
融合频繁项集和潜在语义分析的股评论坛主题发现方法
2019-05-09 07:07翁康年顾小敏张玥杰
同济大学学报(自然科学版) 2019年4期
张 涛, 翁康年, 顾小敏, 张玥杰
(1. 上海财经大学 信息管理与工程学院, 上海 200433;2. 上海市金融信息技术研究重点实验室(上海财经大学), 上海 200433;3. 复旦大学 计算机科学技术学院, 上海 200433; 4. 上海市智能信息处理重点实验室(复旦大学), 上海 200433)
我国证券市场的发展历史短,各项机制还不够健全,因此交易行为常常受到市场信息和传闻的影响.特别是2015年我国股票市场在52个交易日内呈现股灾式暴跌,整体跌幅高达40.31%,年内A股市场惊现17次千股跌停,这暴露出我国证券市场发展的不成熟和股民们的非理性投资决策行为,股市的频繁剧烈波动已超出传统金融学理论的解释范围.研究表明,投资者情绪可显著影响股票市场的表现,如何通过相关论坛股评信息的主题挖掘来度量投资者情绪对股市表现的影响,已成为金融领域的重要研究方向.
网络论坛积累了大量短文本,短文本携带着丰富的用户信息,成为极具价值的新型信息资源[1].因此,从论坛的丰富信息中挖掘出用户真正关心的主题[2],不仅有助于管理层及时了解网络热点信息,还便于对网络舆情的监管[3-4].然而,网络论坛的文本数据具有低质、简短和冗余等问题,使得在基于现有向量空间模型的文本聚类方法处理时陷入高维稀疏、语义缺失的困境.对此,基于深度学习的方法效率较高,但需要依赖大量数据集进行训练,而实际应用中很难获取庞大的数据集.机器学习方法易于解释和理解,便于进行参数调整和模型改进,本文中提出的主题发现方法就是利用改进的机器学习算法进行短文本筛选和频繁项集的聚类.
选取新浪财经股吧论坛版块的评论作为数据集,利用基于频繁项集与潜在语义相结合的短文本聚类(STC_FL)框架和TSC-SN (text soft classifying based on similarity threshold and non-overlapping)算法对论坛数据进行深层次主题分析与挖掘,实现在线股评文本的自动聚类.
1 相关研究工作
一般从以下两个方面对投资者情绪进行考量:从隐性情绪指数的视角,选择公认可测变量来衡量;从显性指数的角度,通过实际调查来获取投资者的情绪[5].面向股评论坛的主题发现是通过对股评文本进行挖掘来获得潜在的主题和热点,然后分析用户发帖行为和情绪指标,并将其用于股市表现分析,以支持投资者的合理投资决策[6].
利用概率模型进行各类文本热点主题挖掘的方法已在信息处理领域得到广泛应用[7].常见的主题发现模型涵盖概率潜在语义索引(PLSI)模型、隐含狄利克雷分配主题(LDA)模型和潜在语义索引(LSI)模型等.其中,LDA模型最为经典,可用于从大量文档集中挖掘潜在的主题信息[8].Shams等[9]将共生关系作为先验领域知识应用到LDA模型中,自动从共生关系等方面的相关主题提取相关的先验知识,提高模型效果.Kim等[10]采用LDA模型,并结合基于变分期望最大化(EM)算法的学习模型参数推理算法,实现Twitter朋友和内容的推荐.Zhang等[11]提出基于群体LDA模型的受众检测方法,将图书模块和图书章节信息融入到模型中.李扬等[12]基于LDA模型将由文本提取的潜在主题用作分类特征,提出基于主题模型的阈值调整半监督文本情感分类模型.然而,基于概率模型的主题发现方法在训练过程中对语料依赖程度较高[13],应用于短文本数据效果不佳,主题中常出现高频重复词而无法直观看出主题,并且容易出现过拟合[14].
基于词频统计的主题挖掘方法也得到一定的关注与应用,最具代表性的是K-means算法.该算法在处理大规模数据时效率较高,不足之处在于初始聚簇中心容易选择不当而导致文本聚类结果为局部最优.针对该算法的不足,Laszlo等[15]利用遗传算法改进K-means算法对初始聚簇中心敏感的问题,尝试将该算法应用于高维数据聚类中.Sun等[16]引进Bradley和Fayyad的初始点迭代算法,提高了K-means算法聚类结果的准确性.然而,基于词频统计的主题发现方法是基于距离来度量文本之间和文本与聚簇类别间的相似度大小,而现实中文本特征项常常具有高维性.
