
一种分布式函数依赖挖掘算法
2019-03-07 05:22葛锡聪叶飞跃刘琪张云猛
电脑知识与技术 2019年36期
葛锡聪 叶飞跃 刘琪 张云猛


摘要:针对分布在不同节点的数据的函数依赖挖掘问题进行了研究,提出了一种分布式函数依赖挖掘算法,该算法是以传统的函数依赖挖掘算法Tane算法为基础设计的。其基本思想是:首先,使用Tane算法挖掘出各个节点的函数依赖;然后,得到各个节点的公共函数依赖;最后,以公共函数依赖的左部公共属性值为散列值对数据进行重分布并对候选函数依赖进行验证,得到最终的函数依赖。该算法的实现过程中帮助解决的数据迁移量大和负载不均衡的问题,通过在真实数据上的对比分析验证了算法的可行性。
关键词:函数依赖;Tane算法;数据重分布
中图分类号:TP311
文獻标识码:A
文章编号:1009-3044(2019)36-0084-04
1概述
函数依赖作为关系理论中的一个重要概念和关系数据库的设计基础,在知识发现、语义分析、依赖推理和数据质量评估等领域有着广泛的应用[1,2]。假定R(U)是一个属性集U上的关系模式,X和Y都是U的子集。对于关系r(U)中的任意元组tl、t2,当tI[X]=t2[X],必有tl[Y]=t2[Y],则称X函数决定Y,或Y函数依赖X,可表示成:X~Y[3],例如在职工信息表中,工号可以决定职工姓名,“工号决定职工姓名”就是一个函数依赖。
目前,对于函数依赖挖掘的研究比较多。比较典型的有基于层次优先策略的Tane算法[4和Fun算法[5]、基于闭数据项集的FD_Mine[6]挖掘方法和基于深度优先策略的FastFDs[7]算法等。这些挖掘算法仅仅适用于对集中的数据进行分析,如果想要利用这些算法分析分布在多个节点的数据属性间的函数依赖关系,就需要将这些数据传输到一个节点进行挖掘。因为,在单个节点上挖掘出来的函数依赖不一定满足所有节点的整体数据。
例1.如图l所示,是一个分布式数据库的实例。
在上述分布式数据库中,图l(c)是将sl上的数据和s2上的数据传输到一个节点后得到的整体数据。如图l(a)(b)所示,实例r1和r2中均包含ID、A、B、C四个属性,而且从图l可以看出rl和r2上均存在函数依赖A→B、A→C和B→C,但是这些函数依赖在r上并不存在。所以,在单个节点上成立的函数依赖,在整体数据上不一定存在。由此可以看出,要准确挖掘出分布在多个节点的数据中的函数依赖关系,必然要对数据进行迁移。 通常情况下,容易想到一个基本的方法就是将所有节点的数据全部传输到一个执行节点上去,然后再挖掘该执行节点上的函数依赖,得到最终结果,但是该算法的会受到数据传输量和负载量的影响而降低效率[8-10]。针对传输量及负载量问题,提出了一种分布式函数依赖挖掘算法来帮助有效提高分布式环境下函数依赖的挖掘效率。
2相关工作
假定存在一个关系模式U,其中,I表示该关系模式上的一个实例,attr(U)表示该模式上的全体属性集,A、B、C、D表示该模式上的一个属性,用X、Y表示属性集合[11]。
定义l函数依赖[12]在关系模式U上成立的函数依赖通常用形如X→Y的表达式来表示,其中,X、Y∈U,且是两个属性的集合,对于实例I上的任意两个元组tl、t2,如果tl(X)=t2(X),则必然有tl(Y)=t2(Y),那么,在实例I上就存在Y函数依赖于X。并且,X是函数依赖的左部,Y是函数依赖的右部。
定义2最小函数依赖[13]设X∈U,A∈U,且X→A是实例I上的一个函数依赖,对X的任意真子集Xi,即Xi∈X,Xi→A都不成立,那么X→A就是实例I上的最小函数依赖。
定义3等价类[14]所谓等价类就是在属性集上取值相等的元组的集合。例如,图l(c)中,{1,4}就是属性A上的一个等价类。
定义4划分[15]在关系r上属性集X上所有等价类的集合就是r在X上的一个划分,并用∏x符号来表示该划分。其中[∏x]表示划分∏x中等价类的个数。
以图l(c)为例,分别基于属性集{A}、{B}和{C}将r划分成等价类兀∏[A]={{l,4},{2,5},{3,6}、∏{B}={{1,5},{2,4},{3,6})和∏{C}-{{1,6},{2,4},{3,5}},其中[∏{A}]=[{B}]=[∏x]=3.
