
一种组合式伪随机数发生器的构造
2019-03-13 05:14韩露露来齐齐曹艳艳
小型微型计算机系统 2019年3期
韩露露,杨 波,来齐齐,曹艳艳
(陕西师范大学 计算机科学学院,西安 710119) (中国科学院信息工程研究所 信息安全国家重点实验室,北京 100093)
1 引 言
随机数发生器分为真随机数发生器和伪随机数发生器,它们均可采用软件和硬件来实现.然而,真随机数发生器[1]由于多采用价格高昂的硬件才可以实现且存在对熵源的要求高和产生随机数的效率低等缺点,因此伪随机数发生器一直以来是研究的热点.
伪随机序列(Pseudorandom Sequence)在计算机仿真学、信息加密、会话密钥的产生、协议认证等诸多领域都有广泛的应用.尤其是在密码学领域,要求伪随机数发生器能够产生与真随机序列在计算上不可区分的序列[2],伪随机数发生器是实现对称加密、非对称加密、数字签名、数据完整性等的技术基础.
伪随机数发生器的构造方法有很多.例如,可以基于分组密码、序列密码、混沌、数论等方法构造伪随机数发生器[3].然而,基于组合式的伪随机数发生器具备构造简单和对已有的伪随机数发生器统计特性改善明显的特点.文献[4]通过对组合法的深入研究得出结论:几个独立且近似均匀的随机序列能线性组合成一个接近U(0,1)分布的随机序列.文献[5]对组合的线性同余发生器的不可预测性进行了研究.
LCG[6]算法和RC4[7]算法因其高效性,近年来人们不断地对其进行研究和改进.Chefranov[8]在06年提出一种改善RC4算法周期的方法.Shen[9]在09年通过对线性同余发生器作位操作来达到改善随机序列统计品质的目的.Rivest[10]通过对RC4算法的深入分析在14年设计了一种类似RC算法的流密码Spritz.然而,关于RC4算法的安全性一直以来都备受争议[11,12].2015年IETF(Internet Engineering Task Force)声称RC4算法已经不再安全[13].
鉴于RC4算法高效的特点和专门设计一款伪随机数发生器的困难性.本文采用组合法以LCG算法和RC4算法为数据的生成源,以安全的密码学Hash函数[14,15]为数据处理算法设计了一个具备一定密码学强度的组合式伪随机数发生器.该组合式伪随机数发生器每产生一个512比特的随机数后,就会对RC4算法当前的内部状态进行置换.这种频繁更新RC4内部状态的做法可提高其抗密码分析能力.同时,密码学Hash函数的单向性保证了该伪随机数发生器产生的序列具备不可预测性[16,17].
2 预备知识
2.1 基本概念
至今,随机数都没有一个统一的定义,数学上的定义和概率论相关,计算复杂性理论则用描述该序列的程序长度来定义.在密码学中,则结合统计特性和密码攻击来描述随机数,按照性质随机数可以分为随机性、不可预测性和不可重现性.
2.1.1 随机性
常用以下两个准则描述序列的随机性(Randomness):
1)均匀分布:序列中每一个数列出现的频率应该相等或近似相等.
2)独立性:序列中任意一个数列都不能由其他数推出.
2.1.2 不可预测性
已知一个序列的任意前缀序列,如果没有有效的算法能以不可忽略的优势猜测到下一个数,则称该序列具备不可预测性[18](Unpredictability).
2.1.3 不可重现性
如果除了将随机数列本身保存下来以外,没有其他方法能够重现数列,则称该随机数列具备不可重现性.
2.1.4 伪随机数发生器
伪随机数发生器是一种确定性算法,给它一个短的真随机输入,产生一个更长的、和真随机序列非常接近的随机序列.称其输入为种子(Seed),输出为伪随机序列[3].
2.2 组合式随机数发生器理论
组合法是指将两个或者两个以上独立的伪随机数发生器按照某种方式组合起来构成一个新的伪随机数发生器,以期望产生周期更长、统计性能更优的伪随机序列.这种发生器的组合方式很多,大体可以分为两类.
第一类是1965年由Maclaren和Marsaglia共同提出的,先用一个伪随机数发生器生成一组伪随机序列,然后通过使用第二个伪随机数发生器产生的随机数对第一个伪随机序列进行扰乱并重新排序,进而得到一个新的序列,其具体算法操作步骤为:
1)首先,用第一个发生器产生k个随机数,并将这k个数顺序地存放在矢量T={t1,t2,…,tk}中,同时置i=1;
2)用第2个发生器产生一个随机整数j,j必须满足j∈[1,k];
3)令Xi=tj,然后再用第一个发生器生成下一个随机数y,令tj=y,并置i=i+1;
4)重复2)-3),即可得到组合的发生器生成的一个新的随机数序列{Xi} .
第二类是首先每个伪随机数发生器分别产生一个随机序列,然后以此为基础对两个序列的元素进行运算(主要包括"+"、"-"以及"XOR"运算组合),从而产生新的随机序列.
3 本方案的设计说明
3.1 方案的整体描述
3.1.1 流程图主要模块的功能说明
下面对图1中各模块的主要功能进行说明:
1)RC4模块(如图1中①所标识):该模块从外部获得一个种子后,每对其调用一次就会产生一个字节的数据.

