
智能教学系统中动态学生模型构建
2019-06-27 06:42王贺张秀梅
科技资讯 2019年9期
关键词:网络学习
王贺 张秀梅
摘 要:随着科技的发展,各个高校网络教学模式日渐增加,而网络教学是在一定教学理论和思想指导下,应用多媒体和网络技术,通过师、生、媒体等,多边、多向互动和对多种媒体教学信息的收集、传输、处理、共享来实现教学目标的一种教学模式。该课题采用Clementine12.0数据挖掘环境中的K-Means方法,分析已有的一定数量的学习行为与效果之间的关联,建立“什么样的学习行为能获得什么效果”的规则,实现了对其学习效果的聚类分析。最终能根据所构建的模型对学生在线学习行为进行学习效果预测,为学习者的个性化学习提供支持,提高其自我调控能力,同时为教师的课堂教学提供资料,作为开展教学的依据。
关键词:预测学习效果模型 K-Means算法 网络学习
中图分类号:G434 文献标识码:A 文章编号:1672-3791(2019)03(c)-0015-03
近年来,随着信息时代的到来。当代学生们的学习模式发生了许多变化,其中网络学习较为流行,它打破了传统教学的局限性。学习新的知识不仅仅可以通过老师们面对面的言传身教,老师和学生也可以通过多媒体和网络技术多边、多向互动。在网络环境下进行教学,要体现学生的主体地位,有利于培养兴趣、启发诱导,并真正调动学生参与教学的积极性、主动性和创造性。网络学习平台除了提供在线学习功能,往往还提供随堂练习、课程作业、课程考试等考试功能。对学习者学习状况的评估将直接影响他们对网络学习的态度、积极性和效果[1]。
“温故而知新”,在线学习成为终身学习的有效途径。在学校教育中,网络学习也日益成为课堂教学的补充[2]。随着计算机与网络的快速发展和广泛应用,网络学习已经是学校教育教学的重要组成部分[3]。该课题主要分析选用相应的学习行为数据,运用数据挖掘分类算法建立“学习行为—效果”预测模型。
聚类分析采用K-Means算法,是一种常用的基于划分的聚类方法,用来根基样本属性值之间的相似度来对样本进行分组。K-Means算法是一种迭代算法,初始的k个类被随机定义之后,将被不断更新,并在更新中被优化,当无法再进一步优化(或达到一定的迭代次数)时算法停止,然后生成模型。先分析聚类样本的数据类型,根据分析结果设计聚类准则函数[4]。该课题以在校大学生为研究对象,通过学生在学习平台中学习C++程序设计来获取学生个人相关信息、总提交次数、通过次数、答题时间、测试成绩及其他学习情况,提取出一些信息,建立模型对学生的学习效果进行分析预测。
1 研究内容
