
海量数据文件异常并行检测技术设计与实现
2019-04-28 05:58姜少彬伍江江周正
电子技术与软件工程 2019年3期
文/姜少彬 伍江江 周正
大数据分析处理技术从海量数据中发现隐含的知识。但数据获取的方式、速度、数据格式以及人为的误操作等都会影响数据质量,进而给大数据分析带来麻烦。大数据处理流程中利用数据清洗来解决数据质量问题。数据清洗通过对数据进行重新审查和校验,删除重复信息、非法格式文件以及纠正存在的错误,并提供数据一致性,从而保证数据质量,服务大数据分析。
遥感卫星系统在运行过程中,大量的遥感数据7*24小时不间断下传,文件系统中存储了海量的遥感数据。由于卫星器件问题、传输问题和地面人为误操作等都会造成一些数据文件的错误。如不及时对非法数据文件进行检测清理,将会影响后续的数据分析处理业务。由于遥感数据体量巨大,且增长速度快,因此需要以更快的速度对数据进行检测,在规定的时间内完成对数据的清洗。
本文设计并实现了一种海量数据文件异常并行检测技术,利用服务器集群对海量数据文件进行异常检测,并在服务器执行过程中采用多线程技术,从而实现服务器和线程两级的并行处理,取得了较高的扫描检测效率。
1 相关工作
通过数据分析获取知识和解决问题是科学研究和工程实践的重要手段,计算机的出现使数据分析计算的效率实现了质的飞跃。随着科技发展,科研和工业上遇到的问题愈加复杂庞大,要分析的数据量也在不断增加,单机的处理速度已经无法满足要求。1993年,集群技术逐渐得到重视和发展。集群将若干台计算机(或工作站、服务器等)通过网络连接,多机协同工作实现并行处理,能够同时具备高性能和高可用性。1997年战胜国际象棋大师卡斯帕罗夫的“深蓝”计算机就是由多台运行AIX的IBMSP2计算机组成的集群,每秒可以计算2亿步。2000年,新墨西哥大学的Los Lobos[1]集群实际上是256台IBM的Netfinity个人多服务器组成的“超级集群”。它以低成本提供超级计算机水平的功能,每秒钟的处理可达到3750亿次。该速度在当时前500台超级计算机中排名第24 。
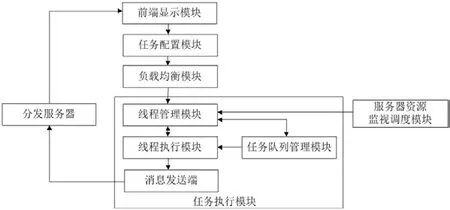
图1:系统模块组成图
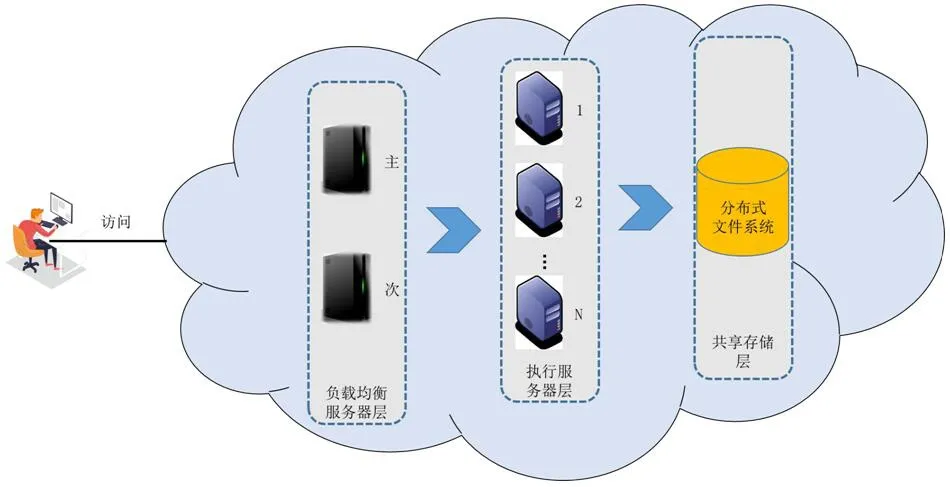
图2:服务器集群结构图
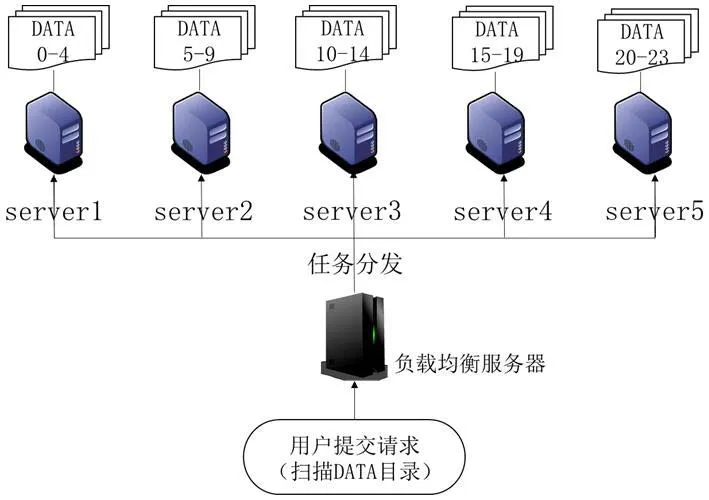
图3:基于负载均衡的任务分发
进入21世纪,现代工业高速发展,特别是网络信息产业的繁荣,使得数据呈现爆炸式的增长。海量数据的处理需求催生了大数据处理技术。大数据处理的基本思想是分治,采用分布式并行计算,将大数据问题分解成规模较小的子问题进行求解,然后合并子问题的解得到最终解[2],在处理速度上取得了质的飞跃。2004年Google 公司提出的 MapReduce[3]是一种专门处理大数据的编程模型和实现框架,具有简单、高效、易伸缩以及高容错性等特点。MapReduce技术本质是一种并行计算,所以也采用集群作为硬件环境。基于MapReduce框架的Hadoop大数据处理平台可以利用普通计算机搭建集群,为超大数据集提供存储和处理能力,适合大规模离线数据的批处理。缺点是小文件处理性能较差,且易造成负载不均衡。Spark[4]是轻量的、基于内存计算的开源集群计算平台。Spark通过完善内存计算和处理优化机制加快批处理工作负载的运行速度,批处理速度比MapReduce快10倍,内存中分析速度快100倍。
