
面向不均衡数据的动态抽样集成学习算法
2019-06-17 09:30杜红乐
计算机应用与软件 2019年6期
张 燕 杜红乐
(商洛学院数学与计算机应用学院 陕西 商洛 726000)
0 引 言
在日益复杂的网络环境中,网络攻击越来越多样化、复杂化,新的攻击手段层出不穷。网络入侵检测通过分析用户行为来判断用户是否存在威胁,是网络安全体系中的重要组成部分。基于数据的网络入侵检测常采用机器学习将攻击检测问题转换为数据分类问题,然而,在实际中,收集攻击行为数据并进行正确标注比较困难,代价也非常大。另外,新的攻击方法日新月异,及时收集并标注相应的攻击行为样本难度很大,导致训练数据集中包含大量的正常行为数据和少量的攻击行为数据。因此,网络行为数据是不均衡数据。
传统分类算法在均衡数据集下有较好的分类性能,而实际应用中的数据集多是不均衡的,面向不均衡数据分类的研究是数据挖掘、机器学习等领域当前的热点之一[1-13],对不均衡数据的解决方法主要集中在数据层面[1-4]和算法层面[5-13]。
算法层面的方法则是提出新方法或者改进已有算法,减少数据不均衡对分类性能的影响,主要包括代价敏感学习[3-4]、单类学习、集成学习[5-13]等。其中集成学习方法是通过迭代重采样构建多个弱分类器,然后再把弱分类器集成为强分类器,可以较好地提高分类器的分类性能,同时也是解决数据不均衡分类问题的方法[5-11]。文献[5]中结合聚类算法对多数类样本进行欠采样,获得与少数类样本数量相同的样本,并与少数类样本一起构成训练集,采用Adaboost算法获得最终分类器。文献[6]利用抽样概率进行抽样,通过迭代不断修正抽样概率,对于分类错误的样本加大抽样概率,而分类正确的样本减小抽样概率,目的是争取下轮迭代中能选中进行学习。文献[7-10]都是按照一定测量把数据集划分为多个均衡的训练子集,生成多个基础分类器,然后对多个分类器按照一定的规则进行集成,获得最终分类器,从而提高分类性能。该类方法中如何对多数类样本进行重取样构建平衡的训练子集,将对最终的分类器有较大的影响。而以上方法多是采用随机抽取,并且每次抽取样本的概率是相同且保持不变,这样进行抽样无法区分样本的重要性。在算法迭代过程中,样本被错分,则表明样本所包含的信息没有被充分学习,在下一轮迭代中应该加大被学习的力度,而对正确分类的样本说明模型中已经包含该样本的信息,下一轮迭代中应该减小学习,因此,采用动态的抽样概率,区分在下一轮迭代中对样本的重视程度。
基于以上分析,本文提出一种基于动态抽样概率的集成学习算法,并应用到网络入侵检测中。该算法依据抽样概率分布对多数类样本进行欠取样,构建多个均衡的训练子集;获得对应的子分类器,按照一定的参数计算分类效果,计算子分类器权值并获得本轮循环的分类器;然后依据多轮循环所得分类器的分类效果更新多数类样本的抽样概率,进入下一次迭代;最后对多轮循环所得分类器进行集成获得最终分类器。
1 相关工作
1.1 Boosting算法
Boosting算法的基本思想是组合学习,把多个预测精度不高的弱分类器提升到有高精度的强分类器,Boosting家族中最有代表性的是Adaboost算法,基本思想是:每次迭代更新样本的权值,增加错分样本的权重,减小正确分类样本的权重。样本被错分,表明样本包含的信息未被学习或者学习不够充分,因此在下轮迭代加大对错分样本的学习。然而Adaboost算法中,在计算样本权重时,依据本轮循环所得分类器计算分类效果,而没有考虑本次迭代之前所得分类器的分类情况。因此本文所提算法对样本抽样概率的更新综合考虑本轮迭代之前所有分类器的分类效果,能够更准确地更新样本的抽样概率。
在Adaboost算法中,每次迭代中都更新样本的权重,目的是改变下次循环中对样本的学习程度。而本文所提算法在每次迭代中更新样本的抽样概率,目的是改变样本被抽中的概率,也改变在下次迭代中对各个样本的学习程度。因此本文借鉴Adaboost算法中更新权重的思想,在每次迭代中更新多数类样本的抽样概率。
EasyEnsemble算法可以解决不均衡数据问题,属于欠采样算法,是从多数类样本中随机抽取与少数类样本数目相同的样本,然后与少数类样本一起构成训练集,进行多次抽取,获得多个均衡的训练子集,并获得多个基础分类器,然后通过Bagging方法集成得到最终分类器。Balance Cascad算法则是每次训练Adaboost后都会丢弃已被正确分类的多数类样本,经过反复迭代,使得数据集逐渐平衡。
EasyEnsemble算法在每次抽样过程中,每个样本被抽中的概率是相同的。而实际上,对于错分样本需要加大学习力度,即需要加大样本的抽样概率。因此本文所提方法对抽取样本是依据样本的抽样概率分布进行抽取,每次迭代,对错分样本加大抽样概率,而对正确分类样本减小抽样概率,目的在于加大下轮循环中对错分样本的学习。
1.2 抽样概率
对多数类样本按照概率pti进行抽样,抽样概率的总和为:
(1)
因为每个样本被抽中的概率为pti,即被抽中期望为E(pti),因此,对多数类样本的抽样期望值总和为:
(2)
在第一轮抽样是,假设所有样本有相同的抽样概率,为了抽取与少数类样本有相同数量的样本,对多数类样本的抽样概率初始化为|T-|/|T+|。
在每轮迭代过程中,依据分类器对样本包含信息的学习程度修改多数类样本的抽样概率,对样本包含信息的学习程度依据当前分类器对数据集的测试结果来评价。被正确分类表示学习较充分,可以减小该样本抽样概率,否则表示学习不充分或者未被学习,应该加大该样本的抽样概率。由于少数类样本数量较少,因此每个样本都被抽中,即每个样本的抽样概率都为1。
2 入侵检测模型
针对网络行为数据不均衡的问题,本文提出基于抽样概率分布的集成学习方法,提高对未知攻击行为的识别能力。如图1所示,该方法通过多次迭代获得最终入侵检测分类器,在每轮迭代中,依据多数类样本的抽样概率分布进行抽样,抽取与少数类数目相同的样本,然后与少数类样本合并,构成均衡的训练子集。该过程经过多次,得到num个均衡的训练子集。然后采用Adaboost算法训练每个子集,获得num个子分类器,依据各子分类器的分类效果计算权值,加权集成获得本轮迭代的分类器。最后对数据集进行测试,依据测试的结果更新多数类样本的抽样概率,进入下一轮迭代。

