
基于因子分析的计算机打印文件鉴定∗
2019-07-10 08:18赵克坚廖海斌
计算机与数字工程 2019年6期
赵克坚 廖海斌
(1.咸宁市中心医院(湖北科技学院附属第一医院)计算机中心 咸宁 437100)
(2.湖北科技学院计算机科学与技术学院 咸宁 437100)
1 引言
随着现代科技的发展,人们的生活越来越数字化,打印机逐渐普及,与之相伴随的打印文件相关的民事纠纷、刑事案件等也越来越多。如伪造合同、证件,传播恐吓、煽动性文书等。打印文件是重要的物证或线索,鉴定问题文档是否被篡改或者辨别此打印问题文档的打印机源能给案件侦破提供有价值的援助。此外,验证印刷证件、打印票据等的真伪也极为重要。
针对一些特定的打印文档,目前的鉴别技术已经可以利用水印[1~2]、安全纤维、全息图[3]或者特殊的墨水[4]等特征来识别真伪,但是这类安全技术往往花费较大,需要特殊的设备来植入安全特征,对普通用户来说成本太昂贵。因此,利用计算机图像处理和人工智能方法来自动鉴定打印文档具有重要的理论意义和应用价值。
计算机打印文件鉴定技术研究开始于21 世纪,目前研究者相对较少。J. Oliver 和J. Chen[5]利用计算机统计打印字符的面积特征,通过相同字符是否存在不同面积来判断文件中是否有非法伪造的内容。该方法简单,计算速度较快,但是判断的依据并不严密,效果并不理想。美国Purdue 大学2002 年成立了传感器与打印机鉴定实验室(PSAPF),其成果主要有:研究了激光打印机的齿轮传动装置的齿咬合误差与大齿轮的离心率误差对打印图像造成的明暗间隔的条纹特征;通过提取字符“e”的灰度共生矩阵等来提取纹理特征,并分别利用5 近邻分类器与SVM 方法进行分类[6~10]。Tsai 等提出利用离散小波变换和特征选择方法来识别彩色激光打印机[11]。Akao 等通过最大熵方法估计正齿轮数目来识别喷墨打印机[12]。王宁、韩国强[13]等利用扫描采集的打印字符的笔画总面积和笔画轮廓总周长等特征值建立单字信息库来识别文档的来源机型。邓伟、涂岩恺、陈庆虎等[14~17]设计并开发了图像整体显微放大系统来采集打印文档的整体细节图像信息,并采用图形匹配算法、双极性Hausdorff 距离、小尺度小波域特征的半影条纹特征提取方法等多种方法进行打印文档的源机识别。总的说来利用计算机进行打印文件鉴定取得了一定的成果,但识别率仍需进一步提高。
国外学者利用计算机进行打印文件鉴定的研究时,训练文件与识别文件常取相同的字符内容,如出现频率高的字母”e”或单词”the”。国内学者也往往是取相同字符内容的样本进行匹配分类。而对中文打印文件来说,很可能识别文件与训练文件中的内容存在很少相同字符甚至不存在相同字符,这样显著增加了识别的难度。这是因为相同字符的非同机距离明显小于不同字符的同机距离。为了更好地研究训练与识别文件字符内容不一致时的打印机文档鉴定问题,本文将影响打印字符形态特征的因素从来源上划分为两类,由打印机的不同如打印机部件的参数不一致、器件不同等引入的差异称为打印机因素或打印机因子,是一种风格因子;由字符本身的文本内容的不同引入的差异称为文本因素或文本因子,是一种内容因子。对打印文件鉴定来说,打印机因子是有效因子,而文本因子是干扰因子。本文提出将因子分析模型的方法用于打印字符的二次特征提取,通过双线性方法进行因子分解,提取特征矩阵的打印机因子,降低文本因素对识别的干扰,从而提高了对打印文档源机的识别率。
2 基于因子分析模型的特征分解
把内容和风格看作影响一个事物的两个互相独立的因素[18],它们决定了事物的观测。比如:语音信号中,表示语音文本即语义信息的是内容因子,表示说话人的音色、说话语气和声调等信息的是风格因子;手写笔迹中,表示这个样本是哪个字符的信息是内容因子,表示这个样本是哪个人写的是风格因子[19];多字体印刷字符中,表示字符文本信息的是内容因子,表示字符字体信息的是风格因子;在人脸图像中,正规人脸(正面,中性,光照归一化)是内容因子,而人脸的姿态、光照、表情等变化是风格因子[20]。同样的,在打印文档中,由打印机的不同引入的差异是风格因子,也可称作打印机因子;由字符文本内容的不同引入的差异是内容因子,也可称作文本因子。打印文档鉴定的目的就是根据打印机风格信息识别出此文档出自何台打印机,如果能将影响打印字符特征的文本内容信息分离出来,提取出内容无关的特征,将有利于打印文档鉴定。基于此思想,本文提出基于因子分析模型的打印字符二次特征提取方法,通过双线性方法分离出打印机因子和文本因子,从而提取近似文本独立的打印字符特征。
2.1 基于双线性的因子分析模型
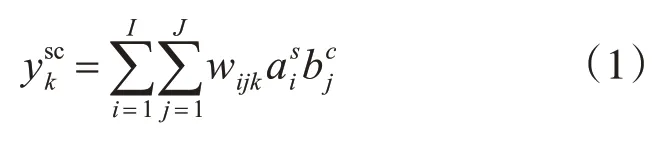
如果打印字符内容bj∈ℝJ具有风格ai∈ℝI,那么打印字符的观测y ∈ℝK可以用双线性表示:其中,k ∈[1,K]表示打印字符观察向量中第k 维特征,符号s 和c 分别标记风格和内容,wijk表示内容与风格的交互作用关系。为了使因子分析模型更具灵活性,假定交互作用项wijk随着内容变化而变化,设,则式(1)变为

