
基于标签传播的蚁群优化算法求解社区发现问题
2019-06-17 09:29顾军华武君艳许馨匀张素琪
计算机应用与软件 2019年6期
顾军华 江 帆 武君艳 许馨匀 张素琪
1(河北工业大学人工智能与数据科学学院 天津 300401)2(河北省大数据计算重点实验室 天津 300401)3(天津商业大学信息工程学院 天津 300314)
0 引 言
自然界中各领域都存在复杂的网络结构,如社交网络、蛋白质的相互作用网络等[1]。挖掘这些网络结构中隐含的信息成为既有难度又有意义的课题[2]。自Newman等[3]提出社区概念以后,复杂网络的社区发现研究逐渐成为最热门的课题之一。社区发现算法可以对网络中的社区结构进行检测,从而获得网络的隐含信息,具有重要的实际意义。目前,挖掘网络中的社区结构可以应用多种算法,但这些算法均有不足。比如以GN算法为代表的划分算法耗时较长;以FN[4]算法为代表的模块性优化算法复杂度过高;标签传播算法速度虽快但不稳定等。而蚁群算法由于采用了分布式正反馈并行计算机制,具有较强的鲁棒性和稳定性,自2007年被Liu等[5]首次用于挖掘社区聚类,进而求得社区结构以来,被频繁地应用于社区发现领域,但也逐渐发现蚁群算法存在收敛速度慢,求解精度低的问题。
针对以上问题,He等[6]将蚁群算法与模拟退火及标签传播算法结合,提出了MABA算法。它以SABA作为子方法,通过优化局部模块度函数Q,在已获得的网络社区结构上构建一个上层网络,再将SABA作用于新的上层网络,如此迭代直到Q值不再增加为止。MABA虽然可以缓解模块度优化带来的分辨率限制问题,但是算法求解精度较低。Chang等[7]把遗传算法中染色体解的表达形式应用于蚁群算法,提出MACO算法。每只蚂蚁跳跃地选择出下一个要到达的点编号,以此填充解向量。该方法虽能得到较好的社区划分结果,但是解码步骤耗时严重。Mu等[8]对MACO算法进行改进并提出IACO算法。采用基于学习的策略尽可能减少探索阶段的冗余计算,但是解码耗时问题仍然没有解决。Zhou等[9]提出了antBCO算法,该算法在每个节点上存储一个标签列表作为蚂蚁移动的禁忌列表,并在标签列表上执行后处理操作,最终获得重叠的社区结构,但是该算法收敛速度慢且时间复杂度高。李有红等[10]提出ELPA-ACO算法挖掘重叠社区结构,该算法先应用标签传播算法获得初始信息素和蚂蚁初始位置,再结合多种属性改进蚂蚁转移策略,但标签传播产生的初步社区个数决定最终社区个数,导致算法适应性较差,求解精度低。因此,上述算法虽有所改进,但仍存在求解精度低和收敛速度慢的问题。
为了使蚁群算法的求解精度和收敛速度得到进一步改善,本文提出一种基于标签传播的蚁群优化算法(Ant Colony Optimization Algorithm Based on Label Propagation,BLP_ACO)。首先,该算法提出一种新的解向量表达方式,蚁群的任务是通过确定节点标签来构造解向量。在解的构造阶段提出基于节点凝聚性的蚂蚁转移策略,降低蚂蚁转移过程中的随机性,提高算法的求解精度。为使算法快速收敛,将标签传播思想引入到蚁群搜索过程,提出一种基于局部社区规模和社区相似性偏向的蚂蚁定标策略,结合信息素和启发式信息,综合确定节点标签。在解的优化阶段采用基于模块度优化的合并策略,进一步改善解的质量。最后,更新信息素时在社区内部的所有边上滞留信息素。
1 传统蚁群算法
传统蚁群算法用一维向量来存储解,向量中存放的元素是索引值对应节点的同社区节点编号。在蚁群的搜索过程中,随机遍历网络,依据概率公式确定与蚂蚁当前所在节点属于同一社区的节点,并构造解向量。设节点i和节点j是网络中的两个节点,蚂蚁从节点i转移到节点j的概率公式如下所示:
(1)
式中:vi、vj代表节点i、节点j,N(i)代表节点i的邻居节点集,τij(ηij)代表节点i与节点j之间的信息素(启发式信息)。参数α和β分别为信息素和启发式信息的相对重要程度。在蚁群完成一次迭代之后,模仿自然界中信息素挥发和释放过程,先对网络中的信息素减少一定比例,再对当次迭代产生最优解的蚂蚁走过的路径滞留信息素,指导后续蚂蚁的行动,体现蚁群算法的正反馈特性[11]。蚁群产生的所有解向量构成解空间,算法最终输出解空间中的最优解。信息素更新过程定义如下:
τij=ρτij+Δτij
(2)
式中:ρ是一个常数,ρ∈(0,1),1-ρ代表信息素的挥发率,Δτij为要在节点i和节点j之间边上滞留的信息素。
但是,传统蚁群算法的解码效率低,蚂蚁仅依据两个节点的相似度来构造解向量,导致算法求解精度低、收敛速度慢,更新信息素时仅在蚂蚁走过的少数边上滞留信息素,在一定程度上限制了蚁群的搜索空间。基于以上几点不足,本文提出了基于标签传播的蚁群优化算法。
2 基于标签传播的蚁群优化算法
BLP_ACO与传统蚁群算法的不同主要体现在三个方面:首先,解的表达形式不同。BLP_ACO所采用的解向量表达形式与传统形式相比,解码效率高。其次,解向量的构造过程不同。本文在构造阶段提出了基节点凝聚性的蚂蚁转移策略和基于局部社区规模和社区相似性偏向的蚂蚁定标策略,提高算法的求解精度,使得算法快速收敛。再次,在解的优化阶段采用基于模块度优化的合并策略,进一步提高算法精度。最后,信息素更新策略不同。BLP_ACO在社区内部的所有边上都滞留信息素,扩大蚁群的搜索空间。
2.1 解向量的表示
目前已有蚁群算法采用的解向量,需要经过复杂度高的深度优先或广度优先搜索来解码,才能得到最终社区划分。本着高效易操作的原则,BLP_ACO也采用一维数组来存储解向量,向量中的元素表示索引值节点所属社区的标签。两种表达形式对比如图1所示。

