
基于深度学习的复杂网络实时Sybil攻击检测算法
2019-07-16 01:18王春明
计算机应用与软件 2019年7期
关键词:标签
李 扬 王春明
1(江苏商贸职业学院电子与信息学院 江苏 南通 226011)2(南通大学计算机科学与技术学院 江苏 南通 226019)
Deep neural network
0 引 言
社交网络是一种典型的复杂网络,目前已成为人们日常生活、社会活动与商业活动的一部分,Twitter、微博、微信、网易云音乐等社交平台每天受到大量的关注与参与,社交网络的安全性随之成为一个亟待解决的问题。Sybil攻击是指利用社交网络中的少数节点控制多个虚假身份,利用这些身份控制或影响网络中正常节点的攻击方式[1]。目前主要有以下几种类型的Sybil攻击[2]:直接通信、间接通信、伪造身份、盗用身份、同时攻击、非同时攻击。Sybil攻击对网络的危害大、隐蔽性高,一旦发生攻击则会造成巨大的破坏,因此对Sybil攻击进行精确地预测是目前主要的研究方向。
目前社交网络的Sybil攻击检测方法主要可分为基于网络拓扑结构的检测机制与基于社交网络用户特征的恶意用户检测两种类型[3],这两种检测类型均需要分析明显的Sybil攻击行为。并且此类方案需要分析网络中的每个节点与连接[4],因此对于大规模的动态网络场景,这两种方法的效率较低。基于网络拓扑结构的方案假设信任关系多的网络中攻击量较低,并且假设用户的连接时间较短,如果这两个假设基础不成立,直接导致Sybil防御系统无效。
近期对社交网络的Sybil攻击检测研究主要集中于Sybil的用户特征与网络特征[3],以及社交网络的拓扑结构[2],这些研究均通过10万个用户的数据进行实验,评估特征集或者网络拓扑结构对Sybil攻击检测的影响。实际情况下社交网络的规模极大、拓扑复杂,而攻击检测系统的效率是另一个关键的性能指标,本文从另一个角度出发,采用深度学习技术同时提高对复杂网络中Sybil攻击的检测准确率与时间效率。