设Bc表示K*I 维的矩阵,元素分别为,则式(2)可写为更简洁的因子分析模型形式:

例如,将双线性模型应用到不同字体的印刷字符集中。则字体的信息为风格因子,字符本身是内容因子,结果如图1 所示。每一个字符都可以由基本内容因子矩阵和字体因子系数的来表示,如果要重建一个特定字体下特定内容的字符,只需要将基本矩阵进行字体系数加权线性组合即可。
2.2 因子分析模型匹配求解
因子分析模型的匹配求解目标是在训练阶段使所有样本的总平方误差最小化。设第t 次训练观测值为y(t),其中t=1,2,…,T 。 设指示变量为hsc(t),其中

因此,因子分析模型的全部训练集的总平方误差E为

如果训练样本中,对各种风格s和内容c的观测数量相等,那么利用奇异值分解(SVD)就可以得到因子分析模型的最优拟合结果。

图1 三种字体的双线性模型分解图
在打印机鉴定中,设打印机为s,文本为c的观测均值为

明显的,这些观测矩阵是3 维的,为了利用标准的矩阵算法,把SC个K维行向量转为S*(KC)维的二维矩阵,表示如下:其中为K维观测均值向量。则式(3)可表示为更为简洁的矩阵形式:其中,为S*I维矩阵,表示打印机因子的参数矩阵;为I*(KC)维矩阵,表示文本因子的参数矩阵。
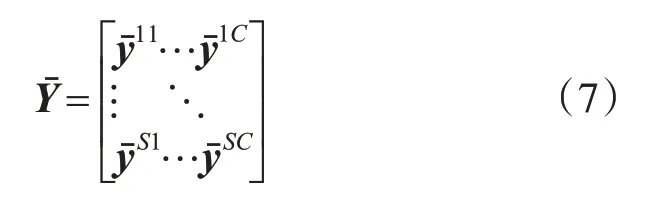

为了得到打印机因子和文本因子参数的最小方差估计,利用SVD计算Yˉ=USVT,S的对角线元素按特征值的大小取降序排列。则A可取U矩阵的前I列,B可取SVT矩阵的前I行。模型的维数I的大小可以根据先验知识或者实验效果来定。
2.3 基于EM算法的打印机分类
假设测试数据来自训练数据中S台打印机的某一台,但是字符内容与训练数据不一样。设打印机因子为as,新的文本因子为Bc˜。假设打印机s的新文本c˜的观测数据y服从高斯分布,其均值为双线性预测值,方差为σ2,则
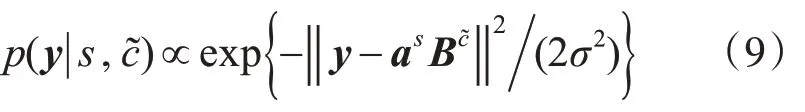
y的整体概率密度分布则为

根据先验知识,p(s,c˜)为均匀分布。下面采用EM 算法循环迭代来得到新的文本因子Bc˜和描述测试数据的最佳标签
E-步:对打印机为s,文本为c˜的观测数据y计算概率密度函数:
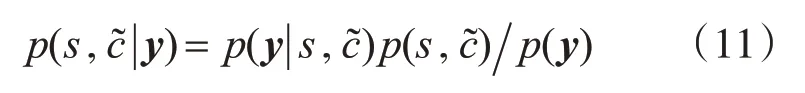
M-步:估计新的文本因子Bc˜,使得对数似然概率最大。令