由于集群在提供高效计算的同时具有较高的性价比,且可以保证计算系统的高可用,并行计算对集群有越来越强的依赖[5],所以本文决定采用集群作为海量数据文件异常检测的硬件平台,并利用多线程技术实现集群和线程两级的并行处理。
2 海量数据文件异常并行检测技术设计
2.1 设计目标
2.1.1 高效检测能力
遥感卫星系统24小时连续运行,海量探测数据不间断的下传,存储在分布式文件系统中。数据文件异常检测服务需要能够快速检测出海量数据文件中的非法文件,并及时清除,保证数据分析处理业务对数据的访问。
2.1.2 智能检测能力
系统应允许用户选择文件目录和检测时间,设置定时扫描检测任务,从而实现海量数据文件异常检测的智能化。
2.1.3 系统高可用
星上数据持续下传,文件系统中不断有新的文件存入,数据文件异常检测服务势必也要长时间运行。服务器长期运行下会有一定的故障概率,如何避免服务器宕机造成服务中断是设计中需要解决的问题。
2.2 设计思路
系统拟采用服务器集群来达到检测所需的性能,在服务器执行扫描检测任务过程中运用多线程技术实现并行处理进一步提高检测效率。系统由负载均衡服务器和执行服务器集群组成,其主要功能模块构成如图1所示。
(1)通过任务配置模块,实施检测策略的灵活配置,能够从文件名、文件格式、文件内容等不同角度对异常文件进行检测,并可对检测时间、检测目录等信息灵活选择,从而实现智能化检测。

表1:任务执行时间表
(2)通过运行在负载均衡服务器上的负载均衡模块将任务划分后分发到多台执行服务器上并行执行,从而提高检测效率,并且集群可以根据需求灵活扩展系统能力。
(3)在执行服务器上设计实现服务器资源监控调度模块,监视服务器资源动态使用情况,根据业务繁忙程度为检测服务分配服务器资源,从而在充分利用资源提高检测效率的同时保证服务器上其他业务的正常运行。
(4)任务执行模块运行在执行服务器上。其中线程管理子模块负责开设线程池,管理多个线程并行执行扫描检测任务,进一步提高检测效率;任务队列管理子模块负责对任务队列进行组织管理;线程执行模块中各线程从任务队列中提取任务进行执行。
(5)各服务器任务完成后通过集成在服务器上的消息发送端将结果发送至分发服务器,由分发服务器直接推送给前端进行显示。
(6)系统内服务器实施热备和冗余设计,当某台服务器宕机后,冗余节点能够在短时间内接手任务,保证服务持续进行,从而实现系统的高可用。
3 关键技术实现
服务器集群在工作过程中,负载均衡模块运行负载均衡策略完成集群之间任务的快速分发;服务器资源监视调度模块为扫描检测任务分配一定的系统资源用于执行;任务执行模块依托多核处理器为任务进程开设线程池,管理和运行多个线程,实现线程级的并行处理;各服务器检测结果最终通过消息发送端发送至分发服务器,由分发服务器推送至前端显示。
3.1 集群的构建和功能实现
3.1.1 服务器集群构建