图1 网络示例图及解向量表示
图1(a)所示网络中包含8个节点,明显划分为{1,2,3,4}、{5,6,7,8}两个子社区。图1(b)代表传统蚁群算法的初始解向量,算法初期设每个节点属于不同社区,因此向量中的元素都用0填充。经过蚁群搜索完成解向量的构造,输出形式如图1(c)所示,设索引值从1开始,并与元素值一一对应,即:节点1与节点2属于同一社区,节点2与节点3属于同一社区,以此类推。若要得到最终社区划分结果,还需通过深度优先或广度优先搜索对解向量进行解码,时间复杂度为O(n2),当问题规模较大时,解码步骤需耗费大量时间。
为了提高解码效率,BLP_ACO在解向量中存放的元素,表示索引值对应节点所属社区的标签,如图1(d)所示。算法初始化每个节点一个唯一标签,设向量索引值从1开始。图1(c)表示算法的输出解向量,只需遍历一次解向量,依据元素值对节点进行分组,就可得到社区划分结果,时间复杂度仅为O(n),与传统表达形式相比,有效提高了解码效率。
2.2 解向量的构造
传统蚁群算法收敛速度慢导致耗时严重的问题亟待解决,而Symeon[12]比较了17种常见社区检测算法的复杂度和适应社区规模的大小,发现标签传播算法(LPA)具有线性时间复杂度,同时实验证明LPA在5次迭代更新标签之后开始收敛,此时有至少95%的节点都划分到正确社区[10]。因此BLP_ACO引入标签传播思想,提出一种基于节点凝聚性的蚂蚁转移策略和基于局部社区规模和社区相似性偏向的蚂蚁定标策略。同时应用标签传播机制和蚁群算法的正反馈机制共同指导蚂蚁的搜索行为,使每只蚂蚁在构造解的过程中,也对网络中的节点迭代确定5次标签,以改善算法的收敛速度,提高算法的效率和精度。
2.2.1基于节点凝聚性的蚂蚁转移策略
由于引入的标签传播机制自身具有随机性,会导致算法精度不高。为了避免这一现象,本文提出了基于节点凝聚性的蚂蚁转移策略,将网络中的所有节点按照节点凝聚性度量值升序排序,作为蚂蚁的转移顺序。相关定义如下所示:
定义1节点吸引力。节点i的吸引力定义如下:
(3)
式中:di表示节点i的度数,N是网络中的节点总数。节点吸引力的取值范围是[0,1)。当节点i是独立节点或者网络中只有一个节点时,该节点吸引力值为0;当节点i与网络中其余各点都有边连接时,该节点吸引力值趋于1。
定义2聚类系数。节点i的聚类系数定义如下:
(4)
式中:Ki表示节点i的邻居节点数,Ei表示网络中真实存在于节点i的所有邻居节点之间的链接数,分母部分则表示节点i的所有邻居节点之间所有可能的链接数的2倍。聚类系数的取值范围是[0,1],当节点的度数为0、1或其邻居节点之间互不相连时,该值为0;当节点与其邻居节点之间构成完全图时,该值为1。
定义3节点凝聚性度量。节点i的凝聚性度量定义如下:
ψi=ATi×Ci
(5)
式中:ATi表示节点吸引力,Ci表示聚类系数。节点凝聚性度量值表示为节点吸引力和聚类系数的乘积,其中节点吸引力保证了凝聚性强的节点度数相对较大,因此处于大规模社区的可能性较大。聚类系数保证了该节点所属社区的内部连接比较紧密,二者综合决定节点凝聚性,ψi的值越大,表明节点i在网络中的凝聚性越强。