新的Bc˜则可以由解出:
EM迭代具体算法如下:
1)初始化文本因子Bc˜;
2)计算出式(11)E-步中观测值y的后验概率

3)根据式(13)更新文本因子Bc˜的值;
4)重复步骤2)3),直至两次计算得出p(s,c˜|y)的差值小于阈值或迭代次数超出规定的最大次数。EM 算法收敛于L的局部最大值,测试数据就可以根据使得后验概率最大的类别s来分类。对于EM 算法来说,初始化是非常重要的。由于本文主要关注的是识别性能,所以初始化采用最近邻方法,即对于每个测试数据向量,文本因子取与之最相近字符的文本因子。
3 实验结果与讨论
为了测试上述基于因子分析模型的打印文件鉴定的有效性,建立了包括40 台激光打印机的打印文件数据库。这些打印机包括一些常用品牌及多种型号,见表1。对40 台打印机分别采样,每台打印机打印两张文件,一张用作训练,一张用作测试。每张文件的打印内容是1100 个一级常用汉字,采用宋体、小四号打印。利用图像整体高倍放大系统采集每张训练文件的504 个字符和每张测试文件的另外504 个完全不同内容的字符,经过预处理,切割,字符内容自动识别,这样就构成了40份样本、每份样本504个字的训练库和40份字符内容与训练库完全不同的测试库。

表1 实验中打印机编号和型号
首先取一台打印机的两张文件,记为A1,A2,取另外一台打印机的一张文件,记为B2。对3张文件中每个字符提取反映字符形状的8 维矩特征,并求出A1与A2之间的距离,记为D1,求出A1与B2之间的距离,记为D2。则D1 表示同一台打印机不同字符内容的距离,如图2 中星形点所示;D2 表示不同打印机同样字符内容的距离,如图2 中菱形点所示。可以看出,同一台打印机不同字符之间的距离远大于不同打印机同样字符之间的距离。即文本因子对字符特征的影响非常显著,远大于打印机因子。因此,打印机因素在字符形态特征中是一种弱信号,容易受到文本因素强信号与误差因素的干扰,这也影响了打印文件鉴别的准确率。
采用本文提出的方法进行打印机因子和文本因子的分离后,对A1,A2 和B2 的打印机因子按上述方法分别求距离,如图3 所示。可以看出,同一台打印机不同字符之间的距离已经小于不同打印机同样字符之间的距离。即文本因子对字符特征的影响显著降低,打印机因子的影响更加显著。