系统呈三层结构,主要包括:负载均衡服务器、任务执行服务器集群和分布式共享文件系统。如图2所示。
负载均衡服务器是系统的对外端口。用户提交的任务请求通过负载均衡服务器分发给执行服务器。执行服务器根据分配的任务从分布式文件系统中提取数据进行处理,并将处理结果写入数据库。
为保证系统的高可用,负载均衡服务器采用主从式双机热备,主服务器负责负载均衡和任务分发。主服务器出现故障停机,从服务器可在短时间内接管服务,保证系统的正常运行。为执行服务器设置冗余节点,当监测到一台执行服务器出现故障,系统会启用冗余节点接管该服务器的任务继续执行,保证系统的高可用。各执行服务器独立完成分配的任务,执行服务器之间不进行通信,从而降低依赖和耦合,便于集群的扩展。
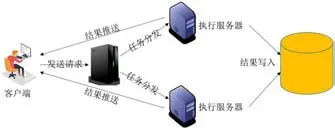
图4:检测结果推送
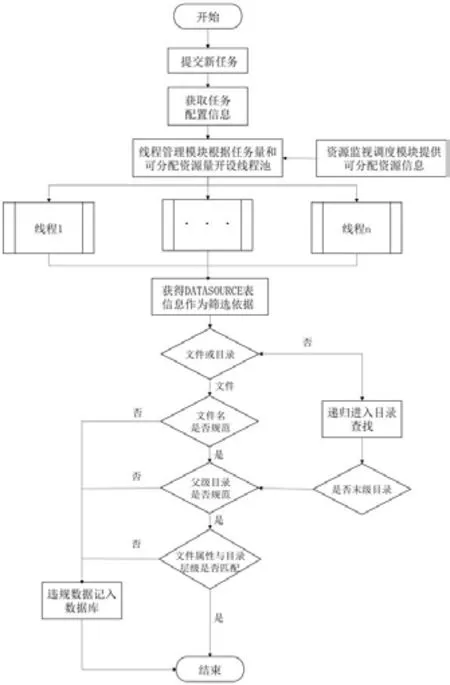
图5:海量数据文件异常并行检测执行流程图
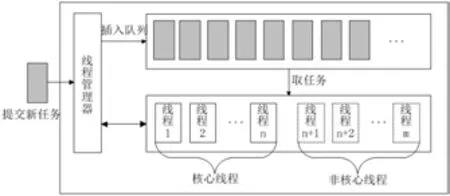
图6:线程池结构图
3.1.2 基于负载均衡的任务分发
负载均衡模块运行基于任务量和服务器负载状态的负载均衡策略,防止出现服务器超载或饥饿现象,提高集群资源利用率,最大限度地发挥集群处理能力。
执行服务器serveri资源空闲情况主要指CPU空闲情况,用空闲的核心数量ci表示。各服务器的空闲资源在所有服务器空闲资源总和中占有的比例称为空闲资源占比ki:
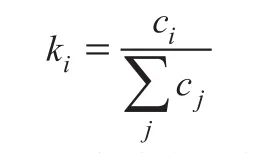
用户请求的任务量为M,则根据空闲资源占比各个执行服务器分配到的任务量为mi:

在实际工作中,文件系统将下传的遥感数据按年、月、日、小时划分目录进行组织,方便后续的使用管理。由于遥感卫星在每个小时所产生的数据量基本相当,所以在实际的均衡策略执行时并不需统计目录下确切的文件数量,可将小时目录的数量近似看做任务量来进行分配。现用户请求对目录DATA下的文件进行检测,其下有0-23共24个小时目录。如图3所示,集群中有5台服务器,假定当前各服务器均为空载,则通过负载均衡策略将子目录分配给各执行服务器执行。
3.1.3 检测结果推送
如图4所示,集群中采用TCP 迁移技术,将客户端与均衡服务器的TCP连接透明地迁移至执行服务器上。执行服务器执行完毕后将结果写入数据库,不经过负载均衡服务器而是直接向客户端推送结果信息,既有效减少了客户端的响应延迟,又大大降低负载均衡服务器的负担,有助于提高整个系统的性能。
3.2 基于多线程的并行检测
3.2.1 并行检测流程
扫描检测任务的执行过程如图5所示。
执行服务器上的任务执行模块根据得到的任务配置信息和分配的系统资源量开辟适当规模的线程池,管理多个线程并行执行扫描检测任务。
用户提交任务时通过任务配置模块和负载均衡模块将配置信息传递给任务执行模块,同时服务器资源监视调度模块监测服务器上业务运行情况,为检测服务分配系统资源。在业务空闲状态下可以为检测服务分配尽量多的资源加快扫描检测速率,在业务繁忙状态下可适当回收部分资源,保证服务器上其他业务的正常运行。任务执行模块中的线程管理子模块根据获得的任务信息和可分配资源信息开辟包含多个线程的线程池,并行执行扫描检测任务。在线程执行过程中,首先从数据库中获得筛选依据,而后递归进入目录对文件格式、各级目录以及文件属性和目录层级匹配是否规范进行判断,并将违规数据写入数据库。