表1 随机转移策略
为了说明基于节点凝聚性的蚂蚁转移策略能降低蚁群转移过程中的随机性,提高算法精度,本文在不考虑信息素的前提下,在图1(a)所示的网络示例图中进行实验对比。本次实验使蚁群分别采用随机转移策略和基于节点凝聚性的转移策略,为其当前所在节点选择其邻居节点中携带个数最多的标签,当此类标签存在多个时,则任选其一,直到网络中的所有节点都满足这个条件为止。本实验中的社区标签用{A,B,C,D,E,F,G,H}表示。当蚁群采用随机转移策略时,蚂蚁转移顺序可以为{2,1,4,3,6,7,8,5},详细信息如表1所示。在第①步,每个节点都被初始化一个唯一标签,分别为{A,B,C,D,E,F,G,H};在第②步,确定节点2的标签,此时节点2选取了节点5的E标签。依次类推(表中斜体加粗的标签表示当前步骤为节点确定的新标签),当算法执行完毕时,所有节点都被划分为一个社区,显然这是一种无效划分。
依据式(5)可以计算出,节点2和节点5的凝聚性度量值均为0.286,节点1、3、4、6、7、8的凝聚性度量均为0.429,将所有节点按照凝聚性度量值升序排列,得到蚂蚁的转移顺序为{2,5,1,3,4,6,7,8},蚂蚁按照此顺序为节点确定标签,结果如表2所示。当算法执行完毕时,得到两个社区,产生正确的划分结果。

