
基于GBRT 的交通流量预测算法研究
2019-04-12 07:01周鑫
现代计算机 2019年7期
周鑫
(四川大学计算机学院,成都610065)
0 引言
随着智能交通系统的发展完善,人们的出行方式得到了极大的改善,对于交通工具的选择也更加的多样化,出租车和网约车对于交通系统更是不可或缺的一部分。而在网约车领域,每天都有成千上万个订单,已经积累了大量的数据,为了给人们的出行提供更舒适的服务和体验,如何对这些数据进行合理地分析建模,成为了城市交通中流量预测的一个很重要的研究课题。
交通领域的流量预测主要包括区域的人流量预测、道路车流量预测、车速预测、共享单车的借用归还量预测[1]等。而在网约车领域,对于给定起始地和目的地的订单量预测基本处于空白阶段。随着网约车在我国合法化之后,网约车司机也越来越多。但是,在一些地区,仍然存在着“打车难”的问题,即:迟迟没有司机接单,打不到车。由于网约车积累了大量的订单数据,对这些数据进行相应的分析建模,我们可以预测在未来一段时间内的订单量需求,来为车辆调度提供支持,以期望在一定程度上缓解“打车难”的问题。
交通领域的流量预测是一个极具挑战性的问题,因为预测结果受到各种因素的影响,如:时间、周末、节假日、天气以及不同区域之间的地理关系等。在传统的流量预测方法有基于时间序列的差分整合滑动平均自回归模型(ARIMA)[2]及其相应的改进模型、卡尔曼滤波、支持向量回归(SVR)[3]等。但是这些算法都无法充分整合天气、区域的兴趣点(POI)、交通拥堵信息等数据进行预测。本文采用梯度提升回归树(GBRT)[4]融合多种数据源的影响因子进行流量预测。
1 算法
1.1 提升与梯度提升
传统的提升(Boost)就是在算法刚开始进行计算的时候,为每个样本都赋值一样的权重1/n,每一次训练得到一个弱学习器,使用这个弱学习器对样本进行估计时会存在差异。所以在每一步完成之后,会对样本的权重进行重新分配,具体是增加错分类样本点的权重,使得错分类的样本会受到重点关注。在通过N 次迭代之后,得到N 个弱学习器,对于准确率高的学习器赋予较高的权重,准确率低的样本赋予较低的权重,通过加权的方式将这N 个弱学习器组合起来,得到一个最终的模型就是提升。
而梯度提升(Gradient Boost)与传统的提升的差别在于:梯度提升每一步计算的目的在于减少上一步计算的残差。为了能够加快残差的减少,在残差减少的梯度方向上建立一个新的模型。因此,在梯度提升中,每个新模型建立在损失函数的梯度下降方向。
1.2 梯度提升回归树
梯度提升回归树(GBRT)的基本思想就是计算一系列简单的回归树,其中每一棵树的建立是为了预测之前的树的残差,这个残差就是预测值与真实值之间的差值。例如:在预测一个人的年龄问题上,样本用户的真实年龄为20 岁,但是使用第一棵树得到的预测结果是18 岁,那么残差就是2 岁。因此在使用第二棵树进行学习时,我们将年龄设置为2 岁进行学习,如果学习后得到的结果就是2 岁,那么将两棵树的结果进行累加,得到的值就是预测值,误差为0。
(2)对于m=1,2,…,M:
①对i=1,2,…,N 计算负梯度值
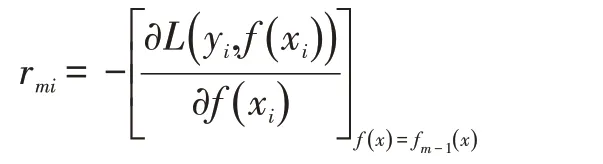
②对rmi拟合一个回归树,得到第m 棵树的叶节点区域Rmj,j=1,2,…,J
③对于j=1,2,…,J,重新计算每个区域的输出值
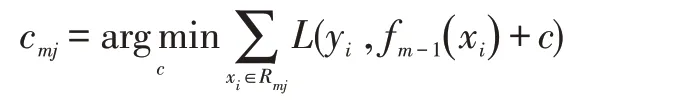
2 对比模型