图1 入侵检测模型构建
在抽样环节依据样本的抽样概率对多数类样本进行抽样,而不是EasyEnsemble算法中对多数类样本的随机抽样,并且在每次迭代中更新多数类样本的抽样概率。在更新抽样概率时,依据本次迭代之前所得分类器的加权集成分类器的测试效果,而不是依据本轮循环所得分类器的测试结果,这样更有助于最终的集成并获得最终分类器。
3 基于抽样概率集成学习算法
EasyEnsemble算法中对多数类样本进行随机采样,即平等地看待每个样本,可以提高算法的泛化性能。但实际上每个样本的重要性是不同的,即样本包含的信息是不同的,常用解决方法是每次迭代更新样本的抽样概率。原因在于,如果样本被错分则表明该样本中包含的信息没有被学习或者没有被充分学习,因此应该加大该样本被抽中的概率,而对正确分类的样本则相反,应减小样本的抽样概率。这个思想与Adaboost算法中更新样本权值的思想是一致的。本文算法中采用同样的思想更新样本的抽样概率,另外少数类样本全部被选择,则不需要改变抽样概率。
算法1SP-Adaboost算法
输入:数据集train_data={(xi,yi)},xi∈Rn,yi∈Y={-1,1},迭代次数K,子分类器数num。
1. 把数据集划分为多数类T+和少数类T-,|T+|和|T-|是两类样本数目。
2. 初始化多数类样本抽样概率分布:probk-1(p11,p12,…,p1|T+|),p1i=|T-|/|T+|,i=1,2,…,|T+|。
3. fork=1:K
(1) 依据抽样概率分布probk-1从多数类样本中抽取|T-|个样本,采用放回抽样,抽取num次得到num个子集,与少数类样本一起构成训练子集:Bk1,Bk2,…,Bknum,其中,num=┌a×|T+|/|T-|┐ ,a为调控系数;
(2) 对每个子集用Adaboost进行训练,获得num个子分类器:fk1,fk2,…,fknum;

