
分类学习方法在犯罪人地域特征预测识别中的应用研究
2019-06-03 07:44石少冲原鹏辉明红霞
中国人民公安大学学报(自然科学版) 2019年1期
石少冲, 陈 鹏,2, 原鹏辉, 侯 超, 明红霞
(1.中国人民公安大学信息技术与网络安全学院, 北京 102600;2.公安部安全防范技术与风险评估重点实验室, 北京 102600)
0 引言
在我国商品经济快速发展、人流物流交换日益频繁的当下,社会治安环境日益错综复杂。与此同时,各种治安、刑事案件的发案量与日剧增并居高不下。因此,在警务资源十分有限的条件下,如何有效地控制和预防犯罪的发生对公安部门极为重要。传统的解决思路是通过基于案件的时空信息利用各类模型预测犯罪案件数量[1-5]或预测犯罪热点区域[6-8],进而改变警力配置,优化警力布局的方式,使公安部门从被动警务变为主动警务。但从运筹学的理论角度,这种做法的局限性在于犯罪人员很容易通过改变作案目标或作案区域从而使公安机关的主动防控手段失效,所以这类预测方法主要适用于公安部门的巡逻布警、治安防控等规模化警力资源应用业务中。
随着近年来信息技术的快速发展以及感知能力的提升,围绕着个体的特征数据越来越丰富,也为人们开展犯罪个体身份和行为的预测提供了基础,相关研究成果逐渐增多。如孙菲菲等提出了利用嫌疑人心理因素特征预测其犯罪概率的方法[9],罗森林等利用嫌疑人部分属性信息构建了犯罪人犯罪倾向的预测模型[10],等等。但是,从目前这方面已进行的研究来看,这种通过犯罪人属性预测犯罪人行为的研究尚存在着一些不足。首先,从应用的方向上来看,目前相关研究主要根据犯罪人的各类特征对其犯罪风险程度进行评价,而不是从侦查的角度,利用案件所呈现出的各类特征信息来快速判别犯罪人员的类别,实现侦查方向的快速确定;其次,从方法的适用性来看,无论是孙菲菲还是罗森林的工作大量采用了犯罪人心理、收入、情感、压力等公安非实时感知数据,具有较大的稀缺性,往往会因实际获取嫌疑人的属性特征较为碎片化而达不到模型预测所需的条件;再次,在不同的案件中,犯罪人的行为预测模型构建可能会随着案件类型的变化而产生较大的变异,即所建立的模型严重依赖工作场景,因此迁移性和扩展性较差。近年来,一些研究人员从犯罪侦查的角度开展了一些利用案件信息挖掘犯罪人身份的尝试,如文献[11]等,但仍存在着不区分案件类型、缺乏具体的应用目标、缺少国内案例数据的验证等问题。综上,根据目前关于犯罪人预测研究工作所存在的一些不足,本文从犯罪侦查的角度提出了利用犯罪案件现场信息建立犯罪人特征识别模型的构建方法,并以国内的实际犯罪数据为基础进行理论验证,进而为信息化侦查提供一些有益的探索。
1 犯罪人地域特征分类识别的机理
犯罪人地域特征是公安机关最为关注的犯罪人特征之一。在我国城市间人口的迁移频度不断增强的过程中,城市犯罪主体中外来人口占比也越来越高,特别是在一些地区,案发后确认犯罪人的地域来源已经成为公安部门侦办案件的一个重要突破点。利用犯罪人的地域特征信息,公安机关可以借助基础信息库关联出犯罪人更多的身份信息,从而实现侦查方向的快速确定。本文将探索基于案件现场信息的犯罪人地域特征识别方法。
1.1 犯罪学原理
