
基于全卷积神经网络的屏幕区域定位算法
2019-06-17 09:28付泽伟
计算机应用与软件 2019年6期
付泽伟 金 城
(复旦大学计算机科学技术学院 上海 201203)
0 引 言
随着科技的进步手机等便携设备的计算能力不断增强,拥有摄像头的移动设备也越来越普及,应用这些设备可以很方便地进行拍照和摄像。人们经常需要利用手机等便携设备记录屏幕中播放的视频信息,但是在拍摄到屏幕的同时不可避免地会拍摄到屏幕外的背景,这些背景对后续的视频处理会带来很大的干扰。
定位屏幕区域的目标是在图片或视频中,找出屏幕边缘的四条直线,如图1所示。

图1 输入图片(左)屏幕区域(右)
实际上想要准确地找到屏幕边缘的四条直线很困难,传统方法先用canny边缘检测算法得到视频中物体的边缘,然后用HoughLine直线检测算法从边缘中检测直线,但是传统方法只能在背景简单的情况下使用。真实的场景下,屏幕外的背景复杂,屏幕区域的边缘本来应该是由四条直线组成,但是传统方法找到的边缘直线经常是多条长短不一的直线并且直线间也存在宽窄不等的间隙。此外,传统方法也面临着屏幕区域外的背景和屏幕区域内的图像中的直线干扰等问题。因此,本文对传统方法的两个关键步骤进行了改进。
(1) 改进了屏幕区域边缘检测方法。传统的canny边缘检测算法需要设置很多的阈值参数,这些参数要根据实验效果人为设定,一旦参数过多,就很难根据经验设定,另外这些参数只对特定的情形有很好的效果。而深度学习具有表征能力强,不需要人为设定参数,自动获得特征等优点。因此,采用了基于全卷积神经网络的屏幕区域边缘检测方法,获得了很好的检测效果。
(2) 提出一种新的屏幕区域边缘定位算法。传统的轮廓检测算法只能定位闭合轮廓的边缘,适应性有限。此外由于有大量的干扰,传统方法定位屏幕区域的边缘很困难。因此,本文提出一种利用全卷积神经网络产生的屏幕区域边缘图像和屏幕区域位置图像来定位屏幕轮廓的算法,这种算法具有效率高,抗干扰能力强,算法简单等特点。
1 相关工作
本方法实现的一个关键步骤就是检测到屏幕的边缘,边缘检测算法的研究历史很悠久,也是计算机视觉的基本研究课题之一。早期的方法是基于sobel算子的边缘检测方法[1],以及被广泛采用的canny检测算法[2]。基于信息论的算法有gPb分割算法[4]、pb算法[5]。有的算法依赖人类设计的特征,比如,BEL算法[6]、Multi-scale[7]和StrucutredEdge[8]。文献[20]依靠视频前后帧的关系定位屏幕范围,取得了很好的效果。还有很多很多基于卷积神经网络CNN(Convolutional Neural Network)的边缘检测算法,比如,N4-Fields[9], DeepEdge[10],Fastmask[11],SGN[12]。文献[16-19]进行图像的语音分割。有的采用全卷积神经网络,例如,HED[13]、RCF[14]、CASENet[15]、Mask r-cnn[21]。这些方法把卷积层的输出接入一个side output 层,side output层由一个1×1的卷积层,一个deconv层和一个softmax层组成,每层side-output进行融合,由于利用了多尺度的信息,因此取得了很好的效果。
2 屏幕区域边缘检测网络
屏幕区域的边缘检测和基于深度学习的边缘检测有很多的不同,最主要的区别是:(1) 基于深度学习的边缘检测目标是得到通用物体的边缘(多种物体的边缘),而屏幕的边缘检测只要得到屏幕区域的边缘图像即可(只有屏幕区域的边缘),因此需要神经网络排除其他物体的边缘。(2) 虽然神经网络能够排除大部分其他物体的边缘,但是还是存在部分干扰。如图2所示,fusion-output是神经网络输出的屏幕区域边缘图像,其中存少量其他物体的边缘,因此只用fusion-output无法得到正确结果,我们需要神经网络输出屏幕区域的位置信息帮助定位(也就是side-outout 5)。

