
基于数组和辅助项头表的快速频繁项集挖掘算法
2019-05-06 05:42张世伟
中国计量大学学报 2019年1期
杜 媛,张世伟
(1.中国计量大学 信息工程学院,浙江 杭州 310018;2.中国计量大学 现代教育技术中心,浙江 杭州 310018)
数据挖掘能够发现隐藏在大量数据集中的信息,而关联规则挖掘是数据挖掘中非常重要的研究方向。关联规则挖掘分成两个阶段:获得频繁项集和产生强关联规则,而强关联规则是根据频繁项集产生的,所以在关联规则挖掘中重点在于如何获得频繁项集。经典的关联规则挖掘算法有Apriori算法[1]和频繁模式增长(Frequent pattern growth,FP-growth)算法[2]。Apriori算法使用产生-测试和逐层迭代策略发现频繁项集,在每次迭代过程中,新的候选项都由前一次迭代发现的频繁项集产生,然后对每个候选项的支持度进行计数,并与最小支持度进行比较。Apriori的并行化研究[3-4]虽然加快了算法的执行速度,但是仍需要多次扫描数据库同时会产生大量的候选项。FP-growth的提出正好解决了这两个缺点。FP-growth算法使用频繁项集头表和频繁模式树(Frequent pattern tree,FP-tree)压缩存储数据库,并通过递归方式挖掘FP-tree来获取频繁项集。算法在构建FP-tree时只需要扫描数据库两次,在递归挖掘频繁项集时无需产生候选项,从而极大程度上减少了存储空间的损耗。
FP-growth在挖掘过程中需要不断递归生成条件FP-tree,而条件FP-tree的生成需要分两步实现:1)根据需要挖掘的后缀基,从FP-tree中提取前缀路径,并根据前缀路径构建频繁项集头表;2)根据频繁项集头表,按照支持度计数降序排列前缀路径,然后构建条件FP-tree。所以在挖掘过程中FP-growth算法需要遍历前缀路径两次:分别发生在频繁项集头表和条件FP-tree构建过程中。FP-growth的改进算法FP-growth*[5]引入了数组技术,在生成条件FP-tree同时构建数组,存储频繁2-项集的支持度计数,进入下一次构建条件FP-tree时直接从数组中提取对应频繁2-项集,删除后缀基后即为当前挖掘过程中的频繁项集头表,减少了对前缀树路径的遍历。但是FP-growth*需要生成条件FP-tree,而基于数组前缀树算法[4](Algorithm of frequent itemsets mining base on Array Prefix-trees,AFP-growth)直接采用数组前缀树代替条件FP-tree,仅存储前缀路径中最后一项和前缀路径的支持度计数,提高算法挖掘效率。FP-growth*和AFP-growth的改进主要体现在挖掘阶段,对于构建树阶段不少学者也提出了众多不同的改进方向:1)扫描仅含频繁项集的事务,同时利用哈希表辅助存储提高构建效率[7];2)对最大频繁项进行构建,减少FP-tree的结点[8-9];3)使用MapReduce模型设计并行FP-growth算法[10-11]。但是这些改进算法都是以树型结构为基础进行频繁项集挖掘,而树在构建过程中需要不断遍历子/父结点以及同名结点,同一结点的子结点或者同名结点越多算法需要遍历的深度越大,建树过程越为复杂,大大降低了执行效率。
针对频繁项集挖掘算法中建树复杂,挖掘效率低等问题,本文提出了基于数组和辅助项头表的快速频繁项集挖掘算法(Fast frequent itemsets mining algorithm based on array and auxiliary item header table,AHT-growth),分别从构建和挖掘两个方面进行改进。算法使用数组结构(Array-structure)代替FP-tree存储项结点,使用数组索引快速定位,避免遍历子/父结点以及同名结点上时间的损耗;同时以辅助项头表代替频繁项集头表,使用可hash的数据结构表示,存储当前项在Array-structure中的索引,达到直接定位项结点效果,提高构建效率。为避免挖掘过程中不断递归生成条件FP-tree降低算法执行速度的问题,算法直接在辅助项头表上进行挖掘,无需生成条件FP-tree。