城市的现代化进程促使了人员、信息、物资日益频繁的流动,犯罪也随着城市的现代化进程演化出一系列的特点。犯罪学专家和公安实战工作中发现案发现场与犯罪人的地域特征有很强的关联性[12-14], 特别是针对侵财类案件,犯罪的地域性和亲缘性更加明显。这些特点就为通过研究犯罪现场的信息构成来识别犯罪人的地域特征提供了可能。而犯罪现场是一种可以从“人”、“事”、“地”、“物”四类维度去描述一种事实活动[15],犯罪人通过其所作所为的“事”同 “物”和“地”联系起来构成一起案件现场的要素,如图1所示。
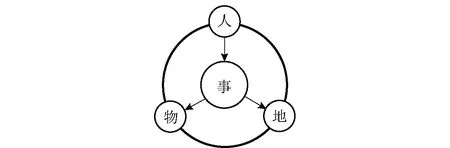
图1 案件现场构成要素
但根据“人”、“地”、“事”、“物”均是包含着多维信息特征集合,将“人”、“地”、“事”中提取单一维度的特征更有力于模型的构建。案件作为承载“地”、“事”、“物”的客体,可以从“事”中抽取为时间、手段两个特征,可以从“地”抽取为区域、部位两个特征,可以从“物”中将受害客体和侵害对象抽取为目标特征,如图2所示。所谓的时间描述的是案件的发生时间,区域描述的是案件发生的地理区域,部位是指犯罪者选择攻击的空间类型,目标描述的是犯罪人选择的对象种类,手段描述的是犯罪人的工具手段。一般情况下,来自相同地域的犯罪人群体往往由于具有相近的社会关系在作案时间、作案区域、作案目标、作案部位和作案手段上具有较高的相似性,利用时间、区域、目标、手段、部位等来确认犯罪人的地域特征具有较高的可行性。

图2 犯罪人地域特征识别模型
1.2 研究框架

图3 犯罪人地域特征识别模型机理
本文研究路线如图3所示,通过对原始数据预处理和清洗阶段来说明犯罪人地域特征识别模型的建立和工作过程。首先根据上述犯罪学和证据分析原理定义时间、区域、部位、目标和手段五种案件现场特征信息,并根据定义对案件现场的描述中抽取对应特征的元素,构建特征集合。时间特征集合里的元素可以以小时为单位划分,区域特征集合里的元素可以以行政区划为单位划分,部位特征集合里的元素可以易受攻击的薄弱位置为单位划分,目标特征集合里的元素可以以学校、商场、居住区等空间类型划分,手段特征集合里的元素可以根据犯罪人的不同作案方法来划分。
然后,对案件的原始数据进行清洗过程中,对数据中信息缺失项进行缺失值插补,去除错误的数据项,剔除与案件现场无关的数据项。接着进行数据规约,对时间、区域、部位、目标和手段各自特征集合中相似元素进行合并化简,如在目标特征中将与学校有关的元素合并为同一类;在目标特征中将商店有关的元素合并成一类;在时间特征中将1~6时合并为后半夜,7~12时合并为上午,13~18时合并为下午,19~24时合并为前半夜,并对相应的案例样本打上犯罪人地域特征的标签,最后选择合适的算法对标签化和标准化的数据构建犯罪人地域特征识别模型,进而实现对犯罪人地域特征的识别。
2 算法原理和评价标准
2.1 分类算法选择
