
NECP-X的多重并行策略及效率优化
2019-05-17 06:15马党伟刘宙宇张文鑫曹良志吴宏春柴晓明
原子能科学技术 2019年5期
马党伟,刘宙宇,赵 晨,贺 涛,张文鑫,曹良志,吴宏春,柴晓明
(1.中国核动力研究设计院 核反应堆系统设计技术重点实验室,四川 成都 610213;2.西安交通大学 核科学与技术学院,陕西 西安 710049)
NECP-X[1-2]是由西安交通大学核工程计算物理实验室(NECP)自主开发的三维全堆芯高保真输运计算程序系统,通过精确几何处理、自主研发多群数据库、全局-局部共振计算[3]、大规模并行二维/一维输运计算、双重CMFD加速、pin-by-pin物理热工耦合[2]及非均匀全堆瞬态计算[4]实现全堆芯高保真输运计算,获得反应堆全三维精细的稳态和瞬态功率分布。其中输运计算为基于特征线方法(MOC)的二维/一维输运方法。
特征线方法具有强大的几何处理能力,被广泛应用于反应堆物理计算中。然而,当利用特征线方法进行三维全堆芯输运计算时,将面临计算量极大、内存要求极高的挑战。结合当前计算机硬件的发展,大规模并行计算成为重要的解决方法。目前发展中的全堆芯三维输运方法大部分是基于单一变量并行,如能群、空间、角度或特征线,其并行度均较有限,无法充分利用当前最先进的计算机资源,如韩国的CRX-3D[5]仅实现了角度的并行,DeCART[6]实现了轴向分层的并行,中国核动力研究设计院的Tiger-3D程序[7]实现了空间的并行,西安交通大学的TOMMOC基于空间区域分解并行,AutoMOC-3D基于特征线并行等。本文针对NECP-X中二维/一维耦合输运计算方法实现基于空间、角度和特征线的多重并行,并在性能分析的基础上对程序进行效率优化。
1 NECP-X中的并行策略
数值反应堆物理计算程序NECP-X是基于二维/一维耦合方法进行输运计算的,采用二维MOC处理径向精细的几何结构,采用一维SN方法进行轴向计算。考虑到单纯的MOC源迭代收敛速度较慢且计算量较大,NECP-X采用了粗网有限差分(CMFD)[1]和多重并行的方法加速收敛或计算。其中,多重并行不仅可提高计算速度,还可分解内存压力,实现大规模问题的求解。NECP-X中的多重并行包括空间、角度和特征线的并行,多重并行的并行方案如图1所示。