表2 基于节点凝聚性的转移策略
2.2.2基于局部社区规模和社区相似性偏向的蚂蚁定标策略
蚂蚁按照基于节点凝聚性的转移策略在网络中移动,并通过为节点确定标签来构造解向量。为了使引入的标签传播机制和蚁群算法的正反馈机制能有机结合,本文提出一种基于局部社区规模和社区相似性偏向的蚂蚁定标策略。蚂蚁为节点i确定标签m的概率公式定义如下:
(6)
式中:n和m代表节点标签,α和β为信息素和启发式信息的相对重要程度,τim是节点i与所有携带m标签的邻居节点之间边上的信息素含量总和;ηim是节点i与所有携带m标签的邻居节点之间的启发式信息总和;NLi是节点i的候选标签集,存放节点i的所有邻居节点携带的标签种类。
(1) 信息素。信息素τ是蚂蚁实现间接通信、完成群体协作的重要媒介[13]。BLP_ACO将信息素放置在边上,并被初始化相同含量。随着蚁群迭代次数的增加,信息素分布越来越不均匀,对后续蚂蚁构造解向量起的指导作用也越来越强。式(6)中信息素τim的计算方式定义如下:
(7)
式中:Ni代表节点i的邻居节点集;label(j)代表节点j所属社区的标签;τij为分布在节点i与节点j之间边上的信息素含量。
(2) 启发式信息。启发式信息η是蚁群在搜索过程中使用的先验性因素,用于辅助蚁群快速准确地作出判断。BLP_ACO中启发式信息的核心内容为节点间的相似度。“社区”没有精准定义,只是社区内部节点的相似度要强于社区之间节点的相似度。类比于社交网络中,两个个体相似度高,不仅指这两个个体共同朋友多,也说明共同陌生人多。因此,本文采用综合考虑二者的皮尔逊相关系数[14]来衡量节点的相似度。两节点的皮尔逊相关系数定义如下:
(8)

(9)
式中:Ni表示节点i的邻居节点集;label(j)表示节点j所属社区的标签;C(i,j)表示皮尔逊相关系数。
综上所述,蚂蚁在衡量某标签被选择的概率时,不仅通过信息素借鉴了之前蚂蚁产生的优质解,也通过启发式信息衡量了待定标节点与所有携带该标签的邻居节点构成的局部社区之间的相似度。同时,信息素与启发式信息的求和操作体现了携带该标签的局部社区规模,改善了算法的收敛速度和精度。
2.3 解向量的优化
蚁群按照上述转移策略和定标策略,已经可以获得相对较好的社区划分结果,但是为了进一步提高算法的求解精度,借鉴FN算法的思想,提出了基于模块度优化的合并策略。
BLP_ACO在蚁群完成每次迭代之后,采用基于模块度优化的合并策略,对当次迭代产生的最优解进行优化。本文将FN算法分别应用于社区发现领域常用的4种数据集,通过实验观察FN算法的特性。模块度伴随社区合并次数增加的变化曲线如图2所示。


图2 模块度变化趋势
图2中各横轴表示社区合并次数,纵轴表示模块度的值。算法每次合并使模块度增量最大或者减小最少的两个社区,随着社区合并次数的增加,模块度从一个负值逐渐增至最高点,又在后期合并至一个社区的过程中迅速降至最低点,曲线在达到峰值之前一直呈现上升趋势,且只有一个峰值。由于BLP_ACO旨在寻找最优社区划分,经上述分析,优化阶段只需要执行合并操作至模块度达到最大时结束,这样能减少不必要的合并操作,进一步提高算法效率和求解精度。
2.4 信息素更新策略
由于BLP_ACO中蚁群的任务不再是为当前节点选择同社区节点,而是为节点确定标签,信息素应用于标签的选择。因此本文将信息素更新策略调整为:在蚁群完成每次迭代之后,运用式(2)更新网络中的信息素,先对网络中的信息素挥发一定比例,再寻找当次迭代产生的最优社区划分,在社区内部的所有边上滞留信息素。BLP_ACO将本次迭代产生的最优解对应的模块度作为信息素的滞留量。定义如下:
(10)
式中:Q()是模块度函数[15];L_best代表蚁群本次迭代产生的最优解。
为了证明信息素对后续蚁群的指导作用,本文仍在图2中的数据集上进行实验。在数据集的社区划分结果中,分别统计社区内部边上信息素的平均含量与社区间边上信息素的平均含量,对比结果如图3所示。