基于频繁项集的热点主题挖掘方法的基本假设是:同一个主题聚簇中的文档集应共享更多的频繁项集,而不同主题聚簇间的文档集则共享较少的频繁项集.在此假设下按照频繁项集将文本划分至不同主题类别下[17].该方法得到了广泛的研究和应用.Chen等[18]提出了基于模糊频繁项集挖掘的层次文档聚类.Wang等[19]将频繁项集的概念用于数据库中的事务聚类和文本聚类,提出基于频繁项集的文本聚类算法.在应用中,学者们也对基于频繁项集的聚类算法不断改进.Zhang等[20]提出MC (maximum capturing)算法,利用文档所包含的频繁项集来度量文档间相似度,并将文档集划分至相似度高的聚簇中.Sethi等[21]提出混合频繁项集挖掘方法,通过对数据集进行垂直布局来解决迭代中数据集扫描的问题,提高算法效率.Djenouri等[22]提出频繁项集挖掘仿生方法,考虑频繁项集的递归性质,并引入粒子群优化算法.
基于频繁项集的方法从文本中挖掘频繁出现的词集合,可有效降低文本特征维度,又可对聚簇结果的聚类主题进行基本描述.然而,针对面向股评论坛中短文本比例较高的特殊情形,依然需要考虑以下三个问题:① 聚类过程中忽略文本所包含的潜在语义关系,造成语义缺失和不合理聚类;② 聚类中仍涉及初始聚簇中心选择与聚类数确定的问题;③ 采用的聚类算法仍属于文本硬聚类,仅将文本划分至唯一聚簇中.为解决这三个问题,有必要建立一种频繁项集和潜在语义的融合机制,有效结合两种方法的优势,以实现对短文本深层次信息的挖掘和主题归类.
2 面向股评论坛的主题发现新框架
为解决现有主题挖掘方法处理网络股评论坛中短文本数据所存在的困难,构建一种面向股评论坛主题发现的短文本聚类框架.利用频繁项集与潜在语义相结合的STC_FL框架从在线股评抽取主题词,再使用TSC-SN算法基于主题词进行文本检索,从而实现特有的股评文本聚类,如图1所示.知网(HowNet)是以揭示概念与概念之间和概念所具有的属性之间的关系为基本内容的常识知识库.针对文本中所蕴含的潜在语义关系,引入知网作为背景知识库建立基于概念的向量空间,并在文本集相似度计算的基础上,采用基于统计和潜在语义相结合的度量模式.通过较长频繁项集预估主题个数,以解决聚类结果数目的最优设定.针对融合频繁项集与潜在语义关系的文本软聚类,在文本检索阶段对TSC-SN算法设置短文本与主题簇间相似度阈值与簇间非重叠度参数,灵活选择和控制文本与主题间的对应关系.