
复杂社会网络节点重要性可拓聚类动态分析方法
2019-07-16 01:19严家萌庞超逸许立波
计算机应用与软件 2019年7期
严家萌 庞超逸 许立波*
1(浙江大学工程师学院 浙江 杭州 310015)2(浙江大学宁波理工学院计算机与数据工程学院 浙江 宁波 315100)
0 引 言
随着信息化网络化走向纵深领域,对复杂网络[1]的研究越来越显现其巨大的实用价值。在人类活动的参与下,网络表现为社会化,相比于其他类型网络,社会网络体现出更接近现实的复杂度,且往往要求对关键和核心节点的认定。比如,交通拥堵路口识别,疾病传播关键节点发现,国际环境中的大国影响力等,都离不开对影响力节点的刻画。发现复杂网络中的关键节点,有针对性的有效利用有着重要意义。在对复杂社会网络节点重要性度量时,应该考虑时间和空间两个维度,即此时此刻和某时某刻。而当前,对复杂网络的研究大都是建立在静态基础之上的,缺乏动态分析和考量。在复杂网络节点重要性背景下,无论是综合考虑节点连接度和经过该节点最短路径数的节点收缩法[2],还是借鉴排名算法的有向加权评估方法[3],亦或是评价网络中每个节点与“核心节点”的关联度的定量评估法[4],以及通过计算多重属性到理想的接近程度的综合评价指标[5]等,基本上都是静态分析方法。
在国外,复杂网络节点重要性中心性指标用来对节点的传播影响力进行刻画,主要有度中心性(Degree Centrality)[6]、介数中心性(Betweenness Centrality)[7]、紧密度指标(Closeness Centrality)[8]、K-Shell(KS指标)[9]等。文献[10]利用度中心性来度量节点的影响力,节点度描述了节点间的直接通信能力,直观反映节点的重要性,度表示为与节点直接相连的个数,在复杂社会网络中度数较大的节点的传播影响力相对较大。