
低字典相干性K-SVD算法研究∗
2019-03-01 02:51李海洋
计算机与数字工程 2019年1期
牛 彪 李海洋
(西安工程大学理学院 西安 710048)
1 引言
图像是一种重要的信息源,随着科学技术的发展,越来越多高质量的图片被社会所需要,因此图像去噪是广大研究工作者最为关心的问题。图像去噪的基本思想为通过抑制噪声,提高图像质量从而来满足对图片更高层次的要求,针对该问题,国内外研究学者展开了一系列的研究,而基于图像稀疏表示理论的方法一直被广泛关注,如Donoho等[1]提出了著名的小波阈值方法;2001年Romberg等[2]在小波域下利用隐马尔可夫模型达到了去噪的目的;Portilla[3]则通过建立一种高斯混合模型来实现去噪;06年Arthur等[4]提出了一种新的MGA方法:无下采样Contourlet变换(NSCT),并通过Bayesian估计方法实现图像去噪。这些方法都取得了初步的成效。
2006年 Elad等[5]提出了 K-SVD(K-singular value decomposition,K-SVD)字典学习算法,它的目的主要是通过固定当前字典进行稀疏编码求解稀疏系数,进一步根据稀疏系数对字典的原子进行更新,采用交替迭代的思想,从而训练得到一个新的过完备字典(over complete-dictionary)。该字典是通过学习训练得到的,若直接应用于图像去噪,由于字典相干性较高,会导致学习字典中噪音原子和无噪原子相似度高,去噪后的图像有噪音残留或者图像较平滑,并且K-SVD字典学习算法计算复杂度较高[6]。而相干性约束是过完备字典学习算法中不可忽视的一个重要因素。一般而言,字典的相干性和其稀疏编码性能有紧密的关系,在相同的冗余度条件下,低相干性可加快稀疏编码的速度,改善信号的重构性能[7]。此外,低相干性还有助于避免字典原子对训练样本的过拟合,避免字典中出现过于相似的原子对。
为降低字典的自相干性,Mailhe[8]提出非相干K-SVD(Incoherent K-SVD,INK-SVD)字典学习算法,在字典更新步骤中,对原子进行操作,如果发现某一对原子的相干性大于指定的相关性门限,则对两个原子进行旋转达到降低其相干性的目的,但是该算法在字典学习过程中相似的原子进行旋转比较耗时,且其计算复杂度较高。Barchiesi等提出了迭代投影和旋转的低相干性字典学习算法[9]与INK-SVD算法的思想类似,它是对整个字典而不是原子进行降低相干性和旋转操作,但是该算法训练得到的字典,其稀疏表示性能有所下降。2012年 Christian D.Sigg 等[10]在《Learning Dictionaries with Bounded Self-Coherence》一文中提出 IDL(Incoherent Dictionary Learning)的字典学习算法,但是该算法不能保证信号的稀疏表示性能,且需要计算矩阵的梯度。
本文在K-SVD算法极小化目标函数下,添加一项刻画字典相干性的惩罚项以降低字典相干性,称该方法为低字典相干性K-SVD算法。在给最大化所得的稀疏度的前提下尽可能有效地控制训练字典的自相关性。具体而言,本文在IDL字典学习算法基础上对K-SVD算法进行改进,采用对字典原子逐一更新的优化目标,从最大化所得稀疏编码到 逼 近 一 个 等 角 紧 框 架[11](Equiangular Tight Frame,ETF)的过程,这是一个对于给定原子数量基于实现最小相干性的字典过程。限制字典的相干性其优势在于更好地编码支持恢复和改进的泛化性能,其中字典自相干的界限直接在原子更新步骤中执行,通过改变拉格朗日乘子γ,进而实现代码稀疏度最大化和字典相干性最小化的目标。
通过实验对比发现,低字典相干性K-SVD算法在一定程度上减少了算法迭代更新的时间,降低了原子的自相干性,从而使得图像在去噪过程中可以更好地恢复重构。
2 K-SVD字典学习模型
在图像去噪的相关研究中,基于字典学习可以提取样本数据的内部结构特征的这一特点,通常采用该方法达到图像去噪的目的。
2.1 字典学习
字典学习最早是由 Olshausen(1996)[12]提出,发展至今该方法已经有了较为成熟的理论与较为丰富的实践运用。字典学习也可简单地称其为稀疏编码,字典学习较偏向于学习字典,从矩阵的角度来看,字典学习的基本过程为,通过给定样本数据集X,其中X的每一列代表每个样本,字典学习的主要目的是通过将样本数据集X分解成如下形式的矩阵进行操作:

其中,D代表字典矩阵,D的每一列称之为原子,C代表对应的系数矩阵,式(1)需同时满足以下约束条件,即系数矩阵C要尽可能的稀疏,字典矩阵D的每一列即每一个原子是一个归一化向量。
通过上述分析可知,字典学习的主要目的是极小化如下目标函数:
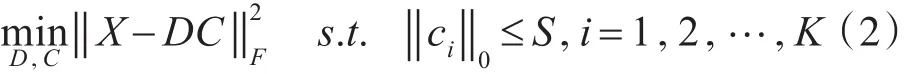
其中,X∈RM×N为信号的样本数据矩阵且满足,M,N分别代表样本数据的维数和个数;D∈RM×K(M<K)为过完备字典矩阵且有,其中该矩阵的第k列dk称为字典的原子;C∈RK×N为信号的稀疏表示系数矩阵且有,‖c‖代表的为稀疏系数矩阵中每一列i0的非零元素个数,S表示为稀疏度。
综合稀疏模型一直以来受到广大研究学者的关注,基于这一模型的字典学习方法也是字典学习理论研究中相对成熟的部分,大多数求解式(2)的算法采用的都是系数更新和字典更新交替迭代优化的方法。算法在系数更新部分没有较大的差异,主要不同之处在于对字典的更新方式上,固定字典D更新稀疏系数矩阵X是常见的稀疏编码问题。通俗的来说,任何一种稀疏编码方法都可以用于系数更新,所以近些年来有越来越多的稀疏编码方法被大家所提出,因此通过固定稀疏系数矩阵X进而更新字典D是研究字典学习算法较为关注的一个重点。
2.2 K-SVD算法
基于上述分析本文主要对K-SVD字典学习模型展开详细的论述。K-SVD算法是Elad等提出的一种新的字典学习算法,该方法是根据K均值聚类发展而来的,因此可将其视为广义的K均值算法。该算法主要分为稀疏分解和字典更新两个部分,稀疏分解阶段,首先得到训练样本的字典D,再通过OMP(Orthogonal Matching Pursuit)[13]算法求解稀疏表示,具体通过优化如下函数:

在此基础上,采用SVD分解算法对字典进行更新。该算法主要是通过对字典的每一列进行更新,从而求得最优字典的过程,字典更新阶段,该算法主要通过如下目标函数进行描述:

其中,X为图像信号所对应的矩阵,D为需要训练的字典矩阵,C为字典矩阵D所对应的稀疏表示系数矩阵,dj和dk分别为字典矩阵D所对应的第j个和第k个列向量,cj和ck分别为稀疏系数矩阵所对应的第 j个和第k个行向量,E为对应的误差矩阵。
K-SVD算法使非参数字典适应训练数据,在算法的每次迭代中,这些原子被更新替换,若原子之间的相干性过高,则会导致替换原子与字典不一致的概率增大,因此这种策略并不能够保证字典的自相干性低于一般的门限阈值。所以为了更好地解决这一问题,本文通过如下方式对字典学习算法进行改进,从而达到在稀疏度最大化前提下降低原子相干性这一目的。
2.3 IDL字典学习算法
假设给定训练图像 X∈RN×M包含M 个信号,IDL字典学习的实质是找到恰当的且原子之间相干性较小的字典D∈RM×K( )M≪K 并使得每个信号xi可用字典D表示,其模型表示如下:

其中拉格朗日乘子γ用于控制最小化逼近误差和最小化自相关性之间的权衡。式(5)中的第二部分惩罚项用于平衡原子之间的相干性。
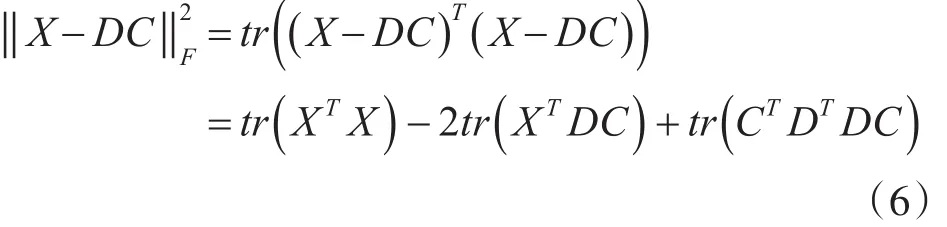
第二项可写为
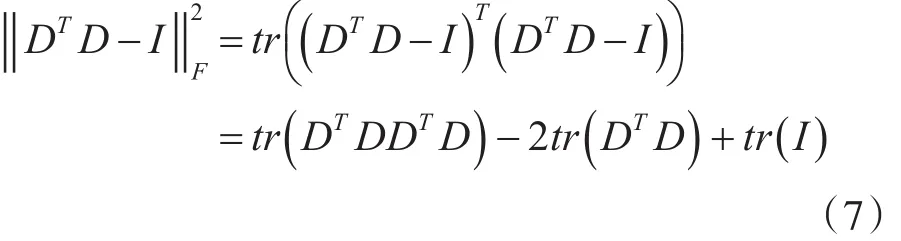
由式(6)和式(7)可知,将式(5)对 D 求导,其梯度表示如下:
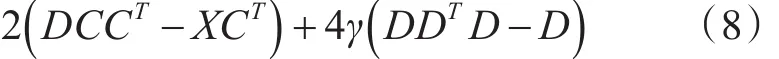
对式(5)的求解采用的是有限存贮拟牛顿法[12]LBFGS(Limited-memory BFGS)。
3 低字典相干性K-SVD算法
目前主流的字典学习算法,大都无法有效地降低字典的相干性,但字典的相干性对图像去噪的效果又起着重要的作用。本文主要在K-SVD算法极小化目标函数下,添加一项刻画字典相干性的惩罚项以降低字典相干性,称该方法为低字典相干性K-SVD算法。
3.1 算法相关知识
一般来说,通常采用互相关这一概念来刻画矩阵列之间的相干性。互相关定义如下:矩阵A的互相关是A中不同列的归一化内积的绝对值中的最大值[14],主要用于刻画矩阵列之间的相关性,具体表达式如下:

其中,aj表示矩阵A的第 j列。
相干性约束是过完备字典学习算法中需要考虑的一个重要因素。正交字典的相干性为0,过完备字典由于原子数量大于信号维数,原子之间的相干性大于0。一般来说,字典的冗余度越大其相干性也越大,字典的相干性对其稀疏编码性能十分关键,在相同冗余度的前提下,低相干性可加快稀疏编码速度,改善信号重构性能,另外低相干性还有助于避免字典原子对训练样本的过拟合,避免字典中出现过于相似的原子对。
对于一般过完备字典的相干性,可以证明其存在一定的范围,即存在一个下界(Welch Bound)值,通过如下定理进行描述。
定理1 假设字典D∈RM×K且M<K,列向量归一化,则字典D的相干性满足:

当式(10)等式成立时,字典D的相干性达到最小,这样越接近于正交基。所以,如何将字典的相干性逼近于其边界值,就成为了稀疏信号恢复的关键。Tropp等[14]提出当且仅当字典D是等角紧框 架(Equiangular Tight Frame,ETF),且 满 足K≤M(M+12)时式(10)中的等号成立,即。同时若D为ETF时,则D是行满秩矩阵,且具有M个非零的奇异值,其值均为。等角度紧框架的具体定义如下:
定 义 1[15~16]假 设 D∈RM×K且 M<K ,,列向量归一化,若满足:

且

其中I是一个N×N的单位矩阵,K,M分别对应字典矩阵D的列数和行数,即字典矩阵D的列向量构成一个等角紧框架,那么D或者D的列向量组成的集合称为等角紧框架。
基于等角度紧框架具有最小相干性的这一特点,本文考虑通过逼近等角度紧框架(Equiangular Tight Frame,ETF)的方法,从而达到降低相干性的目的。
3.2 算法模型
本文为了解决降低基于K-SVD算法下的字典自相干性问题,在K-SVD算法的极小化目标函数下,添加了一项有关字典D的自相干性惩罚项,具体表达形式如下:

其中,xi为图像信号所对应第i个训练样本,即图像块内像素展开的列向量,X={x1,x2,…xi}∈RN×M,D∈RN×K为需要训练的字典矩阵,ci是样本xi所对应的稀疏表示系数,λ,γ为拉格朗日乘子,用于控制重构误差,极小化字典相干性与稀疏度之间的权衡。
基于改进K-SVD降低过完备字典原子相干性的算法流程
算法:改进K-SVD降低过完备字典原子相干性的算法。
2)初始化:
初始化字典:构造 D(0)∈Rn×m,可以使用随机矩阵,或随机选取m个样本作为字典。然后对字典D(0)的列标准化。
3)迭代步骤:
(1)稀疏编码阶段:固定字典D,上式的稀疏编码可重新定义如下,

(2)固定稀疏编码系数矩阵C,则字典更新目标函数如下:
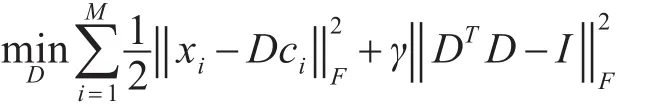
写成矩阵形式,如下:
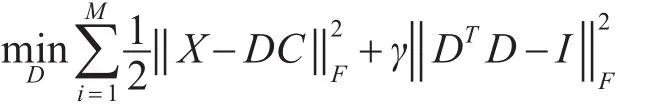
对目标任务中的D进行奇异值分解(svd),即D=UΣVT并简化式子如下:

(3)字典更新:同理K-SVD算法,但是不在使用u1,v1更新字典,而是使用使得上式最小的ui,vi更新字典和稀疏系数矩阵。
4)输出:得到训练字典D。
4 实验结果与分析
为了验证本文所改进的算法对字典原子相干性的影响,应用本文算法与K-SVD算法进行图像去噪实验对比分析。利用CPU为4GHz,内存为8GB的计算机,通过Matlab R2016a仿真实现。实验图像为512×512像素,图像分块为8×8,字典大小为64×256。
采用字典训练时间、峰值信噪比(PSNR)和字典原子间的相干性作为衡量两个算法性能评价标准 。 峰 值 信 噪 比 (PSNR):。其中MSE是原图像与去噪后重建图像之间的均方误差。实验图像为512×512像素,图像分块为8×8,字典大小为64×256。下面列出了图像的实验结果对比。
4.1 字典相干性的测量
为了验证本文所采用的算法对字典相干性是否有所改进,将本文所改进的算法与K-SVD算法所构造的字典进行相干性对比分析。实验中,初始字典D∈RN×K是随机生成的,列向量归一化的,每列向量中非零元素位置随机分布,其值服从高斯分布。最小相干性边界值μ=0.1085。则在不同的高斯噪声标准差下由本文算法所训练的字典的相干性与K-SVD算法的字典相干性表1所示。