引理l函数依赖X→A成立,当且仅当满足条件[∏x]=[nx∪A]。
3分布式函数依赖挖掘算法
和传统的函数依赖挖掘相比较,分布式函数依赖的挖掘难度更高,所挖掘出来的函数依赖既要满足局部数据又要满足全局数据,这就要求在分布式环境下进行函数依赖挖掘时,需要对相应数据进行传输。
3.1 GetFD集中式算法
GetFD算法是将分布式函数依赖挖掘问题转化成及集中式函数依赖挖掘问题去解决的,通过数据传输将分布在多个节点的数据集中起来使用传统函数依赖挖掘算法Tane进行挖掘。首先,统计各个节点的元组数,选择元组个数最多的节点作为运行节点,并将其他节点的数据传输到该运行节点,然后再用Tane函数依赖算法挖掘所有的函数依赖。具体的算法如下:
算法I:GetFD算法
输入:D=(D1,…,Dn),属性集合U
输出:挖掘的函数依赖集合Ω,
(l) for each i∈[l,n] do
(2) count(i)=[Di]/*其中Di表示节点i所包含的元组个数*/
(3) end for
(4) flnd max(count(i)
(5)找出元组最多的节点作为运行节点Sk
(6) for each j∈[l,n] do
(7)DK+=Di
(8)if-j==k.
(91 continue
(10) end for
(11) fl,=Discover(DK,U)/*这里使用经典的Tane算法挖掘函数依赖*/
(12) returnn
以上算法,是将所有分散的节点传输到一个节点后进行函数依赖挖掘的,在算法执行过程中,存在数据传输量大和负载不均衡的问题,会影响算法的执行效率。
3.2 MDFD分布式函数依赖挖掘算法
在文献[3]中提出了一种分布式大数据中函数依赖挖掘的框架FMFD,其算法思想是先通过发现各个节点的函数依赖来生成初始候选函数依赖集,在对各个节点的函数依赖进行剪枝,最后将各节点数据传输到一个中心节点进行检测得到最终的函数依赖集。该方法在进行终极函数依赖发现是需要将数据集中验证,这导致其效率比较低。
为了有效提高上述算法的执行效率,本文针对数据传输量大和负载不均衡这两个问题,提出了一种分布式函数依赖挖掘算法,算法的基本思想是:首先,使用Tane算法挖掘出各个节点的函数依赖;其次,挖掘出各个节点的公共函数依赖;然后,以函数依赖左部公共属性为散列值对各节点数据进行哈希重分布,如图1所示,以A为公共属性进行分析,A→B、A→C在(a)、(b)中成立,假定A→B、A→C为候选函数依赖集,对A的属性之进行哈希计算对数据进行重分布,将(1))中的元组4和6传输到(a)中,(a)中的元组2传输到(b)中;最后,在各个节点并行检测公共函数依赖,只要某一公共函数依赖在其中一个节点上被检测到不成立,则该函数依赖就不满足全局数据。上述实例并行检测,可以检测出A→B、A→C在全局环境下是不成立的。
算法2:MDFD算法
输入:D=(Dl,…,Dn)
输出:挖掘的函数依赖集合n
/*使用Tane算法挖掘每个节点的函数依赖并得出公共函数依赖n*/
(1)n=(),Ω=(),ni-()
(2) for each ie[l,n] do
(3) Ωi=Discover(Di)//这里使用Tane算法挖掘
(4) end for
(5)Ω=∩ni,Ωi
//以Ω的左部单个公共属性值为散列值进行数据重分布
(6) for each m∈[l,n] do
(7) for eac:h tEDi do
(8) ifhash(t)==m-l;
(9)Hmi←Hmi∪t;
(10) end for
(11) end for
(12) for each me[l,n] do
(13) ifi≠k
(14) send Himto Sk
(15) end for
//针对重分布数据检测公共函数依赖
(16) for each'p∈Ω
(17) check(ψ);
(18) if check(ψ)!=true
(19)Ω一=ψ
(20) else
(21)Ω+=ψ;
(22) Ω一=ψ;
(23) end for
(24) retumn
其中,驗证函数如下所示:
check()函数
输入:候选函数依赖ψ:X→Y
输出:true or false