1 频繁项集
设集合I={i1,i2,…,in},I的子集称为项集。设数据库为D,D中的每条事务数据均为I的一个子集,即为项集。如果是频繁的,则称为频繁项集。
定义1:对于项集T,其在D中出现的频率称为支持度计数,记为countT;若D存在N条事务数据,则T的支持度supportT可由式(1)计算得出
(1)
对于给定最小支持度min_support,如果supportT≥min_support,那么T就是频繁项集。而最小支持度计数min_count=min_support×N,所以如果countT≥min_count,T同样是频繁项集。
根据定义1可知判断一个项集是否频繁项集可以使用min_support或者min_count作为评估标准。
2 AHT-growth算法
2.1 项结点
FP-growth使用FP-tree存储数据库中的所有事务,每一个事务在FP-tree中构成一条树路径,路径中的每个结点表示事务中的一个项。为构成完整的FP-tree,每个结点包括5个域:1)项结点标识符name,标识结点基本信息;2)项结点支持度计数count,记录当前项在数据库中出现的频率;3)项结点子指针child_link,链接到当前项的子结点,构建FP-tree时进行结点查询;4)项结点父指针parent_link,链接到当前项的父结点,在进行频繁项集挖掘时根据后缀基自底向上遍历前缀路径;5)项结点同名指针node_link,在生成条件FP-tree时通过该指针遍历同名结点,提取所有的前缀路径。而AHT-growth算法使用Array-structure代替FP-tree,可通过索引值直接取出对应的项结点。其项结点包含1)项结点标识符name,2)项结点支持度计数count,3)父结点位置索引值parent_position,任何一个项结点都可以根据parent_position查询到整个事务。相比于FP-growth,AHT-growth算法中的项结点更加简单。
2.2 辅助项头表
AHT-growth使用辅助项头表代替FP-growth中的频繁项集头表,但其表示的仍然是通过第一次扫描数据库后生产的频繁1-项集,不同的是辅助项头表中存入了所有同名项结点在数组结构中的位置信息,替换频繁项集头表的结点链。辅助项头表整体包含3个域:1)频繁项集标识符name,与项结点名字同等含义;2)频繁项集支持度计数count,表示频繁项集标识符所代表的项结点在整个数据库中的所有计数;3)频繁项集所有同名项结点信息information。整个辅助项头表采用可hash结构表示,name作为键值,可以快速取出频繁项集,提高算法执行效率。其中information域又包含如下内容:父结点位置索引parent_position,频繁项集所有同名结点自身位置索引self_position以及对应的支持度计数self_count,其中parent_position作为可hash结构的键值使用。在创建Array-structure时需要根据前一个结点的self_position确定当前插入结点的位置,也就是当前待插入结点的parent_position,而在频繁项集挖掘遍历前缀路径时需要使用parent_position自底向上查询,所以parent_position作为键值具有合理性。在插入项结点和频繁项集挖掘时可以快速定位,缩短算法执行时间,提高算法执行效率。用self_count表示当前结点前缀路径的支持度计数,用来确定以当前项结点作为后缀基时,其前缀路径的支持度计数。综上所述,辅助项头表采用两层可hash结构表示,提高算法的执行效率。
2.3 AHT-growth构建过程
FP-growth构建FP-tree进行项结点插入操作时需要更新同名结点指针域,操作方式如下:1)如果需要插入的结点已经存在FP-tree中仅更新当前项结点的计数值;2)如果需要插入的结点不存在,则创建一个新结点插入FP-tree中,同时链接至频繁项集头表结点链所表示的同名结点尾部,需遍历整个结点链,故时间复杂度为O(n)。AHT-growth中不存在结点链,当有新结点需要插入Array-structure时,算法直接将该结点的相关信息存入辅助项头表中;而当插入的结点已经在辅助头表中存在时,可根据辅助项头表的两层hash结构直接更新,所以整个操作过程的时间复杂度为O(1)。
