
用于牛奶分析的中红外光谱标准化及其在模型传递中的作用
2019-05-17 08:53刘锐梁秋曼南良康阮健陈焱森李丽丽丁芳陈绍祜闫青霞张淑君
中国奶牛 2019年4期
刘锐,梁秋曼,南良康,阮健,陈焱森,李丽丽,丁芳,陈绍祜,闫青霞,张淑君
(1.华中农业大学,农业动物遗传育种与繁殖教育部实验室,武汉 430070;2.全国畜牧总站,北京 100125;3.中国奶业协会,北京 100193)
近年来,越来越多的研究表明采用傅里叶变换中红外光谱(FT-MIRS)技术,通过建立相应的预测模型,可以对牛奶及乳制品中的各种成分(如蛋白质、脂肪、乳糖和无机盐等营养物质,各种添加剂、抗生素等可能的有害物质)进行简便、快速、实时和准确地定量分析,甚至能够快速准确地分析和鉴定奶牛的营养水平(如饲料转化率、能量利用率和甲烷排放情况等)、健康状况(如酮病和乳房炎等)和生殖生理与繁殖状况(如发情、妊娠和泌乳情况等)[1]。
开发一个稳定可靠的中红外光谱校准模型往往需要收集大量的校准样本,耗费大量的时间、成本和精力。然而当校准样本的测量和用于预测的新样本的测量之间出现仪器响应信号的变化时,这样一个复杂的校准模型将不再适用。主要分为两种情况,第一种是校准过程中的仪器响应不同于预测过程中的仪器响应,即一台仪器(称为主机,master)上建立的模型不能直接应用于另一台仪器(称为从机,slave),这是由于不同仪器得到的光谱信号存在差异;当单个仪器由于老化或关键部位零件修复更替出现仪器响应变化时,原有的模型同样不再适用。第二种情况是校准和预测过程的测量样本之间的物理变化。例如,如果校准过程中测量样本的温度与预测过程中测量样本的温度不相同,则利用在预测过程中收集的中红外光谱获得的预测将是错误的。当从校准步骤到预测步骤的其他物理参数(例如粒度)变化时也会出现类似的问题[2]。
无论出现何种情况,都需要重新校准模型。为了避免这种耗时的重新校准过程,光谱标准化则是一种很好的解决方案。标准化程序有两种,一种是基于少量标准化样品,建立主机与从机所测光谱之间的函数关系,变换从机所测光谱来实现模型传递,主要包括直接标准化(direct standardlization,DS)、分段直接标准化(picecwise direct standardlization,PDS)、专利算法等;另一种则是不需要通过标准化样品在不同仪器上对所测光谱进行比较的方法,如光谱归一化处理等。
1 中红外光谱技术简介
红外线是波长介于可见光和微波之间的一段电磁波,所以红外光谱位于可见光区和微波光区之间,红外光谱属于吸收光谱,是由于化合物分子振动时吸收特定波长的红外光而产生的。中红外(MIR)光区是一段波长在2.5~25.00µm之间的光波,能够很好地反映分子内部所进行的各种物理过程和分子结构方面的特征,是绝大多数有机物和无机离子的基频吸收带。中红外光谱波段中的低频区域为指纹区,包含了大部分基团的弯曲振动,能级差小,光谱波带密集,且光谱波带的性质与化合物及其聚合态有着一一对应的关系,可以通过该波段的光谱精确辨认样品中的特征官能团(图1),从而推断出样品所含化合物。指纹区以外的中红外光谱为特征吸收带,只有折合质量和键力常数大的基团的吸收峰才会出现在这个波段,吸收峰较少,容易辨认[3]。根据不同物质红外特征吸收峰的位置、数目、强度和峰宽等参数,就可以判断样品中存在的基团,从而确定其分子结构,用于化合物的定性分析,也可根据朗伯-比耳定律进行定量分析:通过对样本特征吸收谱带强度的测定来测定组分的含量。其分析方法的主要步骤如下:
(1)选择有代表性的样本做校准集,测定其MIR数据;
(2)采用标准或者广泛认可的参考方法测定校正集样本的化学分析值;
(3)利用校正集光谱及其化学分析数据,采用合理的化学计量学方法建立校准模型;
(4) 利用验证集样本光谱和参考方法得到的数据来验证校准模型的准确度,选择最优校正模型;
(5)模型确立后,通过样品的光谱数据来预测其组成和含量。