在侦查工作中,描述和刻画案件和案发现场的文本型的离散变量很多,不同的特征量化方式对回归等模型的分类精度造成很大的影响,也会人为增加大量带入误差。另外,犯罪人地域特征与案发现场的关联性并不是一种简单的线性关系,很难进行全面精准详细地表达。而决策树模型对文本型数据具有很好的包容性,广泛地应用于农业、商业、医学、地理遥感影像等领域[16-21]。决策树模型也能够对案发现场特征进行非线性分割,并以贴近人类的思维过程的方式生成可视化的分类规则从而建立非线性系统分类模型,并且模型易于理解和表达、可信度较高。而且公安机关特别需要将机器从数据中学得的知识能够直接地展现出来,决策树提供很好的展现方法,因此,本文将利用决策树算法刻画案发现场与犯罪人地域特征的非线性映射关系,构建犯罪人地域特征识别模型进而实现对犯罪人地域特征的识别。
2.2 模型算法原理
决策树是机器学习算法的一种的[22],所谓机器学习,即是计算机从大数据中学习得到一种假设函数模型H,利用假设函数模型H可以对新的对象x进行预测或将对象x通过假设函数模型H映射到对象x的类标号y里。在决策树算法里,信息增益可以作为衡量所选取的特征A对于减少样本的不确定性程度的能力,信息增益数值越大就代表这个特征越好。但选取信息增益不能避免决策树树分支过多的情况。相比而言,信息增益比是对信息增益的一种改进,选取信息增益比作为衡量所选取的特征A是否最优的指标比选用信息增益作为指标更加可靠。信息增益比能够对决策树分支过多的情况进行惩罚,从而抑制决策树分支过多的情况。信息增益和信息增益比的公式如下所示:
g(D,A)=H(D)-H(D|A)
(1)
(2)
(3)
其中,H(D)为数据集D的经验熵,H(D|A)为在特征A给定条件下数据集D的经验条件熵,g(D,A) 为特征A对于数据集D的信息增益,HA(D)为训练数据集D关于特征A的值熵,n是特征A的取值个数。
2.3 模型性能评价指标
在机器学习中有一系列测试性度量方法可以合理的反映所训练模型对于未知数据的分类能力[23],如正确率、Kappa值、真阳率、真阴率、查准率、查全率、F度量等。各自公式如下所示:
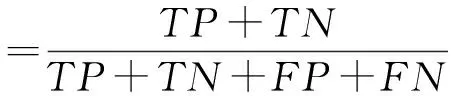
(4)

(5)
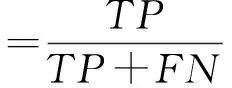
(6)

(7)

(8)
(9)

(10)
其中,TP为真阳性(True Positive)代表正确分类为阳性样本的数量;TN为真阳性(True Negative)代表正确分类为阴性样本的数量;FP为假阳性(False Positive)代表错误分类为阳性样本的数量;FN为假阴性(False Negative)代表错误分类为阴性样本的数量。Pr(a)指的是分类器真实值一致性比例,Pr(e)表示期望一致性的比例。
3 案例测试
3.1 数据来源
在公安机关实战工作中,盗窃电动自行车案件是伴随2008年电动自行车迅速普及过程中产生的一种新型的财产犯罪。在这种新型的财产犯罪中,一方面犯罪分子能以较低的犯罪成本获得较高的收益从而促使盗窃者多次犯罪,另一方面因盗窃电动自行车案发地随机,作案手段简单多样,案件现场痕迹物证少,侦查人员不易快速大量侦破相应案件。对于北京地区,北京盗窃电动自行车案件还有作案人地域特征多样的特点,即北京地区盗窃电动自行车案件融合了全国各地区盗窃电动车案的特点,具有更强的代表性和可信度。因此本文采用来着于北京市2008~2014年间盗窃电动自行车案破案数据。