文献[11]利用介数中心性来衡量社会网络节点重要性,刻画了复杂网络中节点对于信息流动的影响力,以其经过某个节点的最短路径的数目来描述节点的重要性,网络节点介数定义为经过节点的路径数目占最短路径总数的比例。介数中心性认为,在复杂网络中如果一个节点是其他节点对之间联通的必经之路,则其在网络中具有重要地位,相应的影响力也就越大。文献[12-13]利用紧密度指标刻画某个节点到其他节点的难易程度,用其到网络中其他所有节点距离之和的倒数来刻画,节点的紧密度值越大,表明该节点越居于网络中心位置,相应地也就越重要。文献[14-15]提出通过K-shell(KS)分解来确定最具有影响力的单源节点,操作上相当于剥去了最外面一层壳。首先去除网络中度数小于k的所有节点及其连边,如果在剩下的节点中仍有度值小于k的节点,那么就继续去除这些节点,直至网络中剩下的节点的度值不小k,依此类推,直到复杂社会网络中所有的节点都被赋予KS值。
总体来看,目前大多数研究对复杂网络节点重要性度量时的方法均是静态的,能很好地阐释复杂网络节点内部相互连接的逻辑,区分重要性程度。然而,对变化了的节点重要度如何度量缺乏研究,更没有给出变化的量。本文意在尝试提出一种新的基于可拓聚类的节点重要性动态分析方法。
1 可拓聚类方法说明
1.1 变量说明
对文中所涉及主要变量作如下定义和说明。

Dc为度中心性Cc为紧密度中心性pij为标准化后的属性值λj为属性权重Ti为时点K(i)为综合关联度Bc为介数中心性qij节点原始属性值dr为第r个等级ui为节点属性k(pij)为关联度
1.2 引入可拓学
