
基于K-means++的WiFi指纹定位算法*
2019-05-07 11:45苏明明鲁照权尤海龙丁浩峰
传感器与微系统 2019年5期
苏明明, 鲁照权, 陈 龙, 谢 地, 尤海龙, 丁浩峰
(合肥工业大学 电气与自动化工程学院,安徽 合肥 230009)
0 引 言
WiFi[1,2]指纹法通过信号强度与位置的映射关系建立指纹数据库,再使用匹配算法估计目标的位置。在匹配算法中的确定性算法—加权K最近邻(weighted K nearest neighbour,WKNN)法[3],因其复杂度低、易于实现且定位精度较高而被广泛使用。而聚类的使用又能大幅度提高WKNN的计算效率且改善定位的精度,Yousself M等人[4]提出的显式聚类算法是最早用于指纹定位的聚类算法,但该方法只适用于定位区域较小且AP数量少的情况;Borenovic M等人[5]提出了区域分割算法,该算法人为地将定位区域分割成大小相同的子区域,因此受到室内格局的限制;Chen Y等人[6]提出了K-means算法并应用于指纹定位。K-means是通过对由接收信号强度(received signal strength,RSS)均值组成的特征向量进行聚类,其因训练快、易实现等优点成为较受欢迎的聚类算法,但初始点的选择和异常点的出现对其聚类的结果有很大影响。
本文在使用K-means++聚类算法的基础上,提出了一种基于参考点位置聚类的算法。在位置聚类结果的基础上,每个指纹都拥有一个类别。选择M个最大均值AP并计算定位点与各参考点的距离[7],然后利用K最近邻(K nearest neighbour,KNN)对定位点分类,消除了偶然误差,最后根据WKNN匹配算法即可得到位置结果。
1 WiFi指纹定位的一般原理
1.1 离线阶段
离线时将各参考点的指纹存入指纹数据库中。在待定位区域选择L个参考点,在每个参考点位置采集WiFi的信号强度,假设在第i个参考点检测到了m个AP的信号,则第i个参考点的指纹记作
(RSSIi1,RSSIi2,…,RSSIim,xi,yi)
(1)
式中xi,yi为参考点位置的坐标。在录入到指纹库时,将该区域所有能检测到的N个AP的信号按一定的顺序排列。当某个参考点处未检测到其中的某些AP的信号时,则将该AP的信号强度值设为最低值,得到该点真正的指纹
(RSSIi1,RSSIi2,…,RSSIiN,xl,yl)
(2)
1.2 在线阶段