极限学习机(Extreme Learning Machine,ELM)是一种单层人工神经网络,无需专家知识并且学习速度较快,目前广泛地应用于复杂网络的恶意行为识别问题中[5]。极限学习机对于大规模数据的学习速度是一个瓶颈[6],本文对传统ELM进行了改进,将传统的学习时间从小时级别降低到秒级别。本模型包括三个模块,分别为:数据采集模块、特征提取模块与深度学习模块。本方案实现了较快的学习速度,对于Sybil攻击实现了较快的响应速度。
1 基于ELM的半监督表示学习
ELM主要存在三个问题:(1) 每层的随机投影机制导致性能不稳定;(2) 非自动地调节隐层节点的数量较为耗时;(3) 如果隐层规模较大,那么训练时间较长,并且需要大量的存储空间。多层核ELM[7]可解决前两个问题,但处理大规模数据所需的计算成本与存储成本仍然是个难题。提出新的ELM,解决了上述ELM的三个问题。
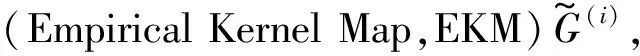
1.1 经验核映射
假设X=[x1,x2,…,xn]T∈Rn×d表示一个n列、d行的输入矩阵,通过核函数κ(·)计算特征空间的内积:
Ωk,j=κ(xk,xj,σ)={φ(xk),φ(xj)}
(1)
∀k,j=1,2,…,n
式中:σ为一个可调节参数,Ω∈Rn×n为核矩阵,φ(x)为核空间特征映射。将核矩阵Ω分解为Ω=GGT,其中G=[φ(x1),φ(x2),…,φ(xn)]T∈Rn×D,D是Ω的秩,G称为经验核映射。
假设V=[v1,v2,…,vl]T∈Rl×d是l个路标点的集合,采用Nystrom方法[8]生成两个小规模矩阵Ωnl∈Rn×l与Ωll∈Rl×l,其中(Ωnl)k,j=κ(xk,vj,σ),(Ωll)k,j=κ(xk,vj,σ)。采用Ωnl与Ωll近似核矩阵Ω:
(2)
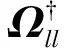
(3)
(4)
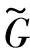