可拓学[16]是通过定性和定量相结合的手段去处理矛盾问题的新兴学科,其中可拓集理论是研究事物动态性和可变性的有力工具。杨国为等[17]利用可拓模式识别建立起神经网络模型,推出模式可拓识别分类器。Xu等[18]提出可拓关联结合后悔理论,应用于决策分析领域。周玉等[19]对可拓神经网络的基本思想、算法思路、应用研究进行了系统分析,并提出了有待进一步研究的方向和问题。而将可拓聚类分析方法应用于复杂网络节点重要性方面尚未见到。本文试图将可拓集理论引入复杂网络节点影响力研究领域,提出一种基于可拓聚类的复杂网络节点重要性动态分析方法。将复杂网络节点重要性加上时间维度,引入可拓关联函数分析关联度变化,从而判断变化方向,给出变化的量。
1.3 节点重要性多属性值
在社会网络中,可用图模式量化,用图中节点表示个体,用边表示各个体之间的连接关系。可设复杂社会网络G=(V,E)是一个无向无权图,其中V={v1,v2,…,vn}是网络中所有节点的集合,|V|=n;E={e1,e2,…,em}是节点间边的集合,|E|=m,aij=1,其中aij=1表示节点i和节点j相连,否则aij=0,如图1所示。
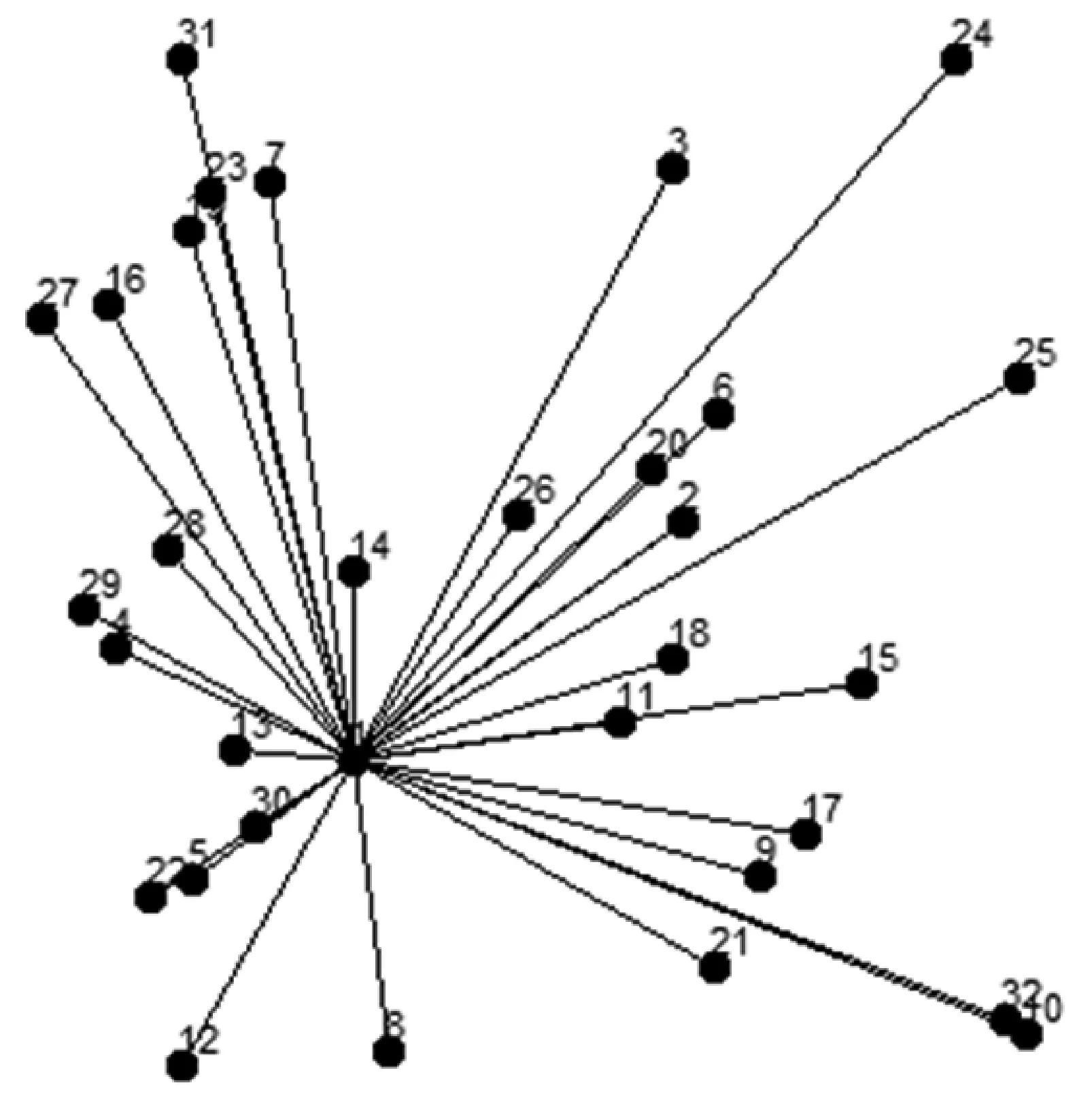
图1 根据社会网络人员熟识如否模拟复杂网络图(节点1为例)
度中心性用Dc表示为:
Dc=d(v)
(1)
式中:d为节点v的度,即直接相连的边数。
节点的介数Bc为:
(2)
式中:Sjk表示源节点j到目标节点k的最短路径数;Sjk(i)表示节点j和k之间经过节点i的最短路径数。
紧密度中性具体Cc表示为:
(3)
式中:dij表示以节点i为起点,以j为终点的最短路径中所含边的数量;N为节点总数。
在评估复杂网络各节点重要性时,为了克服单一属性的片面性,本文采用多属性(即度中心性、介数中心性、紧密度中心性和KS指标)综合考量,在计算完每个节点在对应属性上的关联度后,取综合关联度为该节点重要性的最终量值。