3.2 数据处理
将北京市2008~2014年间盗窃电动自行车案破案数据按照图2犯罪人地域特征识别模型进行整理,此外,从刑事侦查的角度来讲,由于一般的案件现场均包括时间、区域、目标、部位和手段5种信息,基于这5类信息构建犯罪人的特征预测模型具有很好的迁移性和扩展性,也适用于其他类型的侵财类案件,有利于大大缩小犯罪嫌疑人的排查范围、提高侦查速度。
将所整理的案例进行数据清洗,进行相应的标签化和规约化。其中,破案数据中来自X省的罪犯最多,作案地较广,具备典型性。本文将将重点识别犯罪嫌疑人是否来自于X省。经过对数据的清洗和预处理得到判断犯罪嫌疑人是否属于X省的数据集,其包含1 269条有效数据,数据样如表1所示。

表1 实验中使用的部分数据集
3.3 决策树识别结果
将阳性的类别设置为“是”,将阴性的类别设置为“否”。应用基于信息增益比决策树的办法对清洗后的数据集进行分类预测,使用交叉验证办法对模型进行测验,依次进行2-10折测验。检验完成后,计算不同折数下的正确率、Kappa值、真阳率、真阴率、查准率和查全率、F度量和AUC值。其中,AUC值是ROC曲线与x轴所围成的面积,ROC曲线是以样本的真阳率为x轴,以样本的真阴率为y轴所绘制的曲线。若AUC值为0.5意味着模型为随机分类,AUC值越接近于1意味着模型的分类预测能力越强,可信度越高。
表2为经过2至10折交叉检验模型性能评价结果,模模型分类正确均值为79.835%,方差为0.875,Kappa均值为0. 579,方差为0.017,表明模型预测值和真实值之间具有较好的一致性;真阳率均值为0.798,方差为0.009,真阴率均值为0.804,方差为0.011,AUC均值为0.848,方差为0.004,表明模型具有良好的正确分类为阳性样本和阴性样本的能力;查准率均值为0.811,方差为0.007,查全率同真阳率相同为0.798,方差为0.009,F均值为0.801,方差为0.008,表明模型具有很好的精准度和很宽的动态范围。整体而言,利用决策树算法对盗窃电动车案件的犯罪嫌疑人地域特性稳定性较好,分类效果较好。
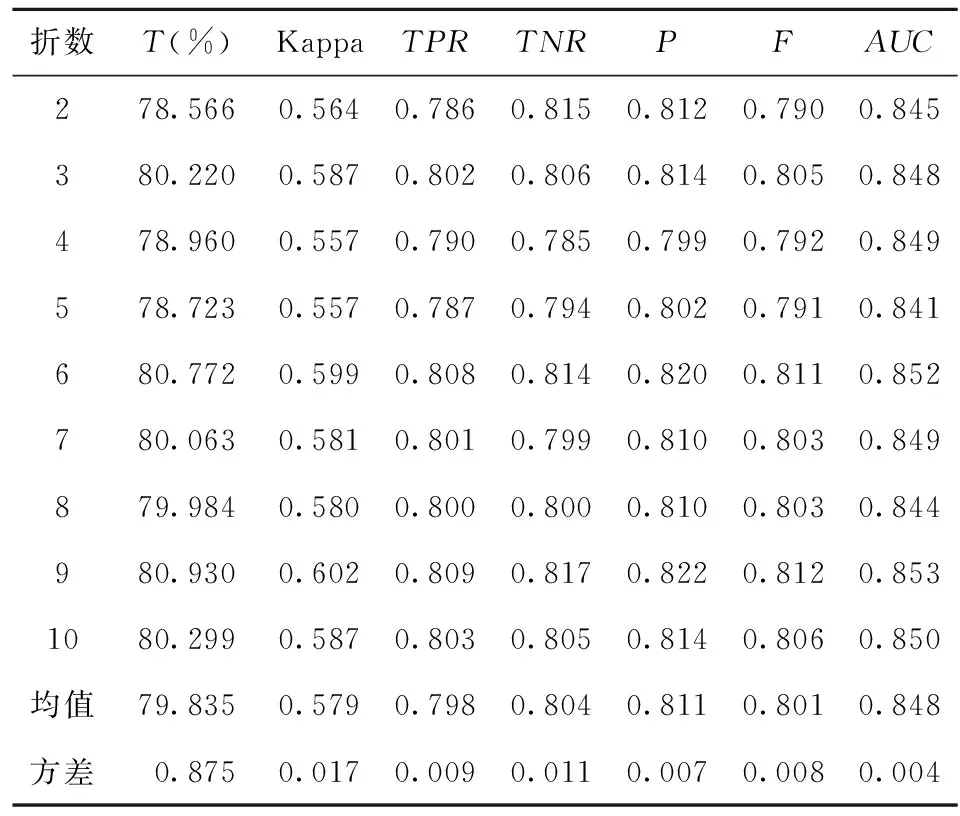
表2 犯罪人分类预测结果
3.4 不同分类算法分类效果的对比
为进一步测试决策树模型的分类能力和可靠程度,将可处理文本数据的朴素贝叶斯、逻辑回归、贝叶斯网络和随机森林4种模型的分类预测效果同决策树模型进行对比。AUC值同真阳率和真阴率均有关,可作为模型区分阳性、阴性样本的综合指标;F度量为查准率和查全率的调和平均值,可作为模型精准程度和动态范围的综合指标。采用AUC值和F度量可方便不同模型间的对比。
通过表3不同分类算法模型评价结果的对比和分析可得,决策树模型在对盗窃电动自行车犯罪分子地域特性分类过程中,拥有较朴素贝叶斯、逻辑回归、贝叶斯网络3种模型更好的精准度和较宽的动态范围,有比较好区分阳性样本和隐性样本的能力。尽管随机森林的性能稍优于决策树,但其是在决策树算法的变形,针对本问题时,其效果也并非远远优于决策树,而且在大样本情况下,决策树模型运行速度比随机森林模型较快,对犯罪人分类预测正确率相对较高。总体而言。表中4种分类算法的分类正确度均都在77.8%以上,这从侧面证明根据时间、区域、部位、目标和手段5种特征可以实现对犯罪地域特征的分类识别。
