
动态环境下结合语义的鲁棒视觉SLAM*
2019-05-07 11:45王金戈邹旭东仇晓松蔡浩原
传感器与微系统 2019年5期
王金戈, 邹旭东, 仇晓松, 蔡浩原
(1.中国科学院 电子学研究所 传感技术国家重点实验室,北京 100190;2.中国科学院大学 电子电气与通信工程学院,北京 100049)
0 引 言
传统的同时定位与地图构建(simultaneous localization and mapping,SLAM)技术建立在静态环境下,不考虑环境物体的运动。而实际环境中,人的走动、车辆的来往都会造成环境动态变化,从而使SLAM系统建立的地图无法保持长时间的一致性,基于视觉的特征也会因为物体的运动而变得不稳定。在仓储、无人驾驶等定位精度要求较高的领域,移动中的人对SLAM定位精度的影响会导致位姿漂移、跟踪失败、误差累积等问题。
为了使SLAM在动态环境下正常工作,需要避免使用处于动态物体上的特征点,因此,需要事先计算出动态物体的位置。目前常用的动态物体提取方法都是基于几何特征[1,2],当面对更加极端的动态环境时,如人靠近镜头的走动,依然会失效。
本文提出了一种结合语义的鲁棒视觉SLAM—Dynamic-SLAM算法,采用深度学习技术在语义层面实现对动态物体的检测,并对动态物体特征点进行剔除,以消除其在SLAM定位与建图中的误差。实验证明,该方案在各种动态环境中都取得了较好的定位精度和鲁棒性。
1 系统框架
本文在ORB-SLAM2[3~5]的基础上,增加基于语义的动态物体判定模型,并优化基于特征点的视觉里程计算法,使其能够舍弃附着在动态物体上的特征点,只采用非动态物体的特征点参与位姿估计和非线性优化,从而避免动态物体特征点的干扰。在物体检测部分,提出了基于运动模型的物体检测补偿算法,进一步提高了物体检测精度。
单目相机实时采集的图像作为SLAM定位与建图模块和物体检测模块的输入,物体检测模块的输出经过语义校正模块后实时反馈给SLAM定位与建图模块,SLAM定位与建图模块最后给出定位和建图结果。
1.1 物体检测
本文采用文献[10]提出的SSD(single shot multibox detector)物体检测网络,该网络使用VGG16的基础网络结构,保留前5层不变,利用Atrous[11]算法将fc6和fc7层转换成2个卷积层,再在后面增加3个卷积层和1个平均池化层。使用不同网络层的信息来模拟不同尺度下的图像特征,最后通过非最大抑制得到最终的检测结果。由于舍弃了最初的候选框生成阶段,使得整个物体检测流程能够在单一网络下完成,从而实现较高的检测效率(46 FPS,Titan X)和检测精度(77.2 %)。
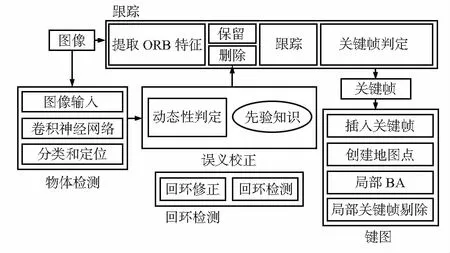
在动态环境SLAM中,动态物体检测的成功与否直接决定了系统的其他模块是否能够正常执行。一旦发生漏检,相邻两张图像间的巨大差异将会导致特征点数量急剧变化,从而导致系统的不稳定。为了能够稳定、有效地剔除动态特征点,必须在物体检测时获得足够高的检测精度。在常规的物体检测任务中,由于各个图片间不具有明显的关联,无法通过上下文信息提高检测精度。但在SLAM中,由于视频帧按照时间序列抵达,可以借助前若干帧的检测结果预测下一次的检测结果,从而弥补下一次可能出现的漏检或误检。基于这一思想,本文提出了相邻帧漏检补偿模型,该模型基于一个合理的假设:“动态物体的运动速度不会超过某个阈值”。用X表示动态物体的坐标,Vth表示动态物体运动速度的阈值,FPS表示帧率,两者之间应该满足X 漏检补偿流程如下: 1)当前帧K1进入SSD网络,输出检测到的物体列表,列表中的每一项包括检测出的物体的位置坐标X1i(0 2)若对于前一帧K0的检测结果中的每一项X0j(0 3)修正后的检测结果列表作为动态物体判定原始数据。 本文在语义的层面上提出了基于先验知识的动态物体判定方法。SLAM系统如果不从语义层面理解周围的环境,就无法真正区分哪些是动态的,哪些是静态的,只能在短时间内找出运动的物体,而无法保证长时间的一致性。