图1 MIR光谱特征官能团示意图[4]
正是由于建立模型的方法非常复杂耗时,尤其是MIR光谱和牛奶成分化学分析值(参考值)的获得尤其困难,往往需要耗费大量的时间和费用,建立标准化体系以推广主机模型的应用才显得尤为重要。
2 标准化
欧盟自2011年起就开始了中红外光谱标准化体系的研究,多年来标准化网络不断发展,至2015年,已经在欧洲、北美、亚洲和大洋洲的14个国家的100多台不同品牌的仪器进行了标准化。研究证明了采用分段直接标准化(PDS)算法,可以将高质量的模型转移到网络中的其他仪器上,并且取得了良好的效果[5]。我国也于2011年成立了全国首家DHI标准化物质制备实验室,用于制备牛奶的标准化样品,使牛奶成分分析更方便。由于目前欧盟和我国标准化网络的建立都是基于标准化样品进行标准化程序,所以这里主要介绍基于标准化样品进行标准化的方法。
基于标准化样品进行标准化的程序分为两个步骤。第一步是在校准和预测过程中精心挑选一部分样品进行测量,以评估校准和预测过程的差异,也就是标准化样品的选择;第二步则是利用标准化样品来计算标准化方法的参数。标准化样品的选择和标准化参数的计算必须仔细研究,以获得最佳的标准化效果[2]。
2.1 标准化样品
标准化样品将在校准和预测过程中测量,以估计样品的物理状态或仪器响应之间的差异。所以标准化样品的选择至关重要,直接影响标准化的效果。
2.1.1 标准化样品的选择标准
为了正确估计校准和预测过程之间的差异,必须着重考虑两点,即作为标准化样品的样品稳定性和代表性。
稳定性即标准化样品必须在物理和化学上稳定,否则在校准和预测过程之间会发生标准化样品的物理状态或化学成分变化,此时,所收集的光谱之间的差异既可归因于仪器差异,也可归因于这些物理化学变化所导致的光谱差异。如果这种由于标准化样品的不稳定性而导致差异的光谱被用于计算标准化参数,则这些标准化参数的使用将不能得到好的效果。代表性即标准化样品必须使计算的标准化参数足够纠正仪器响应的差异,则这些差异是从标准化样品上估计的,如果标准化样品缺乏代表性,则新的预测样品进行标准化后将会得到不理想的结果。
2.1.2 不同来源的标准化样品
2.1.2.1 从校准集合中选择标准化样品
该方法从校准过程中收集的大量校准样品中选择一些标准化样品,然后在预测过程中重新测量该标准化样品。
建议使用基于逐步选择的Kennard&Stone(K/S)算法,该方法旨在使新选择的样品与已经包括在标准化子集中的样品之间的距离最大化(一般使用欧氏距离)。K/S算法的步骤:
(1)首先计算所有样品两两间的距离,选择距离最大的两个作为第一个和第二个标准化子集样品;
(2)然后计算每个剩余样品与已选样品之间的距离,选择其中的最短距离;待所有的剩余样品计算过后,选择这些最短距离中的最长距离所对应的样品作为下一个子集样品;
(3)重复步骤(2),直至所选的标准化子集样品的个数等于事先确定的数目为止[6]。
Bouveresse和Massart证明,能得到覆盖整个实验空间的子集要比基于高利用率的方法好得多,其对所有的预测样本都能产生好的结果。然而,当针对物理和化学状态不稳定的样品(如牛奶等新鲜食品)时,该选择方法不再适用[2]。
2.1.2.2 从预测集合中选择标准化样品
在预测过程中测量的新样品中选择一些作为标准化样品,并在校准过程的条件下(例如在主机上)重新对其进行测量。
这种方法的主要优点是其允许选择具有良好代表性的子集样品,即使校准样品由于其物理或化学不稳定性而不能被存储时也是如此。但如果需要标准化的仪器位置相距很远,对于一些物理化学性质非常不稳定的样本,该方法同样不再适用。2.1.2.3 独立的标准化样品
替诺福韦 (tenofovir)是一种新型核苷酸类逆转录酶抑制剂,抗病毒疗效确切,短期安全性好,妊娠期可以使用,是目前治疗乙型肝炎和获得性免疫缺陷综合征 (AIDS)的主要药物之一。替诺福韦长期使用会引起肾损伤,严重的会出现范可尼综合征 (Fanconic syndrome,FS),影响患者用药的依从性和安全性,从而影响正常的诊疗活动[1]。本研究主要回顾性分析替诺福韦导致肾损伤的特点及其相关因素和预后等,为临床使用提供更多的资料和依据。
该方法主要是通过测量两种仪器上的一组独立样品,来估计仪器响应之间的差异。这种方法的主要优点是可以使用物理和化学上更稳定的标准化样品,如通用标准。然而,使用与校准样品差别太大的标准化样品会因为缺乏代表性而产生不好的结果。
Shenk及其同事在仪器标准化方面对大量的农产品进行了近红外分析[7]。他们建议通过测量密封的或防水杯中包装的干农产品的30种不同混合物来评估仪器响应之间的差异。这些密封的杯子和随附的标准化软件可从Infra Soft International(ISI,Port Mathilda,PA)获得。使用这30个样品(称为Shenk及其同事的特征样品)使得用户能够使用具有良好代表性的各种农产品作为稳定的标准化样品组合。这些标准化样品被Dardenne及其同事用于NIR仪器网络的标准化,得到了令人满意的结果[8,9]。
2.1.3 标准化样品的数量
对要使用的标准化样品的数量必须慎重选择。为了获得关于校准和预测过程之间仪器响应差异的足够的信息,必须使用足够多的标准化样本,否则标准化参数将不能得到良好的效果。但是,使用过多的标准化样本意味着多余的工作。选择适当数量的标准化样品可以在得到较好标准化效果的同时减少多余的工作。标准化样本的使用数量受到两个因素的影响,即仪器差异的复杂性和使用标准化方法的类型。
欧盟使用包括10个脂肪(1%~5%,质量/体积)和蛋白质(2.9%~5%,质量/体积)变化很大的生乳样品,每月发送至每个合作单位进行标准化[4]。
国内使用12个脂肪、蛋白质和乳糖变化很大的生乳样品作为标准化样本,其中脂肪和蛋白质每月标准化一次,乳糖每三个月标准化一次。
2.2 标准化方法
2.2.1 预测Y值的单变量校正