图2 不同字符的同机距离和相同字符的非同机距离比较
下面进行识别实验。采用矩特征(MF)、方向指数直方图(DIH)和Wigner 特征(WF)这三种方法进行特征提取,对提取出来的特征矩阵分别用本文方法和欧式距离方法进行一对一的鉴别实验,其中本文方法是将EM 算法后所得的后验概率与阈值比较,欧式距离方法是将特征距离与阈值比较,若大于阈值则判断为同机打印,统计正确鉴别数,实验结果如表2 所示。另外实验结果也与文献[18]所用方法(记为方法1)比较,其中方法1 的训练库和测试库中每两份文档之间平均有50 个左右的相同字符,而本文实验的训练库和测试库完全无相同字符。3种方法列出的均为最优阈值的实验数据。
可以看出,特征矩阵经过因子分析模型分离打印机因子和文本因子以后,文本因素的影响显著降低,获得近似文本独立的特征,在检材与样本之间没有任何相同字的情况下识别率显著提高。但是相比有50 个相同字情况下的识别率仍然有一定差距,说明文本因子的挖掘并不彻底,分离以后的特征仍然残留有部分的文本因子的影响,这可能是特征矩阵与双线性模型之间不完全契合所导致的。下一步工作中,考虑将特征矩阵先进行变换处理,使之更符合双线性模型,然后再进行变换。另外,会考虑采用新的模型进行因子估计与因子分离,比如非线性模型。
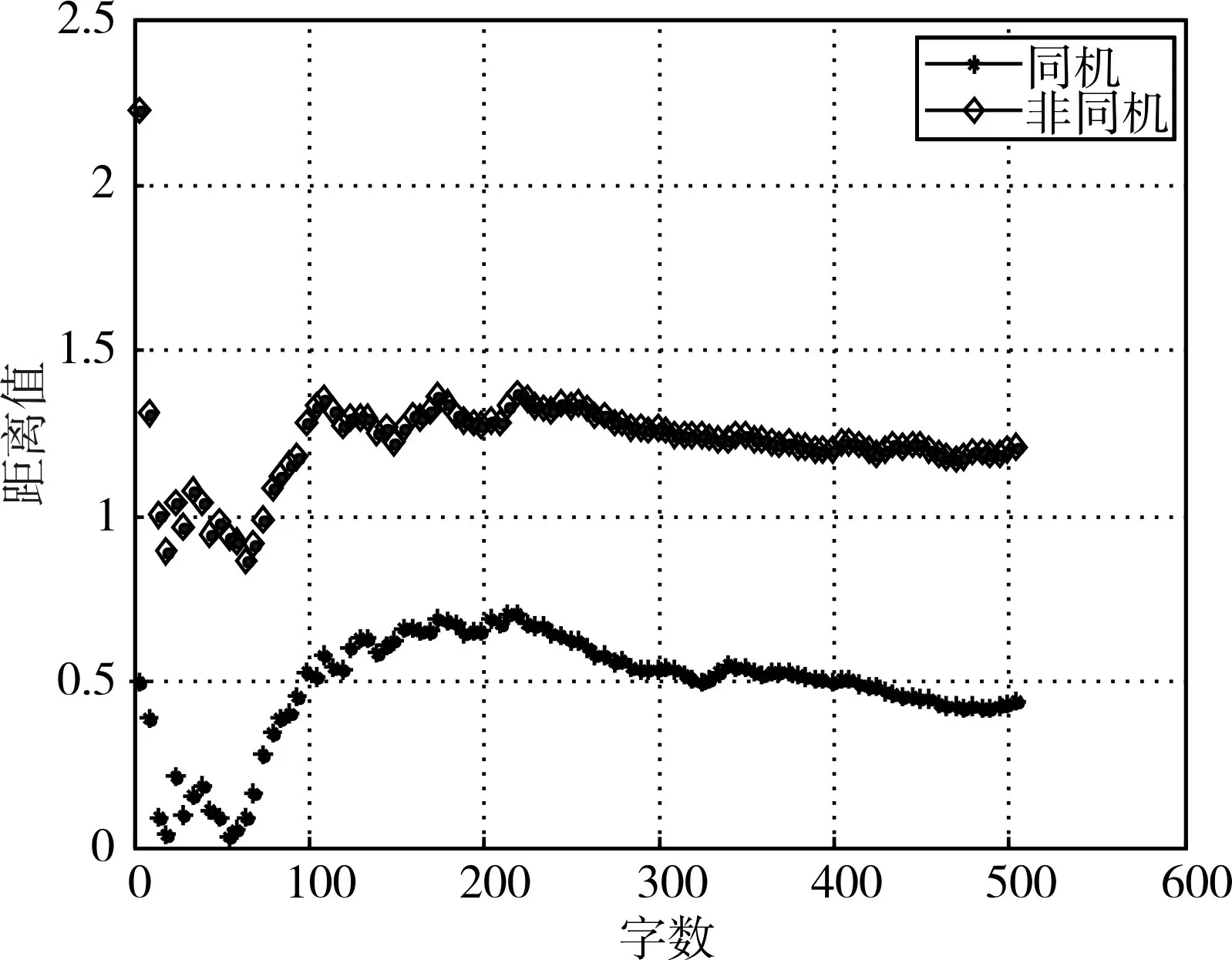
图3 因子分离后不同字符的同机距离和相同字符的非同机距离比较
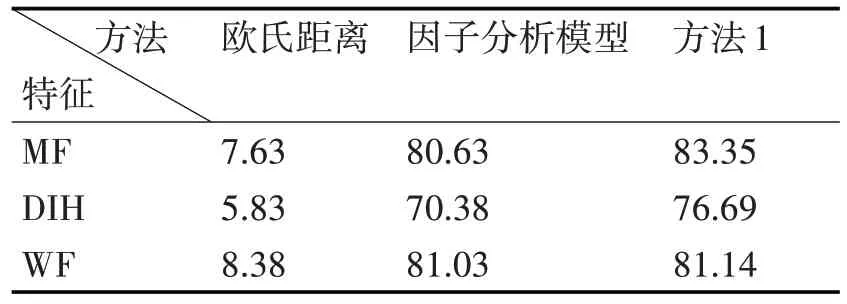
表2 欧氏距离方法、本文方法与方法1的识别结果
4 结语
计算机打印机文档鉴定是一个新的研究课题,在样本和检材文件中没有相同字或相同字符极少的情况下,打印文档鉴定相当困难。本文针对这个问题,提出了一种基于因子分析模型的打印机因子与文本因子分解方法,对特征矩阵采用双线性模型进行因子分离,提取近似文本无关的特征,然后采用EM 算法迭代求得最大后验概率进行分类,使得样本与检材文件中没有相同字时的打印机鉴定正确率有了显著的提高。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
老年博览·上半月(2021年3期)2021-03-30
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电脑爱好者(2017年7期)2017-05-06
发明与创新(2016年34期)2016-08-22
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