因此,本文将物体检测的结果与先验知识相结合,给出动态物体判定模型。根据人的先验知识,对物体的动态特性评分,0分为静态物体,10分为动态物体,常见物体在该区间上所处的大致位置如图1所示。 图1 常见物体的动态特性评分 图中只列出了一部分常见的物体,其他物体的评分可以根据具体应用设定合适的分数。将物体分数与一个事先定义的阈值相比较,分数高于阈值时判定为动态物体,低于阈值时则判定为静态物体。阈值的大小视情况而定,通常可设为5。 在ORB-SLAM2原有框架的基础上,增加了物体检测线程和基于语义的校正模块。新增的模块与ORB-SLAM2已有的3个线程的关系如图2所示。在新的视频帧抵达后,同时传入物体检测线程和跟踪线程,两者并行地对图像进行处理。物体检测线程采用前述的SSD物体检测网络计算出物体的类别和位置,进一步由基于语义的校正模块将其中的物体分为动态物体和静态物体,最后把动态物体的位置提供给跟踪线程。 图2 Dynamic-SLAM流程框图 跟踪线程对每一帧图像提取ORB特征[12],通过与参考帧的特征匹配,得到2张图像间特征点的对应关系,利用这些对应关系估计相机位姿。在初始化完成的情况下,相机位姿估计是一个PnP(perspective-n-point)问题,求解该问题的方法有很多[13,14],本文采用以集束调整(bundle adjustment)[15]为代表的非线性优化方法,该方法可以充分利用所有匹配结果,得到位姿的最优估计。构建非线性优化问题,最小化重投影误差如下 式中ξ将观测到的像素坐标与3D点按照当前位姿ξ投影后的2D坐标求差,该误差即为重投影误差。优化目标是找到一个相机位姿ξ,使得重投影误差最小。 在动态环境中,受到运动物体的影响,动态物体上特征点的重投影误差会处于过高的水平,导致相机位姿ξ无法收敛到最优值,定位误差显著增大。为此Dynamic-SLAM的追踪线程在提取ORB特征后,根据当前检测到的动态物体的位置实施特征点剔除操作,将动态物体其上的特征点予以剔除。在后续的局部地图匹配、相机位姿估计和非线性优化中,只利用静态物体上的特征点,保证整个过程中重投影的一致性,使SLAM系统不受动态物体干扰。 为了保证SLAM系统的实时性,物体检测和跟踪分处2个线程,设计了安全高效且支持并发操作的数据结构Detection来传递检测结果,并使用互斥锁Unique_lock保证不发生访问冲突,在写入操作执行前需事先获取锁。物体检测线程和跟踪线程的处理速度并不一致,采取异步读写共享变量的方式实现线程间通信,最大限度地利用CPU时间。 本文设计并实施了一系列实验来验证Dynamic-SLAM系统在动态环境下的鲁棒性和定位精度。使用TUM RGB-D benchmark[16]中的Walking_rpy数据集验证物体识别的准确率和检出率,使用2段采集的数据集验证动态物体干扰下初始化和定位的鲁棒性,使用TUM RGB-D Benchmark中的Walking_xyz数据集验证一般动态环境下的定位精度。 实验运行环境为Intel Core i5-7300HQ(4核2.5 GHz),8 GB内存,NVIDIA GeForce GTX1050Ti显卡,4 GB显存。 在该项测试中,采用Walking_rpy数据集,在连续487帧图片中,SSD的原始检测结果成功检出401次,失败86次,检出率82.3 %。经过运动补偿后的检测结果成功检出486次,失败1次,检出率达到99.8 %。图3所示为物体检测结果每隔30帧的抽样,左侧为SSD的原始检测结果,右侧为经过相邻帧漏检补偿后的检测结果,方框为检测到的物体位置,左下角标签标注了物体类别。实验表明,相邻帧漏检补偿模型大大提高了物体检测的检出率,为后续的SLAM定位与建图模块打下了良好的基础。 图3 物体检测测试 初始化的成功与否关系到后续的定位是否准确。由于初始时刻尚无事先建立的地图,只能通过帧间匹配来确定相机的运动,导致动态环境下的初始化变得尤为困难。