多属性分析方法要求对属性值进行标准化,每个节点在对应的属性上的取值规范化为:
(4)
式中:qij为第i个节点第j个属性值;pij为规范化后第i节点第j个属性值。
2 可拓聚类模型
2.1 模型经典域及节域设置
以网络节点O为对象,ci为节点各属性特征,O关于ci的量值vi构成的有序三元组M=(O,ci,vi)作为描述节点重要性的基元;而网络节点O的n个特征属性c1,c2,…,cn及O关于ci(i=1,2,…,n)对应的量值vi(i=1,2,…,n)所构成的矩阵M1称为n维物元[20]。
(5)
根据论域U中一个对象对于某特征的量值符合要求的程度,可分为满意区间X0=
(6)
式中:O表示网络节点,dr(r=1,2,…,n)表示对应的第r个等级;
2.2 关联函数
定义可拓距[21]为某节点与经典域节域区间的距离。给定区间X0=
(7)
反映各节点重要性与各经典域的隶属程度的函数为关联函数[22]。设区间X0=
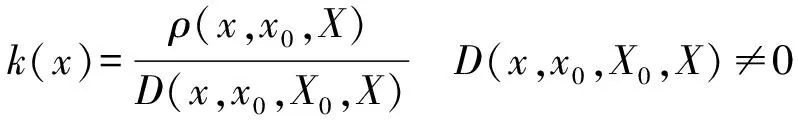
(8)

式中:ρ(x,x0,X)为可拓距;D(x,x0,X0,X)称为位值,用来描述点x关于x0与X0和X组成的区间套的位置关系。
2.3 熵权及综合关联度
在度量节点重要性综合关联度时,将根据每个属性的不同重要程度取合理的权系数计算得到。在复杂社会网络中,节点综合关联度有整体变化的趋势,因此利用等权值并不合适。根据网络节点不同属性的变化程度来设置不同的权值将更具可靠性。而熵权是根据特征参数值变化程度所反映的信息量大小来确定权值的客观赋权法。计算各节点的熵值ej:
(9)
计算各节点的熵权λj:
(10)
所有权值向量λ满足:
(11)
最后根据各属性关联度及熵权系数计算每个节点的综合关联度:
(12)