1.1 空间区域分解及效率优化
NECP-X空间区域分解是基于分布式存储的并行编程技术MPI[8]进行设计的,这对于缓解全堆芯问题的内存压力非常重要。NECP-X的空间区域分解通过轴向和径向两次分解实现,如图2所示。对于轴向区域分解,根据轴向层数和拟分轴向区域数,获得每个计算核心的层数,若无法平均分配,则部分计算核心多计算一层。为了负载平衡,建议轴向区域数为轴向层数的约数。对于径向区域分解,提供了两种分解方式:1) 根据径向的模块数和区域数计算每个区域的模块数;2) 由用户人为指定区域分解的方式,这种分解方式具有较大的灵活性,但也给用户的使用带来了难度。用户可根据问题选择合适的分解方式。轴向和径向两次分解确定了所有的三维子区域内的轴向层数和径向模块数。
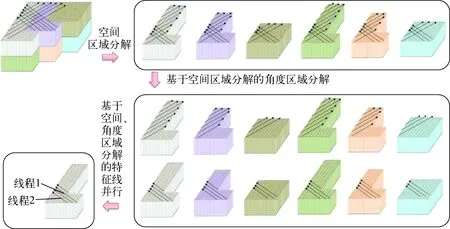
图1 NECP-X的多重并行方案Fig.1 Multilevel parallel scheme of NECP-X
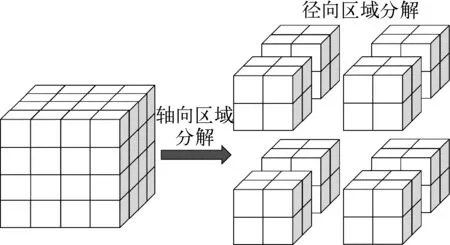
图2 空间区域分解示意图Fig.2 Space decomposition scheme
三维空间区域分解后,每个计算核心负责同一区域内的二维MOC和一维SN计算。此外,每个计算核心仅与相邻区域通信,因此每个计算核心的通信量不随计算核心数线性增长,显著提高了并行扩展性;并通过非阻塞通信减少二维/一维迭代计算过程中的通信等待。所以,空间并行理论上可获得很高的并行效率和极大的并行度。
空间区域分解后,各子空间区域同时求解,从根本上改变了迭代流程,因此与串行计算相比,收敛过程也发生了改变。在空间区域分解中,各子区域在源迭代计算中的初始值均相同,只有在更新内边界条件时,各子区才会进行信息交换。而在串行计算中,对于二维MOC计算,当前模块的初始通量值是由相邻的已计算模块的出射通量值传递而来的,即串行计算时通量更新较为及时。故空间区域分解的迭代格式相对于串行计算会有退化。
1.2 角度并行和特征线并行简介