采用频繁项集和概念映射来降低向量空间维度,弥补基于向量空间的聚类所存在的语义缺失问题;融合频繁项集与潜在语义,有效降低特征空间维度的同时充分考虑潜在语义关系;在对主题词相关文本进行检索时控制短文本与主题簇间相似度阈值,同时引入簇间非重叠度概念,利用新型文本集划分策略实现文本软聚类.
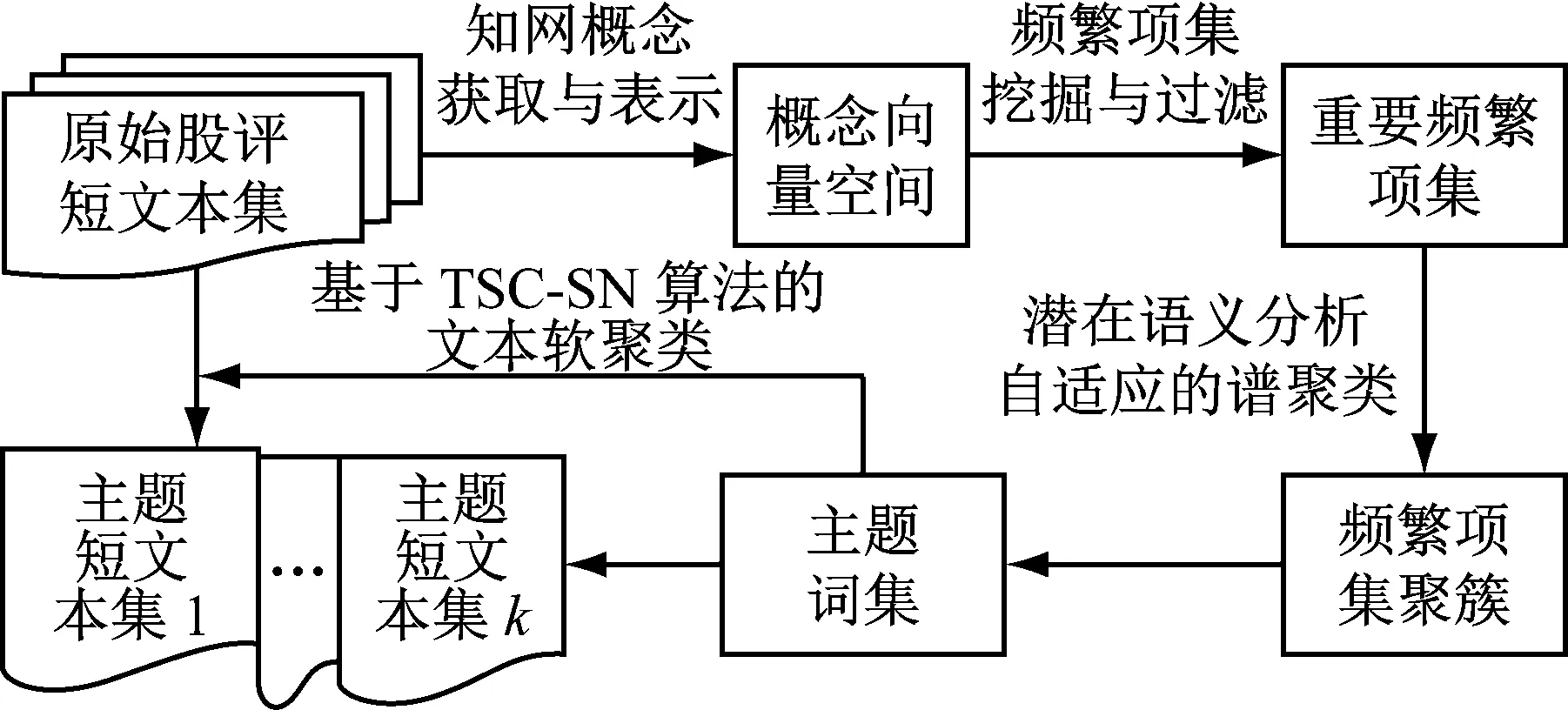
图1 基于频繁项集和潜在语义的短文本聚类基本框架
2.1 概念获取与表示
为了使具有潜在语义关系的词能够表达同一主题,引入语义知识源——知网作为背景知识库来加强语义间关联,在关键词向量空间中,将关键词映射至知识库中的某个概念,以概念来代替关键词特征项,在更高的概念层面上实现文本相似度度量,从而使同一主题的文本更容易聚集在一起.
2.1.1词义消岐
当某个语义场与文本中的语境相符时,语义场中的词也有可能出现在文本中,可通过对比文本中的词和语义场中的词来实现语义消岐.通过计算各语义场中词在文本中的重要程度来选取概念定义式(DEF),采用语义场密度进行度量,表现为语义场中词在文本中出现的频率之和.对于一个多义词w,其第i个DEF的语义场密度定义如下所示:
式中:tj表示第i个语义场中第j个词;f(tj)表示多义词w的语义场中第j个词在文本中出现的频率;qi为第i个语义场中所有词的个数.语义场密度越大,语义场中的词对文本就越重要,针对词义消歧的DEF由下式确定:
2.1.2义原抽取
由知网的概念层次树特点可知,义原在概念树中的层次越深,所表达的含义就越具体,其描述能力就越强[23].可以认为,义原离概念树根节点越远,同时下位义原个数越少,该义原的描述能力就越强.义原权值计算如下所示:
式中:W(ZDEF,wj)为DEF中第j个义原ZDEF,wj的权值;Wtree为所在概念树的权重;droot,j为义原j在概念树中的层次;mj为义原j的下位义原数;a、b、c为控制权值W(ZDEF,wj)取值的因子.最终,义原的选取由下式确定:
2.1.3概念向量空间构建
在对文本、关键词进行概念抽取后,即可构建基于概念的向量空间.假设分词和预处理后的文本d={t1,f1(d), …,ti,fi(d), …,tn,fn(d)},ti表示文本d中的第i个关键词,fi(d)表示文本d中ti的词频,概念向量空间表示的生成算法如图2所示.
