
融合可变形卷积与条件随机场的遥感影像语义分割方法
2019-07-12 07:12左宗成张东映
测绘学报 2019年6期
左宗成,张 文,张东映
1. 武汉大学遥感信息工程学院,湖北 武汉 430079; 2. 欧特克(中国)软件研发有限公司,上海 200122; 3. 郑州大学水利与环境学院,河南 郑州 450002
高分辨率遥感影像已经在制图、城市规划、灾害监测、房地产管理、计量经济学、作物分类和气候研究等多领域得到应用[1]。遥感影像语义分割作为高分辨率遥感影像信息提取与目标识别的前提和基础,是实现从数据到信息的对象化提取的过渡环节和关键步骤,具有十分重要的意义[2]。图像语义分割不同于图像分类或物体检测等任务,图像语义分割是一个空间密集型的预测任务,换言之,这需要预测一幅图像中所有像素点的类别[3]。语义分割旨在分类每一个像素到指定的类别,是一种对于理解和推理对象以及场景中物体之间关系的重要任务。作为通向高级任务的桥梁,在计算机视觉和遥感领域中,语义分割被用在了多种应用中,例如自动驾驶、姿态估计、遥感影像解译及3D重建等[4]。传统的特征提取难以应付空间变换的要求,并且手工特征设计难度大。自从FCNs[3]首次被用于图像的语义分割之后,新的方法不断被创造。近年来,由于深度卷积神经网络的广泛使用使得密集型预测的语义分割取得了长足的发展。最近的工作都表明,在许多图像处理任务中,深度学习模型往往显著优于传统的方法[5]。
标准的卷积操作通常是在特征图谱固定的位置上进行采样,对于复杂目标对象的检测来说不是很合理,这是因为不同位置对应的目标大小是不同的。如果能够使得感受野[6]在不同位置的大小进行自适应调整,那么对于语义分割任务必然有很大的帮助。
其次,对于深度卷积神经网络来说,从分类器获取以对象为中心的决策需要空间不变性,其内在特性限制了深度卷积神经网络(DCNNs)的空间精度模型,并且DCNNs的最后一层通常没有充分地对局部对象进行分割,所以本文通过采用全连接的条件随机场来提升本文方法捕获细节的能力[7]。条件随机场(CRF)已广泛应用于语义分割,以便将由多方向分类器计算的类别得分与由像素和边缘的局部交互所捕获的低级信息进行综合[8]。因此本文提出一种融合可变形卷积与条件随机场的方法来解决标准卷积操作对空间自适应能力的欠缺以及采用条件随机场的方法来提高局部分割精度。
1 方 法
本文方法主要分为3个步骤:①对常规的标准卷积添加了一项二维偏移量到采样网格中,得到一种可变形卷积网络[9],该项偏移量的添加使得卷积网络可以自由形成变形,这些偏移量是通过卷积层抽取的特征图谱进行学习而来;②训练的网络采用VGGNet网络的参数进行初始化,反卷积网络作为分割结果层进行预测每个像素的分类结果;③对输出的粗糙预测分割结果进行CRF操作,得到精细化的分割图。