角度区域分解是针对特征线方法和SN方法中的角度变量实施的并行策略,可在整个二维/一维输运计算中对角度进行并行,实现一维计算和二维计算的并行度匹配。由于各角度的特征线段数不同,采用贪婪算法[9]的分配策略实现更好的角度区域分解负载平衡,如图3所示。图中不同矩形的面积代表不同角度的特征线段数量。

图3 角度区域分解的贪婪算法Fig.3 Greedy algorithm for angle decomposition
特征线并行是对MOC计算的核心计算部分(特征线扫描部分)进行的并行加速处理,通过基于共享内存的编译处理方案OpenMP[10]实现。在单纯的特征线方法中,特征线的扫描部分会占到总计算时间的90%以上[11],所以针对特征线扫描进行加速很有必要。角度并行和特征线并行的实现详见文献[11]。
1.3 特征线并行的效率分析及优化
三维输运计算时,程序早期的数值结果表明特征线并行的并行效率随线程数的增加下降较快,如图4所示,10个线程并行时并行效率已低于60%。为此本文针对特征线并行部分进行分析与优化。
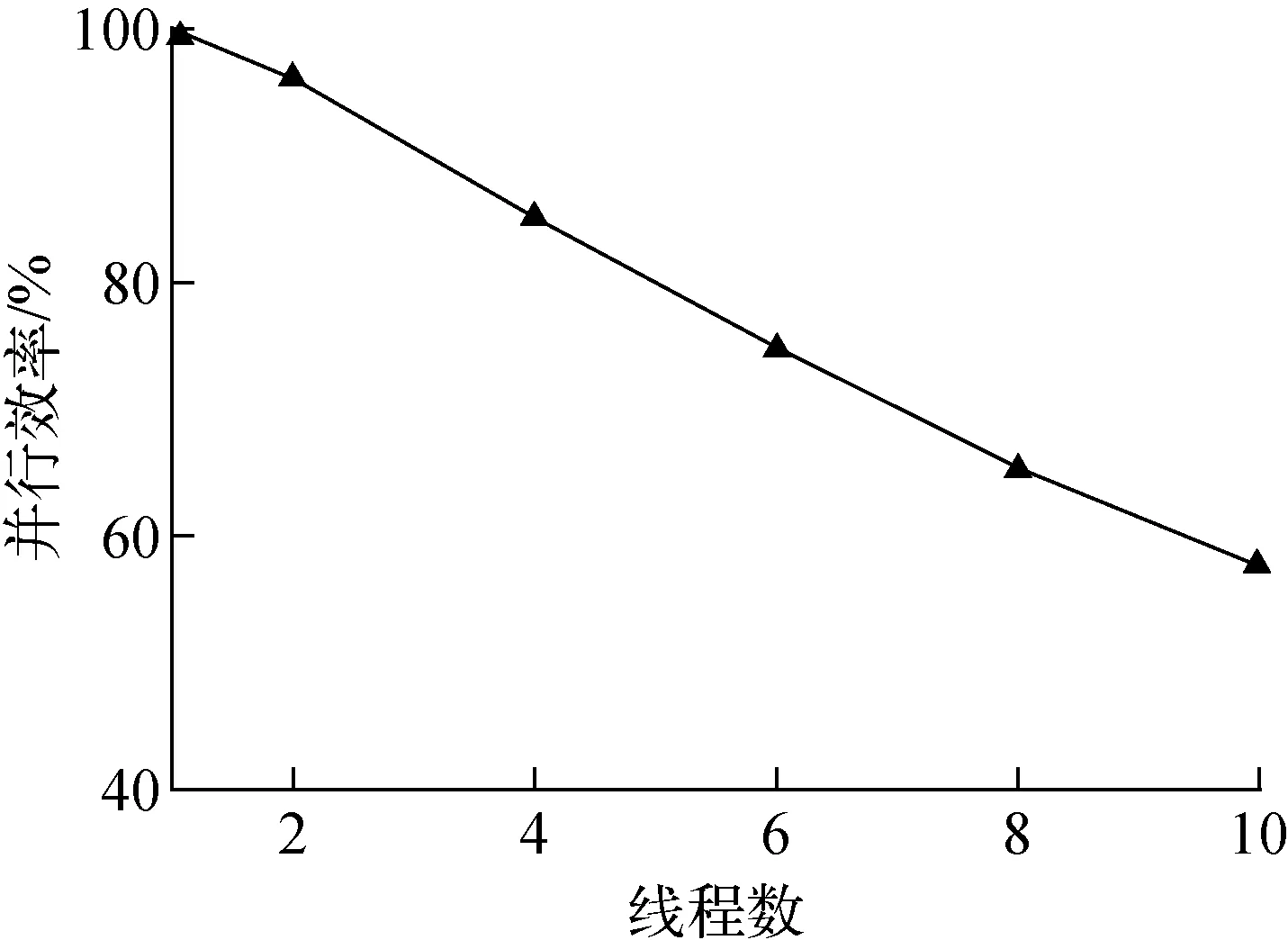
图4 特征线并行效率Fig.4 Efficiency of characteristic ray parallel
特征线扫描部分的伪代码如下:
1:do i_sweep=1,n_sweep #内迭代循环开始
2:do iang=stt_ang,stp_ang #幅角循环开始
3:calculate source item #源项计算
4:do iray=1,n_ray #特征线扫描计算循环开始
5:calculate fluxes #特征线扫描计算
6:end do #特征线扫描计算循环结束
7:tally angular flux #统计角通量
8:tally current & leakage #流与泄漏项计算
9:calculate scalar flux #标通量计算,线程归约
10:end do #幅角循环结束
11:update boundary condition #更新边界条件
12:end do #内迭代循环结束