2.2 基于潜在语义分析的频繁项集聚类
针对所构建的概念向量空间,利用频繁模式增长(FP-growth)算法进行频繁项集挖掘,但得到的频繁项集存在冗余度高的问题.为此,采用相似度过滤获取重要频繁项集.首先剔除所有频繁项集的子集,然后对剩余频繁项集计算相似度.将频繁项集相似度定义为Jaccard系数形式,如下所示:
式中:Ii表示频繁项集i;J(Ii,Ij)表示Ii与Ij的

输入:文本d的关键词向量空间Vt(d)= (t1, f1(d), …, ti, fi(d), …, tn, fn(d)),阈值为θwhile d≠Ø且i≤n从d中依次取出关键词ti;判断关键词ti在知网中是否存在;if ti为未登录词if fi(d)<θ去除;else ti的概念zi={ti},并将概念zi和词频fi(d)加到概念向量空间Vc(d)中;else 查询知网,获取ti的概念if ti只有一个DEF定义计算每个义原的权值W(ZDEF,wj),选择权值最大者作为ti的概念zi,并统计zi频率,将zi加入至概念向量空间Vc(d)中;else 通过词义消岐选择ti的语义场密度最大的DEF,再选择其中权值最大的义原计算频率,作为ti的向量加入至概念向量空间Vc(d)中;i=i+1;endreturn 文本d的概念向量空间Vc(d)= {z1, f1(d), …, zi, fi(d), …, zk, fk(d)}
图2 概念向量空间表示的生成算法
Fig.2 Generation algorithms for conceptual vectorspace representation
Jaccard系数;|Ii∩Ij|表示Ii与Ij的交集元素个数;|Ii∪Ij|表示Ii与Ij的并集元素个数.若频繁项集相似度大于设定值,则剔除,否则保留.将每一频繁项集作为一个检索词串,从文本中查询出相关文本集合.因此,两个频繁项集间的相似度计算就可由其相关文本集间相似度来替代,如下所示:
(1)
式中:Di和Dj分别为包含频繁项集Ii和Ij的文本集;gi为频繁项集Ii中词的个数;Wj为每个词的权重;fjk为词tj在文本dk中出现的次数.设ζ为频繁项集与文本间最小相似度,当Sim1(Ii,dk)≥ζ时,将文本dk划分至频繁项集Ii的相关文本集Di中.由此,即可得到频繁项集相似度较高的文本集.
2.2.1文本潜在语义分析
潜在语义分析(LSA)是Scott等于1990年提出的一种索引与检索方法[7].基于该方法的表示过程为矩阵奇异值分解(SVD)与降维,具体步骤如下所示:
(1) 分析文档集,建立词-帖子矩阵.假设帖子数量为n,涵盖m个词,Xm×n=(Xij)=(c1,c2, …,cn),Xij表示词i在帖子j中出现的频数.
(2) 运用SVD将Xm×n分解为三个矩阵的乘积,Xm×n=USVT.其中,U和V分别为m×m与n×n的正交矩阵,S为对角矩阵,S的非零对角元素δi(i=1, 2, …,r)为矩阵Xm×n的奇异值,r为非零对角元素的个数.
(3) 对SVD后的矩阵进行降维,剔除较小奇异值.计算得到原矩阵的相似矩阵X′,构建潜在语义空间,将文档向量与查询向量映射至一个子空间,该空间中来自文档矩阵的语义关系被保留,从而计算出帖子间的相似度.
2.2.2文本语义相关度度量
为充分考虑自然语言中所蕴涵的语义问题,提出将语义和统计相结合的文本语义相关度度量方法.在考察频繁项集相关的文本集间相关度时采用以下两种计算方式:基于Jaccard系数和基于SVD相似矩阵.基于Jaccard系数和基于SVD相似矩阵计算式如下所示:
(2)
式中:ci为文本集Di中所有文本合并生成的长向量;xir(r=1,2,…,R)为ci中的元素;Sim2(Di,Dj)和Sim3(Di,Dj)分别为基于Jaccard系数和基于SVD相似矩阵的潜在语义分析所计算的文本集语义相关度;Seqcom(*, *)为最终文本集之间的语义相关度.设η为文本集之间Jaccard系数最小语义相关度,ω为文本集间的潜在语义最小相似度,则Seqcom(*, *)计算按照以下策略进行:
步骤1计算度量文本集Di和Dj间语义相关度的Jaccard系数.若J(Di,Dj)≥η,则Di和Dj语义相关,否则执行步骤2.
步骤2计算相关文本集Di和Dj间的潜在语义相关度cos(ci,cj),若cos(ci,cj)≥ω,则Di和Dj语义相关,否则两者不相关.
2.2.3基于潜在语义分析的聚类
字符较多的频繁项集表达完整且明确的主题,利用较长频繁项集进行聚类所得到聚类数可作为总体频繁项集V的初始聚类数.选取较长频繁项集集合I*={vi|vi∈V, |vi|>2},设定初始簇C1={v1|v1∈I*},初始簇集C={C1},初始簇数目K=1,则对∀vi∈I*,依次比较vi与当前所有簇Ck∈C间的相似度.对较长频繁项集聚类后将簇按大小排序,依次累计簇的元素个数,直至累计之和大于集合I*长度的80%为止,此时已累计簇的数量即为预估的聚类数K.为此,频繁项集与簇间的相似度计算如下所示:
对任一频繁项集vi与簇Ck间的相似度,可利用vi与Ck中所有频繁项集的平均相似度来计算.