图1 方案的整体描述Fig.1 Overall description of the scheme
2)SHA-3 512模块(如图1中②所标识):该模块把RC4算法产生的字节流当做SHA-3 512的输入,并将其产生的散列值作为输出.这个过程每被执行一次可以产生64个字节的数据,则对其执行C次总共可以产生C×64字节的数据.
3)LCG模块(如图1中③所标识):该模块以RC4算法产生的字节流为参数对LCG算法的参数进行更新(在本方案中,更新参数的目的是使得模256的LCG算法达到满周期[19]),参数更新后的LCG算法每被调用一次会产生一个字节的数据,对其连续调用64次以产生64个字节的数据.这个过程被执行C次,总共可以产生C×64字节的数据.
3.1.2 流程图的执行过程说明
该PRNG输入输出规格说明:
1)输入:种子的输入长度范围32(字节)~256(字节).
2)输出:该算法每被调用一次可产生64字节的随机数.
流程图1的执行过程:
1)首先,从外部获得一个种子并将该种子赋给RC4算法.
2)调用RC4算法并将其产生的字节流分别作为LCG模块和SHA-3 512模块的输入,经过一系列的运算后,这两个模块分别输出C×64字节的数据(如图1中②和③所标识),接着将两个模块产生的数据按位进行异或得到C×64字节的数据(如图1中④所标识).
3)用SHA-3 512求上一步最终得到的C×64字节数据的散列值,并将该散列值作为本轮该PRNG算法产生的随机数并输出.
4)分别取第2步LCG模块和SHA-3 512模块输出的第Q个64字节的数据,并将其转换成大整数进行相加(如图1中⑤所标识),同时将结果累加到PRNG的内部计数器Couter(如图1中⑥所标识)上,然后用SHA-3 512求计数器Counter的散列值.然后,用求得的散列值对RC4算法当前的内部状态进行置换.
5)重复第2步至第4步,直到得到所需数量的随机数.
3.1.3 方案用到的组合式思想说明
1)由3.1可知,LCG模块的输出是通过调用C个参数不同的LCG算法获得,将这C组的输出组合在一起可以改善单个LCG算法周期短的缺点.
2)在图1中,将LCG模块输出的C×64字节的数据和SHA-3 512模块输出的C×64字节的数据进行异或,该操作不仅起到改善单个C×64字节统计特性的作用,还增加了整个PRNG的抗密码分析能力.
3)在图1中,该PRNG在产生第2个以及以后的第N个随机数之前,首先会利用SHA-3 512求得的PRNG内部计数器Counter的散列值,然后利用该散列值对RC4算法产生上一个随机数时所处的内部状态进行置换.由计数器Counter的值不断增加和SHA-3 512的抗碰撞性知,每次用于置换RC4算法内部状态的散列值都是不一样的.因此,该操作可以增加RC4算法的周期.
由第2章组合式随机数发生器的理论可以得出,本方案不仅增加了输出序列的周期,而且还增加了RC4算法的周期,使得整个PRNG算法具备更强的抗密码分析能力.
3.2 方案局部的详细执行过程
流程图2的执行顺序及各模块的详细操作说明.
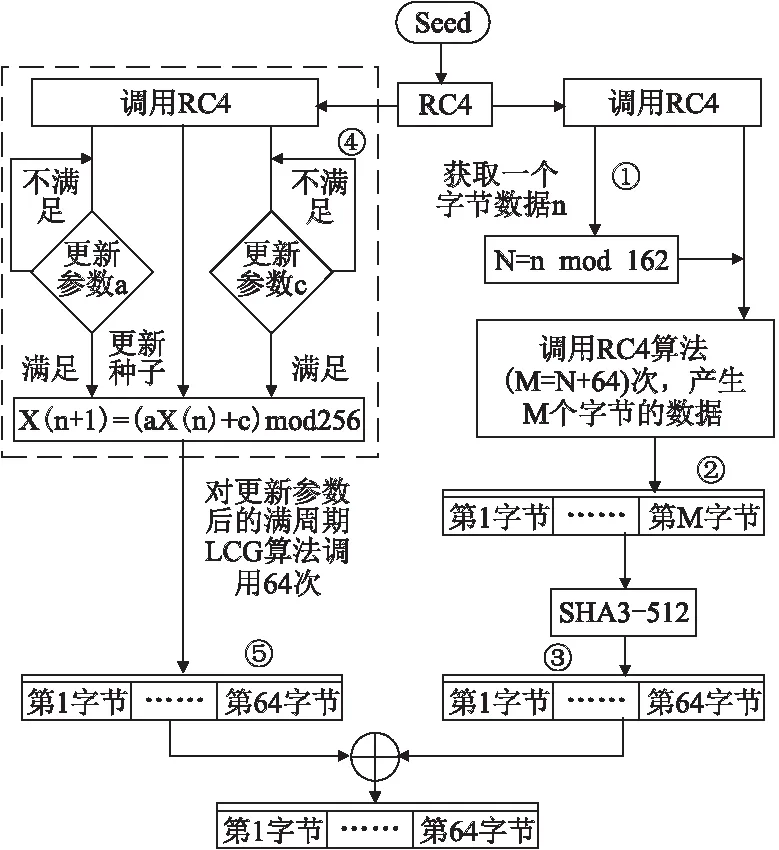
图2 本方案的局部结构图
Fig.2 Local structure of the scheme
1)从外部获取一个随机的种子(Seed)并将此随机数作为RC4算法的种子.
2)调用RC4算法(如图2中①所标识)产生一个字节的随机数(用n表示),并计算N=64+(nmod162).
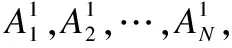