图5为串行计算特征线扫描各部分的时间比例,其中蓝色为特征线扫描计算,红色为源项计算。可明显看出,特征线扫描计算约占总时间的90%以上。特征线并行通过在该部分添加OpenMP的编译制导语句实现多线程的动态任务分配。

图5 串行计算的时间分布Fig.5 Time distribution of serial calculation
通过敏感性分析,并行起始区间为内迭代循环开始处。在此条件下,研究特征线并行的负载平衡、通信开销等问题。本研究利用TAU(tuning and analysis utilities)[12]和PAPI(performance application programming interface)库[13]统计并行化后的特征线扫描部分每段的计算时间,特征线并行的弱可扩展性[14]测试表明,随线程数的增加,特征线扫描计算的并行效率一直保持在94%以上,由于采用了动态调度的分配方案,10个线程依然保持着良好的负载平衡,如图6所示,图中左侧数据为每个线程的特征线扫描计算时间。然而,非并行部分(如源项计算、标通量计算等)计算时间理论上应随线程数线性增加,测试结果(表1)却显示为超线性增加,因而造成了整体并行效率的急剧下降。
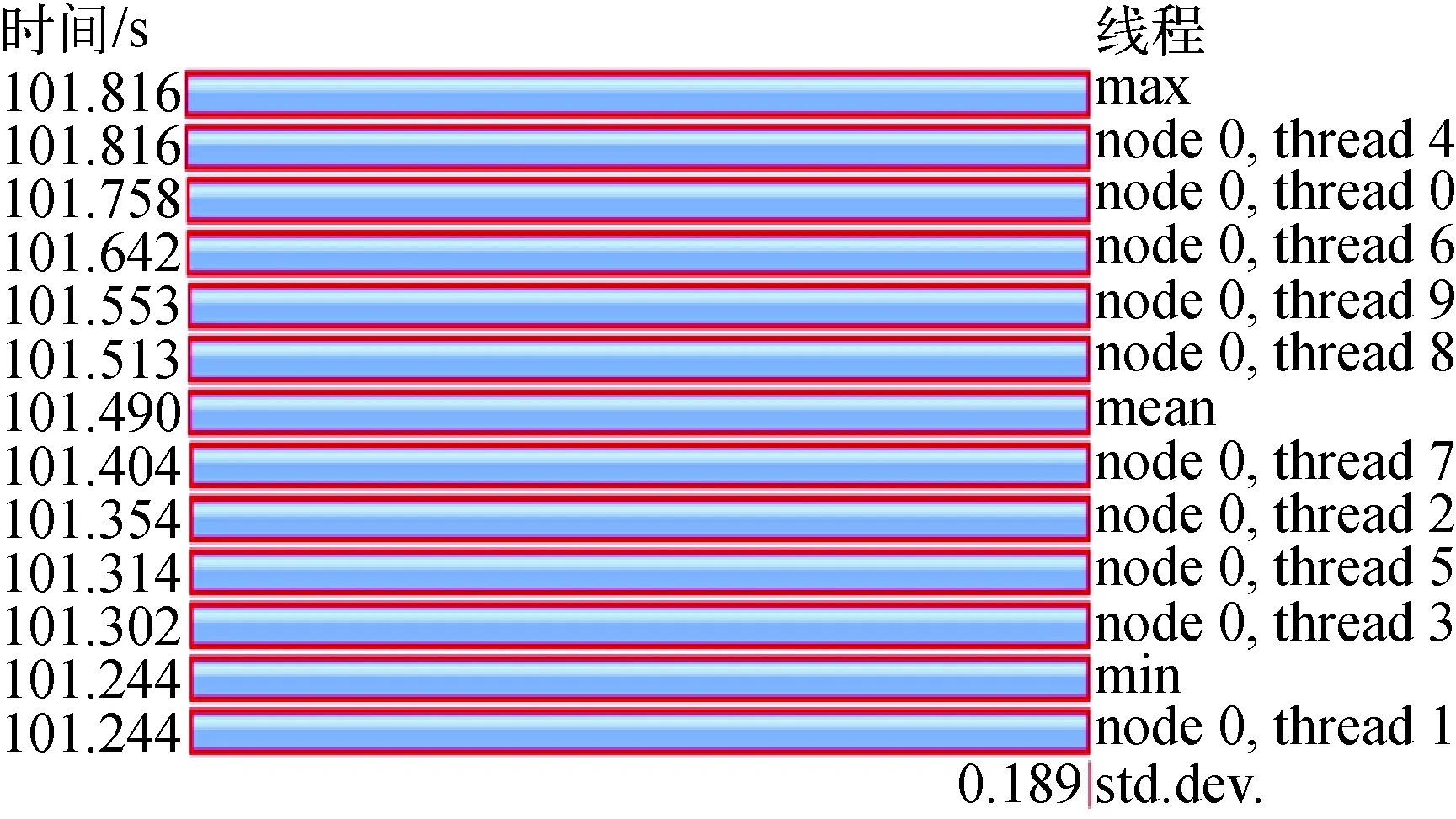
图6 10个线程时特征线扫描时间Fig.6 Time of characteristic ray sweeping at 10 threads
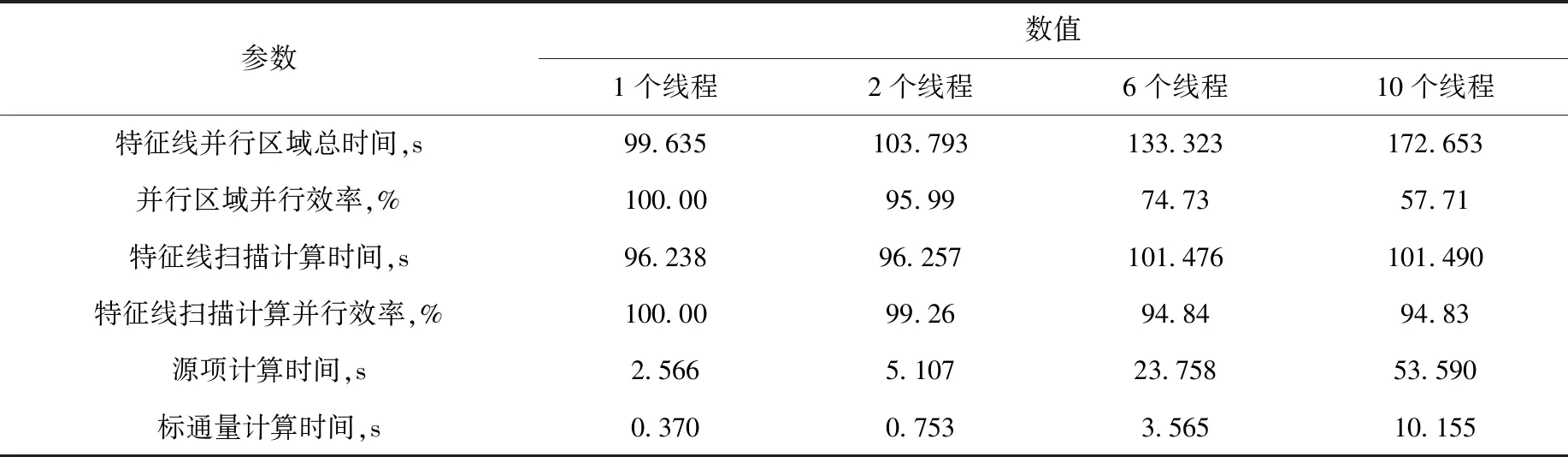
表1 不同线程时特征线并行时间及效率Table 1 Characteristic ray parallel time and efficiency for various thread numbers
结合特征线理论模型分析程序源代码后,通过消除源项计算中的重复性计算以及将原来的串行计算改为多线程并行计算,同时对并行区域内的其他部分通过优化数据结构提高缓存命中率,最终实现了并行效率的明显提升。优化后的特征线并行时间及效率列于表2。可看出,源项计算时间由53.59 s降低至11.52 s,时间占比降到10%以下。标通量的计算时间随线程数的增加也出现非线性增加,该部分的源代码为:
do ireg=stt_fsr_1+1,stt_fsr
tphi(:,ireg,ithd)=tphi(:,ireg,ithd)+
phi_bar(:,ireg)*weights(iang)
enddo
其中:ithd表示每个线程的编号;tphi表示标通量。TAU的测试结果表明,该部分每个线程的浮点运算次数不随线程数而改变,其理论计算时间应保持不变。但时间的测试结果却为超线性增加,与理论不符。由于该部分的计算时间占比较小,且多种测试分析均未获得该现象的原因,目前未进行进一步的优化。

表2 优化后的特征线并行时间及效率Table 2 Characteristic ray parallel time and efficiency after optimization
2 数值验证
本文首先分别验证NECP-X的空间、角度及特征线并行在小规模问题下的并行效率,然后分别以真实三维单组件问题和大规模并行可扩展性分析为例说明NECP-X多重并行的正确性和并行能力。
分别对空间、角度和特征线的并行效率进行测试。为使每个核的计算量尽可能地相等,即达到较好的负载平衡,本测试选取了4×4×4的三维压水堆组件,整个组件可分为64个栅元模块,如图2所示,每个栅元分为320个平源区。为使测试结果真实可靠,每个算例测试进行100次特征值迭代计算。计算条件为在每个卦限内8个幅角、3个极角,特征线宽度为0.03 cm,使用7群宏观截面。其中,特征线并行的测试例题为上述三维组件的四分之一,且使用69群宏观截面,其余参数保持一致。测试算例所使用计算机的相关参数如下:处理器为Intel(R) Xeon(R) CPU E5-2640 v4@2.40 GHz(79)、计算核心个数为20、Ubuntu14.0.4操作系统、编译器为GNU Fortran 4.8.4。
2.1 空间并行的数值验证
受限于计算机计算核心的个数,对于空间并行效率的测试分径向和轴向区域分解分别进行。为保证负载平衡,在径向区域分解时分别使用1、2、4、8、16个核进行计算,在轴向区域分解时分别使用1、2、4个核进行计算。在保证计算核个数不超过20的情况下,对径向和轴向同时区域分解进行测试。3种情况下的测试结果大体相近,其中径向区域分解的并行加速比示于图7。