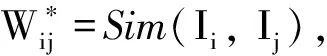

输入:重要频繁项集集合V′={vi|vi=Ii, i=1, 2, …, N},用于挖掘频繁项集的文本集D∗={dj|j=1, 2, …, M},词权重集W={Wp|p=1, 2, …, P},参数η、ω、ζ以及簇与频繁项集间最小相似度γ初始化:初始化每个频繁项集vi的相关文本集Di=Ø,∀vi∈V′, dj∈D∗,根据式(1)计算Sim1(vi, dj);if Sim1(vi, dj)≥ζ将dj加入至vi的相关文本集Di中;建立相似度矩阵X∗,元素Wij由式(2)中的Sim2(Di, Dj)和Sim3(Di, Dj)比较得到;if Sim2(Di, Dj)=J(Di, Dj)≥ηWij=Sim2(Di, Dj);else if Sim3(Di, Dj)=cos(c1, c2)≥ωWij=Sim3(Di, Dj);else Wij=min{Sim2(Di, Dj), Sim3(Di, Dj)};endreturn 相似度矩阵X∗;预估的聚类数K按照谱聚类算法对频繁项集进行聚类
图3 基于频繁项集和潜在语义的聚类算法
Fig.3 Clustering algorithm based on frequent item-sets and latent semantics
2.3 基于TSC-SN的文本软聚类
基于主题簇的主题词抽取,主要从词性、词频、词的簇内支持度以及词的簇间区分度综合考虑.有关词tki的主题词分值计算式如下所示:
式中:fi为词tki在高质量文本集中出现的频率;Sk(i)为簇Ck中包含词tki的频繁项集的个数;IKey为重要频繁项集集合;|Ii| (Ii∈IKey)为包含词tki的频繁项集个数;|Ci|为包含词tki的聚类数;|C|为总聚类数;W(i)为词tki的词性权重.
短文本聚类可看作在主题词基础上进行信息检索,寻找出与短文本di(di∈D)相似度较大的聚簇Ck(Ck∈C),簇与短文本相似度度量依据式(1)计算.TSC-SN算法允许同一文本划分至多个主题.设文本与聚簇间的相似度阈值为λ,簇间非重叠度参数pnol的临界值为δ.主题词集Tk与短文本di间的相似度Sim1(Tk,di)>λ时,将文本划分至相似度大于λ的若干个聚簇中,实现文本与主题间一对多的对应关联.pnol的计算式如下所示:
式中:N为文本总数;|Cij|为初始簇Ci经过第j次文本划分后所包含的文本数;K′为主题簇个数.基于TSC-SN算法的文本软聚类算法的具体步骤如下所示:
步骤1计算短文本di∈D与簇Ck∈C的主题词Tk={tk1,tk2, …,tks}间的相似度,将短文本di划分到相似度最大的簇,即argmax(Sim1(Tk,di)).
步骤2降低相似度阈值θ,θ∈[0, 1],可从1开始逐渐下调.选定θ后将Sim1(Tk,di)>θ时的文本划分至相似度大于θ的若干簇中.
步骤3计算在选定θ下的pnol,若pnol≤δ,则聚类结束.
步骤4重复步骤2和步骤3,直至pnol≤δ.
在对主题词相关的文本进行检索时,控制短文本与主题簇之间的θ,不断降低θ,计算每次降低后的总体文本pnol,直到满足pnol≤δ为止.由此,既可控制总体文本重叠度,又可实现文本软划分.
3 实验分析
实验数据来源于新浪财经股吧论坛,涵盖2015年5月至2015年12月期间与七个股市热点事件相关的64 286条评论数据,日均股评发帖量262条.该期间内国内股市行情波动较大,经历比较明显的上涨和下跌,并且引发股民热烈讨论,有利于论坛中多样化主题和热点的挖掘.基于在线股评数据,根据知网中所蕴含的概念上下位关系,知网中的义原共构成“事件树”、“实体树”、“专有名词树”、“属性树”、“次特征树”等九棵概念树.鉴于名词与动词更能体现文本的语义内涵,赋予“实体树”和“事件树”更高的权重,分别设置为1.00和0.25.“次特征树”中“领域”分支下的义原能加强文本的主题区分度,将其权重设置为0.15.“专有名词树”主要涵盖国家名称义原,但这些词本身已是不可再分的语义单位,因此这类义原不参与概念抽取,将其权重设为0.其他概念树中所包含的概念对文本类别区分的贡献都比较小,相应权重均设置为0.1.针对义原权值W(ZDEF,wi)计算中所涉及的三个参数a、b、c,分别设置为1.50、5.00和0.15.经过文本预处理后所得到的关键词数为46 382,特征空间的概念数为19 075,特征空间维度缩减58.9%,有效缓解概念向量空间表示中所存在的高维度问题.