(1) if (i//xi=i//xu yl)
(2) return true
(3) else
(4) return false
4实验
4.1实验环境
为了验证MDFD算法的可行性,在处理器为Intel(R) Core(TM)i7-4790 CPU 3.60GHz,内存:16.OGB的PC上进行了实验。操作系统为Ubuntu16.04.所有算法均由python实现。
4.2实验数据
该实验选取UCI标准数据集上的Adult数据集和与之相似的Census-income(KDD)数据集,其中,Adult数据集包含32561条元组和14个属性,Census-income(KDD)数据集包含299285条元组和40个属性。
4.3实验结果及分析
本文设计了3组实验,对本文中提出的GetFD算法和MDFD算法进行测试,在实验过程中,分别改变元组个数,节点个数以及属性个数,每一组实验都以运行4次后的实验结果的均值为最终结果。
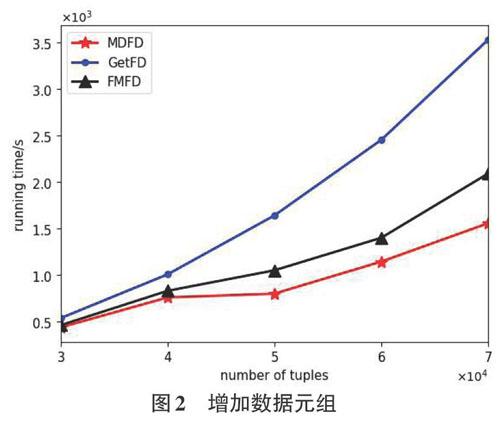
为验证当节点和属性个数保持不变时,增加元组数量对于MDFD算法、FMFD算法和GetFD算法执行效率的影响与对比,本文选取了Census-income(KDD)数据集进行实验,保证属性个数n=8,节点个数s=4,元组个数从30000条增加到70000条,每次增加个数为10000条,由于元组数量在增加,数据传输量与负载量也随之增加,这就使得三种算法的执行时间也会随之增加。从图2中很容易看出这一规律。与此同时,从图2也能看出,随着元组个数的增加,MDFD算法、FMFD算法和GetFD算法的执行时间差也逐渐增大,这说明MDFD算法的运行效率也逐渐高于FMFD算法和GetFD算法,而且元组个数越多,MDFD算法的优势更明显。
为验证当元组和属性个数保持不变时,增加节点数量对MDFD算法、FMFD算法和GetFD算法执行效率的影响,本文选取了Adult数据集进行实验,保证属性个数n=8,元组个数为20000条,节点个数从2个增加到6个,每次增加个数为1个,从图3中可以看出,两个算法随着节点增加运行时间的变化情况,随着节点个数的增加,GetFD算法的执行时间随着节点个数的增加而增加,而MDFD算法和FMFD算法的执行时间随着节点个数的增加而减少,这与理论预期结果相一致,在执行GetFD算法时,随着节点数的增加传输量增加,因此执行时间也不断增加,对于MDFD算法和FMFD算法,它们都是先对函数依赖进行并行挖掘,节点增加使得单个节点的负载量下降且负载均衡度得到提高,因而其算法的执行时间也将随之下降,但是FMFD算法是在初步挖掘之后,通过集中数据进行终极检测的,相对MDFD算法的并行检测,其并行度较低。所以,在节点增加时,MDFD算法的运行效率是明显优于FMFD算法和GetFD算法的。
为验证当元组和节点个数保持不变时,增加属性个数对于MDFD算法、FMFD算法和GetFD算法执行效率的影响与对比,本文选取了Adult数据集进行实验,保证节点个数s=4,元组个数为20000条,属性个数从4个增加到8个,每次增加个数为1个,由于随着属性个数的不断增加,单个节点的数据传输量与负载量也随之增加,这就使得三种算法的执行时间也会随之增加。从图4中很容易看出这一规律。与此同时,从图4也能看出,随着属性个数的增加,MDFD算法、FMFD算法和GetFD算法的执行时间差也逐渐增大,这说明MDFD算法的运行效率也逐渐高于FMFD算法和GetFD算法,而且属性个数越多,MDFD算法的优势更明显。
5结束语
随着分布式数据存储的广泛应用,传统的集中式函数依赖挖掘方法难以满足实际应用需要。当前,国内外相关研究人员正在对分布式环境下的函数依赖理论及应用进行深入研究。本文基于基本的函数依赖挖掘算法Tane算法,提出了一种分布式函数依赖挖掘算法MDFD算法,算法包含基础函数依赖挖掘、数据重分布和函数依赖验证等内容的实现,并通过相关实验对比验证了该算法的可行性。
参考文献:
[1]李建中,刘显敏.大数据的一个重要方面:数据可用性[J].计算机研究与发展,2013,50(6):1147-1162.