然后将在校准过程中收集的光谱计算得到的预测y值与在预测过程中收集的光谱计算得到的预测y值进行比较,并且通过最小二乘法将单变量偏差或斜率/偏差校正调整到那些点。对于在预测过程中收集的新图谱,预测的y值是通过计算获得的。

然后通过这种偏差或斜率/偏差校正来校正,产生标准化的预测y值Y(PX)std。
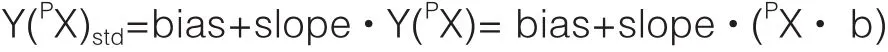
即两个独立的数据集在同一品牌的两个不同的NIR仪器上测量。每个数据集被分成校准和测试集,并在每个仪器上建立校准模型。在第一台仪器上测量的校准集的光谱用在第二台仪器上开发的校准模型预测,计算斜率/偏差校正以校正那些预测值。然后用在第二台仪器上开发的校准模型预测在第一台仪器上测量的测试集合的光谱,并且通过斜率/偏差校正来校正所获得的值[8]。
这种方法的主要优点是只需要一个单变量的修正,简单快捷。但是,如果在校准过程中开发了多个校准模型,则必须对每个校准模型独立应用此方法。此外,当校准和预测过程中的差异比较简单时,这种方法可以使用,但是当校准和预测之间的差异非常复杂时,这种方法也就不再适用。
2.2.2 直接标准化(DS)
Wang等提出的直接标准化(DS)方法是通过一个传递矩阵来实现的[10]。