5)调用RC4算法若干次以使本方案用到的线性同余发生器(Xn+1=(aXn+c)mod256)达到满周期.具体的参数更新过程如下(如图2中④所标识):

② 同更新参数a的值一样.调用RC4算法产生一个字节的随机数c1,判断c1是否满足gcd(c1,256)=1(gcd(a,b)表示a和b的最大公约数),如果满足,则将c1作为该线性同余发生器的参数c的值(c=c1);如果不满足,则继续调用RC4算法产生一个随机数ci,直到ci满足gcd(ci,256)=1,该步骤停止,并将ci作为该线性同余发生器参数c的值(c=c1).
③ 因为RC4算法产生的任何数都可以作为该线性同余发生器的种子,所以只需要再调用一次RC4算法产生一个字节的随机数X,并将X作为该线性同余发生器的种子(Xn=X).

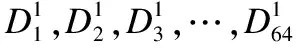
3.3 方案整体的详细执行过程
下面对方案的整体流程图3的执行过程进行说明.
1)从外部获取一个随机的种子(Seed)并将此随机数作为RC4算法的种子,同时把该种子的前16个字节作为本方案所设计的PRNG内部计数器的初值(即Counter=Seed16,该操作仅被执行一次).
2)调用一次RC4算法产生一个字节的数据(用M表示),计算C=H+(MmodP) (如图3中①所标识).其中C表示:本轮产生一个伪随机数所用到的线性同余算法(LCG)个数.其中,H表示每生成一个随机数最少用到的LCG个数,P表示整个PRNG算法在生成随机数的过程中使用的LCG的变化幅度,对于生成的任意一个随机数其用到的LCG个数变化范围为:H至(H+P-1).H和P的具体取值由实际需要的安全强度和效率决定.
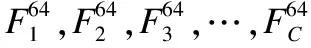