1.1 可变形卷积网络
1.1.1 可变形卷积
传统的二维图像上的卷积操作包含两个步骤:①在输入特征图谱x上采用常规网格R进行采样;②由w加权的采样值的求和。网格R定义了感受野的大小和步幅。例如:R={(-1,-1),(-1,0),(-1,1),(0,1),(0,0),(0,-1),(1,1),(1,0),(1,-1)}定义了一个步幅为1的3×3卷积核。对于输出特征图谱y上的每个位置p0可得到
(1)
可变形卷积使用偏移{Δpn|n=1,…,N}扩充了常规网格R,这里的N=|R|。上述方程变为
(2)
现在,采样在不规则和偏移位置pn+Δpn之上。由于偏移Δpn通常是小数形式的,式(2)通过双线性插值变换之后变为
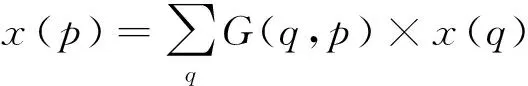
(3)
式中,p代表一个任意位置(p=p0+pn+Δpn);q枚举特征图谱x中的所有的积分空间位置;G(.,.)代表双线性插值核。这里的G是二维的,它可以被分为两个一维的内核
G(q,p)=g(qx,px)g(qy,py)
(4)
式中,g(a,b)=max(0,1-|a-b|)。式(4)是快速计算,因为G(q,p)仅对于部分q的取值是非零的。
如式(2)所示,可变形卷积是通过在相同的输入特征图谱上应用卷积层来获得偏移。可变形卷积核与当前卷积层也是具有相同的空间分辨率。输出偏移量与输入特征图谱具有相同的空间分辨率。当通道维数为2N时,需要编码N个二维偏移向量。在神经网络训练期间,可以学习用于产生输出特征和产生偏移量的卷积内核。在可变形卷积模块上执行的梯度可以通过式(3)和式(4)中的双线性运算来反向传播。
文献[10]发现,感受野中并不是所有的像素都有助于输出单元响应。由于靠近中心的像素具有更大的影响,所以有效感受野只占理论感受野中的小部分,并服从高斯分布。虽然理论感受野尺寸随着卷积层的数量线性增加,但让人感到意外的是,有效感受野尺寸是随着卷积层数量的平方根线性增加,因此以比预期慢得多的速率进行收敛[10]。这一发现表明,即便是CNNs中的顶层单元也可能没有足够大的感受野。这部分也解释了为什么空洞卷积[11]被广泛应用于视觉任务。它揭示了可自适应性感受野学习的必要性。可变形卷积能够自适应地学习感受野,如图1所示。