AHT-growth构建过程与FP-growth整体上一致,不同之处在于以下两点:1)使用Array-structure代替FP-tree存储数据库中的所有信息;2)使用辅助项头表代替频繁项集头表存储频繁1-项集。AHT-growth需要扫描数据库两次才能完成构建:第一次扫描数据库统计各项的支持度计数得到降序排列方式,同时根据最小支持度计数删除非频繁项;第二次扫描数据库时构建Array-structure。算法构建过程如下。
1)第一次扫描数据库D,依次读取D中的每条事务数据并统计事务中每个项的支持度计数存入辅助项头表中。如果取出的项已经存在辅助项头表中则仅对该项的支持度计数增加1,否则在合适的位置记录该项,并初始化值为1。
2)辅助项头表创建完成后,根据给定的最小支持度计数删除非频繁项集,此时的information域为空。
3)创建一个root结点,存入Array-structure头部,作为所有事务数据首个项的父结点使用,在频繁项集挖掘时亦可作为遍历结束标志位。
4)第二次扫描数据库D,依次读取D中的每条事务数据,根据第一次扫描数据库得到的支持度计数降序排列方式对事务中的项进行排序,同时结合最小支持度计数删除非频繁项。
5)设4)获得的项集为T,依次遍历T中的每个项,将其插入到数组结构中同时更新辅助头表中的information域,操作方式按照6)。
6)设T中取出的项为Ti,首先根据Ti.name取出辅助头表中的information域,记为infor,根据infor中的parent_position判断当前需要插入的项是否已经存在Array_structure中,因为具有相同父结点的同名项在Array_structure中为同一个项。如果存在,则对应项的计数增加1,因为parent_position为第二层hash结构的键值,故可以直接取出self_count;如果不存在,新建一个结点Ni,设置项结点标识符为Ti.name,项结点计数为1,父结点位置索引为其前项的位置索引值即为infor.parent_position,之后将Ni添加至数组结构末尾,同时在辅助项头表添加Ni的相关信息。
7)循环执行5)~6),D中所有数据全部添加至Array-structure中,此时算法构建完成。
为便于理解AHT-growth的具体步骤,文中引入了一组简单的测试数据集[12],数据集包括6条事务数据,共涉及16个不同的项集,每条事务数据均为此16个项集的不同组合,如表1第二列。设置最小支持度为3,经过算法构建过程步骤1)和2)得到辅助项头表,如表2第一列和第二列。所有事务数据在构建Array_structure时都会根据辅助项头表中支持度计数降序排列方式和最小支持度计数进行处理,处理后的数据如表1第三列。
根据表1数据举例说明如下:算法在构建数组结构时,首先创建Nroot=(root,0,-1)插入数组结构中,数组结构的位置索引以root为0开始标记;然后取出第一条事务数据,经处理后得到{z,r},取出z,此时数组结构和辅助项头表中均不存在z结点的相关信息,故直接产生一个新项结点Nz=(z,1,0),将Nz插入数组结构。辅助项头表中z对应的information域为{0:(1,1)}。对r进行相同操作,结果如图1(a);取出第二条数据,经处理后为{z,x,y,t,s},首先需要插入z,通过辅助项头表的第一层hash结构,以z为键值直接取出z的同名项结点信息即{0:(1,1)},而当前插入项为首结点,故其前项结点为root,因此当前事务中z所处环境已经存在数组结构中,根据第二层hash结构以0为键值取出(1,1),根据self_position=1,定位到数组结构中,并对其支持度计数增加1,同时对辅助头表中z的self_count域加1,剩余项{x,y,t,s}都是首次出现,依次添加至数组结构并更新辅助项头表即可,如图1(b);依次取完6条事务数据后辅助头表如表2,数组结构Array-structure如表3。