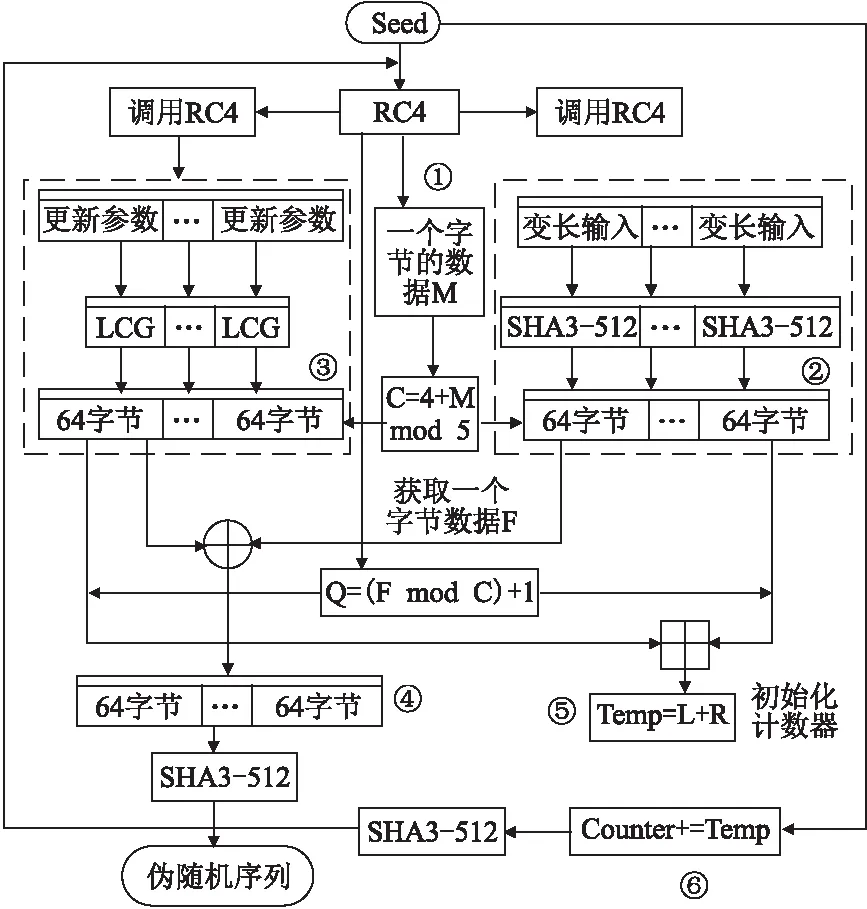
图3 方案整体的详细描述Fig.3 Overall detailed description of the scheme

7)调用RC4算法产生一个字节的数据(用F表示),计算Q=(FmodC)+1.将第3步和第4步得到的C×64字节数据的第Q个64字节的数据分别转化成一个大的整数,分别表示为R和L,并计算Temp=L+R(如图3中⑤所标识).

9)重复第 2到第 8步,直到得到所需数量的随机数.
4 安全性
4.1 不可预测性
应用于密码学的随机数发生器必须具备不可预测性[20,21].对于伪随机数发生器而言,在种子未知的情况下,即使已知序列中任意多个前缀都不能够猜测到序列中的下一个随机数,也即已经产生的随机数和序列的下一个随机数之间没有明显的关系.这个性质称为前向不可预测性.同时,还应该保证从任何已经产生的序列中不能推导出伪随机数发生器的种子,也即已经产生的随机数和种子之间没有明显的关系.这个性质叫做后向不可预测性.下面分别从前向不可预测性和后向不可预测性的角度对本文设计的伪随机数发生器的安全性进行分析.
4.1.1 前向不可预测性



图4 先后产生的随机数的关系
Fig.4 Relation of random numbers generated one after another
从图1可以看出,要想得到第n个随机数和第(n+1)个随机数的关系,需要得到产生下一个随机数的Seedn(其作用是在产生下一个随机数之前对RC4当前的内部状态进行置换).那么就需要得到计数器Counter当前的值,也即需要得到相应的R和L的值.继续向前推导,需要猜测到方案流程图3本轮生成的C×64字节的数据.

图5 求逆的困难性Fig.5 Difficulty of inversion
若上述工作全部完成,接下来猜测将两个C×64字节的数据的第几个64字节的数据转化成了大整数.那么就可以得到Tempn.然而,Counter=Seed16+Temp1+Temp2+…+Tempn,其中Seed16表示该PRNG从外部获得的种子的前16个字节的数据.因此,需要对变长输入的SHA-3 512成功求逆n次,对异或的结果求逆n次,还要成功猜测n次转化成大整数R和L的数据是C×64字节数据的第几个64字节的数据,最后,还要猜测到计数器的初始值(外部输入的种子的前16个字节).这是不可能的.因此,本方案具备前向不可预测性.
4.1.2 后向不可预测性