在标准卷积中的空间采样位置增加了额外的偏移量就可以得到可变形卷积。这些偏移量是从目标任务驱动的数据中学习的。当可变形模块堆叠成多层时,复合变形的影响是巨大的。相较于标准卷积而言,对于复杂目标可变形卷积有着强大的自适应提取能力。如图1所示,标准卷积滤波器中的感受野和采样位置在上层特征图谱上是固定的(图1(a));当使用可变形卷积时,它们会根据物体的尺度和形状进行自适应调整(图1(b))。特别是对于非刚性物体增强了目标定位能力。
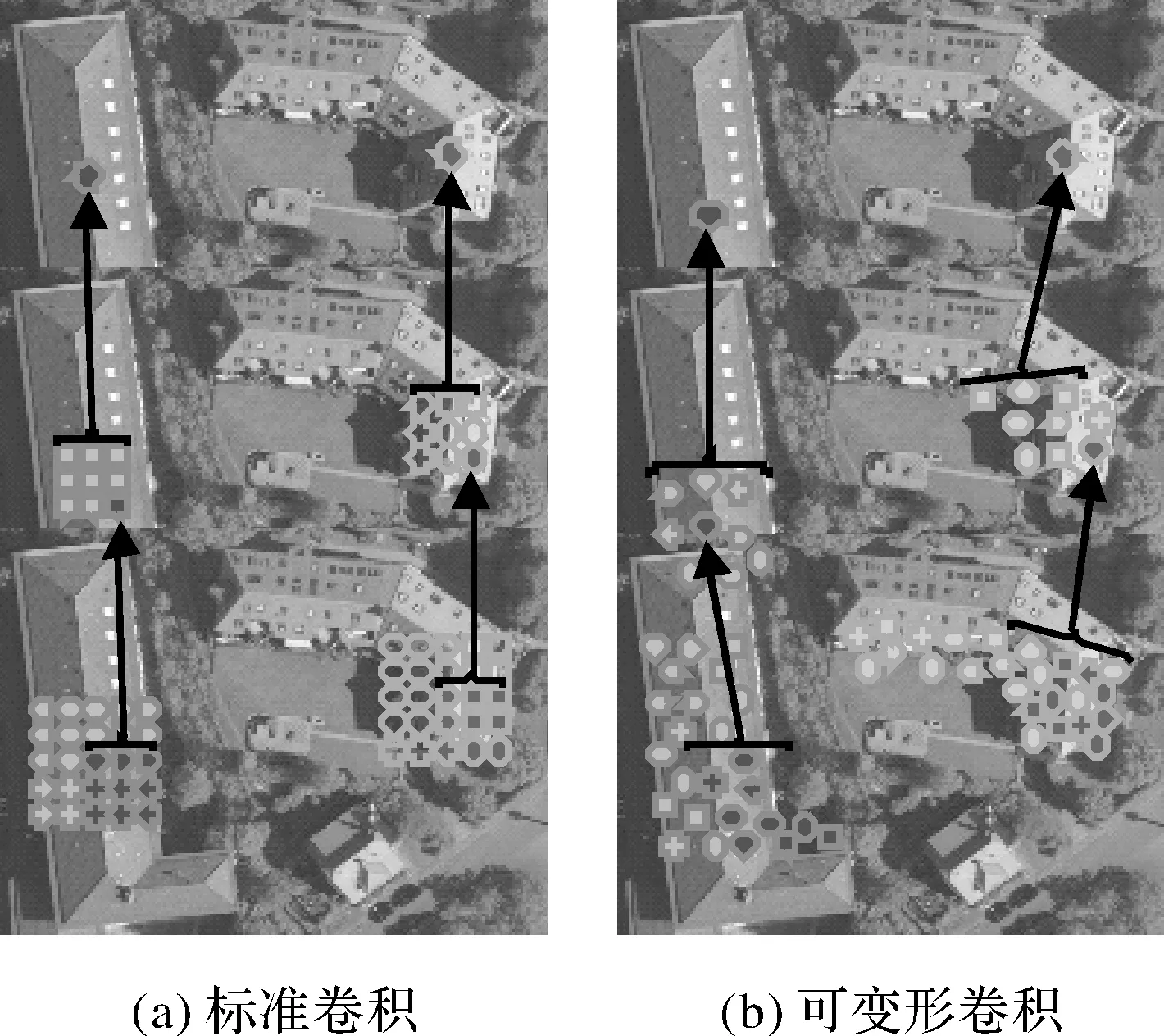
图1 标准卷积与可变形卷积Fig.1 Standard convolution and deformable convolution
1.1.2 可变形卷积的网络结构
可变形卷积与标准卷积有着相同的输入和输出。因此,在神经网络结构中可变形卷积可以很容易替换标准卷积操作。在训练期间,可以学习用于产生输出特征和产生偏移量的卷积内核。在可变形卷积模块上执行的梯度可以通过式(3)中的双线性运算来反向传播。他们通过反向传播训练,通过方程式中的双线性插值运算,所得到的CNNs称为可变形网络(deformable ConvNets)。可变形网络自动学习预测影像中物体对象的位置,它是基于增强空间采样位置的能力为考量并使用非监督方法从目标任务中学习偏移量。
为了将可变形ConvNets与现有的CNNs架构相结合,本文提出由3个阶段组成的流程来实现可变形卷积网络。首先,深度全卷积网络(DFCNs)在整个输入图像上生成特征图谱;其次,从特征图谱中生成分割结果;最后,对于粗糙的结果进行反卷积得到精细化的分割图。以下详细说明这3个步骤。
(1) 可变形卷积的特征提取。本文采用广泛使用且具有良好性能的特征提取架构VGGNet[12]作为特征提取层。网络的初始化参数在ImageNet[13]分类数据集上进行了预训练。这个VGGNet模型是由卷积层、平均池化层和一个用于ImageNet分类的1000路全连接层组成。本文删除了平均池化层和全连接层。像通常的做法[14]一样,本文将最后卷积块中的有效步幅从32像素减少到16像素,以增加特征映射分辨率。本文中可变形卷积层被施加在最后3层作为特征提取层。
(2) 语义分割网络。当前有许多可用的语义分割的网络架构。本文选择SegNet架构[15](图2),因为它提供了精度与计算成本之间的良好平衡。以此结构为基础,嵌入可变形卷积结构。SegNet的对称架构使得它对池化层及反卷积的使用非常有效,这对于遥感数据来说至关重要。除了SegNet,还对DeepLab[16]进行了初步试验,结果显示并没有显著改善甚至没有改善。因此,没有必要切换到更昂贵的计算架构。请注意,本文方法可以轻松地适应其他架构,而不是限定于SegNet的架构。SegNet具有VGG-16的卷积层的编码器与解码器架构[17-18]。编码器由一系列卷积层组成,每个卷积层后面紧跟着的是批量归一化[19]和整流线性单元。卷积块之后是池化层,本文采用步幅为2的最大池化层操作。没有试验其他的激活函数,如PReLU[20]或ELU[21],也没有进一步改变SegNet架构。这样做的目的是为了在后续试验中对比可变形卷积的性能。