原图 神经网络输出的fusion-output 神经网络输出的side-outout 5图2 屏幕区域边缘图像
2.1 网络结构
网络通过修改VGG-16而来,VGG-16网络由13个卷积层,和3个全连接层组成,VGG-16网络不但在分类问题中表现优异,而且容易应用到其他场景[15],比如物体检测和图像分类。本文的网络对VGG-16的修改主要有:
(1) 移动设备性能差,而VGG-16是一个通用的神经网络框架,VGG-16模型对于移动设备来说太大了,而屏幕边缘检测只需要网络能检测屏幕区域到边缘的直线即可,因此减少VGG-16每一层卷积核的数量对屏幕区域边缘检测也不会造成太大影响。在实验部分也测试了不同卷积核的数量对最终结果的影响以及运行速度,而本文最终采用的网络结构如图3所示。

图3 本文采用的网络结构
(2) 去掉了VGG-16的第五个max-pool层,和后面的全连接层。主要原因是,加入max-pool 5层会使输出的side-output大小缩小为原来的1/32,经过32× deconv层后,会使得精度大大降低,对结果不利。
(3) 在Conv1-2、Conv2-2、Conv3-3、Conv4-3、Conv5-3五层后面接了一个1×1-1的卷积层进行降维,这等于对所有卷积核输出的结果做加权求和,同时权重由网络学习得到。之后接一个deconv层,对feature map进行上采样,使得feature map和原图一样大。
(4) 所有5个上采样得到的结果进行concat,之后用一个1×1-1的卷积层进行特征图的融合,最后使用一个sigmoid输出屏幕区域边缘图像(图3的fusion-output所示)。这里1×1-1的卷积的参数可以自动学习,也可以人工指定,本文中采用人工指定的方式,具体值在2.2中说明。
(5) 在Conv5-3之后的deconv层连接一个sigmoid layer输出屏幕区域位置图像(如图3的side-output 5),side-output 5得到的屏幕区域边缘位置不够精细,但是作为高层的输出比fusion-output少了很多干扰,因此可以当作屏幕区域位置图像使用。
2.2 损失函数设计
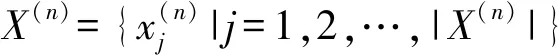
(1)
式中:
(2)

下式表示各层第j个像素点融合为fusion-output的第j个像素点的值时各层的权重,其中w1=w2=w3=w4=0.2,w5=0.28。
(3)
(4)
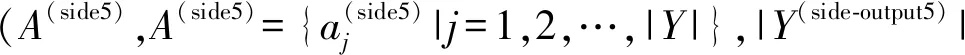
(5)
式(6)是最终的损失函数,该损失函数删去了HED[13]中损失函数的低层部分,保留了side-output 5。在实验部分解释了原因和实验结果。
L(W)=L(side 5)(X(side 5);W)+L(fusion)(X(fusion);W)
(6)
2.3 训练数据
本文采用部分真实场景的图片和部分合成图片的方式自制数据集。合成的图片主要采用了不同的背景,和不同的前景图片合成,其中前景图片加上平移、旋转、透视变换。背景图片进行随机的裁剪,合成的图片还进行了反转操作来扩充数据集,这种自制数据总计有10万幅,手工标注的真实场景数据总计2 000幅。另外有500幅真实场景的图片作为测试集。
3 屏幕区域边缘定位算法
主要利用fusion-output和side-output 5得到屏幕区域的边缘。整体流程如图4所示。