表1 测试数据集

图1 Array-structure构建过程Figure 1 Establishment of Array-structure

标识符支持度计数同名结点信息z5{0:(1,5)}x4{1:(3,3),0:(7,1)}y3{3:(4,3)}t3{4:(5,3)}s3{5:(6,2),7:(8,1)}r3{1:(2,1),8:(9,1),5:(10,1)}

表3 Array-structure完整结果
2.4 AHT-growth挖掘过程
Array-structure构建完后便开始进行频繁项集挖掘,挖掘过程采分治策略[13],将一个问题分解为多个较小的子问题,从而发现以某个特定后缀结尾的所有频繁项集。FP-growth在挖掘某个后缀基的所有频繁项集时会生成条件FP-tree以及对应的频繁项集头表。而AHT-growth使用辅助项头表代替了频繁项集头表,同时辅助项头表中存储了所有项结点的父结点和自身结点位置以及支持度计数,所以在挖掘时无需生成条件FP-tree,直接在辅助项头表上挖掘即可,加快了算法的挖掘效率。而对应前缀路径可直接在Array-structure上通过辅助项头表的information进行查询。以表1数据集为例,挖掘过程如下。
1)挖掘算法从辅助项头表中最后一项开始执行,如表2中的r,因为辅助项头表中的项均为频繁项集,所以r是频繁的。
2)根据r取出对应的information域信息,令infor={1:(2,1),8:(9,1),5:(10,1)}。infor各项对应{parent_position:(self_position,self_count)}。根据infor中的parent_position查询r的全部前缀路径,由{1:(2,1)}可遍历的前缀路径为{z,root},该路径的支持度计数为1,因为root仅作为标记项使用,在去除后root该路径可表示为{z:1},对应information域为{0:(1,1)};同理,由{8:(9,1)}遍历的前缀路径为{s,x:1},information域为{7:(8,1),0:(7,1)};由{5:(10,1)}遍历的前缀路径为{t,y,x,z:1},对应information为{4:(5,1),3:(4,1),1:(3,1),0:(1,1)}。合并所有结果,后缀基为r并包含非频繁项集的辅助项头表如图2(a)。

图2 后缀基为r的辅助项头表Figure 2 Auxiliary header table with suffix base r
3)因为最小支持度计数为3,所以图2(a)中不存在频繁项集,经处理后辅助项头表为图2(b),无需再递归挖掘后缀基为r辅助项头表。
4)接下来转为挖掘以s为后缀基的频繁项集,令infor={5:(6,2),7:(8,1)},根据2)-3)的挖掘过程,取出后缀基为s的前缀路径构成辅助项头表并去除非频繁项后,仅剩{x:(3,{1:(3,2),0:(7,1)})},如图3(a)。之后挖掘以{x,s}为后缀基的频繁项集,遍历完所有的前缀路径并去除非频繁项后,以{x,s}为后缀基的辅助项头表为空,如图3(b),至此以s为后缀基的频繁项集挖掘完毕,频繁项集有{s},{x,s}。

图3 以s结尾的辅助项头表Figure 3 Auxiliary header table ending in s
5)对表2中的t,y,s,z进行相同操作,完成对表1数据的频繁项集挖掘。
3 实验结果与分析
为验证AHT-growth性能,实验将本文算法与FP-growth,AFP-growth进行对比。实验在Windows 7操作系统,Core i3-3220 CPU 3.3 GHz,8 G内存环境下实现。算法使用Python编程完成。为验证AHT-growth在不同数据集上有效性,实验数据选择2个常用数据集:1个密集型数据集Mushroom[14]和1个稀疏型数据集retail[14]。实验得到的结果如图4~图5。
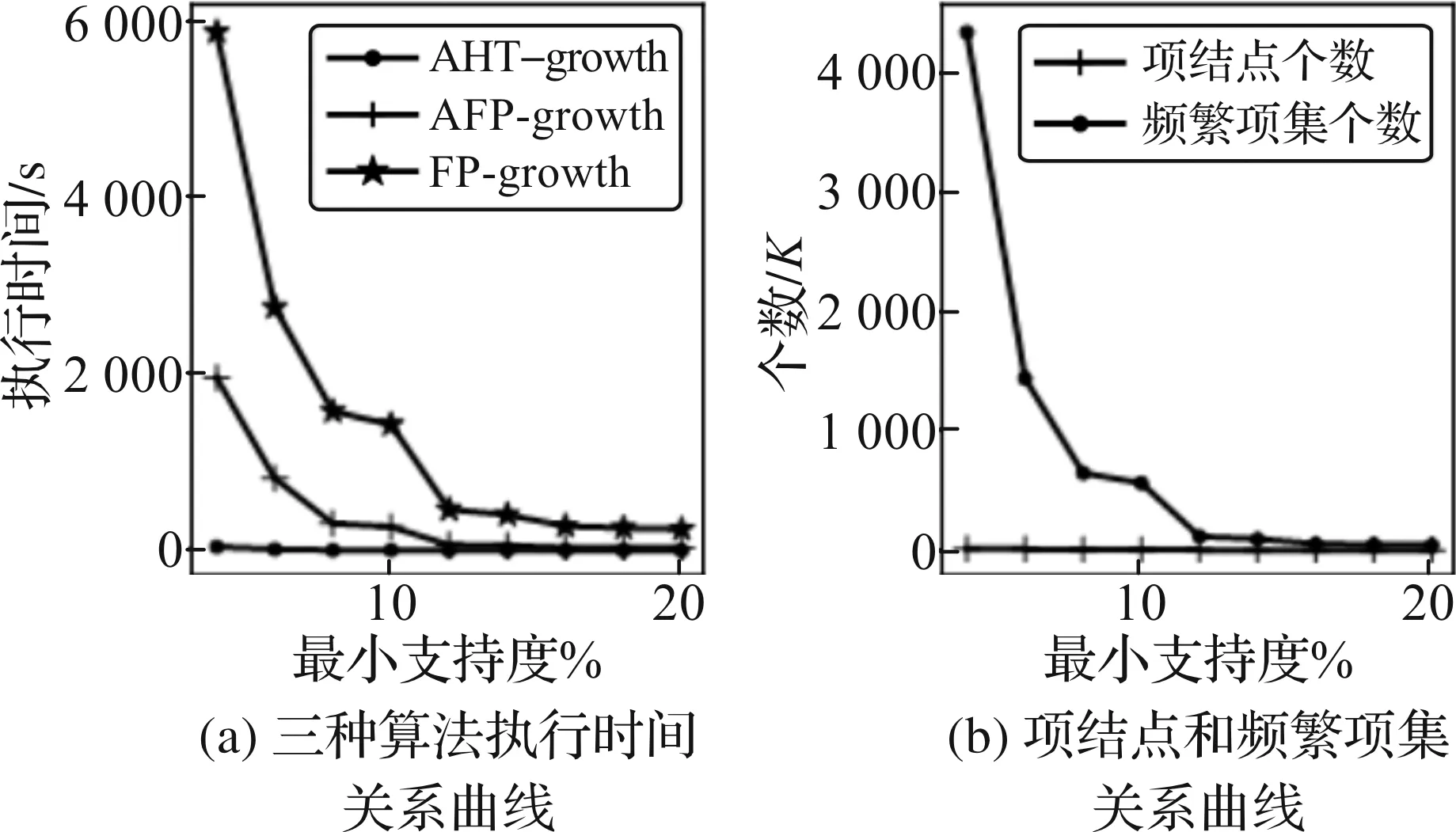