(3) 反卷积网络。解码器的结构与编码器是对称的,解码器对于输入结果进行上采样,本文使用文献[24]中的策略随机初始化解码器中网络的权重。在一般的CNNs结构中,如AlexNet、VGGNet均使用了池化操作来缩小输出图片的尺寸,例如VGGNet,5次池化操作后输入图像的尺寸被缩小了32倍。本文目的是得到一个与原图像尺寸相同的分割图,因此需要对最后一层特征提取层进行上采样。卷积网络输出的特征图谱是缩小的尺寸,因为最终预测的分割图是基于像素的,所以需要对卷积网络的输出进行反卷积操作。反卷积就是卷积计算的逆过程,可以从卷积过程中来推导反卷积的过程
Wn+1=(Wn+2p-k)/s+1
(5)
Hn+1=(Hn+2p-k)/s+1
(6)
式中,W表示宽度;p表示填充像素大小;k表示卷积核尺寸;s表示卷积的步幅。可以很容易推导到反卷积的公式
Wn=s+k-2p(Wn+1-1)
(7)
Hn=s+k-2pHn+1
(8)
本文使用卷积特征图谱的后3层作为反卷积的输入特征。

(9)
式(9)即为训练网络的损失函数。
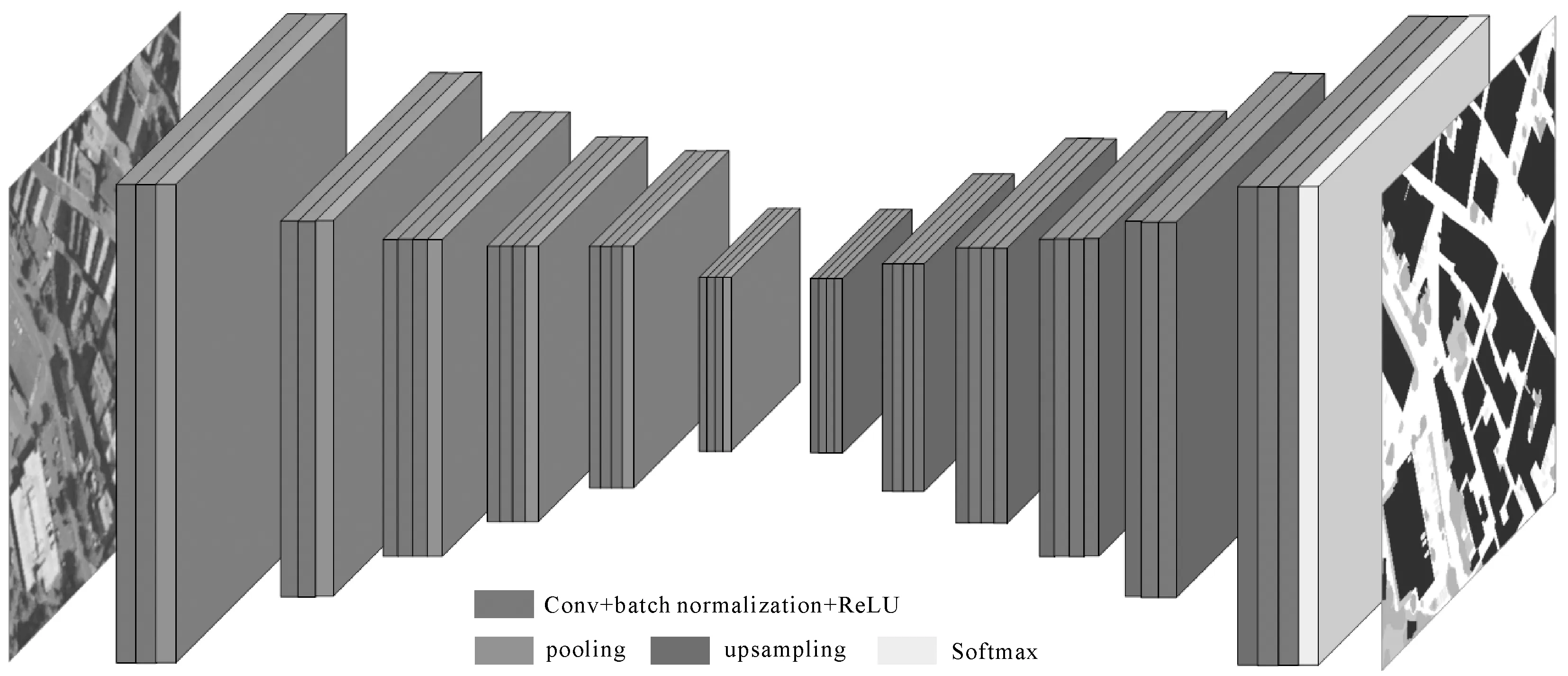
图2 带有编码器和解码器的SegNet架构Fig.2 SegNet architecture with an encoder and a decoder
1.2 全连接条件随机场后处理
DCNNs得分图可以可靠地预测图像中已知的对象和粗略位置,但不太适合用于指向其精确的轮廓。卷积网络的分类准确度和定位精度之间有一个合适的权衡:具有多个最大池化层的深层模型在分类任务中被证明是成功的,然而过多的池化层所带来的对空间不变性的提升与有效感受野增大的同时也使得从网络输出层根据得分推断位置变得更具挑战性。
解决这个问题目前有两种方法:第1种方法是利用卷积网络中多尺度的信息来更好地估计对象边界[3,22];第2种方法是采用超像素表示,基本上将定位任务委托给低级分割方法,这种解决思路由文献[23]提出。