图4 边缘定位算法整体流程图
(1) 屏幕区域边缘直线检测 先对Fusion-output生成的单通道图进行阈值化,大于阈值t的点的像素值为255,小于t的点的像素值为0,其中的阈值t是Fusion-output中像素点的值大于30的点的均值,设阈值化后的图像为Ft,然后用Hough直线检测算法在Ft中检测直线,但是同一条直线,也会被检测为很多长短不一,有重叠、有间隙的直线,因此需要对检测到的直线进行合并。
合并方法:
① 对检测到的直线根据长度进行排序。
② 找到最长的直线,删除所有比这条直线短且和这条直线重合的直线(重合判断方法在下文详述)。
③ 重复步骤①和②,直到最后一条直线为止。
④ 记录边缘直线集合SI。
判断重合方法:
① 计算较短直线两个端点到长直线的距离,记为L1和L2。
② 设定两个长度阈值ps和pm(pm>ps,在本文中pm=10,ps=5)。
③ 如果L1>pm或L2>pm,判断为不重合;如果L1 说明:只用一个阈值来区分两条直线是否为同一条直线会带来问题。因为fusion-output屏幕区域内外边缘之间有宽有窄,如果长度阈值取得较大,直线合并效果好,但是在屏幕内外边缘距离较窄的情况下,容易把内外边缘也错误合并;如果阈值取得较小,直线合并效果差,产生的干扰多。因此采用两个直线阈值,可以获得很好的内外边缘直线。 (2) 产生候选框 图5显示了产生候选框集合的流程。在图片中选取一个点t(本文中设置t点为屏幕中心点),称之为目标点,SI集合中选两条直线la和lb, 直线la和lb的交点为pi,选取la的一个端点为pa,选取lb的一个端点为pb,交点pi到pa的向量称为pipa,pi到pb的向量称为pipb,pi到目标点t称为向量pit,计算满足公式pit=a·pipa+b·pipb,a>0且b>0的端点pa和pb。如果有多个端点满足要求,则取到交点pi长度最大的端点。记录pi、pa和pb,作为一个角结构。依次对SI集合中剩余的直线进行处理。 图5 产生候选框集合的流程 从前面得到的角结构中,取两个不含相同直线的角结构,为pi1、pb1、pa1和pi2、pb2、pa2,其中pb1和pb2位于点pi1和pi2组成的直线一边,pa1和pa2位于直线一边,如图5所示。计算等式pi1pi2=a1·pi1pb1+b1·pi1pa1,pi2pi1=a2·pi2pb2+b2·pi2pa2,若a1、b1、a2、b2都大于0,则这两个角结构可以组成一个候选框,如图5最后一步所示。计算pi1pb1和pi2pb2的交点以及pi1pa1和pi2pa2的交点,得到四边形的另外两个交点,保存四个交点,得到候选框,重复对所有角结构进行计算。最终所有的候选框总算包围着目标点t。 (3) 候选框评分方法 我们主要用fusion-output和side-output 5对候选框打分,式(7)计算四边形一条边的得分,其中点(xi,yi)位于直线Line(i)上,pj(xi,yi)是点(xi,yi)在图像j中的像素值(本文中,j为fusion-output或side-output 5),|line(i)|是直线Line(i)上点集的个数。式(8)计算一个候选框的得分,Line(i)为候选框Rect(q)的边缘线。 (7) (8) 首先在side-output 5对候选框进行打分,即对所有候选框计算M(q,j)j=side-output5,最高得分乘0.9为阈值a,排除得分小于阈值a的候选框,之后对剩余的候选框在fusion-output中打分,对剩余的候选框计算M(q,j)j=fusion-output,得分最高者为最终结果。 之所以采用这种方案是因为,fusion-output中屏幕边缘较为精细,但是错误很多,side-output 5的边缘粗,但是能准确反映边框的大概位置,如果候选框只用fusion-output计算评分,可能会出现画中画的侯选框得分最高。产生这种问题的原因是,fusion-output是由各层side-output融合而成,低层错误的边缘可能会融合成像素值很大的错误边缘,导致最终的评分错误。因此我们先用side-output 5得到一些位置准确,但是可能包含一些由屏幕区域内边缘和外边缘组成候选框。之后用fusion-output评分,因为内边缘和外边缘组成候选框会穿过屏幕边框的部分,而屏幕的边框部分的像素值很低,导致评分降低,只有那些连成一个整体的全是由屏幕内边缘组成或全由屏幕外边缘组成的候选框,才会在fusion-output中得到很高的评分,之后选取评分最高的那个。因此最终结果要么是屏幕区域内边框组成的边缘,或者是屏幕区域外边框组成的边缘。 