
网络舆情热点获取与分析算法研究
2019-05-24 14:17徐建国蔺珍张鹏
软件导刊 2019年5期
关键词:网络舆情
徐建国 蔺珍 张鹏

摘 要:从新闻网页中自动获取大量舆情数据,经过热点提取算法划分到不同话题簇中,并获取网络舆情最新热点。通过网络舆情变动周期把握舆情随时间发展情况,利用中文分词提取每篇新闻关键词,并对网页集合利用改进K-Means算法进行分析获得热点,从而获取某事件由出现到消亡过程中的热点迁移。改进的K-Means算法能有效分析获取的热点,有利于政府通过网络舆情热点掌握最新舆论动态,引导公众正确看待问题,营造积极、健康的社会氛围。
关键词:网络舆情;舆情热点;K-means聚类;话题簇
DOI:10. 11907/rjdk. 182597
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2019)005-0093-05
Abstract:This paper automatically obtains a large amount of public opinion data from the news webpages, and divides them into different topic clusters through the hotspot extraction algorithm, and obtains the latest hotspots of the network public opinion. The development of public opinion over time are grasped through the network public opinion change cycle, Chinese word segmentation is used to extract the keywords of each news, and the improved algorithm of K-Means algorithm is used for web page collection to obtain hotspots, so as to obtain an event from appearance to hotspot migration during the demise. The improved algorithm of K-Means algorithm can effectively analyze the hotspots obtained. It is beneficial for the government to grasp the latest public opinion dynamics through online public opinion hotspots, guide the public to correctly treat problems and create a positive and healthy social atmosphere.
Key Words: network public opinion; public opinion hotspots; K-means clustering; topic cluster
0 引言
随着互联网技术的飞速发展,网络媒体已成为人们获取信息的主要途径。网络舆情是指在互联网上流行的对社会事件的不同网络舆论,公众可以畅所欲言,行使自己的监督权、知情权、表达权与参与权,从而在一定程度上影响了国家网络安全。因此,需要对网络舆情进行分析、监控与引导,以及时防范误导性言论造成社会危害。