条件随机场已被广泛应用于平滑噪声分割图[24-25]。通常,这些模型包含耦合相邻节点的能量项,有利于对空间邻近像素的类别分配[26]。本质上,这些短距离CRF的主要功能是清理基于局部手工设计的弱分类器的虚假预测。严格来说,这种模式适合于有效的近似概率推理[27]。本文通过融合DCNNs的识别能力和全连接的条件随机场(CRF)的细粒度定位精度来寻求新的替代方向,通过试验表明它在解决逐像素定位与分类方面取得了良好的结果,产生了准确的语义分割结果以及恢复对象边界的细节能力。
图3所示为模型的分割流程。通过可变形卷积采样POI区域,然后得到特征图谱,使用特征图谱来生成粗糙的缩小分割图,再通过反卷积插值得到同尺寸的预测分割图,最后将此粗糙的分割图使用CRF进行精细化分割,得到精细化的分割图。
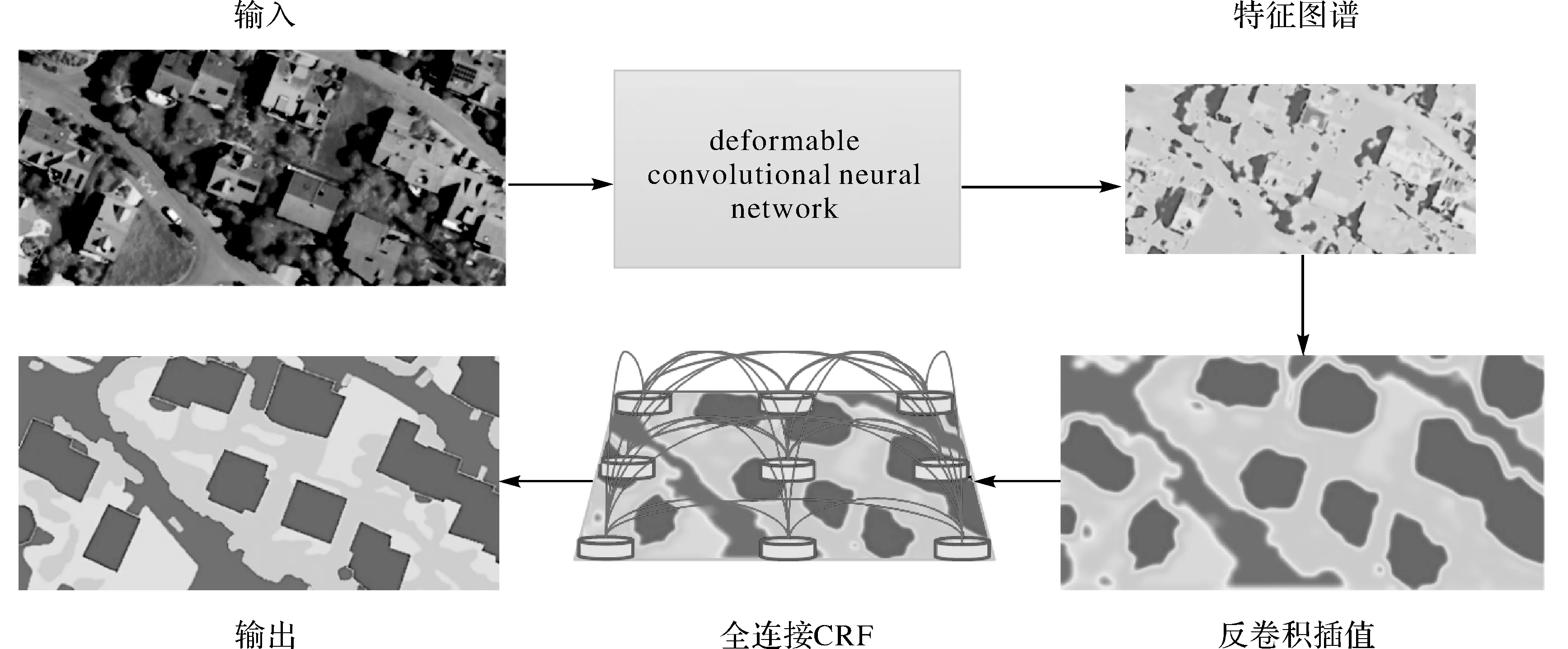
图3 语义分割流程Fig.3 The flowchart of the proposed approach
2 试验结果与分析
2.1 数据集
本文使用ISPRS Vaihingen 2D语义标签遥感数据集[28]来评估本文提出的方法。这是一个开放的基准数据集。数据集由33幅大小不同的图像组成,每幅图像为300万至1000万像素,图像是在德国Vaihingen地区拍摄的高分辨率正射影像,影像的平均尺寸约2493×2063像素,分辨率为9 cm。除了正射影像之外,数据集中还包含具有相同空间分辨率的数字表面模型(DSM)图像。此外,文献[29]提供了归一化的DSM,以限制不同地面高度的影响。33幅图像中的16幅图像已被正确标注,其中所有像素都被标记,总共分为6个类别,即道路、建筑物、植被、树木、车辆及杂类地物(例如集装箱、网球场、游泳池等)。如以前在其他方法中所做的那样,试验中不包括杂类,因为杂类的像素面积仅占总图像像素的0.88%。
ISPRS只提供16幅标注的图像进行训练,而其余17幅图像未标注用于评估提交的方法。为了评估本文方法,有标签分类的数据集被分为训练集和验证集。按照文献[30]的例子,训练集包含11幅图像(图幅区域为1、3、5、7、13、17、21、23、26、32、37);验证集包含5幅图像(图幅区域为11、15、28、30、34)。
2.2 数据预处理
高分辨率遥感图像通常尺寸较大,无法整幅图像通过卷积进行处理。例如,来自Vaihingen数据集的ISPRS瓦片的平均尺寸为2493×2063像素,而大多数卷积操作的分辨率为256×256。鉴于目前的GPU内存限制,本文使用滑动窗口将原始的遥感影像分割成较小的图像块。如果卷积步幅小于图像块尺寸,在连续图像块重叠的情况下,对多个预测进行平均,以获得重叠像素的最终分类。这可以平滑每个图像块边界的预测,并消除可能出现的不连续性。