(1)简单的程序设计语言学习测试平台(Online Judge)的搭建,该平台集在线导学、交流互动、在线测试等于一体。
(2)学生学习行为数据的采集,采集学习者学习活动数据,并存储在原数据库中,为数据挖掘做好准备。
(3)“学习行为—效果”预测模型,需要对大量的学习行为数据实施数据挖掘,全面分析在线学习行为与学习效果之间的内在联系。
2 研究方法
(1)搭建简单的学习测试平台,进行信息的积累。
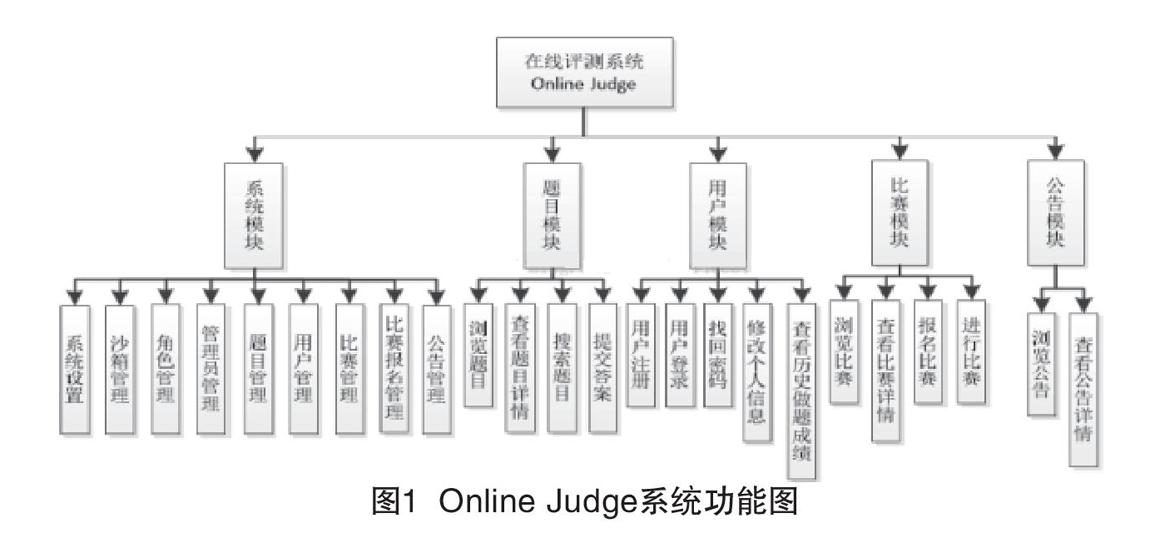
该测试平台模拟Online Judge在线程序评测系统(简称OJ),Online Judge一般指在ACM/ICPC(国际大学生程序设计竞赛)等一系列各种程序算法编程竞赛比赛中,用于自动化判断选手程序的正确性,并得出时间内存消耗等各项效率指标。Online Judge系统大概功能如图1所示。
模拟Online Judge系统的搭建,提供了一个C++练习的平台,实现注册用户平时训练以及比赛的相关功能。具体数据包括:用户账号、密码、邮箱、昵称、注册时间、总提交次数、通过次数等。该功能主要是为了注册用户平时训练,用户可以自由选题。通过这个简单的学习测试平台可以收集到该课题以后研究所需的数据,为最后的“学习行为—效果”预测模型打下坚实的基础。
(2)学习行为数据的采集。
采集学习者学习活动数据,并存储在数据库中,为数据挖掘做好准备。具体字段为“姓名/User”“题目名称”“题目考核状态”“提交题目次数”“题目正确次数”。
分别采集测试平台的10月15日、10月26日、11月14日、12月04日、01月09日5个时间点的阶段练习数据作为样本集数据,使用 Microsoft Excel工作表导出记录并保存。
(3)预测模型的构建。
SPSS Clementine是SPSS公司收购取得的数据挖掘工具。SPSS Clementine12.0结合商业技术可以快速建立预測性模型,帮助用户改进决策过程。
启动Clementine并新建流文件后,选择界面下部“源”子菜单内的“Excel”,将其拖入面板中。双击面板中的“Excel”图标,在弹出编辑界面中选择“导入文件”,选择文件“样本集.xls”并导入,面板中图标名称变为“样本集.xls”。添加“类型”节点设置各字段“数据类型”和“方向”,“考核状况”对应“标志”类型,“学习次数”对应“集”类型,“提交题目次数”对应“范围”类型。设置样本集的数据类型如图2所示。
样本集数据信息的浏览如图3所示。
学生成绩一般分为优、良、中、及格和不及格,因此将数据集分成5类。图4中的$KMD-K-Means表示样本数据被划分到的类,$KMD-K-Means表示样本数据与所在类的质心之间的距离。