在线时将实时的RSS特征向量上传到上位机,与指纹库进行匹配得到估计的位置结果。一般多采用WKNN匹配算法,其原理是:计算待定位点与每个参考点的距离,找到距离最近的K个点用作位置估计,其中距离为
(3)
式中disti为待定位点与第i个参考点的距离;N为所有AP的个数,也即特征向量的维数;当p为1时,该距离为曼哈顿距离,而一般p取2,即欧氏距离。当找到距离最小的K个点后,通过式(4)来计算这K个点对待定位点位置计算的重要程度,即权值
(4)
式中wi为待定位点与第i个参考点的权值;根据式(5)可求得位置结果
(5)
2 基于K-means++的定位算法
在复杂的室内环境下,根据指纹定位的一般算法虽然能够得到待测点的位置坐标,但定位的可靠性很低且精度一般难以满足要求。图1所示为本文定位方法的流程。
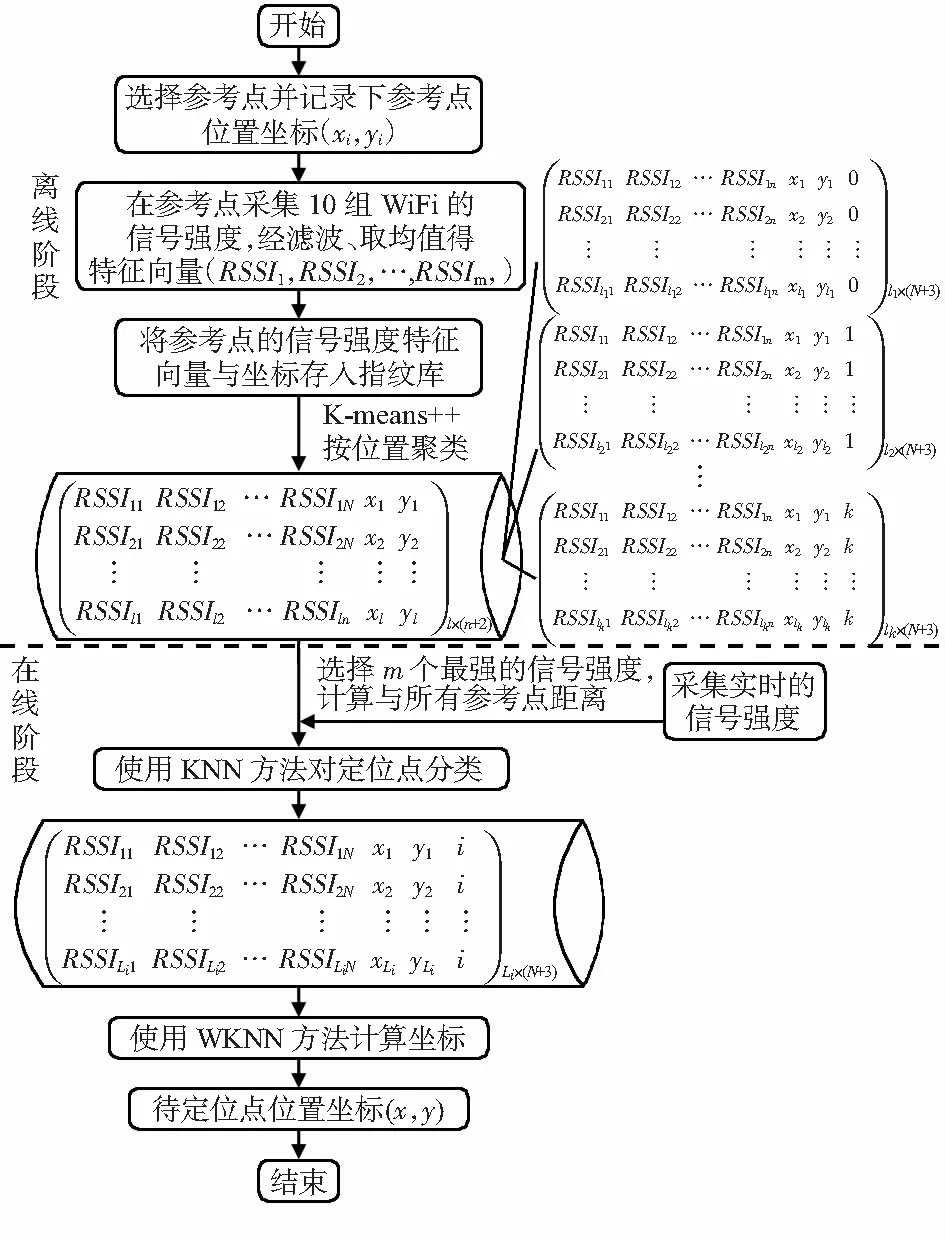
图1 基于位置聚类的指纹定位法流程
2.1 数据的滤波处理
为减小误差,本文使用限幅滤波和求均值的方法对数据进行滤波处理,流程如下所示:
1)观察采样数据,确定2次采样的允许的最大偏差值,并设为A。
2)每次检测到新的时,计算新值和上次的偏差,记作δ,并判断:
a.δ≤A,新值有效;
b.δ>A新值无效,取上次值。
3)重复过程(2),直到没有新值。
4)计算滤波后的均值,构建指纹。
2.2 使用K-means++对指纹分类
K-means++是一种无监督的学习方式,目的是为了把指纹库中的所有指纹按相似度进行分簇,使得相似的点在一个簇中,不相似的点属于不同的簇。
对指纹库中的指纹按位置聚类,把所有指纹分成了K个簇(C1,C2,…,CK)。在分簇的基础上,使用KNN分类法找到待定位点所属的分簇Ci,从而可以在该簇中估算其位置。算法流程如下所示:
1)随机选择一个参考点,并将其坐标(x,y)作为初始的“种子点”;
2)对每个参考点计算其与最近的一个“种子点”的距离D(x),并把这些距离加起来得到sum(D(x));
3)取一个落在sum(D(x))中的随机值Random=rand(sum(D(x))),然后用Random-=D(x),直到Random≤0,此时对应的坐标就是下一个“种子点”;
4)重复步骤(2)和步骤(3)直到选出K个聚类中心;
5)在这K个聚类中心下运行K-means算法。
2.3 有监督学习KNN
KNN分类的思想是,找到距离待定位点最近的K个参考点,则待测点就属于这K个参考点中大多数所属的簇。