网络舆情是指由于各种事件刺激产生的通过互联网传播的人们对于该事件所有认知、态度、情感与行为倾向的集合[1]。网络舆情热点获取是指“对广大网民关于网络舆情的关注点以及后续发展关注度集合的掌控”。国内外研究者运用不同方法与技术实现网络舆情热点获取,并对获取过程中采用的相关算法进行研究。Manquan等[2]利用层次聚类算法,按时间顺序对新闻语料进行分组,从而有效避免了将内容相似,但实际上是两个完全不同话题的报道聚合在一起,而且通过组间聚类可以使时间跨度较大的话题合并成一个话题;Makkonen等[3]对TDT探索过程中出现的技术进行总结,如正文提取、检索和过滤、文本分类等;Yang&Ault等采用K最近邻算法与Rocchio进行话题跟踪研究;Cui&Kitagawa提出一种基于文本到达率与文本相关度的话题活跃程度分析方法;Kleinberg认为话题报道数量会在不同水平之间跃迁,增长率突然升高的词很可能会成为热点话题的表征词,因此提出突发检测算法;Zheng等[4]利用 Aging Theory对论坛中的热点话题进行识别,从而快速挖掘任意时间段内的热点话题。
虽然国内在该领域的研究起步较晚,但很多学者对其进行了大量研究,也取得了较多成果。通过各种聚类算法对信息进行分类,已有算法包括:K-mean算法、PAM算法、ARHP算法、OPTICS算法、PDDP算法与DBSCAN算法等。黄敏、胡学钢以舆情网络为节点、以链接关系为边搭建网络舆情传播网,采用PageRank与 Hits 算法挖掘网络舆情热点;韩晨靖[5]在已有聚类算法基础上创新性地添加可从标题提取特征词并改进文档相似度的算法,以提高网络舆情熱点获取准确率;王宏伟[6]对新闻报道与网民评论进行研究,首先考虑新闻报道特点和话题的多中心性,对原有聚类算法进行改进;其次,修改网民发表评论的非正式人名,借助频繁模式算法寻找评论出现的频繁模式。专家学者们通过对网络舆情的不断深入研究,相关思想与技术日趋成熟,对于热点的获取也更加准确。
1 研究设计
1.1 数据来源与采集
凤凰网新闻通常是对多个新闻网页的整合,因此本文以凤凰网为例进行分析,可获得较为全面的信息。网络舆情数据主要来自爬虫采集[7],爬虫采集是指利用种子链接向 Web 服务器发送 HTTP 请求,以获取当前网页内容,并分析得出其它所有链接,依据一定筛选标准从中选取某些链接加入下载队列,重复以上过程直至达到停止条件。
1.2 数据预处理
数据预处理主要包括数据清理、数据集成和数据规约,本文主要进行数据清洗与数据存储。首先通过爬虫采集网页元数据,然后进行相应处理如删除原始数据集中无关数据、平滑噪声数据等,最后将处理完的数据存入数据库以备后续查找等[8]。
从新闻网页上爬取的网络舆情数据长短不同,如果对整篇文章进行处理会影响分析效率。但是每篇新闻主旨都能用几个简单的词进行概括,因此只需提取能真实反映文章主旨的词即可,这些词称为关键词。经过中文分词后,每篇新闻都能得到对应关键词,然后利用Jieba分词技术[9]根据词频对词语进行排序。候选集特征向量是出现频次更高的若干词语,计算出每个词语权重,将上述候选集用文本描述成由不重复词组成的表,转换成系统可处理的文本特征向量即转换成功[10]。
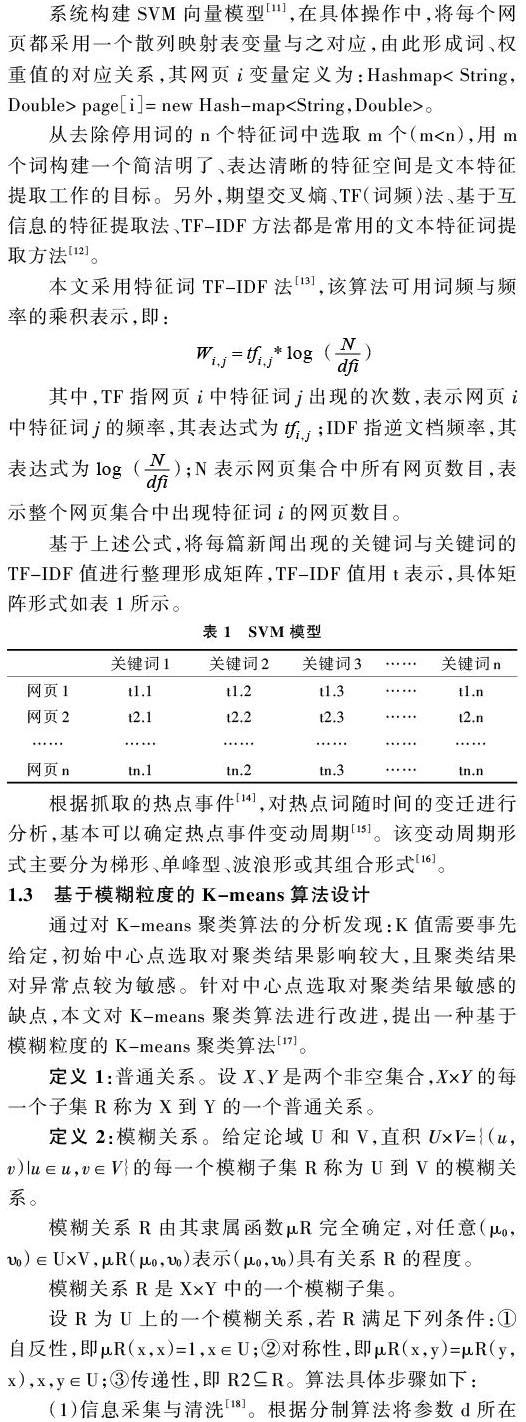
系统构建SVM向量模型[11],在具体操作中,将每个网页都采用一个散列映射表变量与之对应,由此形成词、权重值的对应关系,其网页i变量定义为:Hashmap< String,Double> page[i]= new Hash-map