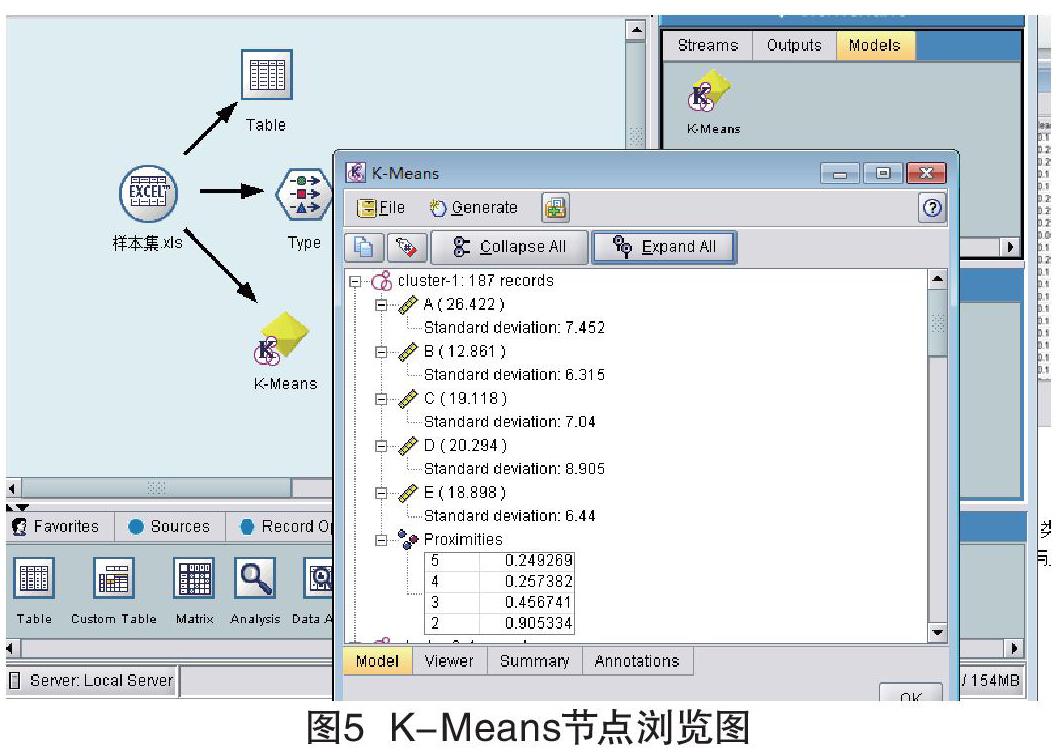
对管理工具模型下的K-Means节点进行浏览,并选择全部打开,可以显示每个类的一些统计信息,如图5所示。
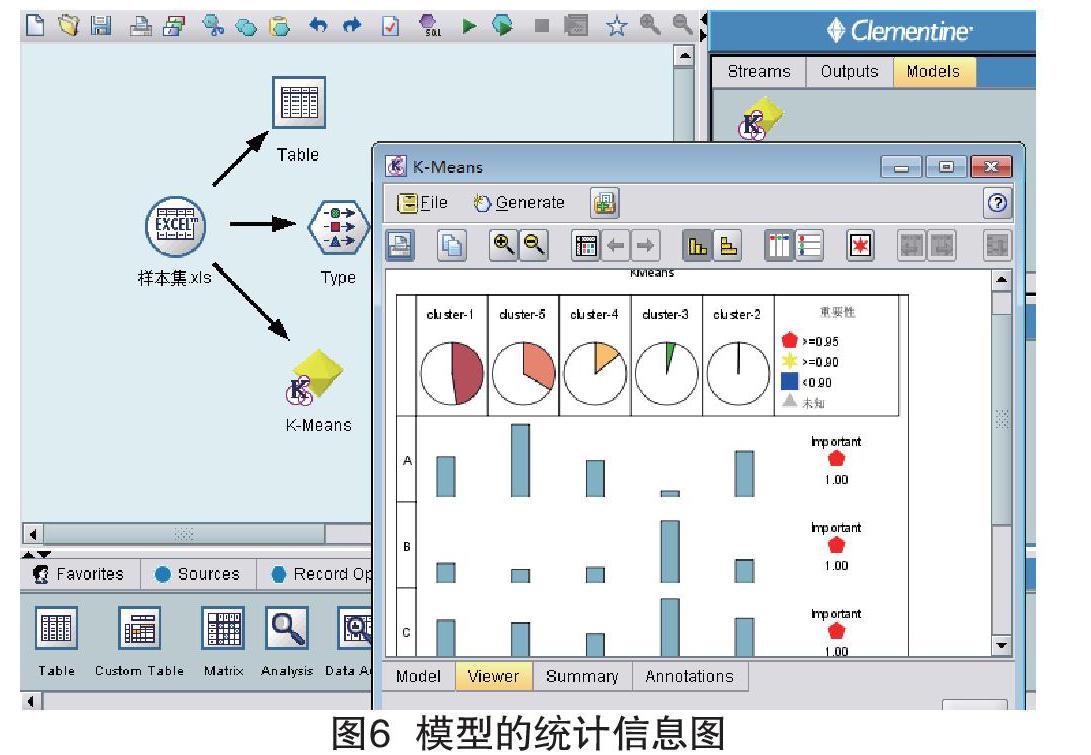
选择查看器标签,可以看到模型的统计信息以及各个属性在各个类中的分布情况,如图6所示。
通过数据的统计分析得出,尽管在学期初期同学们上机练习和提交题目次数较多,但是如果没有持续的练习与学习,预测出来的成绩也会不太理想。将分析数据对照学生们的期末成绩符合预测结论,学生要结合网络资源进行自学和自我练习才会达到预期的成绩。所以软件学科的学习是一个长期坚持和练习的过程。
3 结语
该课题以大学生学习C++程序设计为例,由搭建的Online Judge系统获取了大量信息。按照学生基本学习数据、学习过程和成绩数据从数据库中过滤掉无用信息并提取有效信息。通过用Clementine 12.0数据挖掘工具采用K-Means算法获取“学习行为—效果”预测模型。使生成的规则更加准确,模型具有良好的健壮性。经过评估达到一定准确率的规则,就可以应用在学生学习行为进行过程中,方法是将“学习行为”代入模型,预测出“效果”如预测效果(学期成绩)不理想,再回溯行为,比对规则,对行为做出改进,以获得更好的结果。
参考文献
[1] 岳伟.建构主义学习理论指导下的自学考试网络助学策略设计[J].考试研究,2015(1):9-15.
[2] 郝珺,蔡海飞.大学生网络学习行为实证研究[J].高教探索,2018(2):41-44.
[3] 傅钢善,王改花.基于数据挖掘的网络学习行为与学习效果研究[J].电化教育研究,2014(35):53-57.
[4] 金晓民,张丽萍.基于最小生成树的多层次k-Means聚类算法及其在数据挖掘中的应用[J].吉林大学学报:理学版,2018,56(5):1187-1192.
猜你喜欢
亚太教育(2016年36期)2017-01-17
成长·读写月刊(2016年12期)2017-01-12
中学课程辅导·教学研究(2016年14期)2016-12-23
软件导刊(2016年11期)2016-12-22
课程教育研究·学法教法研究(2016年24期)2016-11-30
中国市场(2016年41期)2016-11-28
文艺生活·中旬刊(2016年9期)2016-11-07
中国教育信息化·基础教育(2016年7期)2016-11-03
中国市场(2016年36期)2016-10-19
考试周刊(2016年77期)2016-10-09