3.1 重要参数设置
3.1.1重要频繁项集数的参数分析
为通过频繁项集过滤策略获得比较完整与冗余性低的重要频繁项集集合,特别分析最小支持度min_sup和频繁项集间的Jaccard系数最大相似度α与重要频繁项集个数的关系,分别设置α的不同取值,观测每个取值下过滤后的重要频繁项集数与最小支持度min_sup之间的变化规律,如图4所示.
由图4可知,在α的不同设置中,过滤后的频繁项集占频繁项集总数的百分比均不超过20%,有利于提高频繁项集聚类的效率.为挖掘出更多的频繁项集,这里将min_sup设置较低,由此可得到大量包含主题信息的频繁项集,再通过过滤策略得到高质量的重要频繁项集.过滤策略的方法复杂度低,不会增加过多的时间消耗.α设置越高,过滤后的重要频繁项集所占百分比越高.当α取值为0.4与0.5时,重要频繁项集的百分比相差较小;当α取值为0.6时,重要频繁项集的百分比显著增大.这主要是因为基于FP-growth算法挖掘获取的频繁项集中包含大量3-项集.当α取值为0.4或0.5时,两个3-项集中若有两个重叠项,则被过滤掉;当α取值为0.6时,两个3-项集都会被保留.这说明α取值为0.6是不合理的,会造成大量冗余频繁项集未被过滤.另外,过滤后频繁项集的比例与min_sup成反比关系,这是因为min_sup越高就会产生越多的1-项集和2-项集,这些项集几乎是其他频繁项集的子集,很容易被过滤掉,使得重要频繁项集的比例降低.

图4 过滤后频繁项集所占百分比与最小支持度的关系
Fig.4 Relationship between frequent item-sets proportion and minimum support degree after filtering
3.1.2聚类数的参数分析
为进一步分析min_sup与α、频繁项集与频繁项集簇间最小相似度β对预估聚类数的影响,选取min_sup∈{20, 25, 30, 40, 50, 60}、α∈{0.4, 0.5, 0.6}以及β∈{0.2, 0.4, 0.6}时来预估聚类数,实验结果如表1所示.

表1 针对不同参数的预估聚类数比较
由表1可知,聚类数随着min_sup和α的增加而逐渐减小,主要因为min_sup增加时一些话题无法产生较长频繁项集,在预估聚类数时直接将其忽略.另外,当α增加时,新增加的频繁项集往往被分配到规模较大的前几个频繁项集簇中,而在估计聚类数时选择频繁项集累计总数占总频繁项集数80%以上的簇个数作为聚类数.因此,当更多频繁项集划入较大规模的簇中时,聚类数会减少.此外,β对预估聚类数影响较大.当β设置为0.2或0.4时,针对α和min_sup的不同设置,聚类数相近并且比较稳健.当β设置为0.6时,原来比较相似的簇会被划分成更小的簇,聚类数也明显增多.
综合上述分析,考虑效率与准确性的平衡,设定min_sup=25、α=0.6以及β=0.4.
3.2 文本软聚类性能评估
3.2.1主题词提取
将名词、动词与形容词的权重分别设定为1.00、0.25和0.15,按前文方法对主题词簇中每个词打分后,选择排序在前τ位的词为该簇主题词,这里设定τ=4.针对聚类数K不同设置的各事件主题词提取结果如表2所示.
由表2可知:当聚类数K=7时,股市暴跌这一事件分裂为两个子主题,一类讨论股市暴跌时国家是否会及时出台救市政策,另一类讨论暴跌所带来的恐慌情绪与投资者信心受挫,通过股吧论坛原文数据分析可发现,对于股市暴跌这一事件的讨论词区分度较大,一定程度上说明股市暴跌时投资者情绪波动较大,意见分歧明显;当聚类数K=8时,救市事件也被分裂为两个子主题,一类讨论国家出台相关救市政策及影响,另一类讨论为防止大盘崩盘央行紧急制定各种政策;当聚类数K=6时,这些分裂簇会消失,其他簇则几乎不变.这说明本文所选取的聚类方法在主题抽取方面比较稳定且准确.
