
虚拟机参数配置故障
2019-07-10 01:00新疆马小川
网络安全和信息化 2019年7期
■ 新疆 马小川
编者按:本文通过对虚拟机语言环境参数配置不当造成的软件系统故障问题的解决和分析,介绍了分析了出现问题的原因,字符编码的知识,以及语言环境配置文件i18n的相关知识。
VMware Workstation是一款功能强大的桌面虚拟计算机软件,可以提供用户在单一的桌面上同时运行不同的操作系统。笔者一直需要使用该软件虚拟Linux操作系统服务器进行一些软件测试工作。但最近发现,之前一直使用的Linux虚拟机出现了问题。
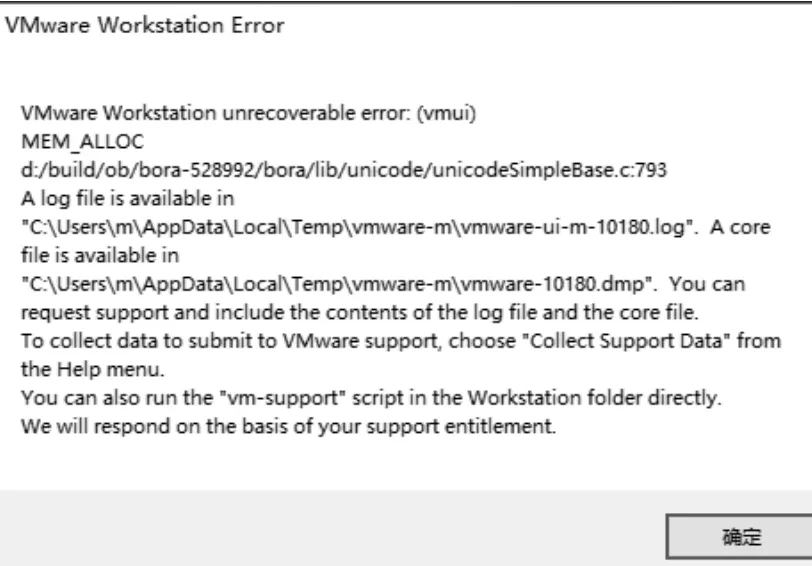
图1 报错对话框
故障现象
虚拟机系统启动过程都是正常的,但在登录输入密码 后,VMware Workstation软件会弹出报错对话框,错 误 内 容 为“VMware Workstation不可恢复错误(vmui):MEM_ALLOC”, 以及错误日志存放在何处等信息,如图1所示。将对话框进行确定后,VMware Workstation软件界面消失,无法进行操作。
笔者使用的计算机操作系统为Windows 10,虚拟机软件是VMware Workstation 8.0,linux虚拟机系统为Centos 6.0。在重装VMware Workstation软件后,该问题依然存在。但发现通过SecureCRT等连接工具却可以访问Linux虚拟机,说明该Linux虚拟机程序还在计算机后台运行。
分析原因
VMware Workstation软件提示的报错信息是MEM_ALLOC,是 内 存分配方面的报错。难道是Linux虚拟机分配的内存不足造成的吗?尝试将虚拟机内存从1GB重新分配为2GB,该问题依然存在。因此并不是内存不足造成的问题。
该报错信息是在Linux虚拟机系统正常登录以后立刻出现的。而通过SecureCRT等连接工具能够访问Linux虚拟机,因此可以猜测在Linux虚拟机使用命令行界面模式时应该不会出现报错。于是在SecureCRT中使用“init 3”命令,并重启虚拟机后,发现Linux虚拟机在命令行界面模式下能够正常登录和运 行,VMware Workstation软件无报错信息出现。于是可以基本排除Linux虚拟机系统本身存在问题。出现的错误应该是与Linux虚拟机在图形界面模式下的登录有关。
问题的解决
仔细检查Linux虚拟机在图形界面下的登录界面,发现在登录界面下方的语言栏是“汉语(中国)[gb18030]”。 通 过 语言栏的下拉菜单,将语言改 为“English (United States)”,登录后发现虚拟机在图形界面下运行正常,没有任何报错信息。虚拟机恢复正常,该问题被解决。
由此可以发现VMware Workstation软件出现的报错问题,竟然和虚拟机的语言环境设置有关系。
原来笔者使用的Linux虚拟机的系统是一直英文的。之前由于要测试中文页面,于是在/etc/sysconfig/i18n中修改了语言配置,将其中的LANG参数设置为汉字字符集“zh_CN.GB18030”,在修改配置后,笔者就没有使用过该虚拟机。而最近再次使用,就出现了报错信息。
因此可以确定造成报错的原因,是笔者在Linux虚拟机系统中将i18n文件的LANG参数设置为汉字字符 集”zh_CN.GB18030”后,系统的中文配置和VMware Workstation软件出现了冲突,造成了出现报错信息,以及软件图形界面消失。