由于并不是所有AP都适合用于定位,且MM法的AP选择方式简单又有较高的定位精度。因此,在选择M个最大均值AP的情况下,通过式(6)计算定位点与L个参考点的距离
(6)
将计算所得的disti按从小到大排序,则前K个参考点被用来投票分类。这K个参考点在K-means++聚类后都有自己的分簇C,则定位点就属于这K个参考点大多数所属的簇。
当指纹库中部分参考点在采集数据时因信号强度波动使其指纹偏离原本所属的簇,KNN以这种投票的方式也能够正确的分类,提高了可靠性。
3 试验与结果分析
试验采用UJIndoorLoc数据集,其为一个基于WiFi指纹的多建筑多层室内定位数据集。该数据集包括训练集TrainingData和测试样本ValidationData。选取其中部分样本(第0栋建筑的第0层的训练样本和测试样本)用于测试所提出的算法,在100 m×100 m的范围内,总共53个参考点以及37个测试点。
试验前对UJIndoorLoc数据集进行2处预处理,该数据集将所有在参考点处未检测到的AP信号强度设置为100,此处,均改WiFi信号强度的最低值-127,如此更符合实际情况[8];对数据集中参考点的经纬度分别减去取值范围的左边界,用新的坐标值来标定。
3.1 数据的滤波效果
在TrainingData中,每个参考点处都采样了10组RSS数据,观察数据后发现WiFi信号强度并不稳定,因此,需要对原始的数据进行滤波处理。仔细观察TrainingData后,选择A为5对采样数据作限幅滤波。如图2所示为在1个参考点处2个不同AP的10组采样数据滤波前后的对比,从图中可以看出,限幅滤波消除了因偶然因素引起的大幅度波动,使得采样值更加平滑、可靠,对滤波后的数据求均值更接近实际的RSS值。

图2 对10次采样值进行限幅滤波
3.2 K-means++聚类结果
为了验证对参考点的位置聚类有更高的可靠性,本文分别对强度和位置的聚类结果进行了分析。其中,聚类中心个数K的选择对定位性能的优劣有直接的影响,通过对不同K值的定位结果分析,最终选取K为4。如图3(a)中可以看出,第4个分簇在空间位置上有明显差别,空间位置的差别导致其由信号强度组成的特征向量是有差别的,理论上各量并不属于一个簇,但其与聚类中心的距离却决定了各量属于一个簇。而从图3(b)可以看出相邻位置的点属于一个簇,而距离远的点分属不同的簇。
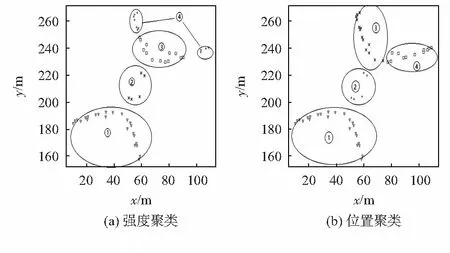