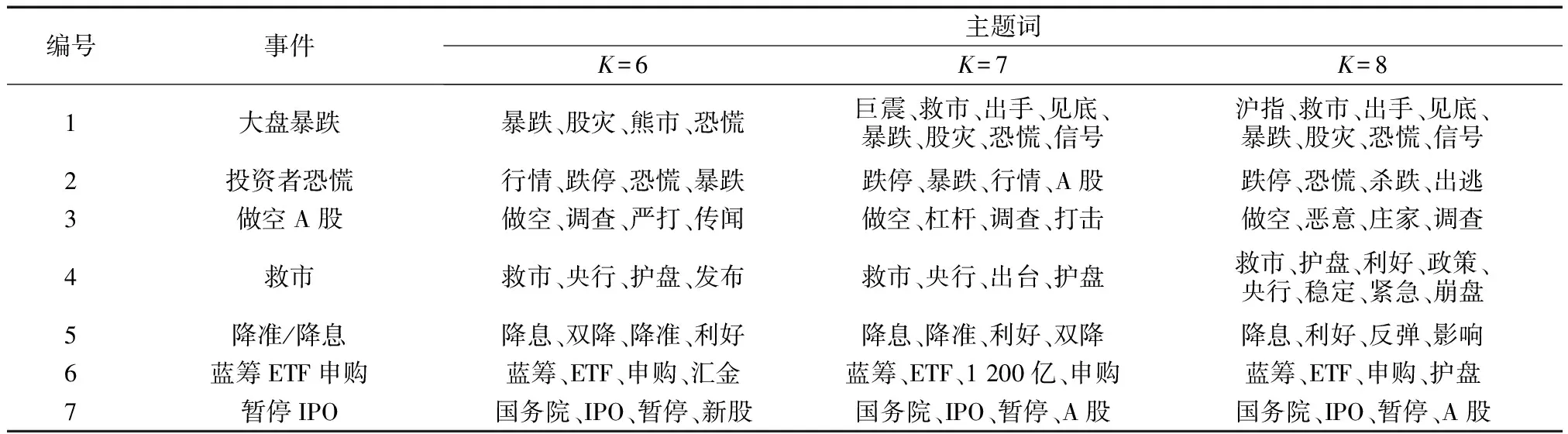
表2 针对聚类数K不同设置的各事件主题词提取结果
注:ETF为交易型开放式指数基金; IPO为首次公开募股.
3.2.2文本聚类
通过计算文本与频繁项集簇中主题词之间的相似度,将文本划分至相似度最高的主题词簇下,围绕2015年股市大幅下跌前后的评论数据进行文本聚类,部分聚类结果如图5所示.

图5 基于频繁项集的短文本聚类部分结果
首先根据argmax(Sim1(Tk,di))将短文本di划分至相似度最大的簇中,此时pnol=1,对应图5中第一次聚类结果;若设定δ=0.8,则降低θ(θ∈[0, 1]).选定θ=0.6,将符合Sim1(Tk,di)>0.6的文本划分至相似度大于0.6的若干簇中,对应图5中第二次聚类结果,此时再次计算θ=0.6下的pnol(0.916).因pnol>δ,需重复调低θ值,将文本进行软划分之后再计算pnol.随着θ值增大,pnol呈现缓慢上升趋势,这是因为聚类文本长度较短,大部分仅表达一个主题,少数文本与多个主题簇之间相似度均较高.有关pnol随文本与θ变化情况,如图6所示.
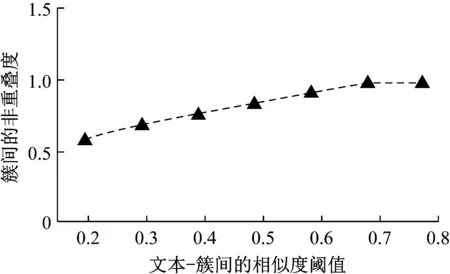
图6 聚类簇间非重叠度与文本-簇相似度阈值关系
Fig.6 Relationship between non-overlapping degree of clusters and text-cluster similarity threshold
通过重复对θ进行取值与文本软划分,发现将θ取值为0.4时所计算出的pnol=0.762,满足终止条件pnol<δ=0.8.
3.3 整体性能对比分析
针对频繁项集聚类效果的评估,选择聚类后簇内平均紧密度c与簇间平均分离度s作为比较对象,计算式如下所示:
式中:uk为聚类簇Ck的中心向量;ui与uj分别为不同聚类簇的中心向量;l为欧氏距离.高质量的聚类算法应具有低簇内紧密度和高簇间分离度.整体性能评估采用涵盖准确率、召回率及F值,F值为准确率与召回率的加权平均.考虑到当α∈{0.4, 0.6}与β∈{0.2, 0.4}时,所估计的聚类数集中分布在{6, 7, 8},因此将聚类数K值设置为6、7、8.
3.3.1频繁项集聚类性能对比分析
为验证基于知网获取概念向量空间TSC-SN算法的性能,选取基于关键词向量空间的V_SC谱聚类算法、V_K-means算法、V_TSC-SN算法进行比较.因四种聚类算法并非都在欧氏空间进行聚类,无法直接比较算法的簇内平均紧密度c与簇间平均分离度s,因而选择比值c/s作为评价指标.四种算法的参数设置均相同,对比结果如表3所示.

表3 四种聚类算法的性能对比
由表3可知,针对不同聚类数,TSC-SN算法和V_TSC-SN算法的c/s值小于V_SC与V_K-means算法,相比于基于欧氏空间的距离度量法,TSC-SN算法的频繁项集聚类效果更优.TSC-SN算法的c/s值也小于V_TSC-SN算法,说明基于知网获取概念向量空间的聚类结果优于基于关键词向量空间的聚类结果,验证了本文算法的有效性.