从去除停用词的n个特征词中选取m个(m 根据抓取的热点事件[14],对热点词随时间的变迁进行分析,基本可以确定热点事件变动周期[15]。该变动周期形式主要分为梯形、单峰型、波浪形或其组合形式[16]。 1.3 基于模糊粒度的K-means算法设计 通过对K-means聚类算法的分析发现:K值需要事先给定,初始中心点选取对聚类结果影响较大,且聚类结果对异常点较为敏感。针对中心点选取对聚类结果敏感的缺点,本文对K-means聚类算法进行改进,提出一种基于模糊粒度的K-means聚类算法[17]。 定义1:普通关系。设X、Y是两个非空集合,X×Y的每一个子集R称为X到Y的一个普通关系。 定义2:模糊关系。给定论域U和V,直积U×V={(u,v)|u∈u,v∈V}的每一个模糊子集R称为U到V的模糊关系。 模糊关系R由其隶属函数μR完全确定,对任意(μ0, υ0)∈U×V,μR(μ0,υ0)表示(μ0,υ0)具有关系R的程度。 模糊关系R是X×Y中的一个模糊子集。 设R为U上的一个模糊关系,若R满足下列条件:①自反性,即μR(x,x)=1,x∈U;②对称性,即μR(x,y)=μR(y,x),x,y∈U;③传递性,即R2?R。算法具体步骤如下: (1)信息采集与清洗[18]。根据分制算法将参数d所在理论区间划分为较小区间,依据不同的d进行聚类,并去掉效果不好的区间。 (2)从数据集X中随机选取k个数据对象,并将其设定为初始聚类中心,则形成初始聚类中心点C1,C2,…,Ck,数据集即可确定划分成k类。 (3)分别计算数据集中剩下每个数据对象到k个初始中心点的距离,将每一数据对象根据距离就近划分到最相近的类中,从而形成以k个初始中心点为中心的类。例如,数据对象Xp离中心点[Ci](i≤k)最近,因此将数据对象Xp划分到[Ci]类中。 (4)根据公式[Ci=1nix=wiX],重新计算每一个聚类的中心点,即得到C*1,C*2,…,C*k。 (5)重复步骤(3)、(4),直到重新计算后的聚类中心点与计算前的聚类中心点相同,任何变化都未发生,说明聚类结果已达到收敛,输出聚类结果。 根据K-means算法基本原理,下面给出基于模糊粒度的K-means聚类算法简易流程,如图1所示。 模糊粒度计算方法即先利用分治算法思想将参数值d所在理论区间分解成较小区间,在每一个小区间上选取一个距离空间数作为dθ值,依据不同dθ值分别对数据集进行聚类,去掉聚类效果不好的区间,然后利用连续属性离散化思想对剩余区间进行离散。dθ取遍离散化后的区间端点值对数据集进行聚类,利用95%有序BWP指标值的均值衡量聚类结果,均值越大,说明聚类效果越好,最大均值对应最好的聚类结果。粒度值d由粗变细的过程便会产生动态聚类结果,粒度越粗,划分区间越大,对异常点敏感问题则处理得越好,但同时数据失真度也越大;粒度越细,异常点对聚类结果影响越大,但数据真实度高。该改进算法解决了K-means聚类算法聚类数需要事先给定,以及对初始中心点选取与异常点较敏感的问题[19]。 将互联网获取的新闻网页数据通过热点提取算法划分到不同话题簇中是网络舆情热点提取的主要模式,并可在需要时扩充新的话题簇[20]。该模式可帮助人们快速发现有用信息,并了解与监督网络整体舆论情况。实验需要准备的数据为包含n个数据对象的数据库,即通过网页分析获得的网页内容,以及满足方差最小标准的k个聚类输出,输出的k个聚类即为k个热点。 2 实验与分析 本实验以凤凰网2016年11月1号-2017年5月1号的新闻为例,对网络舆情获取过程进行完整演示,并对结果进行分析。 首先通过关键词“朴槿惠”、“崔顺实”获得所有相关新闻与带有关键信息的URL,通过“查看网页源代码”可以找到网页特点,标题存放在