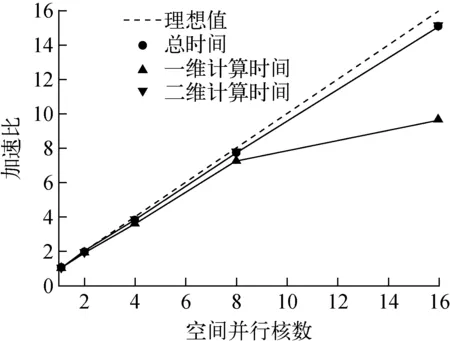
图7 NECP-X空间并行加速比Fig.7 Space parallel speedup of NECP-X
从图7可看出,空间并行在使用4个核时,总时间、一维计算时间和二维计算时间的加速比均接近于4;16个核并行时总时间的加速比也在15左右,一维计算时间加速比下降较快,是因为一维计算时间在单核时也仅为0.29 s,16个核时已下降到0.03~0.02 s,存在较大的测量不确定性,不具有参考性。
2.2 角度并行的数值验证
测试例题为在每个卦限内8个幅角,故在0~180°范围内共有16个幅角。为使分配到每个核的计算任务尽量相同,在对角度并行进行测试时分别使用了1、2、4、8、16个核进行计算,测试结果如图8所示,由于一维计算时间较少,不具有参考性,故未在图中示出。从前文介绍的贪婪算法可知,当使用2个核并行时,2个核的计算量是完全相同的,此时的并行加速比约为2,也证实了贪婪算法的高效;随着核数的增加,每个核的计算量逐渐出现不同,当使用16个核并行时,分配到每个核的特征线段数目存在较大不同,同时通信时间增加,此时并行加速比有所下降,但也在14左右。

图8 NECP-X角度并行加速比Fig.8 Angle parallel speedup of NECP-X
2.3 特征线并行的数值验证
在验证特征线并行的加速效果时,本文采用69群的宏观截面,因为在实际计算中,大部分问题都使用了69群甚至更多能群的宏观截面,这样特征线扫描部分的计算时间占比也更趋于真实。
本文选择1个线程到10个线程分别测试其加速比,测试结果如图9所示。可看出,当线程数达到4时,并行加速比依然在3.5以上,并行效率接近90%;随着线程数的逐渐增加,非并行部分计算时间逐渐增加,同时各线程对共有数据的读取存在竞争关系,造成并行加速比逐渐下降。在实际使用中,特征线的并行度一般不超过4个线程。
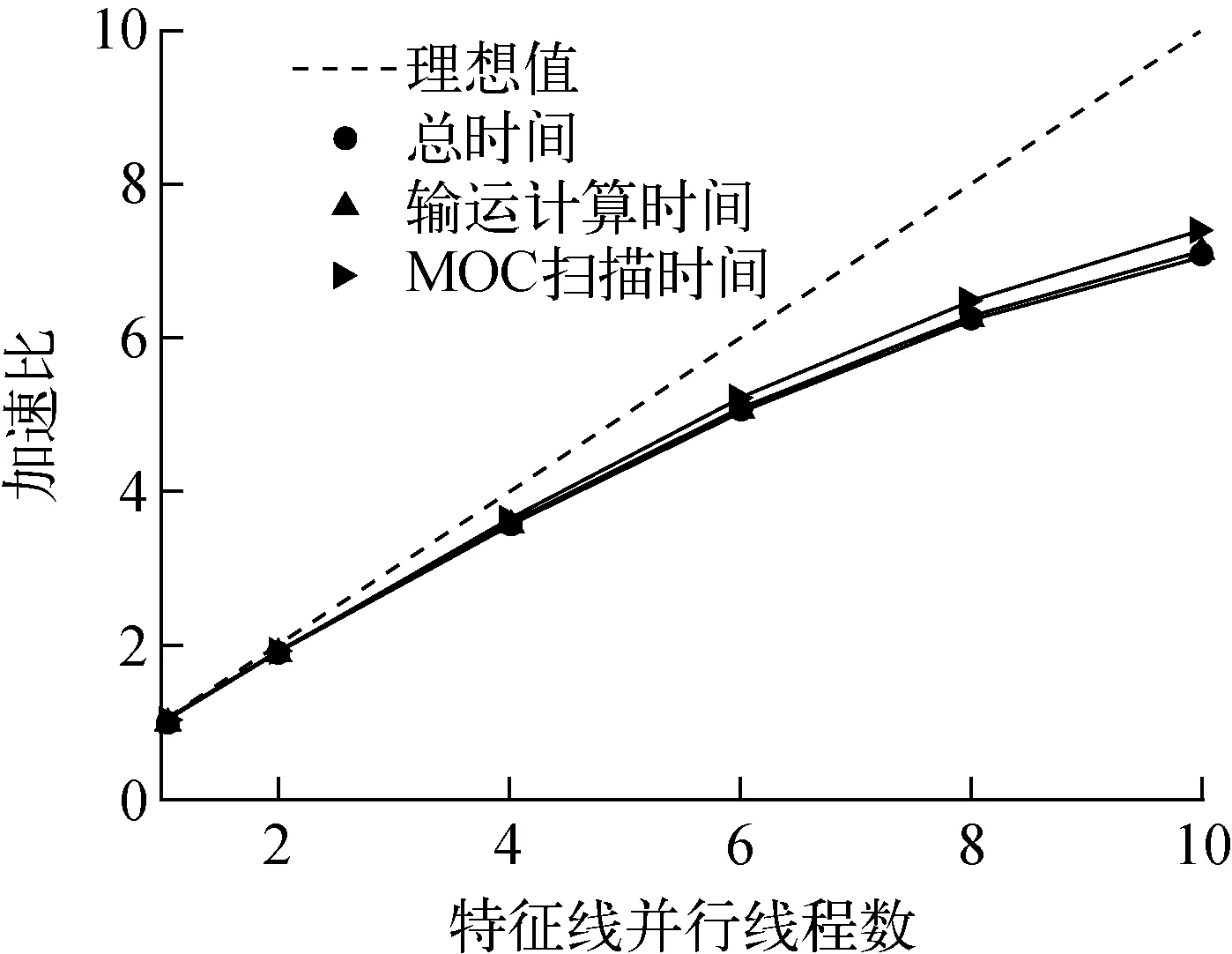