在动态物体的干扰下,SLAM很容易错误初始化。实验中,将摄像头放置在桌面上固定不动,测试人的来往走动对初始化会造成怎样的影响。 实验结果如图4所示。可以看到,ORB-SLAM 2在面对动态物体时,不能分辨前景和背景物体,无法排除动态物体的干扰,特征点大多聚集在动态物体之上,到第4幅图时已经错误初始化。而Dynamic-SLAM成功检测出动态物体的位置,并将其上的特征点剔除,从而避免了错误初始化。 针对人始终存在于相机视野中的情况设计了一个测试集,分别测试ORB-SLAM2和Dynamic-SLAM的运行效果。如图5所示。 图5 抗动态环境干扰测试 图6 抗动态环境干扰测试定位和建图结果 图5(a)中,为ORB-SLAM 2的特征提取(点状为特征点),图5(b)为Dynamic-SLAM的动态物体识别和特征提取。图6(a)ORB-SLAM 2的定位与建图结果,6(b)Dyna-mic-SLAM的定位与建图结果。可以发现,由于无法区分动态物体和静态物体,ORB-SLAM 2提取的特征点大多集中在人身上,使得系统把人当成背景环境,从而导致定位的结果完全依赖于人和相机之间的相对运动。在图6(a)中可以明显地看到,相机在运动一段时间后就完全停止了,地图点也不再更新。而Dynamic-SLAM能够自动选取静态环境的特征,定位结果是一条连续的直线,建立的地图也基本与实际场景相吻合。 本文选择TUM RGB-D benchmark中的Walking_xyz数据集,该数据集的场景中有2个人在办公桌周围来回走动,运动幅度大,且在视野中占据了不小的比例,本文测试两种算法在该场景下的定位精度和性能。 图7(a)为ORB-SLAM2的实时画面,图7(b)为Dynamic-SLAM的实时画面。记录了所有关键帧的定位结果,与真实值比较并计算误差。 图7 Walking_xyz数据集测试 从实验结果可以看出,在均方根误差、平均误差、误差中间值、误差标准差、最小误差和最大误差这6个指标中,Dynamic-SLAM(分别为1.68,1.59,1.74,0.55,0.54,2.81 cm)都明显优于ORB-SLAM2(分别为2.17,2.05,2.02,0.68,0.95,4.01 cm)。以均方根误差为标准,Dynamic-SLAM的精度比ORB-SLAM 2提高了22.6 %。在性能方面,记录了2个算法的运行时间,多次运行取平均值的方法Dynamic-SLAM的性能比ORB-SLAM 2提高了10 %。虽然增加了物体检测流程,但由于物体检测放在一个独立线程中,并利用了GPU加速,非但没有拉低整个系统的运行速度,反而使运行时间缩短了。这得益于无效特征点的减少,使系统只借助于有效的特征点进行计算,从而节约了位姿估计和非线性优化的时间。 本文提出了一种动态环境下结合语义的鲁棒视觉SLAM算法,实验结果表明,改进后的算法在动态环境下的定位和建图精度更高,鲁棒性更强。与目前State-Of-the-Art的视觉SLAM算法ORB-SLAM 2相比,在动态环境数据集下的定位精度提高22.6 %,性能提高10 %。1.2 动态物体判定

1.3 动态环境SLAM
2 实验与结果分析
2.1 物体检测

2.2 动态物体干扰下的初始化测试
2.3 抗动态物体干扰测试


2.4 TUM动态环境数据集测试

3 结 论
猜你喜欢
山西电子技术(2021年3期)2021-06-28中学生数理化·高一版(2020年1期)2020-02-20网络安全技术与应用(2020年1期)2020-01-07中学生数理化·八年级物理人教版(2018年10期)2018-12-06环球市场(2017年36期)2017-03-09光学精密工程(2016年5期)2016-11-07光学精密工程(2016年4期)2016-11-07湖北工业大学学报(2016年5期)2016-02-27科普童话·百科探秘(2015年4期)2015-05-14组合机床与自动化加工技术(2014年12期)2014-03-01