本文的目标是将当前计算机视觉领域中的典型的人工神经网络结构应用到地球观测数据中,因此,使用最初为RGB数据设计的人工神经网络,处理后的图像必须遵守这种3通道格式。ISPRS数据集包含Vaihingen的IRRG图像,因此,3个通道(近红外、红色和绿色)将被处理为RGB图像。该数据集包含从空载激光传感器获取的数字表面模型(DSM)的数据。本文还将使用文献[30]中的归一化数字表面模型(NDSM),然后从近红外和红外通道计算归一化差异植被指数(NDVI),最终使用DSM,NDSM和NDVI信息为每个IRRG图像构建一个相对应的合成图像。
2.3 分割试验
本试验中深度学习网络的训练设备为4核心8线程Intel I7-7700K CPU;32 GB内存;NVIDIA GTX 1080显卡,8 G显存。软件环境为Ubuntu16.04.01操作系统;开发平台是Anaconda 4.3.1;内置的Python版本为3.6.1;深度学习软件框架是TensorFlow1.2。本次试验训练迭代次数为5e5,总训练时间为32 h 30 min。
本文使用随机梯度下降方法训练网络。学习率采用固定大小,本文使用的学习率为5e-3,学习率过大容易无法收敛,太小训练时间过长。批处理数量(batch)受到显存大小的限制,所以本文设置batch=10。本文网络特征提取层的权重使用了VGGNet[20]上进行预训练的权重,迁移预训练的权重可以增强网络在特征提取的性能。
本文使用ISPRS[28]定义的评估方法来评估结果,用F1分数来评估试验的结果
(10)

2.4 分析与评价
2.4.1 分割结果的比较
本文模型在ISPRSVaihingen数据集上获得了良好的分割结果,分割结果参见表1。表1比较了采用CNNs、FCNs及SegNet作为自编码器的网络。图4展示了采用本文方法与采用其他当前主流人工神经网络结构的分割结果,分割图中白色代表道路,蓝色代表建筑物,青色代表植被,绿色代表树木,黄色代表车辆。其中图4(c)为文献[31]中提出的传统CNNs方法的影像分割结果;图4(d)为文献[32]中提出的FCNs方法的影像分割结果;图4(e)为本文提出的方法的影像分割结果。
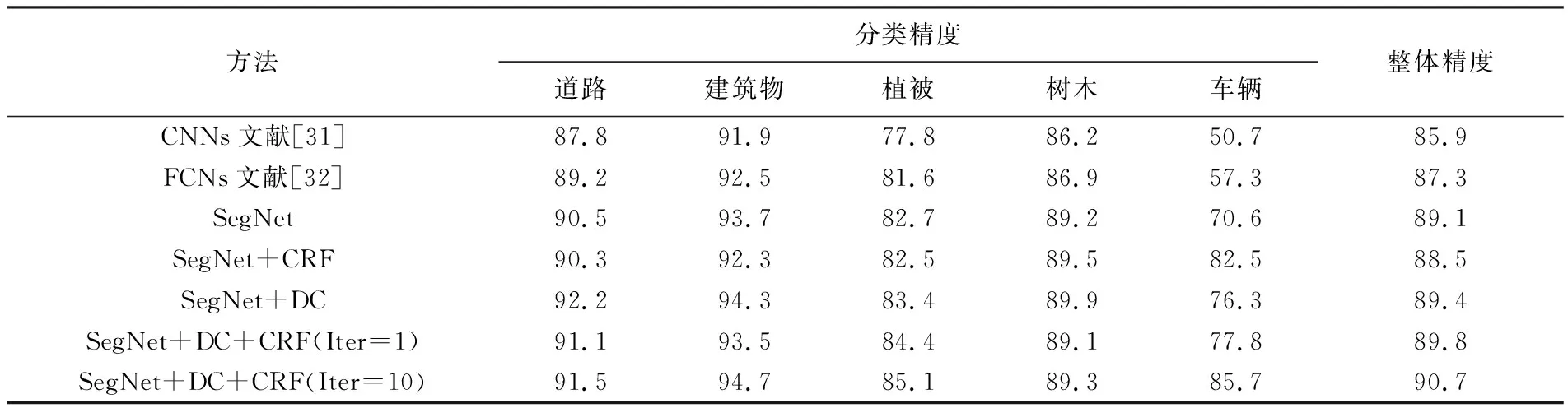
表1 ISPRS Vaihingen数据集语义分割结果