图9 NECP-X特征线并行加速比Fig.9 Characteristic ray parallel speedup of NECP-X
2.4 多重并行的数值验证
NECP-X多重并行能力的测试例题为美国橡树岭国家实验室在2014年发布的VERA(virtual environment for reactor applications)基准题[14]中的3A问题。该问题为一典型的压水堆17×17三维燃料组件在寿期初热态零功率工况下的稳态计算,详细的问题描述可参考文献[14]。该三维组件在轴向上共有8个格架,同时考虑到轴向的上下端塞以及上下反射层区域等,在轴向上被划分为66层,其模型示意图如图10所示。

图10 VERA问题3A参考模型Fig.10 VERA problem 3A reference model
本次验证NECP-X多重并行使用的计算机是“天河二号”超级计算机,每次测试均为节点独占式。计算条件为每个卦限内使用8个幅角、3个极角,特征线宽度为0.03 cm。为保证负载平衡,本文选择空间轴向33个区域、角度2个区域、特征线2个线程并行的并行测试组合,测试结果列于表3。基准题3A特征值的参考值为1.175 72,NECP-X在p0散射的计算条件下的计算结果为1.176 36,相差64 pcm,并行计算结果与串行计算结果相差不到10 pcm,说明多重并行的计算结果正确。需要说明的是,本次测试为强可扩展性[11]效率测试,由于上管座等位置处与燃料段的网格划分不一致,所以负载并不平衡,将会影响并行效率。另外,测试使用了粗网有限差分(CMFD)加速,但CMFD目前并未使用角度和特征线的并行资源,所以在使用角度和特征线并行时并行效率会有明显下降,后期将对CMFD如何高效利用MOC中角度和特征线的并行资源进行研究,这将显著提升总并行效率。

表3 三维组件的多重并行计算Table 3 Multilevel parallel calculation of 3-D assembly
2.5 大规模并行可扩展性分析
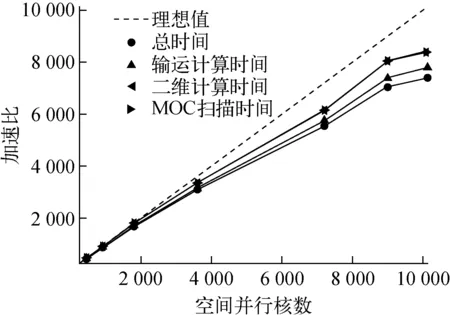