中。
标题:
李克强一句“煤亮子”鼓励,矿工们变身“双创”秀才
时间:2016-11-20 20:43:03
内容:
原标题:总理一句;煤亮子;鼓励,山西官地矿工们变身;双创;秀才
将每篇新闻的标题、时间、内容从标记中提取出来并导入数据库,共获得456条信息,作为网络簇特征词获取的测试样本,信息格式如图2所示。
为了对数据库中的网页新闻集合特点进行分析,统计在某时间区间内出现的新闻主题报道数量,可以更清晰地看到公众或媒体对于该主题的关注度变化情况,从而了解该主题出现、高潮、消亡的区间。如图2所示,以“朴槿惠”、“崔顺实”为主题的新闻從2016年10月26号开始出现,到2016年11月2日新闻数量达到67篇,其呈现的周期形式为单峰型;2016年11月2日-12月21日新闻数量有所减少,说明该事件没有新的进展;2016年12月21日-1月11日平均每7天新增47篇报道,其呈现的周期形式为梯形,说明在此期间该事件可能激化了新的矛盾;之后新闻数量逐渐减少,意味着人们对该事件关注度下降,该事件已不能再称为“热点”[21]。
在对热点整体发展情况进行预判之后,采用先整体后局部的方法进行分析。为了提高分析效率,在中文分词之前将每条记录中的content内容导出数据库,用Jieba技术进行分词并将结果写入txt文本中,其中3篇新闻分词如表2所示。获得每篇新闻分词结果后,需要对出现的词语进行TF-IDF值计算[22],并建立向量矩阵[23],例如第一页新闻的TF-IDF权重如表3所示。
对每篇网页TD-IDF权重组成的矩阵作K-means聚类分析,为了避免难以选择K-means聚类簇个数的缺陷,将k值从3~7测试一遍,从而找到最佳测试结果,并将结果进行可视化。
图4表示未进行聚类分析的网络舆情热点情况,图5、图6分别显示的是k=3、k=4的舆情热点情况。
根据以上聚类结果导出新闻网页关键词如表4所示,这些关键词TF-IDF的权重值大于0.4,代表了在讨论朴槿惠、崔顺实过程中公众关注的其它热点。
根据文本聚类可以看出,整个网页集合的热点主要是“朴槿惠、崔顺实之间的亲密关系是否对韩国造成影响”,其它小分支热点是公众关注此次事件其它涉案企业或人员所衍生出的。同时这些热点可能朝着新的方向发展,网络舆情也会随之变化,如郑尤拉走后门事件将引发公众对其他富二代不公平入学事件的关注、朴槿惠下台之后韩国公众将重新投票选举总统,以及经过弹劾事件后,公众选择标准可能会更关注下一任总统的清廉作风等。
3 结语
本文从网页新闻采集入手,再对采集的网络数据进行预处理,得到中文分词矩阵进行降维,以便得到聚类分析需要使用的数据,最后对得到的网络舆情话题进行分析。本文对该研究过程不断改进,以获得更加精确的热点,取得了以下研究成果:
(1)通过对凤凰网网页内容的分析与净化,提高了数据库中导入新闻网页的相关度和纯净度,保证了数据的全面性,不需要任何人工干预。同时,在具体聚类之前将数据库中所有新闻网页按时间顺序进行统计,可以看出每个时间区间发布的新闻数量,从而对热点发展过程产生初步了解。
(2)对网页进行中文分词,将本篇新闻出现次数较多的词语作为新闻关键词,并对所有新闻集合的关键词进行K-means聚类,从中提取共同关键词即是其所在簇的中心话题。
然而,本研究还有待完善,如何更加全面、准确地获取舆情热点,并对舆情情感进行分类仍需要未来作更深入研究。
参考文献:
[1] 曾润喜. 网络舆情管控工作机制研究[J]. 图书情报工作,2009(18):79-82.