E包含未建模的残差。
该传递矩阵是方矩阵,并且通过将在预测过程中获得的标准化集合的广义逆乘以在校准步骤中获得的标准化集合来确定。

对于在预测过程中收集的新光谱,通过将这些光谱乘以估计的转移矩阵来简单地实现光谱的转移。

DS方法有两个重要的优点,即它们拥有能够处理复杂的仪器响应差异的多变量特性和使不同分辨率的仪器标准化的能力。然而,DS的主要缺点是在预测过程中收集的全部光谱被用来重构所传输光谱的所有光谱强度值,这可能导致过拟合。此外,应该注意的是,用于DS的标准化样品的数量必须至少与用于校准模型的相关样品的数量一样大,但这在实际应用中可能难以实现。
刘翠玲等使用DS算法对食用油理化指标的近红外光谱定量模型在三组仪器间进行模型转移,较大提高了从机的预测效果[11]。李鸿儒等对DS算法进行了优化改进,并将改进的DS算法用于玉米2种成分和烟草4种成分的近红外光谱预测模型转移,取得了优于标准DS算法的结果[12]。
2.2.3 分段直接标准化(PDS)
标准化样品在主仪器和从仪器上测量,得到响应矩阵M和S。PDS方法基于光谱数据的变化局限于小光谱区域的事实。在PDS中,在主仪器上以波数j测量的响应mj与位于从仪器上测量的围绕j(邻近)的大小为n的小窗口(sj)中的波数有关。窗口(sj)由5个波数组成,所有仪器都是一样的:

使用主成分回归方法的回归计算波数为j的主设备上的每个光谱响应与从设备上的相应窗口sj之间的回归。矢量bj是第j个波数的变换系数矢量,而b0j是偏移项:

F矩阵包含所有波数的bj系数变换向量。这种使用移动光谱窗计算bj参数的方法导致了带状对角矩阵。b0矢量包含所有波数的偏移项。每次在从仪器上测量一个新的样品时,使用F和b0可以将获得的光谱X标准化为Xstd(图2):


图2 PDS算法示意图[4]
PDS算法很好地减少了过拟合的风险,即使标准化样品的数量很少,也能得到很好的效果。欧盟使用PDS算法建立了跨越四大洲十几个国家的标准化网络,并取得了良好的效果[4]。黄承伟等成功地将结合了标准正态变换(standard normal variate,SNV)的PDS算法应用于汽油拉曼光谱模型传递,得到了较好的结果,SNV-PDS方法具有减少标准样品、高精度和传递稳定性好等优点[13]。
2.2.4 其他标准化算法
此外,还有很多标准化算法被开发,如专利算法、SWS算法和基于主成分分析的SST算法等。还有基于拓展光谱(基于少量标准样品将主机上的光谱转移为从机上的光谱)建立的从机校准模型的模型转移方法[14],以及不使用标准样品的标准化算法,如光谱归一化等。
3 总结
随着我国MIR技术的发展,越来越多的模型被研究和应用。标准化程序可以避免耗时的重新校准过程,但也需要建立全新的适用的标准化网络,来整合全国数十家DHI中心得到的光谱数据,以便于管理和资源收集。新的模型能快速适用于所有仪器。
所以,标准化网络对于光谱整合和预测过程是至关重要的,可以让所有的光谱仪讲同一种语言,允许交换和传输可靠的校准模型,预测整个网络中的光谱数据和参数。为了获得最好的标准化效果,我们要慎重考虑标准化样品的选择和标准化方法的确定以及标准化参数的计算。
猜你喜欢
大众标准化(2022年20期)2022-11-07
现代仪器与医疗(2022年4期)2022-10-08
北京航空航天大学学报(2022年8期)2022-08-31
现代仪器与医疗(2022年3期)2022-08-12
现代仪器与医疗(2022年2期)2022-08-11
黑龙江大学自然科学学报(2022年1期)2022-03-29
口腔护理用品工业(2021年4期)2021-11-02
空间科学学报(2021年1期)2021-05-22
党的生活(江苏)(2019年4期)2019-06-26
百科探秘·航空航天(2017年12期)2018-01-31