图4 Mushroom数据集实验结果Figure 4 Result of Mushroom data set

图5 Retail数据集实验结果Figure 5 Result of retail data set
图4(a)是三种算法在密集型数据集Mushroom上执行结果。随着最小支持度不断增大,三种算法之间的差异不断缩小,而在较低的最小支持度下,三种算法都存在很大差异。但是本文的AHT-growth执行效率最佳,并且随着最小支持度的降低,这种差异更加显著。这是因为当前实验的数据集为密集型数据集,该数据集事务数据总数为8 124条,项集个数为119个,但是每个事务的平均长度和事务最大长度均为23个,说明其必然存在非常庞大的频繁项集,从图4(b)的结果也可看出:当最小支持度减小时,频繁项集的增长速度加剧,算法将花费大量的时间在频繁项集挖掘中,由于FP-growth需要不断的产生条件FP-tree,AFP-growth使用数组前缀树代替条件FP-tree,而本文改进算法直接在辅助项头表上挖掘,并且利用两层hash结构可快速定位项结点在Array-structure上的位置,所以在三种算法中AHT-growth具有最好的执行效率。
图5(a)是三种算法在稀疏型数据集Retail上的执行结果。随着最小支持度不断增大,三种算法之间的差异不断缩小,而在较低的最小支持度下,AHT-growth与FP-growth以及AFP-growth存在很大差异,而后两种算法的差异较小,并且随着最小支持度的降低,AHT-growth算法的优势更加明显。这是因为当前实验的数据集为稀疏型数据集,该数据集事务数据总数为88 162条,项目个数为16 470个,但是每个事务的平均长度为10,事务最大长度为76,说明其频繁项集相对于项结点来说非常少,从图5(b)的结果也可看出:当最小支持度减小时,项结点的增长速度加剧,算法将花费大量的时间在构建过程中。由于FP-growth和AFP-growth都需要构建FP-tree,且在构建算法上思想基本一致,故两者算法效率基本一致,而本文改进算法使用Array-structure替换FP-tree,并且使用具有两层可Hash的辅助项头表,利用Array-structure可直接索引特性,用以快速定位结点位置以及同名结点信息,所以在三种算法中本文的AHT-growth具有最好的执行效率。
4 结 论
本文提出了一种基于数组和辅助项头表的频繁项集挖掘算法——AHT-growth。该算法使用Array-structure代替FP-tree存储数据库中的事务数据,同时使用具有两层可Hash的辅助项头表存储频繁项在Array-structure中的位置和支持度计数,利用Array-structure可直接索引特性结构hash结构快速定位,缩短同名项结点和前缀路径的查询遍历时间。在挖掘频繁项集时,使用辅助项头表中存储的信息直接挖掘,避免了频繁生成条件FP-tree过程,缩短算法在挖掘上的时间损耗。实验结果表明AHT-growth在密集型和稀疏型数据集上具有更好的执行效率,并且优势显著。本文算法改进方向集中在提高算法执行效率上,在创建Array-structure时,辅助项头表中会存入所有项结点在Array-structure上的位置信息,故内存占用较大。在挖掘过程中虽然无需生成条件FP-tree,但是存储在辅助项头表上的项结点信息仍占据着内存,如何减小算法内存占用量将是下一步研究的方向。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
电脑报(2022年13期)2022-04-12
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
电脑报(2020年24期)2020-07-15
计算机与数字工程(2018年10期)2018-10-23
电脑爱好者(2017年22期)2017-12-04
计算机与数字工程(2017年2期)2017-03-02
初中生之友·中旬刊(2015年4期)2015-06-10

- 中国计量大学学报的其它文章
- 基于组分分析的农业废弃物类生物质热裂解机理研究