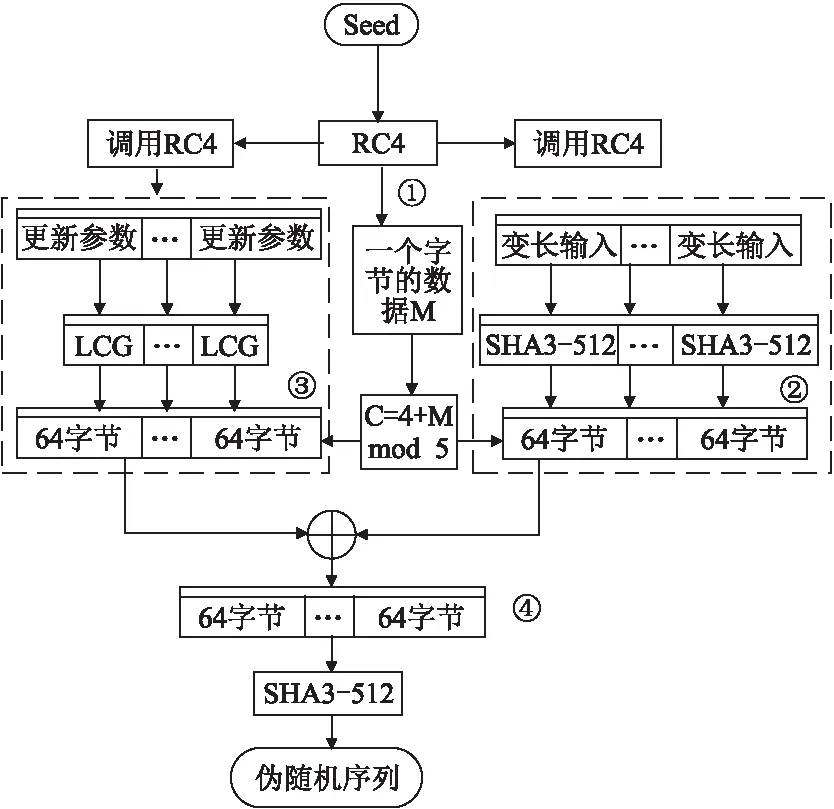
图6 PRNG产生的随机数与种子之间的关系Fig.6 Relationship between random numbers generated by PRNG and seeds
5 方案实验
5.1 实验平台
本方案的实验环境主要参数如表1所示.在集成开发环境Visual studio 2012中用C/C++对本方案进行代码实现,在代码实现过程中用到密码学库CryptoPP1.

表1 实验环境主要参数Table 1 Main parameters of experimental environment
5.2 实验数据
实验的主要目的是测试本方案设计的PRNG能否通过NIST的随机性测试标准.同时,测试了方案中使用的LCG个数对产生随机数效率的影响.表2中列举了该PRNG算法使用的LCG个数的变化范围为4(个)至8(个)时,使用不同位数的种子产生不同数量的随机比特并将其以二进制格式写入磁盘中的文件花费的时间.表3列举了该PRNG算法使用的LCG个数的变化范围为2(个)至4(个)时,使用不同位数的种子产生不同数量的随机比特并将其以二进制格式写入磁盘中的文件花费的时间.

表2 使用的LCG个数的变化范围为:4(个)~8(个)Table 2 Number of used LCG varies from 4 (units) to 8 (units)
表3 使用的LCG个数的变化范围为:2(个)~4(个)
Table 3 Number of used LCG varies from 2 (units) to 4(units)