[2]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[3] Ye Feiyue,Liu Jixue,Qian Jin, et al.A framework for miningfunctional dependencies from large distributed databases[C]//Proc of 2010 Intemational Conference on Artificial Intelli-gence and Computational Intelligence.Alamitos,CA:IEEE,2010:109-113.
[4] Huhtala Y,Karkkainen J,Porkka P,et al.TANE:An efficientalgorithm for discovering functional and approximate depen-dencies[J].C omputer Joumal,1999,42(2):100-11 1.
[5]Novelli N,Cicchetti R.Fun: An efficient algorithm for miningfunctional and embedded dependencies[C]//Proc of the 8th In-ternational Conference of Database 'l'heory. New York:ACM,2001:189-203.
[6] Hong Yao, Howard J. Hamilton, Cory J. Butz. FD_Mine: Dis-covering Functional Dependencies in a Database Using Equiv-alences[C]. Proc of the 2002 IEEE International Conferenceon Data Mining. Japan:lDCM, 2002:9-12.
[7] Wyss C, Giannella C, Robertson E. FastFDs: A heuristicdriv-en, depth-first algorithm for mining functional dependenciesfrom relation instances[C]//Proc of the 3rd IntConf on DataWarehousing and Knowledge Discovery. New York, 2001:101-110.
[8] ShouzhongTu, Minlie Huang. Scalable Functional Dependen-cies Discovery from Big Data[C]//Proc of 2016 IEEE Secom'lInternational Conference on Multimedia Big Data (BigMM),2016:426-431.
[9] Jixue Liu, FeiyueYe,Jiuyong Li, et al. On discovery of' func-tional dependencies from data[J].Data & Knowledge Engineer-ing, 2013,86:146-159.
[10] Weibang Li, Zhanhuai Li, Qun Chen, Tao Jiang,HailongLiu:Discovering Functional dependencies in Vertically DistributedBig Data.WISE(2)2015:199-207.
[11] Jixue Liu, Jiuyong Li, Chengfei Liu, et al. Discover Depen-dencies from Data-A Review[C]. IEEE 'rransactions on Knowl-edge and Data Engineering,2012,4(2):251-264.
[12] H. Yao,H. J.Hamilton. Mining functional dependencies fromdata[J].Journal Data Mining and Knowledge Discovery,2008,16(2):197-219.
[13]王新,馬万青 . -种有效的最小函赖挖掘方法 [J].云南民族大学学报:自然科学报, 2005, 14(4) : 356-362.
[14] Abedjan Z, Schulze P, Naumann F. DFD: Efficient functionaldependency discovery[C]// Proc of the 23rd ACM InternationalConference on Information and Knowledge Management. NewYork: ACM, 2014:949-958.
[15] Shyue-Liang Wang, Ju-Wen Shen, 'rzung_Pei Hong.lncre-mental discovery of functional dependencies using partitions[C]//IFSA World Congress and 20th NAFIPS Intemational Con-ferenee:IEEE,2001:1322-1326.
收稿日期:2019-09-25
基金项目:国家自然科学基金项目(No.61472166);江苏省研究生科研与实践创新计划项目(SJCX18_1021)
作者简介:葛锡聪(1995-),女,江苏南通人,硕士研究生,主要研究方向为数据挖掘、智能装备运行与管理;叶飞跃(1960-),男,浙江
东阳人,教授,博士,主要研究方向为数据挖掘、人工智能;刘琪(1993-),女,江苏南通人,硕士研究生,主要研究方向为数据挖掘、智能装备运行与管理;张云猛(1996-),男,江苏盐城人,硕士研究生,主要研究方向为数据挖掘、机电产品检测与智能控制。