图11 NECP-X空间并行弱可扩展性测试Fig.11 Space parallel weak scaling test of NECP-X
对NECP-X的大规模(上万核)并行能力进行了弱可扩展性[15]分析。该分析采用的测试例题为径向每层225(15×15)个17×17组件,采用四分之一组件模块化,故每层有225个模块;轴向上随着问题规模的增大而增加层数,故总的模块数为225的整数倍。测试计算机为“天河二号”超级计算机,计算条件与2.4节相同,使用69群宏观截面。在每次测试中保证每个核计算1个模块,输运计算迭代次数为30次,不使用CMFD,并计算了弱可扩展性的加速比,结果如图11所示。在10 125核大规模并行的情况下,并行加速比高达7 000以上,并行效率约为70%,体现了NECP-X较好的并行可扩展性。
3 结论
本文介绍了数值反应堆物理计算程序NECP-X的空间并行、角度并行和特征线并行的多重并行策略。基于区域分解的空间并行可分解计算机的内存压力,极大地扩大了可计算问题的规模,同时具有较高的并行效率;基于贪婪算法的角度并行可充分地考虑负载平衡,达到较高的加速效果;基于OpenMP的特征线并行在动态调度的分配方案下可较好地加速计算,同时优化了非并行区域的计算。计算结果表明,角度和特征线并行可在空间并行的基础上进一步扩大并行规模,加速计算;空间并行可利用上万核的并行资源实现高效的三维全堆芯计算。NECP-X的多重并行策略可充分利用计算资源,实现不同规模问题的高效并行计算。
猜你喜欢
水泵技术(2021年5期)2021-12-31
山西电子技术(2021年3期)2021-06-28
中学生数理化·高一版(2021年3期)2021-06-09
数学物理学报(2021年1期)2021-03-29
重型机械(2020年3期)2020-08-24
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
数学年刊A辑(中文版)(2019年3期)2019-10-08
制造技术与机床(2018年12期)2018-12-23
北京航空航天大学学报(2017年4期)2017-11-23