比特数量种子位数 100000000(bits)1000000000(bits)10000000000(bits)256位种子1.286(mins)12.849(mins)126.012(mins)512位种子1.291(mins)12.912(mins)132.532(mins)1024位种子1.287(mins)13.245(mins)128.418(mins)
用NIST提供的SP800-22测试包对上述实验产生的数据进行统计测试.该测试包主要包括15个测试项,有些测试项被分成了多个子测试项,每个测试项的结果中均有p-value值和通过率Proportion两个指标.对于P-value值,若该值大于规定的显著水平α,则说明序列是随机的,一般α的取值为[0.001,0.01];对于通过率的值Proportion,若该值在置信区间内,表示序列通过该项检测,反之则未通过.设β是被测序列的组数,则置信区间为:
设置显著性水平α=0.01,其他选项采用默认.用NIST随机性测试方法对本方案设计的PRNG算法生成的β组1M bits的序列进行测试.在使用256位种子、LCG变化范围为4(个)~8(个)情况下,分别取分组长度β=1000、β=3000、β=5000的数据进行测试,结果显示该PRNG算法能够很好地通过测试.表4列举了β=1000时,各项测试结果对应的P-value值和Proportion值.其中,带*的测试项目表示该项含有多个子项.对于含有多个子项的项,表中分别对列出了其Proportion值最大的子项和最小的子项及相应的P-value值.
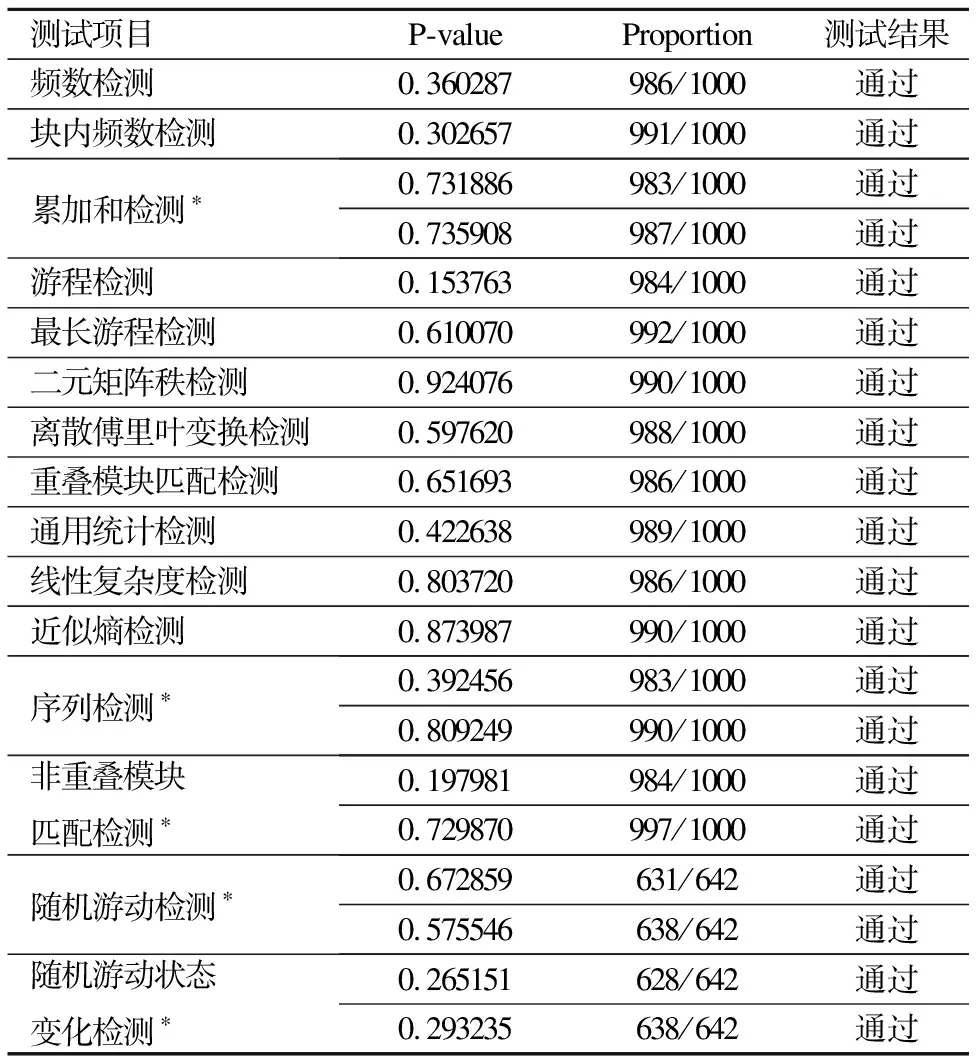
表4 NIST SP800-22 测试结果Table 4 Test results of NIST SP800-22
5.3 实验结论
从表2和表3的实验结果可以得到,该PRNG在使用相同的种子产生100000000(bits)、1000000000(bits)、10000000000(bits)的随机数平均花费的时间近似相等,所以可以认为方案中用到的CryptoPP中构造的Integer类涉及的大整数转换和加法运算都可以高效地执行.
对比表2和表3的实验结果可以得到,方案中使用的LCG算法个数影响着整个PRNG的效率.因此,在使用该PRNG算法时可以根据具体的安全性强度和效率要求选择合适个数的LCG.
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
商品与质量(2019年34期)2019-11-29
儿童时代·幸福宝宝(2019年9期)2019-10-28
销售与市场(营销版)(2019年6期)2019-06-21
计算机系统应用(2019年3期)2019-03-11
莫愁·家教与成才(2017年7期)2017-07-11
中国信息化·学术版(2013年1期)2013-05-28
恋爱婚姻家庭·养生版(2010年8期)2010-05-14
智能计算机与应用(2007年4期)2007-08-25