表1 字典相干性对比分析
由图1可知,在γ一定的情况下,本文所改进的K-SVD算法与传统的K-SVD算法相比较,在噪音水平一致的条件下,由K-SVD算法训练得到的字典,其相干性比本文算法训练出的字典的相干性大,即本文算法的字典相干性明显低于传统的K-SVD算法。上述分析表明本文所改进的算法在降低字典相干性问题上具有较大的优势。
4.2 图像去噪实例
比较本文算法与传统的K-SVD算法应用于图像去噪,在噪音水平相同的条件下,进行比较去噪效果。下列是标准的Lena图在σ=25的高斯白噪音的干扰下去噪的效果图。

图1 本文算法与K-SVD算法对Lena图去噪对比

图2 本文算法与K-SVD算法训练的字典

图3 本文算法与K-SVD算法对house图去噪对比

图4 本文算法与K-SVD算法训练的字典
通过上述去噪实例的对比,可以看出在噪音水平相同的情况下,本文改进的算法有良好的去噪效果。
实验中分别在高斯噪声标准差σ=5,10,15,20,25不同噪音水平下进行图像去噪测试。获得峰值信噪比PSNR值和运行时间,其测试结果,如表2所示。
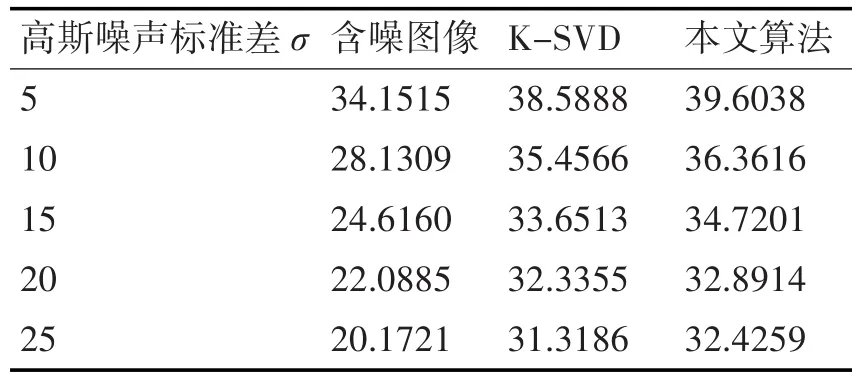
表2 两种去噪方法对Lena图像去噪后的峰值信噪比PSNR(dB)

表3 两种去噪方法对house图像去噪后的峰值信噪比PSNR(dB)
由上表的PSNR值,可以看出在相同的噪音水平下,两种算法都可以有效地去除噪音,改进后的算法能够更加有效地去除噪音,在不同标准差下本文算法还是有一定的优势。
下面给出lena图像和house图像在噪音水平分别为5,10,15,20,25时,运行30次实验得到的平均时间。

表4 Lena图像在不同噪音水平下两种算法运行时间比较

表5 house图像在不同噪音水平下两种算法运行时间比较
实验分析:通过表4、5可以看出,在噪音水平σ =5,10,15,20,25对比K-SVD算法,本文算法的运行速度有了较大程度的提高,
5 结语
针对于K-SVD算法学习的字典有较高的相干性这一问题,本文提出了低字典相干性K-SVD算法。首先本文对K-SVD中的字典构造进行了改进,不在单一的选取以最大奇异值对应的特征向量去更新字典的列,而是对原有的模型增加刻画字典相干性的约束项,在字典更新阶段选取能使得模型极小化的特征向量去更新字典的列。这样改进的方法有效地降低了字典的相干性,由于相同的冗余度下,低相干性可加快稀疏编码速度,改善信号的重构性能,另外,低相干性有助于避免字典对训练样本的过拟合,即有效地避免字典出现过于相似的原子对。本文算法有效地降低了字典的相干性,使得图像去噪效果更好。
猜你喜欢
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
疯狂英语·新悦读(2019年10期)2019-12-13
现代装饰(2019年10期)2019-10-17
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
读者(2016年14期)2016-06-29