式中:i为节点序号;j为属性序号;n为节点数;m为属性数量。
2.4 知识发现
可拓集理论可用来描述复杂网络节点重要性动态变化趋势和方向。定义当T=(TK,TU)=(e,e)时,根据关联函数值把论域分为标准正域、负域和零界,即有表达式:V+={u|u∈U,k(u)>0},V-={u|u∈U,k(u)<0},V0={u|u∈U,k(u)=0}。当T=TK,TU≠(e,e)时,把论域U划分为关于变换T的正质变、负质变、正量变、负量变域和拓界,可分别形式化表示为:
V.+(T)={u|u∈U,y=k(u)≤0;Tu(u)∈U,y′=Tkk(Tuu)>0}
(13)
V.-(T)={u|u∈U,y=k(u)≥0;Tu(u)∈U,y′=Tkk(Tuu)<0}
(14)
V+(T)={u|u∈U,y=k(u)>0;Tu(u)∈U,y′=Tkk(Tuu)>0}
(15)
V-(T)={u|u∈U,y=k(u)<0;Tu(u)∈U,y′=Tkk(Tuu)<0}
(16)
V0(T)={u|u∈U;Tu(u)∈U,y′=Tkk(Tuu)=0}
(17)
3 实验与分析
3.1 算法流程
对于给定的复杂社会网络,可拓聚类算法首先分析节点的多重属性并计算其重要性。然后按照实际需求划分为不同的等级,统计每个等级的取值范围及其在全体数据中的取值范围分别构成经典域和节域。通过关联函数计算每个节点关于对应等级的关联度。利用熵权值取综合关联度。最后比较不同时间点每个节点综合关联度变化,计算关联差,给出等级变动。利用这种形式化模型刻画复杂社会网络,根据关联函数定量分析各个节点隶属于某区间的范围,并在不同时间点上给出动态变动。
3.2 节点重要性多属性值