使 用“zh_CN.GB18030”字符集会出现冲突,那么其他汉字字符集也会产生冲突吗?笔者又测试了“zh_CN.GB2312”等汉字字符集,虚拟机也出现了相同的问题。但配置为“zh_CN.UTF-8”字符集,虚拟机却能运行正常,系统的中文语言显示也都正常。
那么为什么使用汉字字符 集“zh_CN.UTF-8”虚 拟机软件和系统就能正常的运行,而同为汉字字符集的“zh_CN.GB18030” 和“zh_CN.GB2312”就会出现报错信 息。“zh_CN.GB18030”、“zh_CN.GB2312” 与“zh_CN.UTF-8”究竟有什么不同呢?
想了解它们的区别,要从字符编码的历史说起。
字符编码
计算机的底层语言是直接存储和处理二进制数字的。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。ASCII码是最基础的标准单字节字符编码方案,由于标准的ASCII编码能够包含的字符数目有限,为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准。GB2312编码是ANSI编码的一种,由于GB2312不能处理汉字繁体字等,于是就产生了GBK编码,GBK编码扩充了GB2312编码。
世界各国不同ANSI编码之间互不兼容,当信息在国际间交流时,文本会出现乱码。为了解决跨语言、跨平台进行文本转换、处理的要求,国际组织制定了Unicode编码。Unicode的编码效率不高,为了提高Unicode编码效率,于是出现了UTF-8、UTF-16等编码方式。其中UTF-8在互联网上使用最为广泛,UTF-8编码的文字可以在各国各种支持UTF-8字符集的浏览器上显示。
UTF-8具备了更好的通用性。这也就是为什么在i18n文件中,使用zh_CN.UTF-8字符集,虚拟机不会报错。而使用其他汉
字字符集会报错的原因。
关于i18n文件
笔者遇到的问题,是由于在Linux系统/etc/sysconfig/i18n中修改了相关配置而出现的。那么这个文件是起什么作用的呢?
“i18n”是国际化组织Openi18n提出的一套国际化解决方案,通过简单的配置就能适应不同语言和地区的需求。本例中,笔者只是将/etc/sysconfig/i18n文件的LANG参数进行了修改,就使得Liunx的语言环境发生了改变,系统的语言环境从英文改变为中文。在Centos 6.0系统中,默认的i18n文件非常简单,只有LANG参数和SYSFONT两个配置参数。其中LANG参数选择字符集配置系统的语言环境,SYSFONT参数配置系统字体。
例如i18n文件配置如下:
LANG=”zh_CN.UTF-8”
SYSFONT=”latarcyrhebsun16”
那么这个配置,就是要求系统的语言环境为zh_CN(简体中文)、UTF-8编码、latarcyrheb-sun16字体。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
疯狂英语·新读写(2018年3期)2018-11-29
小学阅读指南·低年级版(2017年4期)2017-04-24
小学阅读指南·低年级版(2017年1期)2017-03-13
