1)来表示结点,如下例所示:
node(node_fail,decision,ques_fail,_,[node_ans1,node_ans2,node_ans])
这表明node_fail结点是一个判定结点,该结点的问题是ques_fail代表的意思为:不达标的原因是什么?node_fail结点的子结点为node_ans1、node_ans2、node_ans3,该子结点不仅代表ques_fail作出回答后所有可能经历的结点,而且它们代表了一系列提供给用户的选择(在这里选择为:体重超重或不足、身高超高或不足、体重/身高×1000、下肢长/身高×100择优录取)。
我们用自定义数据结构(1)来表示node_ans1,node_ans2,node_ans3结点,如下例所示:
node(node_ans1,answer,_,ans1,_)
node(node_ans2,answer,_,ans2,_)
node(node_ans3,answer,_,ans3,_)
根据事实中第2个参数answer可node_ans1,node_ans2,node_ans3都是答案结点。node_ans1给出的答案是ans1(即解决方案1:运动员要想控制住自己的体重应当从饮食和训练方面双管齐下,要加强训练的强度,在饮食上一定要多加控制。如果体重不足,可以合理增加饮食,并保持训练强度。),node_ans2给出的答案是ans2(即解决方案2:运动员的身高在某些特定的比赛项目上有特定的要求,选择适合自己的项目和分类)。node_ans3给出的答案是ans3(即解决方案3:体重/身高×1000数值越小越好,下肢长/身高×100数值越大越好,择优录取),如表1所示。
Visual Prolog不支持中文系统,并且由于显示的中文内容过多,在表示结点的事实中我们使用了英文字符中来表示它所对应的中文,当需要显示中文时,只需通过一定的转化就可使界面上显示相应的中文,其英中文的对应见表,其具体转化过程是这样来实现的,用Access数据库保存中文字符串和对应的结点名,当需要在界面上显示中文时,就可以将结点名作为查询条件查出所对应的中文字符串,然后在界面上显示。
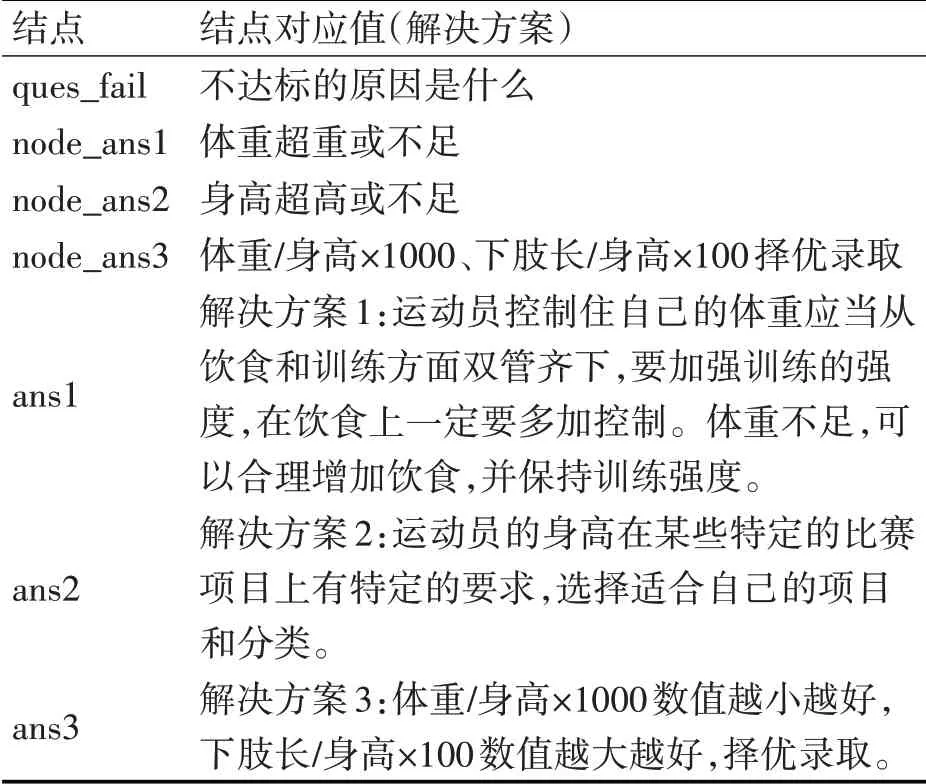
表1 自定义数据结构结点与对应值表
根据所举的例子可以看出,自定义数据结构(1)不但可以表示各结点储存的数据信息,还可以表示父结点与子结点之间的联系及父结点转到子结点的条件。因此我们要表示一棵判断树,只需要把该判断树的所有结点按自定义数据结构(1)表示出来。
遍历树得到答案结点的过程较为简单,推理过程以设置判定树的当前位置为根结点开始。若当前位置为一判定结点,必须以某种方式回答与该判定结点相联系的问题,假设当前结点有3个分支branch1,branch2,branch3,如果用户选择的分支是branch1,则当前位置被设置为同当前位置的branch1分支相联系的子结点;如果选择的分支是branch2,则当前位置被设置为同当前位置的branch2分支相联系的子结点。如果答案结点成为当前结点,则此答案结点的值就是询问该判断树所得的答案。否则,处理判定结点的过程将重复进行,直至到达一个答案结点。关于这个算法的伪代码如下:
procedure Solve_Tree