3.2.2 多线程的实现
线程池结构如图6所示。
线程池主要由线程、任务队列和线程管理器组成。其中线程管理器负责调度,避免反复创建和销毁线程造成不必要的时间开销,提高资源利用率。
服务器根据可分配的资源量默认开辟线程数为n的线程池,为核心线程。任务到达时,按小时目录划分为子任务分配给各个线程执行。若子任务数多于n,则线程池增开线程,但总数不得超过可分配的最大核心数m;若线程池已满则将任务放入任务队列等待执行;若任务队列已满则拒绝新加入的任务。
4 实验分析
4.1 实验环境
4.1.1 硬件环境
1台PC终端(作为软件操作终端),4台服务器(1台负载均衡服务器,3台执行服务器)。
服务器配置如下:
CPU:Intel(R) Xeon(R) CPU E5-2650 v3@ 2.30GHz×4
网卡:Intel Corporation 82599ES 万兆网卡
4.1.2 软件环境
集群操作系统:Redhat Linux 6.5 64位PC端操作系统:Windows 7 64位中文版文件系统:华为Oceanstor5500分布式文件系统
4.2 性能测试及结果分析
实验按照实际的文件格式在DATA目录下生成日期子目录20190103,在20190103目录下生成12个小时子目录01-12,每个小时目录内包含100000条正常数据和2000条异常数据,共计1224000条数据。分别采用集群服务器多线程执行、单服务器多线程执行和集群服务器单线程执行对DATA目录进行多次扫描检测对比实验,记录任务执行时间如表1。
从表1中的数据可以看出,集群服务器的检测效率要优于单机的检测效率,多线程的检测效率要优于单线程的检测效率。分别定义集群多线程、单机多线程和集群单线程的执行速率为V1、V2、V3,则有:

实验中,所有异常数据均能被检测出来,同时没有正常数据被误检为异常数据,检测准确率为100%。由此得出采用集群和多线程技术对海量数据进行扫描检测,在检测效率上可以取得显著提高,是一个可行的方案。
5 结语
本文通过对海量数据处理技术的学习研究以及对实际业务的具体分析,设计了一种针对海量数据文件异常的并行检测技术,主要采用集群和多线程的技术进行实现。通过在百万量级的数据上进行对比实验,取得了令人满意的结果,证明采用集群和多线程技术能够显著提高检测效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
网络安全和信息化(2018年9期)2018-03-03
信息安全研究(2018年1期)2018-02-07
网络安全和信息化(2017年12期)2017-11-08
环球市场(2017年36期)2017-03-09
建筑设计管理(2014年12期)2014-02-28
测绘科学与工程(2014年2期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
吉林建筑大学学报(2012年3期)2012-08-15