历史平均(HA):每一个起始地-目的地对在该时间片上的历史流量的平均值,此处对历史平均分为工作日和周末两种情况。因为工作日和周末的流量变化趋势是不同的,工作日的流量早晚高峰明显,而周末的流量趋势更加平稳。所以分别计算出工作日和周末的历史平均流量。
差分整合滑动平均自回归模型(ARIMA):ARIMA是时间序列预测中一种经典的模型。通常有三个参数p、d、q,AR 是“自回归”,p 为自回归项数;MA 为“滑动平均”,q 为滑动平均项数,d 是差分次数,其含义是为了使序列成为平稳序列所做的差分阶数。
支持向量回归(SVR):SVR 是支持向量机(SVM)的一个很重要的分支。SVR 回归,就是找到一个回归平面,使得所有样本数据到该平面的距离最近。SVR的性能与核函数的选择有很大关系,常用的核函数是RBF。
3 数据和实验
实验数据来自于2016 年滴滴比赛Di-Tech 2016数据。该数据包括2016 年2 月23 日至3 月17 日共计24 天的订单数据、天气数据、区域的POI 信息数据、交通拥堵情况数据。对数据进行预处理,选取出行成功的订单并统计起始地和目的地,然后按照30 分钟为一个时间片进行划分,得到每个时间片上由区域i(1…58)到区域j(1…58)的订单量。另外,由于工作日、周末、节假日的流量变化情况都不相同,因此提取出是否是周末,是否是节假日等特征。另外,天气情况包括晴天、多云、阴天、下雨,所以对天气情况进行one-hot 编码,而由于温度和PM2.5 的数据是连续性数据,所以采取Min-Max 归一化的方式,将结果归一化到[0,1]。对于交通拥堵数据和POI 数据,进行统计求和,得到每一个交通拥堵等级对应的路段数和每一类POI 的数量。对数据进行特征工程之后,每条训练数据,均包含86个特征。对实验采取离线实验方法,以2 月23 日至3月10 日共计17 天的数据为训练数据,3 月11 日至3月17 日的数据为测试数据。
首先,对训练集数据进行分析,可以发现,历史数据中共存在2722 个起始地-目的地对,统计不同起始地-目的地对在训练集中的总订单量,以订单量为横坐标,小于该值的起始地-目的地对占总对数的比例为纵坐标,得到图1。
从图1 中可以看出,大约80%的起始地-目的地对的订单量均小于等于418,也就是说,平均每个时间片还不足一个订单,所以这类起始地-目的地对没有太大预测价值,直接使用历史平均就行。对于另外的20%的起始地-目的地对,采取GBRT 算法来预测。以平均绝对误差(MAE)均方根误差(RMSE)为评价指标,公式分别如下:根据以上评价指标,实验对比结果如图2。
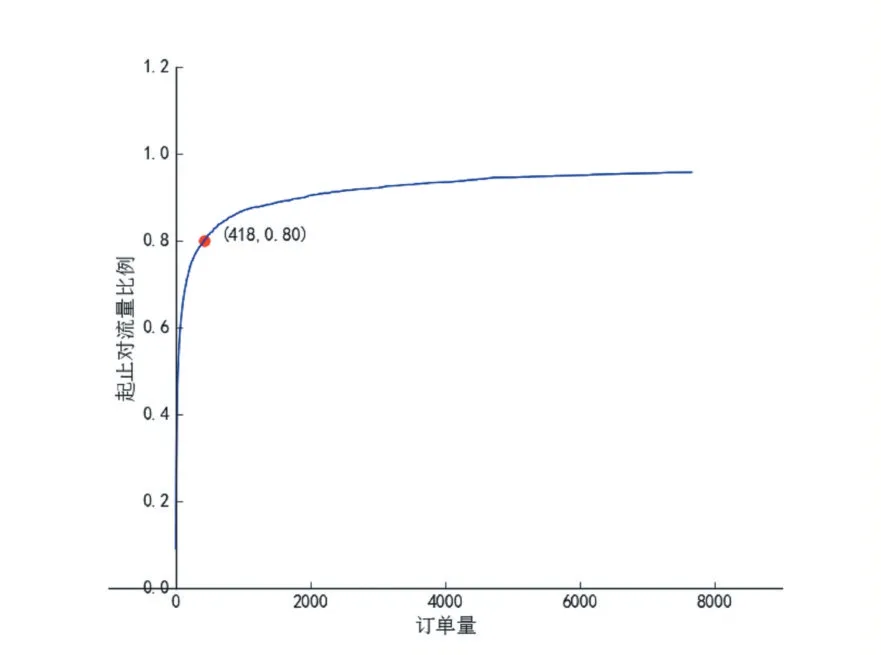
图1

图2

由图可知,在MAE 和RMSE 评价指标下,使用GBRT 融合各种数据源的特征得到的预测结果相对于另外几种算法都是较好的。
4 结语
本文提出了基于GBRT 的交通流量预测算法,使用比赛公开数据集进行了实验对比,根据MAE 和RMSE 评价指标的结果,证明该模型可以融合多源数据来进行流量预测。同时,该模型具有一定的扩展性,不仅可以用于交通领域的流量预测,也可以用于股票预测、房价预测等。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
悦游 Condé Nast Traveler(2022年2期)2022-02-18
小天使·三年级语数英综合(2021年4期)2021-06-15
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