图3 按强度和位置聚类结果
3.3 定位结果分析
为了验证本文算法的性能,在同一个指纹库下对37个测试样本进行了多次定位试验。在选择M个最大均值AP的情况下(本文M取4)[9],分别对未聚类、强度聚类和位置聚类的指纹库使用WKNN算法(本文K取3)计算测试集的坐标;在位置聚类下,对指纹库使用线性插值法插入2个指纹并计算测试集的坐标,从定位结果可以看出,对指纹库的合理聚类提高了可靠性和降低了最大误差。其中强度聚类相对未聚类平均误差降低了21.35 %,而位置聚类与强度聚类相较平均误差又降低了7.31 %,本文提出的聚类方法有效地提高了定位的性能。另外,在观察参考点位置的过程中发现有些地方指纹稀疏,有可能是障碍物的存在导致无法采样,从而影响了定位的精度。为了降低误差,在合适的位置插值很有必要。本文使用线性插值在位置空白处插入了2个指纹,从结果来看同样降低了定位的平均误差。
不同聚类方法下定位精度概率累积分布以及位置聚类下测试集实际位置与定位位置如图4所示。从图中可以看出:本文算法的定位精度累积概率一直领先于强度聚类的方法,且达到了5 m以内89.19 %的概率,最大误差也控制在9 m以内,基本满足了对定位的要求。
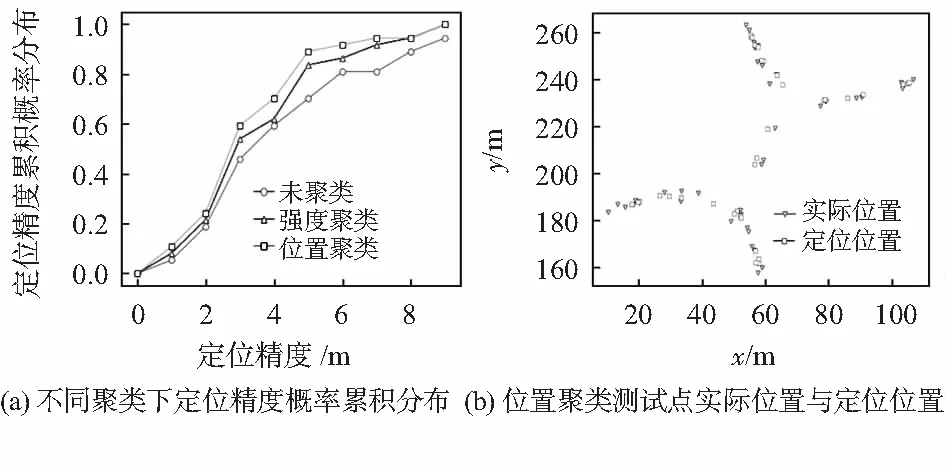
图4 定位精度概率累计分布和定位结果
4 结束语
本文在传统对信号强度聚类的指纹定位基础上,提出了对参考点位置聚类的方法。经过对试验数据的定位,验证了该方法在定位可靠性和定位精度方面都有较大提高。
但是本文方法中聚类的使用并没有降低计算量,测试点仍要与每一个参考点计算距离来正确分类。针对这一问题,可以在大区域定位时先进行强度聚类降低计算量,在小区域中再使用本文提出的方法提高定位性能。
猜你喜欢
中华眼视光学与视觉科学杂志(2022年8期)2022-08-17
中成药(2022年1期)2022-01-27
保健医苑(2021年9期)2021-09-08
金属加工(冷加工)(2020年11期)2020-11-24
机械制造与自动化(2018年6期)2019-01-08
中国设备工程(2018年14期)2018-08-09
精密制造与自动化(2018年1期)2018-04-12
现代测绘(2018年1期)2018-03-06
金色少年(奇趣科普)(2017年4期)2017-06-05
自动化学报(2017年2期)2017-04-04