[2] 王玉珍. 网络舆情热点发现综述[J]. 内蒙古科技与经济,2015(16):66-67,145.
[3] 张玉芳,万斌候,熊忠阳. 文本分类中的特征降维方法研究[J]. 计算机应用研究,2012(7):2542-2543.
[4] 柳虹,徐金华. 网络舆情热点发现研究[J]. 科技通报,2011(3):421-425.
[5] 陈瑜,韩晨靖. 浅谈文本聚类算法对网络热点发现精准度的影响[J]. 中国管理信息化,2017(17):194-195.
[6] 陈君. 互联网隐式文本特征的提取[J]. 电子技术与软件工程,2017(23):155-156.
[7] 程田. 网络信息抓取技术大揭秘[J]. 课堂内外:科学Fans,2016(7):32-33.
[8] 于营. 面向微博的网络爬虫数据采集[J]. 信息系统工程,2017(12):36-37.
[9] 徐明磊,赵博文,诸葛福民. 高校网络舆情获取方法研究[J]. 软件导刊,2018(17):48-50.
[10] 孙雪凡. 试论新形势下网络舆情的发展对思想政治教育载体的影响[J]. 法制博览,2013(4):285-286.
[11] 梁永春,焦文强,田立勤. 基于大数据新闻网站文本挖掘的网络舆情监测设计与实现[J]. 华北科技学院学报,2018(4):82-87.
[12] 邓先均,杨雅茜,罗昭,等. 网络舆情热点话题检测聚类算法研究[J]. 数字技术与应用,2018(5):146-149.
[13] 陈珂,蓝鼎栋,柯文德,等. 基于Java的新浪微博爬虫研究与实现[J]. 计算机技术与发展,2017(9):191-196.
[14] 梁喜涛,顾磊. 中文分词与词性标注研究[J]. 计算机技术与发展,2015(2):175-180.
[15] 张世军,程国胜,蔡吉花,等. 基于网络舆情支持向量机的股票价格预测研究[J]. 数学的实践与认识,2013(24):33-40.
[16] 薛可,许桂苹,赵袁军. 热点事件中的网络舆论:缘起、产生、内涵与层次研究[J]. 情报杂志,2018(8):78-83.
[17] 张霞,王素贞,尹怡欣,等. 基于模糊粒度计算的K-means文本聚类算法研究[J]. 计算机科学,2010(2):209-211.
[18] 康鲲鹏. 基于大数据的数据清洗研究[J]. 江西科学,2018(4):654-657.
[19] 费贤举,刘金硕,田国忠. 基于模糊近似空间组合度量的特征选择算法[J]. 计算机工程与设计,2018(7):1911-1916.
[20] 龙志祎,程葳. 基于词聚类的热点话题检测算法[J]. 计算机工程与设计,2011(6):2214-2217.
[21] 张一文,齐佳音,方滨兴,等. 非常规突发事件网络舆情热度评价指标体系构建[J]. 情报杂志,2010(11): 71-75,117.
[22] 于韬,王洪岩. 基于TF-IDF算法的文本信息提取[J]. 科技视界,2018(16):117-118.
[23] 张宸,韩夏. 大数据环境下基于SVM-WNB的网络舆情分类研究[J]. 统计与决策,2017(14):45-48.
(责任编辑:黄 健)
猜你喜欢
新媒体研究(2016年21期)2016-12-19
法制与社会(2016年33期)2016-12-15
今传媒(2016年10期)2016-11-22
大学教育(2016年11期)2016-11-16
经营者(2016年12期)2016-10-21
今传媒(2016年9期)2016-10-15