图3 社区内部与社区间边上信息素平均值对比
图3显示了BLP_ACO在各数据集上求得近似最优社区划分时的信息素分布柱状图。横轴表示社区(其中最后一个表示社区间),纵轴表示边上信息素含量的平均值。从图中易看出,不同数据集各社区内部边上信息素的平均含量基本相当,且明显高于社区之间边上信息素的平均含量。因此,BLP_ACO中的信息素有效指导了蚂蚁搜索近似最优解的过程。
3 算法流程与复杂度分析
3.1 算法流程
算法伪代码如下:
Input: G(V,E) /*输入邻接矩阵A和算法相关参数*/
Output: 社区划分结果
1. 初始化算法相关参数和解向量;
2. 初始化NodeCoherencyList为空;
/*节点凝聚性度量值列表*/
3. 初始化updat_order为空
/*蚁群转移路径列表*/
4. For each v∈V do
5. 运用式(3)-式(5)填充NodeCoherencyList;
6. 对NodeCoherencyList升序排序,将对应节点编号填充updat_order;
7. For max_t do
/*蚁群迭代次数*/
8. For ant do
/*蚁群规模*/
9. t=0;
/* t为每只蚂蚁的迭代次数*/
10. If t<5 do
/*每只蚂蚁迭代定标5次*/
11. For i ∈ updat_order do
12. 初始化i_Candidate_coms列表为空;
/*存放当前节点的候选标签集*/
13. 运用式(6)-式(9)计算每个标签被选择的概率;
14. 轮盘赌策略确定节点标签;
15. End for
16. t++
17. End if
18. 运用式(11)计算模块度;
19. End for
20. 优化蚁群产生的局部最优解,得到L_best;
21. 运用式(2)、式(10)依据L_best更新信息素;
22. End for
3.2 时间复杂度
设网络节点数为n,边数为m,节点平均度数为2m/n,蚁群迭代次数为max_t,蚁群规模为ant。BLP_ACO算法主要包括三部分:第一部分为计算节点凝聚性度量值,需要遍历网络中的所有节点以及每个节点的所有邻居节点。因此第一部分的时间复杂度为节点数与节点平均度数的乘积,近似为O(m)。第二部分为蚁群构造解向量,首先遍历网络中的所有节点及其邻居节点,通过计算确定节点标签,这部分时间复杂度是O(max_t×ant×m)。其次是优化阶段,需要遍历蚁群划分的初步社区,时间复杂度是O(max_t×p2),p是蚁群划分的初步社区个数。因此第二部分的时间复杂度为O(max_t×(ant×m+p2))。第三部分是更新信息素,需要遍历网络中所有的边,并检测该边的端点节点是否属于同一社区。因此第三部分时间复杂度为O(maxt×m)。综上所述,BLP_ACO的时间复杂度为O(max_t×(ant×m+p2))。
4 实验结果与分析
为了检测BLP_ACO算法在收敛速度和求解精度方面的性能,本文将BLP_ACO与MACO[7]、IACO[8]和SOCP_LPA[16]算法分别在6种真实网络和LFR人工基准网络上进行实验对比。所有实验算法均在Spyder工具中使用Python语言编程实现,实验环境是:Window 7系统,Intel Core i5-3230M CPU @2.60 GHz,4 GB内存的PC机。
4.1 评估方法
4.1.1模块度
模块度是一种衡量社区划分质量的量化指标。模块度[15]的计算公式如下:
(11)
式中:Lc表示社区c内部的边数,m表示网络的边数,Dc表示社区c内部节点的度数总和,L表示全部社区集合。Q值越接近于1,表示划分结果越好,与真实网络划分越接近。
4.1.2归一化互信息
归一化互信息NMI[17]常作为评价指标应用于社区发现领域。在LFR人工基准网络中,用NMI来衡量真实社区划分与算法检测到的社区划分之间的相似度。计算公式如下:
(12)
式中:N代表LFR网络中的节点总数,A代表网络的标准分区,B代表算法求得的分区。CA(CB)代表A(B)种分区对应的社区总数。R是表示两种分区相似程度的混合矩阵,矩阵元素Rij表示同时存在于A分区的社区i和B分区的社区j中的节点个数。Ri.表示矩阵R第i行元素的求和,R.j表示矩阵R第j列元素的求和。NMI(A,B)的取值范围是[0,1],当两种分区完全相同时,取值为1。NMI取值越大,表示算法的求解精度越高。
4.2 数据集
4.2.1真实网络
为了验证BLP_ACO算法提高了求解精度,本文选取6种真实网络用于实验,这些真实网络是社区发现领域常用的数据集,具体信息如表3所示。
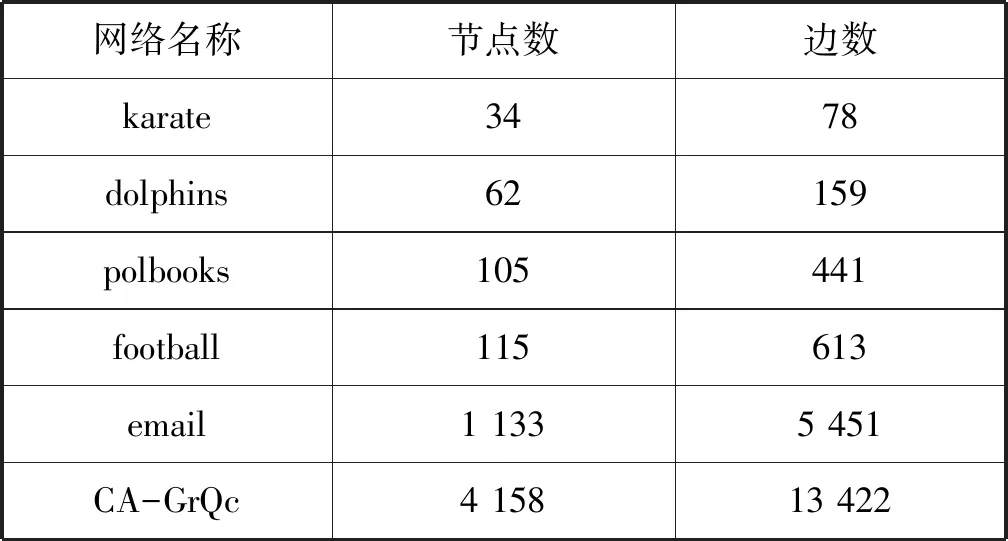
表3 数据集介绍
4.2.2LFR人工基准网络
Lancichinetti等[18]提出的LFR人工基准网络是一种常用于社区发现研究中的模拟网络。生成该网络的算法可以调整参数,使得生成的人工基准网络具有不同的规模和清晰度。LFR人工基准网络的相关参数介绍如表4所示,其中混合参数mu是处于[0,1]之间的数,该数值越大,表明生成网络的社区结构越不清晰,算法越难检测出准确的社区结构。用于本次实验的4组LFR网络的详细介绍如表5所示,其中每组对应15个mu值不同的网络,mu的取值范围是[0.1,0.8]。在相同节点数量的网络500S(2000S)和500B(2000B)中,后者的每个社区中包含的节点数量相对较多。