我们利用了TensorFlow来实现网络,先在网络最后的卷积层后加上Maxpool-5层、全连接层、soft-max层并用ImageNet数据集对网络进行物体检测训练,然后用预训练好的参数初始化我们的网络,side-output1-5中的1×1conv采用期望为0、方差为0.01的高斯分布来初始化,bias=0。Fusion-output中的1×1convd用来融合各层的结果,其中ai为side-outputi(i为1~5)对应的参数,其中a1=a2=a3=a4=0.2,a5=0.28,不参与训练。deconv-layer用 bilinear初始化。网络剩余的超参数为:minibatch size=10,learning rate=1e-6,每训练10 k次除以10,momentum=0.9,weight decay=0.000 2,所有参数的训练在1块NVIDIA TITAN X GPU上完成。 我们测试了不同的卷积核个数对fusion-output和side-output 5的影响,表1显示了三种网络的结构,每种网络都以VGG-16模型为基础,只是改变了卷积核的个数。使用同样的屏幕区域边缘定位算法计算最终的结果。 表1 三种不同的网络大小 经过测试表2显示了在一台iphone8手机上三种网络的计算性能。 表2 三种网络的性能 图6显示了三幅不同的输入图在三种不同网络结构中得到的结果,图片1在三种模型的最终结果中,都把屏幕区域的左边缘标记为外边框,右边缘标记为内边框,我认为产生这种结果的原因是,左-内边框和右-外边框都不明显,导致fusion-output中对应的像素值较低,最终候选框在fusion-output上得分较低,因此我们的算法会优先选择边缘清晰的边框。图片2在三种模型的最终结果中下边缘都不对,产生这种结果的原因是本文中目标点t设定为屏幕中间,导致目标点t在下边缘的下面,而边框的要求是必须包围目标点t,因此导致错误。图片3是不含有屏幕区域的图像,Model-A不能准确地区分,但是Model-B,Model-C的side-output 5、fusion-output都不会产生明显的响应,可以区分这种不含屏幕的干扰。 图6 三种不同网络的结果 在HED[13]边缘检测方法中,loss的计算公式如下: (9) 我们测试了Model-B网络采用HED-loss和式(6)的输出,如图7所示。 HED网络是一种通用的边缘检测方法,通过让低层的side-output参与loss的计算,可以让低层产生的更精细的结果参与最后的融合,得到非常好的边缘检测效果。但是,我们需要的只是检测到屏幕的边缘,如果让低层也参与loss计算,最后的结果会因为低层的影响而产生很多干扰。而且,不同层检测到的边缘的粗细程度也不一样,如果简单地加以融合,HED-loss产生的fusion-output屏幕边缘较粗,很容易无法区分屏幕内外边框的边缘。而我们的loss边缘精细,且干扰更少。 为了证明算法的有效性,我们将屏幕区域定位算法(Model-B)和三种基于特征点的目标跟踪算法进行对比。三种目标跟踪算法为:CamShift[22],Online Boosting(Boosting)[23],Multiple Instance Learning(MIL)[24] 具体来说,我们手动标记视频帧的屏幕区域,采用图像检索的评价标准,正确率=(计算结果中是屏幕区域的像素个数)/(计算结果中总的像素个数),召回率=(计算结果中是屏幕区域的像素个数)/(屏幕区域中总的像素个数)。我们将所有视频帧的平均结果作为最终结果记录于表3中。结果表明,由于深度学习的应用,本方法速度较其他三种慢,但是准确率、召回率和F-score都有明显提高,此外,我们的方法相比其他三种不需要设定大量的参数,使用简单。 表3 不同方法在屏幕检测上的性能对比 本文提出了一种新的基于深度学习的定位屏幕轮廓的方法,利用深度学习极强的表达能力,产生好的边缘图像和位置图像,并用屏幕轮廓定位算法定位屏幕轮廓。实验表明,我们的方法在面对非屏幕的矩形物体的干扰下,也能产生很好的效果,即使图像背景复杂,边缘干扰严重,也能成功获得很好的结果。本方法计算速度快,扩展性强,可以用同样的框架检测其他形状的物体,拥有广泛的应用前景。
4 实 验
4.1 不同的网络大小



4.2 不同的loss 函数
4.3 相关方法对比实验

5 结 语
猜你喜欢
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
临床骨科杂志(2020年1期)2020-12-12
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