从试验结果中可以看出,CNNs算法难以很好地分割不同地物类别的边界,且整体分割精度较低,仅为85.9%。由图4(c)可以看出植被、建筑物与道路之间的分割边界很模糊并且不规整;其次是分割的地物中出现了很多类别错误,例如在植被区域出现了图斑状的树木类别,导致植被的分割精度只有77.8%。究其原因,文献[31]中已经提及这是由于CNNs网络对于空间变换没有很强的自适应能力。FCNs方法在边界分割能力上有一定的提升。从图4(d)可以看出,相较于CNNs方法,FCNs方法的分割边界更加清晰并且更加规整,但是依然存在较多的分割错误,例如房屋的边界不连续并且在车辆类别上的分割精度只有57.3%。从文献[32]中得知,FCNs某种程度上解决了CNNs的一些缺点。该方法的内在本质是利用现有的CNNs作为强大的视觉模型,使得网络能够学习特征的层次结构。尽管FCNs模型具有强大的性能和灵活性,但它仍然具有局限性,其内在的空间不变性并没有考虑有用的全局上下文信息,导致FCNs对细节不敏感。究其原因主要有两点:一是固定尺寸的感受野,对于大尺度目标而言,只能获得该目标的局部信息,导致目标的某些部分将被错误分类,对于小尺度目标而言,很容易被忽略或当成背景处理;二是目标的细节结构容易被丢失,导致边缘信息不充分,这是由于FCNs得到的特征图谱过于粗糙,这样用于上采样操作的信息过于简单。
本文提出的可变形卷积在空间变换上具有很强的自适应性。因为在不同区域对应的目标尺寸是不相同的,如果感受野在不同区域的尺寸能够进行自适应调整,这对于语义分割必然有很大帮助。从图4(e)中可以看出,分割的边界相较于CNNs与FCNs更加清晰规整,整体分割精度达到了90.7%。可以看到本文方法相比以CNNs和FCNs作为自编码器网络的方法在各个类别的分割精度上均有提升,尤其在车辆这个类别上提升最多达到了85.7%的分割精度,说明本文方法对于小目标物体的分割有着很高的适应性。

图4 试验结果Fig.4 The experimental results
2.4.2 可变形卷积的理解
可变形卷积的理念是建立在一个容易理解的想法之上的。可变形卷积是将空间采样位置增加额外的偏移量,这些偏移量是以目标任务为驱动的数据中学习到的。当可变形模块堆叠成多层时,复合变形的作用是显著的。对于同一区域的5幅图像,本文选取了不同尺度大小的地物(依次为车辆、建筑物、树木、植被和道路)作为激活单元,分别展示不同地物的采样位置,以此来可视化可变形卷积滤波器的工作原理。如图5所示,其中绿色点代表激活单元的位置,蓝色点代表对该地物的采样位置,每幅图像中展示了93=729个采样点的位置。
2.4.3 可变形卷积与CRF的性能比较