实验数据来自Freeman观测的由美国国家科学基金会赞助的计算机会议的参加者构成的社会网络,该网络呈现出复杂网络的基本特征。会议的参加者都是社会网络研究领域从事新兴学科专业研究的研究者,选取其中32个人构成的网络数据,通过熟识与否来定义网络的边取值,并在两个时间点上进行了测量,两个时间点距离9个月。
根据该网络图测量节点的多重重要性属性,分别计算基于度中心性u1、介数中心性u2、紧密度u3以及K-shell分解值u4的影响力重要性量值。标准化后得到如表1、表2所示的量值矩阵。

表1 第一时点多属性节点重要性指标
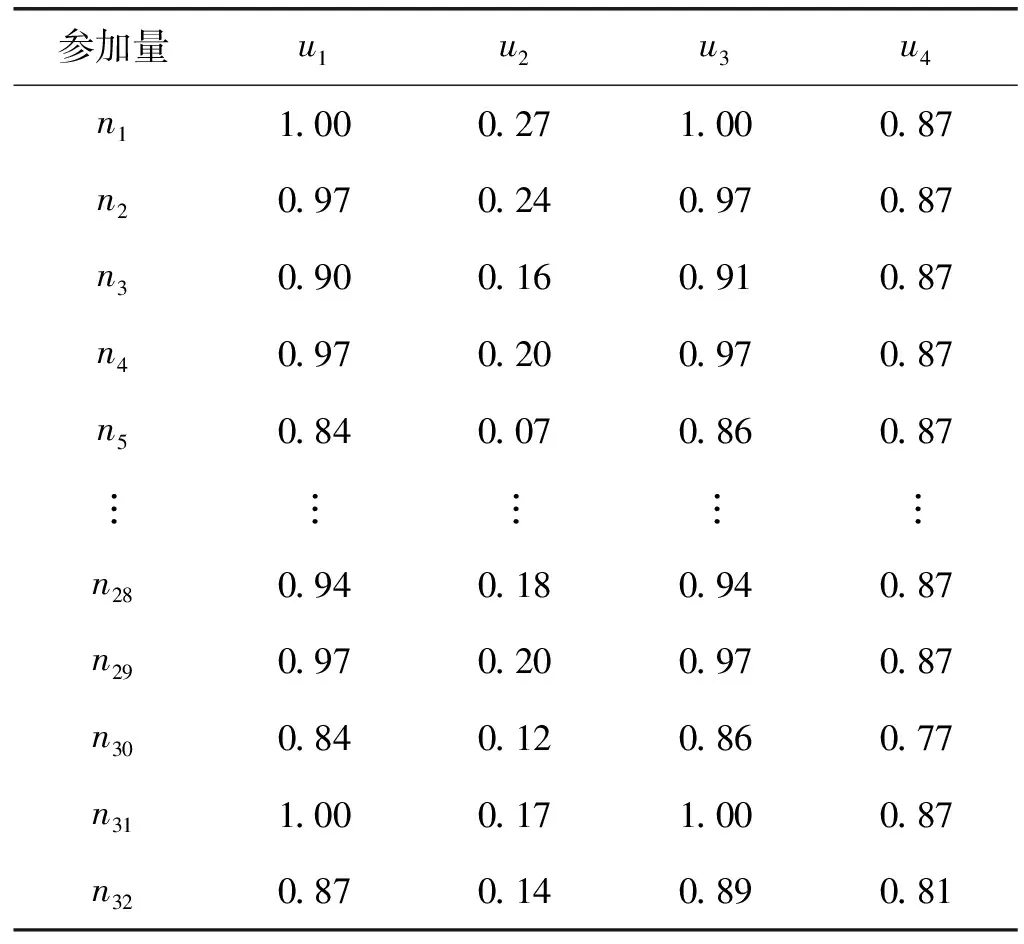
表2 第二时点多属性节点重要性指标
3.3 等级划分及经典域节域
节点重要性度量后,在每个属性上取前25%组成高影响力等级节点的经典域X0,取全部属性上的范围为节域X,如表3、表4所示。随着节点间的相互熟悉程度的提升,会出现属性值整体提高的可能,因此,在取经典域节域时在两个时点上分别取值,各自考察其高影响力等级节点的变化。此处的属性都是越大越好的效益型属性,最优点在经典域的最大值处取得,即右侧距中x0=b处。

表4 第二时点各个属性高影响力经典域及节域
3.4 关联度及熵权
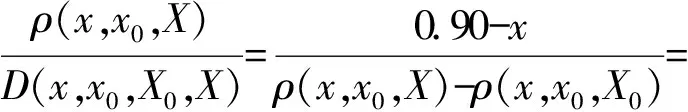
结果如表5、表6所示。
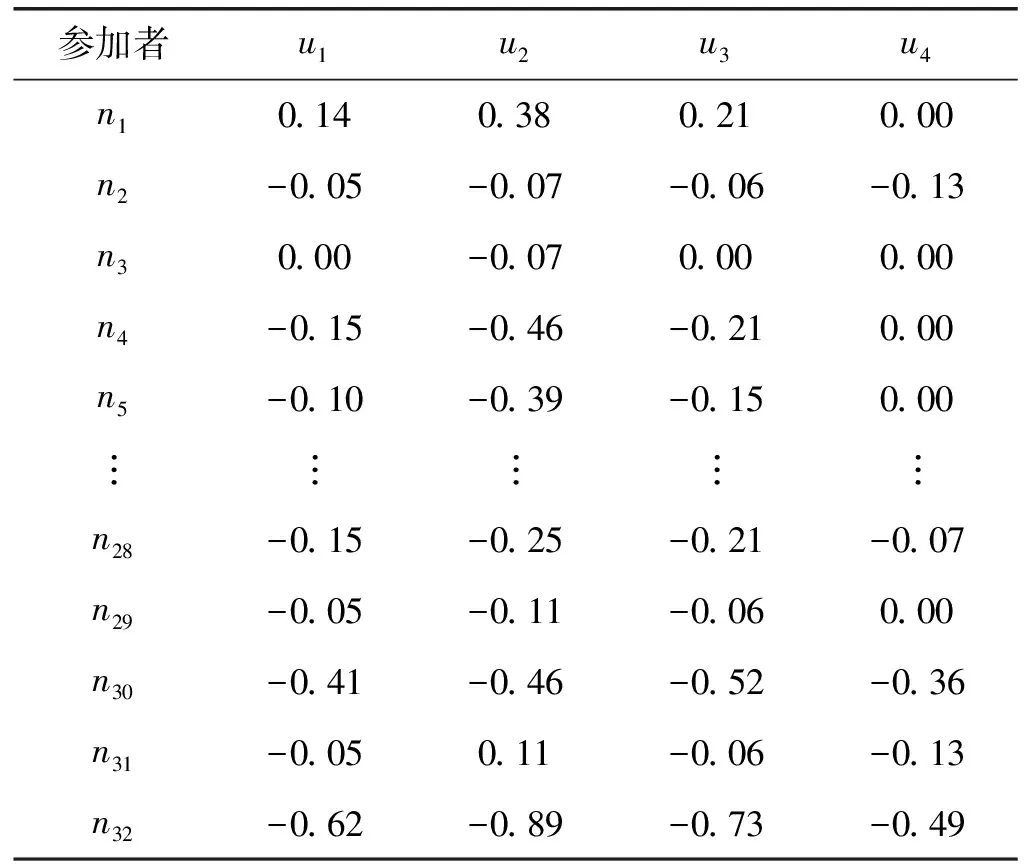
表5 第一时点各属性节点重要性关联度
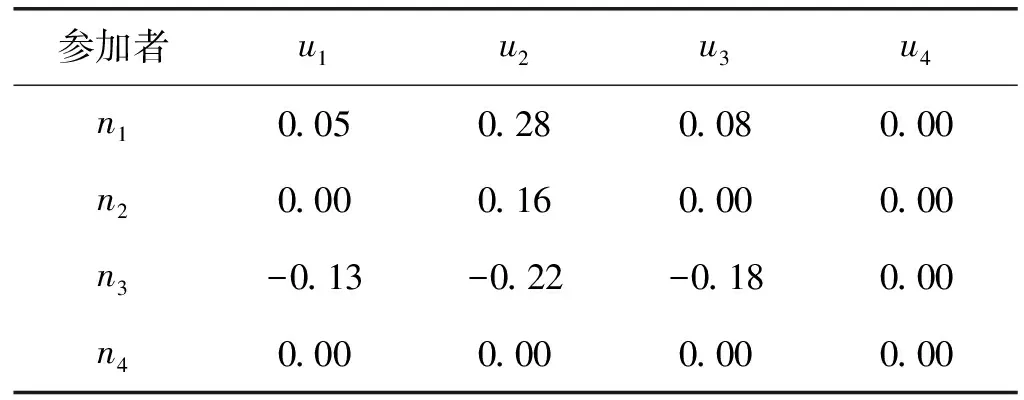
表6 第二时点各属性节点重要性关联度

续表6
根据式(9)和式(10)计算各个属性熵权值(如表7所示)。

表7 各属性不同时点熵权值
3.5 综合关联度及关联差
综合关联度的变化反映了节点重要性的变化,根据式(12),计算其前后两个时间节点T1、T2的综合关联度K(i)和关联差Sumi,数据结果如表8所示。