表4 LFR人工基准网络的相关参数

表5 LFR人工基准网络描述
4.3 实验结果对比
该算法设置蚂蚁迭代次数max_t=10,蚂蚁只数ant=10,概率选择公式中信息素与启发式信息的权重因子α=1、β=2,信息素滞留率ρ=0.8,信息素参照MMAS[19]的模型控制在[0.1,6.0]之间。
4.3.1真实网络的模块度对比
本文在表3中的数据集上应用4种算法,进行100次社区发现实验,并对模块度的平均值与最高值进行比较。对比结果如表6所示,其中每个网络对应两行数据,第一行是平均模块度值,第二行是最高模块度值,加粗斜体数据为每行的最优值。由表6可知,BLP_ACO在前5种网络都取得最好结果,尤其在karate和email网络上明显优于其他算法。虽在较大规模的CA-GrQc网络上没有取得最优值,但也仅次于最优值,但与最优相值差较少。因此,BLP_ACO算法具有较高的求解精度。

表6 模块度对比

续表6
4.3.2LFR人工基准网络的NMI对比
本次实验在表5中的LFR人工基准网络上应用4种算法,进行100次社区发现实验,并对平均NMI值进行比较。对比结果如图4所示,其中横坐标表示不同清晰度的LFR网络,纵坐标表示NMI值。由图4中曲线的整体变化趋势可知,mu值越大,社区结构越模糊,算法的求解精度也都明显下降。