为了定量量化本文提出的两个模块对于分割精度的作用,将CRF模块与可变形卷积模块单独嵌入SegNet网络中进行试验,以此来定量对比模块的效果。CRF可以细化模型的分割输出并提高其捕捉细粒度细节的能力。CRF能够将低级图像信息(如像素间的交互)与产生逐个像素的类别得分的多类推理系统的输出进行组合。这种组合对于捕获卷积层未能考虑的远程依赖关系特别重要,并且可以保留良好的局部细节。从图6(b)中可以看到采用全连接的CRF显著改善了分割结果,使模型能够准确捕获复杂的对象边界,尤其是车辆这类小目标物体,可以看出相对于单独使用SegNet网络分割精度提升了11.9%。从局部分割图中也可以看出,分割的边界更加清晰,并且错误分类的孤立图斑更少。经过试验比较,一般对CRF的迭代次数取为10次,多于10次以上性能提升不明显,应用CRF操作之后整体精度可以提升1%~2%左右。从图6(c)可以看出对于道路、建筑物及树木这些不规则的地物,可变形卷积有着很好的提升效果,尤其在道路的分割精度上提升了1.7%。这也证明了可变形卷积在空间变换上有着很好的自适应能力。

图5 可变形滤波器的采样位置Fig.5 Sampling locations of deformable filters
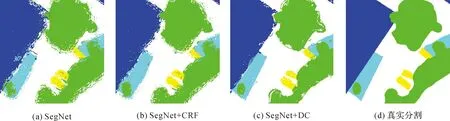
图6 可变形卷积与条件随机场的分割对比Fig.6 Comparing deformable convolution with conditional random field segmentation
3 结 论
本文研究了深度卷积神经网络在遥感影像语义分割中的应用。当前使用卷积网络来分割影像已经取得了很大的进展,但是由于传统的卷积方式无法有效地模拟几何变换,导致分割能力受到限制。相比之下,本文采用的可变形卷积方法对空间变换有着很强的自适应能力。准确捕获复杂地物的边界一直都是语义分割的难点,为此本文在神经网络的输出层加入了结构化的后处理步骤——条件随机场,并通过试验验证其有效性。本文也展示了如何为这种级联方法构建训练实例,并在ISPRS 2D Vaihingen数据集上验证了本文方法。由表1可以看出,本文方法获得了良好的分割结果。今后,残差校正是否能改善不同拓扑网络的分割性能是下一步研究目标。
猜你喜欢
地理空间信息(2022年3期)2022-04-01
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
自然资源遥感(2018年3期)2018-09-04
制造技术与机床(2017年7期)2018-01-19
湖南工业职业技术学院学报(2017年3期)2017-07-18
中成药(2017年3期)2017-05-17
中国社会历史评论(2016年2期)2016-06-27
领导科学论坛(2016年9期)2016-06-05
现代语文(2016年21期)2016-05-25