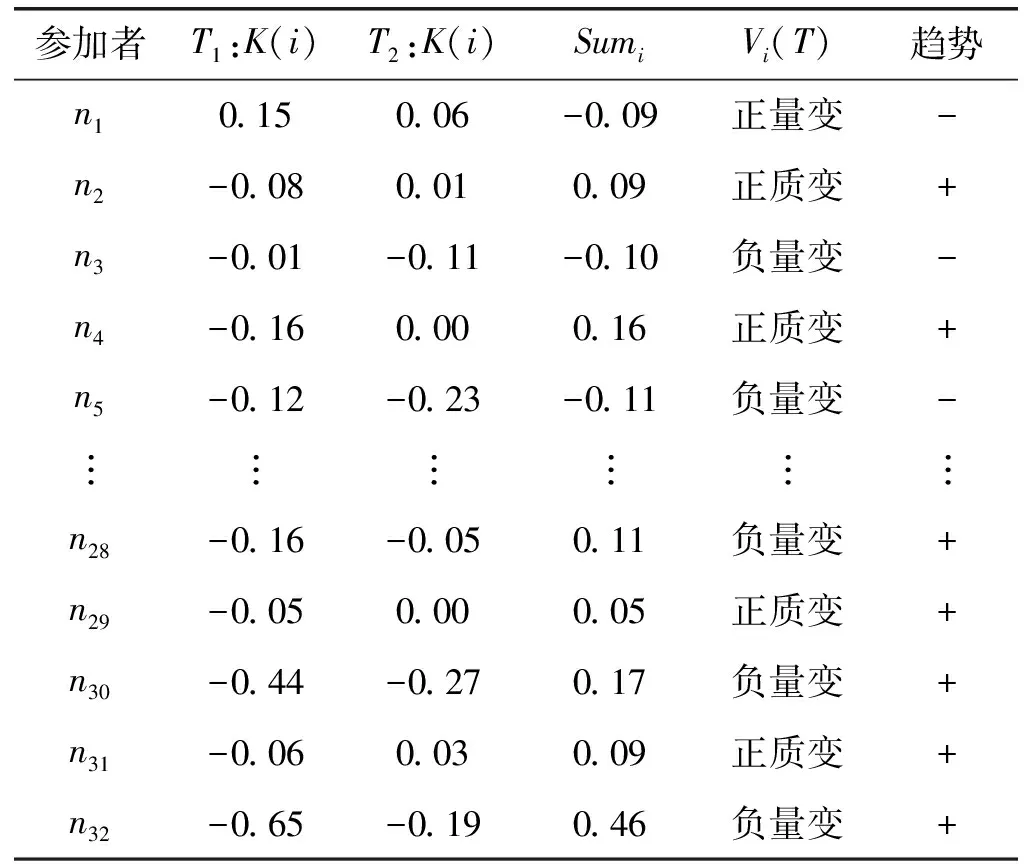
表8 节点重要性综合关联度及关联差
在这里,不仅能看到节点重要性变化方向,而且给出了变动的量。在趋势一栏里,节点重要性有所下降则其符号为负,相应地,节点重要性有所提高则符号为正。比较第一时点与第二时点综合关联度,如果符号相同则为量变,符号不同则为质变。更具体地,如果第一时点符号为负第二时点为正则等级提升,该节点变为高影响力节点。相反,如果第一时点符号为正第二时点为负则等级下降,该节点变为非高影响力节点。例如,节点2的综合关联度由负号变为正号,说明其重要性等级一定有所提升,由非高影响力节点转变为高影响力节点,发生了质变,即“正质变”,且其变化量是0.09。
将各节点重要性可视化表示如图2所示,利用坐标系能直观反映各节点重要性变化方向,变动量则为其差值。可见,零值以上部分对应着前25%高影响力等级节点,在第二时点有部分节点由高影响力节点转变为非高影响力节点,也有部分节点由非高影响力节点转变为高影响力节点,还有部分节点只有同一等级内的量变。
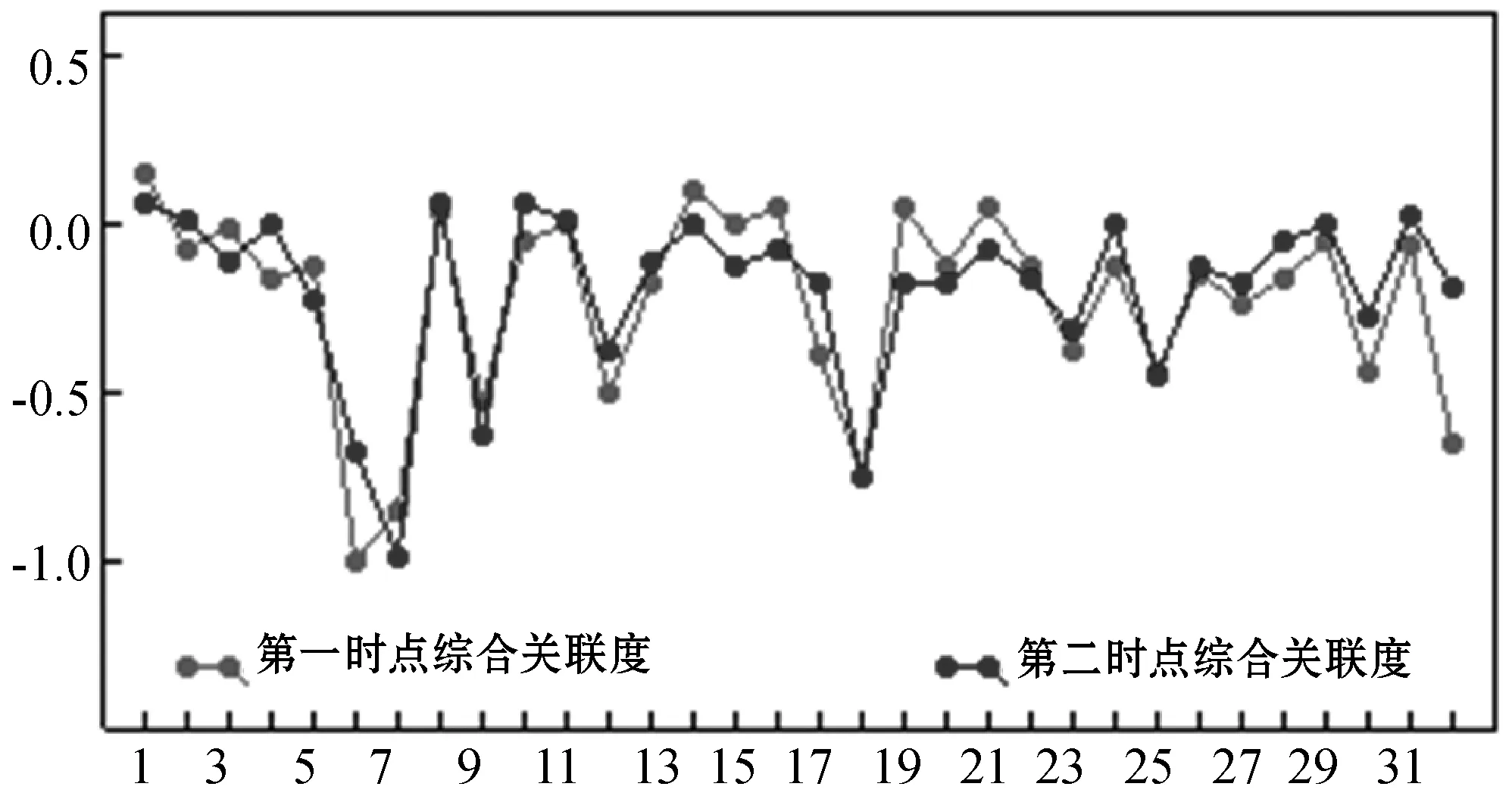
图2 各节点在不同时点的综合关联度变化
4 算法比较
假设共有N个节点,r个类别等级,各节点有m个特征,则K均值算法针对每一个特征首先选取k个样本节点,然后计算每个节点与各个样本节点聚类中心的距离,时间复杂度为O(N×k),共m个特征,则总复杂度为O(N×k×m)。而DBSCAN密度聚类算法,针对每一个特征,首先随机选取一个节点,然后检查其领域半径内是否达到密度要求,若是则新建聚类,把所有点加入候选集,在候选集中对没处理过的对象继续检查其领域,如此往复,时间复杂度为O(N×m)。