(a) 500S网络的NMI对比

(b) 500B网络的NMI对比

(c) 2000S网络的NMI对比

(d) 2000B网络的NMI对比图4 LFR基准网络上不同算法的NMI对比
由图4(a)可知,mu取值在[0.1,0.3]时,4种算法都能挖掘出相对准确的社区结构;mu取值在[0.3,0.5]时,BLP_ACO与SOCP_LPA的NMI值不相上下,当mu的值大于0.6时,BLP_ACO的NMI值明显高于其他算法。由图4(b)可知,当mu的值在0.7和0.8之间时,BLP_ACO算法略低于SOCP_LPA,但在其他mu值对应的网络上,均优于其他算法。由图4(c)可知,当mu值大于0.7时,MACO算法已经无法挖掘社区结构,IACO与SOCP_LPA算法对应的NMI值也明显低于BLP_ACO。由图4(d)可知,只有当mu值为0.55和0.8时,BLP_ACO的准确度略低于SOCP_LPA,在其他mu值对应的网络上,BLP_ACO均明显优于其他算法。
4.3.3收敛速度对比
本文将模块度函数作为目标函数,当函数值趋于稳定时,算法达到收敛状态。为了证明BLP_ACO与传统蚁群算法相比,提高了收敛速度,本次实验将BLP_ACO、MACO和IACO在4种网络上进行社区发现,分别观察模块度随蚁群迭代次数增长的变化趋势和蚁群迭代10次的运行时间。为了保证实验结果的科学性,3种算法中的相关参数取值均相同,算法在每个网络上重复实验100次,求得平均模块度和平均运行时间。
模块度增长如图5所示,其中横坐标表示蚁群迭代次数,纵坐标表示模块度。

(a) Karate网络的模块度变化

(b) dolphins网络的模块度变化

(c) polbooks网络的模块度变化

(d) football网络的模块度变化图5 算法在各网络上的模块度变化
由图5可知,BLP_ACO在4种网络上使蚁群迭代一次,产生的解均优于另两种算法;图5(a)显示在karate网络上,3种算法几乎都在蚁群第6次迭代时开始收敛,但是MACO与IACO收敛时的模块度低于BLP_ACO;综合观察图5(b)、图5(c)和图5(d)可知,BLP_ACO均在蚁群第3次迭代时开始收敛,另两种算法达到收敛状态时需要的蚁群迭代次数明显多于BLP_ACO,且收敛时的模块度低于BLP_ACO,尤其在polbooks和football网络上相差较多。
运行时间对比如图6所示,其中横坐标表示网络,纵坐标表示运行时间,单位为秒。

图6 不同网络上的运行时间对比
由图6可知,BLP_ACO在不同网络上的运行时间均明显低于MACO与IACO,由于在polbooks和football网络上,BLP_ACO分别需要1.69 s和2.08 s就运行完毕,而MACO由于其解码步骤时间复杂度较高,在两种数据集上的运行时间均超过100 s,IACO虽在MACO的基础上做了改进,但是仍然没有解决解码效率低的问题,在这两种网络上的运行时间分别达到83.25 s和110.32 s,与BLP_ACO算法相差较大。因此,BLP_ACO不仅在算法达到收敛时需要的蚁群迭代次数少,而且算法运行时间短,与传统蚁群算法相比,提高了收敛速度。
5 结 语
本文针对蚁群算法收敛速度慢和求解精度低的问题,提出一种基于标签传播的蚁群优化算法。首先,该算法提出一种新的解向量表达方式,提高解码效率。其次,在解的构造阶段提出一种基于节点凝聚性的蚁群转移策略,降低蚁群转移过程中的随机性,提高算法精度。为使算法快速收敛,提出一种基于局部社区规模和社区相似性偏向的蚂蚁定标策略,结合标签传播思想和蚁群算法的正反馈特性,共同指导蚂蚁为节点确定标签。最后,在解的优化阶段提出基于模块度优化的合并策略,进一步改善算法的解。与目前效果较好的蚁群算法和改进的标签传播算法相比,BLP_ACO在收敛速度和求解精度方面均有明显提升。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