(4) 更新多数类的抽样概率分布:
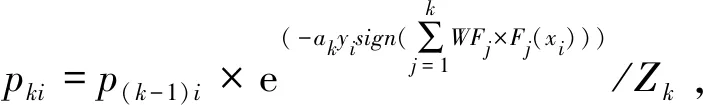
end fork

probk+1(i)=probk(i)×exp(-ak)/Zk=
probk(i)×exp(-0.5×ln((1-Ek)/Ek))/Zk=
probk(i)×|T-|/(2(1-Ek))
(3)
-1,则:
probk+1(i)=probk(i)×exp(ak)/Zk=
probk(i)×exp(0.5×ln((1-Ek)/Ek))/Zk=
probk(i)×|T-|/(2×Ek)
样本抽样概率被更新过后,期望值仍然为|T-|。
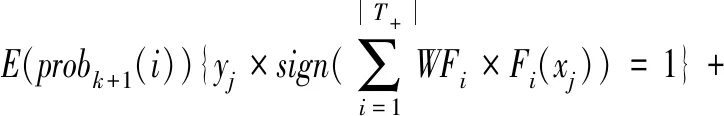
|T-|×(E(probk(i)/(2×(1-Ek))){yj×
由Adaboost算法可知:
因此,E(probk+1(i))=|T-|。
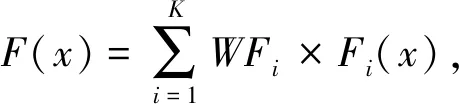
4 实验分析
本文分为两部分,首先选择7组来自UCI的数据集,Car Evaluation、TIC-TAC-Toe Endgame、Liver Disorders、Breast Cancer、Haberman’s Survival、Blood transfusion和Teaching Assistant Evaluation,验证所提算法的有效性,然后把所提算法应用到网络入侵检测公共数据集KDDCUP,两部分的实验数据集的详细情况如表1和表2所示。
表1 实验数据集
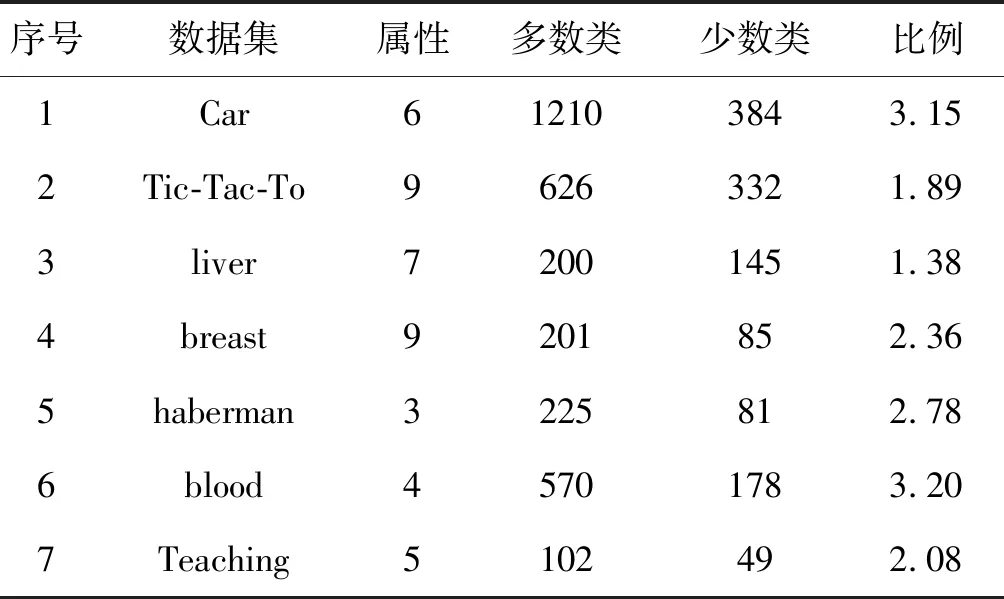
序号数据集属性多数类少数类比例1Car612103843.152Tic-Tac-To96263321.893liver72001451.384breast9201852.365haberman3225812.786blood45701783.207Teaching5102492.08