将根结点置为当前结点;
while当前结点是一个判定分枝do
询问与该判定结点相联系的问题,然后用户以某种方式作出回答
将当前结点设置为与当前结点的被选择分支相联系的子结点
end do
返回当前结点的答案
end procedure
在算法Solve_Tree中,定义current_node(node_name)谓词表示当前所访问的结点,该谓词只有一个参数:结点名,并且由于当前所访问结点是动态变化的,将该事实存储在内存的动态事实库中,使得Prolog程序在运行过程中,还能够改变它自己。定义next_node(node_name)谓词表示用户选择的结点,即与当前结点的被选择分支相联系的子结点。此事实也存储于动态事实库中,由Delphi程序根据用户的选择插入到动态事实库中。
5 具体设计
本系统的推理机制的编制是通过判断树建立的,将复杂的问题逐级细化为一个个较为简单的问题,逐一解决、逐层推进,最终确诊。主要用4条规则init、next、if_leaf(由两个子句构成)、back来实现遍历判断树的操作,用3条规则show_radiolist、show_sug(answer)、show_question用来实现对用户界面控制。我们以图4为例,介绍一下规则推理的过程。首先假设当前的结点位置为node_start,这时用户界面应显示专家询问“运动员身体是否达标?”若用户回答为“no”,则进入下一个结点node_fail,并将node_fail置为当前结点,用户界面又会显示结点node_fail所对应的信息—专家询问“不达标的原因是什么?”和备选答案“体重超重或不足”、“身高超高或不足”“体重/身高×1000、下肢长/身高×100择优录取”,若用户做出的回答是“体重超重或不足”,则下一个要经历的结点是node_ans1,node_ans1是一个答案结点,该结点将会给出“解决方案1”,解决方案1具体来说是“运动员要想控制住自己的体重应当从饮食和训练方面双管齐下,要加强训练的强度,在饮食上一定要多加控制。如果体重不足,可以合理增加饮食,并保持训练强度”。结合提出的算法Solve_Tree,用规则实现遍历判断树的方法,其流程图如图5所示。
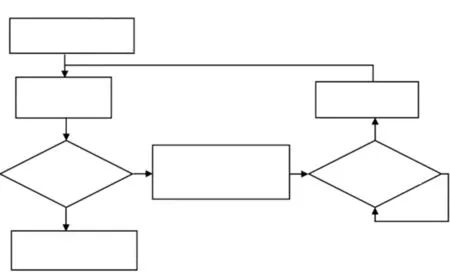
图5 遍历判断树的流程图
6 结语
采用运动员教练经验构建知识库,将判断树方案引入运动员训练专家系统中,并采用Prolog编程技术来实现了这一方案。此方案不但编码简洁,结构灵活,便于系统的修改和扩展,而且推理正确,效率较高,能给运动员专家级的指导,对运动训练进行科学的数据分析和运用,使用计算机技术进行更加专业化辅助训练,通过运动训练专家系统辅助训练运动员,使他们能在比赛中取得优异的成绩,收到满意的效果。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
课程教育研究(2021年23期)2021-04-13
中国信息技术教育(2020年22期)2020-12-08
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
计算机教育(2006年2期)2006-02-23
计算机教育(2006年2期)2006-02-23