3.3.2主题发现性能对比分析
为评估本文算法所获取的主题类别效果,计算出相应的最大F值,如表4所示.
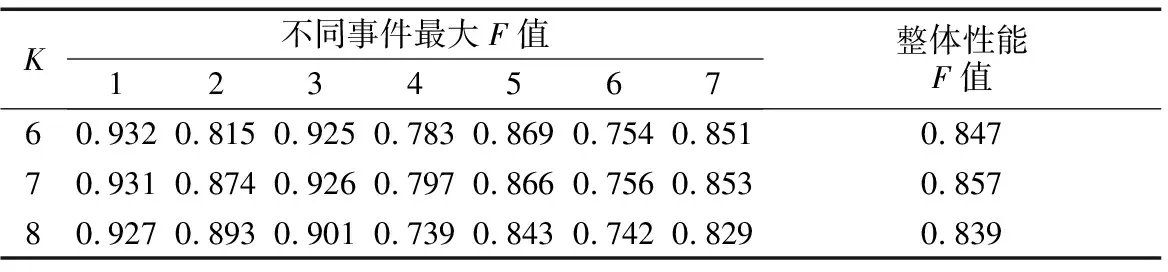
表4 不同事件的文本聚类整体性能
由表4可知,在本文所提出的基于频繁项集和潜在语义相结合的论坛主题发现算法框架下,不同事件的最大F值整体上均较高.当K为7时,大部分事件的最大F值优于K取6与8时的情况.另外,K为6与7时,不同事件的最大F值相差较小,因为“大盘暴跌”和“投资者恐慌”这两个主题经常同时出现,文本软划分时这两个主题簇重叠度较高.
为进一步验证本文算法在基于文本聚类的主题发现上的整体性能,选取基于关键词向量空间的V_EM算法、V_K-means算法、V_TSC-SN算法以及基于概念向量空间但未考虑潜在语义的C_TSC-SN算法进行比较,结果如图7所示.
由图7可知,TSC-SN算法的整体性能最优,F值最大.V_EM和V_K-means算法的整体性能F值均低于其他三种算法.这主要是因为大部分文本较短,从而造成向量空间的稀疏性,使得仅从欧氏距离度量相似度比较低效,由此得到聚类中心向量所表达的主题不集中,聚类结果不理想.TSC-SN算法与V_TSC-SN算法相比,前者略优于后者,两种算法效果优于C_TSC-SN算法,说明结合潜在语义进行相似度分析后所得到的主题簇更为全面.

图7 不同聚类算法F值对比
Fig.7 Comparison ofF-measure values among different clusting algorithms
3.3.3时间性能对比分析
为验证TSC-SN算法的时间性能,选取基于概念向量空间的C_K-means算法、V_SC算法进行比较,实验结果如图8所示.
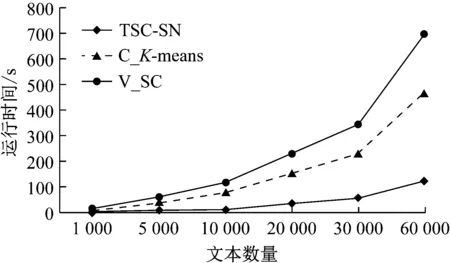
图8 不同聚类算法时间性能对比
由图8可知,TSC-SN算法在时间性能上表现最优,并且随着文本数量的增加运行时间增加较为缓慢.比较TSC-SN和V_SC的运行时间可见,基于知网获取概念向量空间后可有效缓解短文本高维度问题,降低算法运行时间.
4 结语
针对股评论坛主题发现问题,提出利用频繁项集和潜在语义相结合的框架从在线股评抽取主题词,使用TSC-SN算法基于主题词进行文本检索以实现文本软聚类,进而获取股评论坛相关文本的主题.实验结果表明,该方法具有明显优势.利用潜在语义信息与多层次聚类优化策略,是提高大规模短文本聚类效果以获取文本主题的有效方式.未来研究将进一步拓展目前的整体框架与文本情感倾向性分析的融合,考虑短文本中修饰词、专有词项的词法层检测和语义层分析,充分利用短文本中的多样性信息,延伸更为深层次的主题发现与情感获取.
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
实用医药杂志(2021年4期)2021-01-11
中国医学计算机成像杂志(2020年6期)2020-03-14
时代英语·高二(2018年7期)2018-12-03
计算机与数字工程(2018年10期)2018-10-23
时代英语·高二(2018年3期)2018-06-06
计算机与数字工程(2017年2期)2017-03-02
档案管理(2014年6期)2014-10-30
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