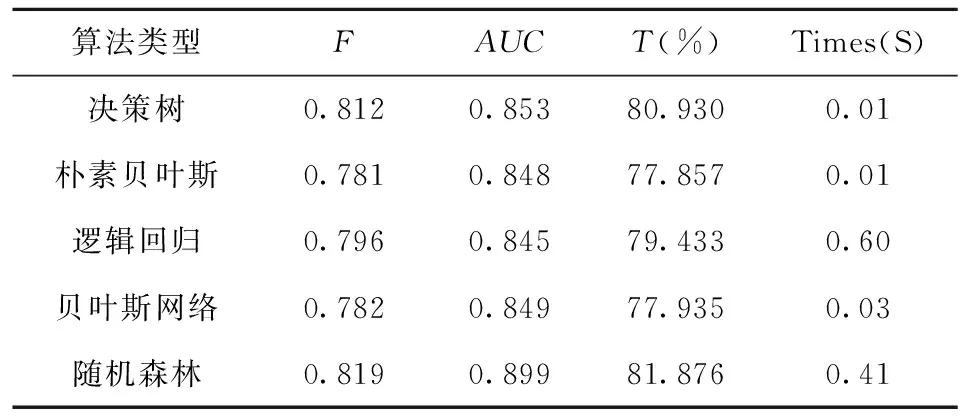
表3 不同分类算法模型评价结果
3.5 决策树的生成
利用Weka 3.8软件绘制以作案手段、作案目标、作案部位、作案区域和作案时段信息为特征向量,基于信息增益比所构建的决策树,即犯罪人地域特性分类预测模型,这就是机器从数据中学习分类规则。图1显示了所绘制的决策树的部分图形 。决策树选择“作案区域”为根节点,表明“作案区域”的信息增益比最大,以此划分更能获得更纯的子节点。在图1中“作案区域”为西城区,“作案手段”为撬锁开锁,“作案部位”为路边,“作案时间”为晚上,表明决策树模型可正确分类10个样本、错误分类2个样本;若“作案时间”为下午,决策树模型可正确预测9个样本、错误分类3个样本;作案区域为“怀柔区”能完全正确分类95个样本。
如果新的案发现场为“作案手段”为撬锁开锁,“作案目标”为商业区,“作案部位”为路边,“作案区域”为怀柔区,“作案时间”为晚上,结合所生成的模型预测判断犯罪嫌疑人来自X省。在实践过程中应不断更新决策树模型,使模型能学习盗窃电动自行车案的新情况,保证模型有很好的扩展性和实时性。
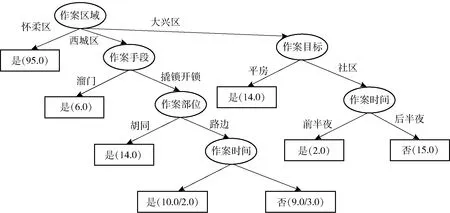
图4 决策树的部分结构
4 结语
本文基于犯罪学和信息侦查学原理,建立了利用时间、区域、部位、目标和手段等5种案件现场信息识别犯罪人地域特征的理论模型,并通过北京市盗窃电动自行车案例利用决策树算法进行了实际验证。结果表明,5种特征可以有效地实现对犯罪地域特征的分类识别,决策树模型能够对训练数据中所蕴含的知识或分类规则进行充分的学习,并具备较好的知识扩展能力,利用该模型实现对犯罪人地域特征的分类识别的方法可行,且其分类正确率在80%左右。在警务工作中,大多数案件均包含这几类现场信息数据,模型对其他侵财类型具有较好的迁移性和扩展性。虽然本研究中,决策树算法各项性能并不是最优,但从效果对比得知,在数据量较大时,决策树算法较朴素贝叶斯等其他算法在预测精度和运算时间成本上更为优良,采用了决策树算法作为分类器来构建分类模型具有一定的合理性。本工作的缺陷与不足是由于公安信息保密原因所获取的样本量较小,时效性不强,特征向量不够充分,因此下一阶段将重点研究犯罪人籍贯地的多分类预测和犯罪人团伙关系的预测,以进一步提升模型的适用性。
猜你喜欢
地理与地理信息科学(2022年5期)2022-10-12
青少年科技博览(中学版)(2022年3期)2022-04-26
证券市场红周刊(2021年26期)2021-07-06
学生天地(2020年5期)2020-08-25
新华月报(2019年24期)2019-09-10
电子制作(2018年16期)2018-09-26
儿童时代(2017年2期)2017-09-16
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
黑龙江史志(2014年15期)2014-11-10