表2 实KDDCUP数据集
4.1 实验评价指标
分类器的分类性能多采用分类精度作为评价指标,而对于不均衡数据,多关注少数类样本的分类效果,分类准确率不能准确描述分类器的分类性能,针对不均衡数据分类的评价指标多采用Recall、Precision、F-mean、G-mean、ROC曲线和AUC等,这些性能指标是基于混淆矩阵来计算的,对于二分类问题的混淆矩阵如表3所示。

表3 混淆矩阵
依据混淆矩阵可以计算上面评价指标:
(4)
(5)
(6)
(7)
式中:Recall表示正类的查全率,Precision表示正类的查准率,F-mean同时考虑查全率和查准率,只有当两个都大时F-mean的值才较大,可以较好地描述不均衡数据集下的分类性能,实验中F-mean的n取值为2;G-mean综合考虑两类的准确率,任何一类准确率较低时,G-mean的值都会较小,因此能够较好评价不均衡数据集下的分类性能。本文实验通过以上指标及ROC曲线、AUC值来评价算法的性能。
4.2 UCI数据实验结果
本小节主要与Adaboost、Balance Cascad和EasyEnsemble算法进行性能对比,由于本文算法及Balance Cascad和EasyEnsemble算法的结果都有一定的随机性。所以,实验数据是经过5次实验,然后取平均值。另外,对各数据集采用一半作为训练集、一半作为测试集的式样,具体的实验结果如表4所示。从实验结果可以看到,除了liver和Teaching数据集外,本文算法在其他实验结果的大部分指标上均优于其他算法。

表4 算法性能对比1
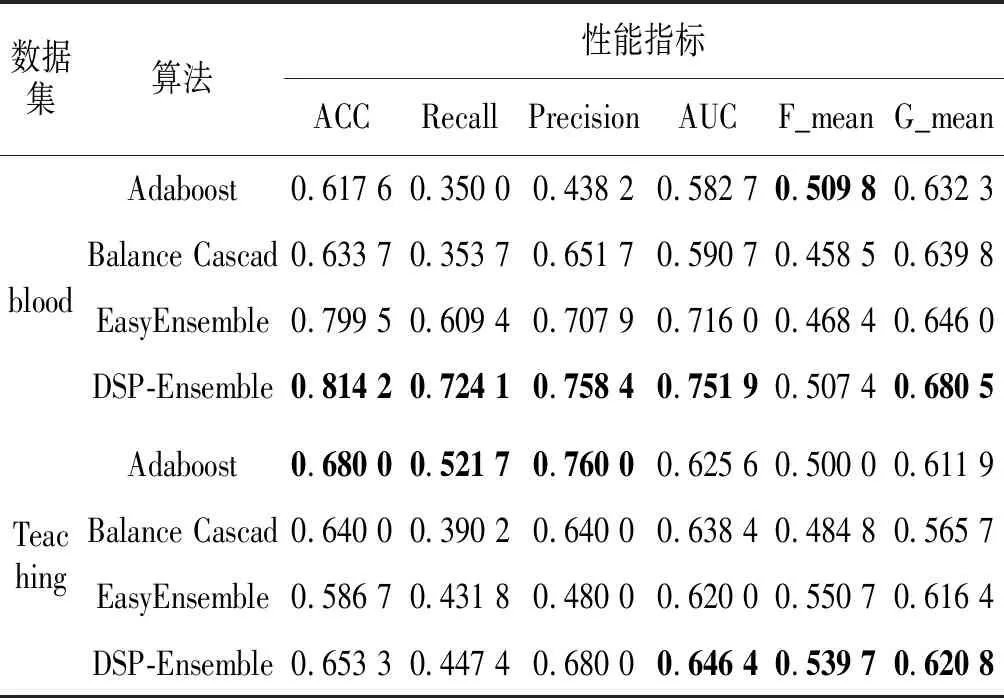
续表4
4.3 KDDCUP数据集
本小节仍然是与Adaboost、Balance Cascad和EasyEnsemble算法进行性能对比,采用KDDCUP数据集的实验结果。由表2可以看到,在测试数据集中增加了部分在训练数据集中没有出现的攻击类型数据,目的是为了验证对新攻击行为的检测情况,详细数据如表5所示,仿真结果是5次实验结果的平均值。图2是ROC曲线的对比结果,ROC曲线仍然是随机的一次。