而可拓聚类算法将每个特征上的节点重要性划分为r个类别等级,时间复杂度均为O(m×r)。由于N≫r,所以可拓聚类时间复杂度较低。当然,可拓聚类中的等级个数主要是由根据实际问题或者经验知识划分得到,粒度相对较粗,但可拓聚类的特点在于能够描述网络节点影响力在动态变化下的量变和趋势,其他的聚类算法则不具备。
5 结 语
复杂网络往往具有多对多的复杂关系,对复杂网络的把握有利于掌握舆论热点和对关键的认定。而对复杂社会网络节点重要性动态观测,从变化的视角审视网络,本文给出了可拓聚类分析方法。该方法根据多属性计算节点重要性,首先通过聚类分析划分节点重要性等级,构造经典域和节域。然后根据关联函数计算节点与对应等级关联度,进而计算综合关联度,最后分析不同时点的变化量。通过可拓聚类方法实现对节点重要性变化的动态把握,使网络节点及各指标均能以形式化的模型更直观地展现。该方法不仅能判别节点重要性的变化方向,而且给出了变化的量。接下来工作包括:(1) 对可拓聚类预测方法在更大数据集中的预测效果作进一步探索;(2) 在节点重要性划分等级时尝试利用其他方法,而不是根据需要主观划分;(3) 在一个有向带权网络图上利用该方法,验证是否具有相同结果等。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
中草药(2022年17期)2022-09-05
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
金桥(2021年3期)2021-05-21
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
NBA特刊(2018年14期)2018-08-13
人大建设(2017年11期)2017-04-20