表5 算法性能对比2

图2 KDDCUP的ROC曲线
为了验证迭代次数对分类结果的影响,设计该部分实验,该部分实验数据仍然是采用5次实验,然后取平均值。如表6所示。可以看出,进行10次以上的迭代时实验结果差别很小,因此,为了减少算法时间,上面的实验数据均是采用10次迭代的实验结果。
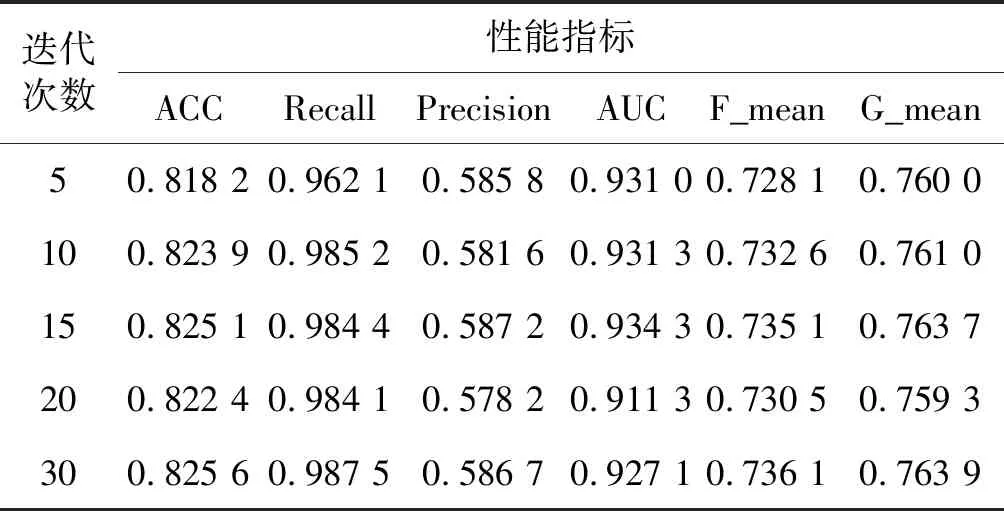
表6 迭代次数的影响
为了验证调控系数对实验结果的影响,设计该部分实验,该部分实验数据仍然是采用5次实验,然后取平均值,详细的实验结果如表7所示。实验结果显示,调控系数为1.5时,各项性能指标比较均衡,因此上面实验所得数据均是在调控系数为1.5时的实验结果。

表7 调控系数的影响
5 结 语
针对网络行为数据不均衡的问题,本文提出一种基于动态抽样概率的集成学习算法,该算法依据抽样概率分布对多数类样本进行重采样,相比随机抽样,能更准确地加大对错分样本的学习。在更新样本抽样概率时,依据所得分类器的集成测试分类效果,而不是只依据本轮迭代所得分类器的分类效果。最后在两种实验数据集上的实验结果也验证本文算法的有效性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
计算机系统应用(2021年2期)2021-02-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
计算机应用与软件(2020年1期)2020-01-14