1.2 多层极限学习机(Multilayer extreme learning machine, ML-ELM)
H(i)Γ(i)=X(i)
(5)
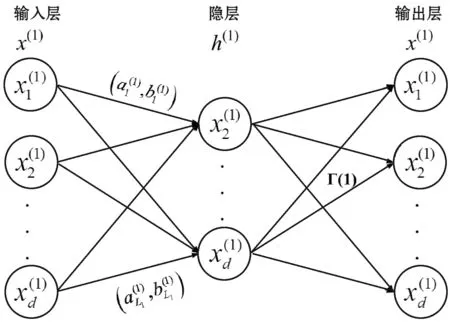
(a) 变换矩阵Γ作为表示学习
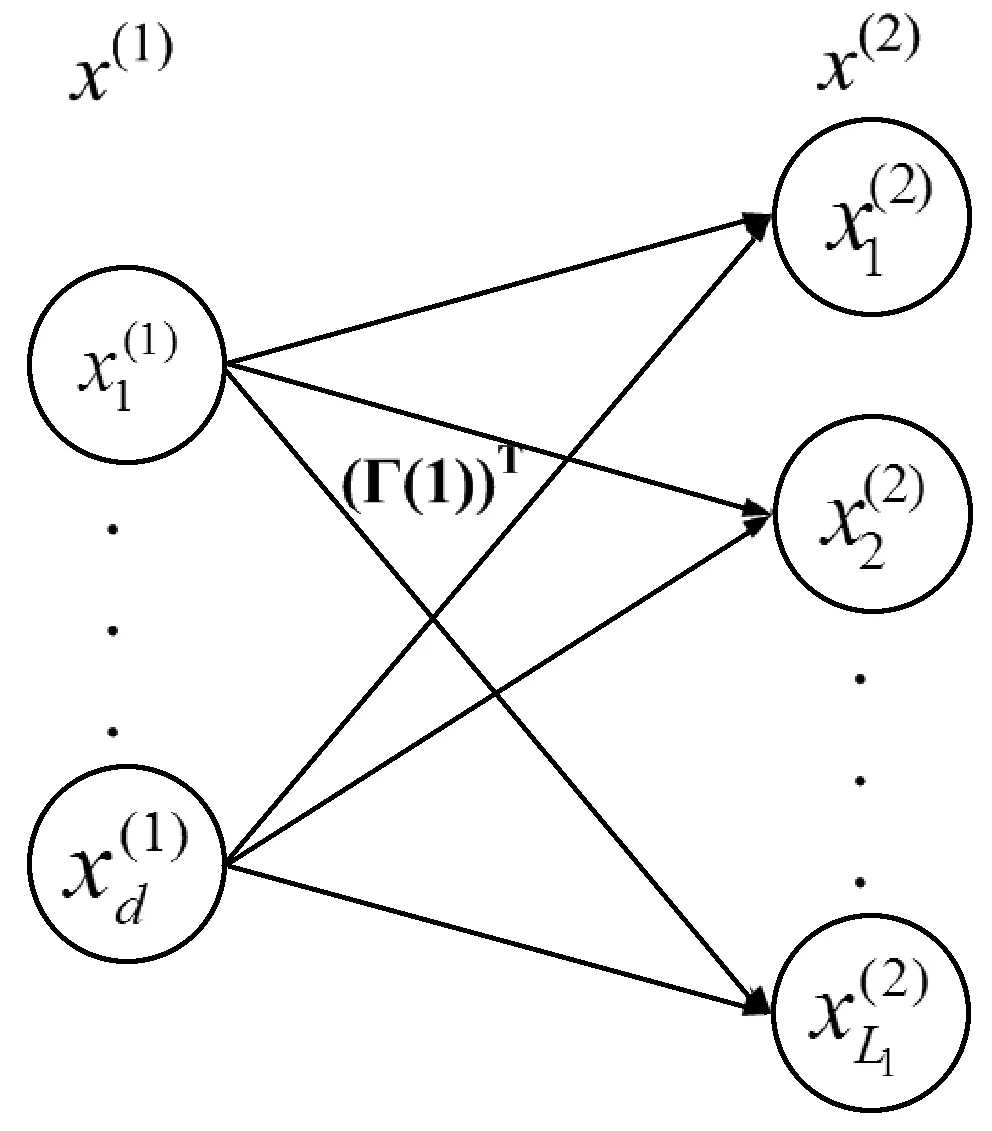
(b) 计算的新输入表示
(c) x(2)作为输入学习的输入
(d) 无监督表示学习结束图1 多层ELM的结构
H(i)的计算方法为:
(6)
式中:h(i)(a(i),b(i),x(i))=gi(a(i)x(i)+b(i)),gi为第i层的激活函数,第i层的输入a(i)与bias(偏差)b(i)均为随机产生。Γ(i)的计算方法为:
(7)
式中:ILi与In分别表示维度为Li与n的单位矩阵,Ci为第i层的正则化项。
式(7)的X(i)与Γ(i)相乘获得一个新的数据表示:
Xi+1=gi(X(i)(Γ(i))T)
(8)
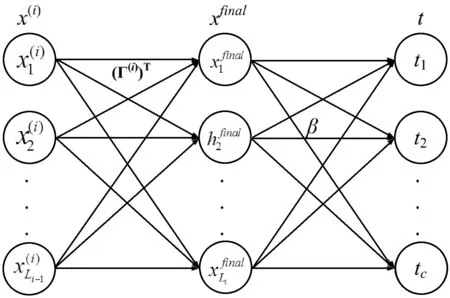
通过图1(d)的学习程序可获得X(1)的最终数据表示Xfinal。ML-ELM直接将Xfinal作为隐层来学习输出权重β:
Xfinalβ=T
(9)
式中:T=[t1,t2,…,tn]T,tk∈Rc是一个独热输出向量,c是分类数量。通过求解以下方程获得权重矩阵β:
(10)
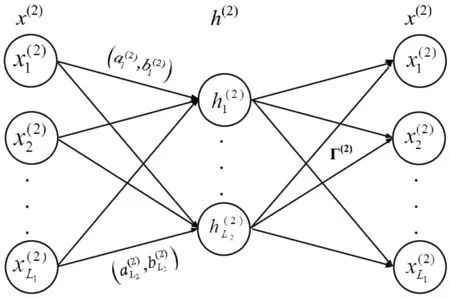
1.3 多层核极限学习机(Multilayer kernel extreme learning machine, ML-KELM)
为ML-ELM引入核学习来实现高度的泛化效果[9],ML-KELM包含两个步骤:(1) ELM-AE栈式核的无监督表示学习;(2) 基于K-ELM的监督特征分类。
Ω(i)Γ(i)=X(i)
(11)
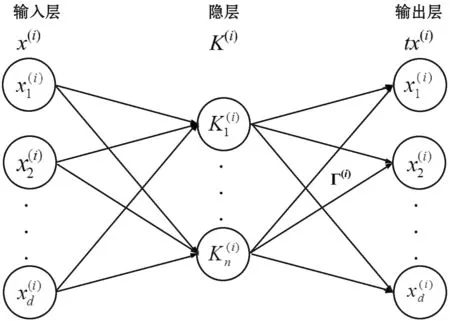
图2 隐层到输出层的学习过程
Γ(i)的计算方法为:
(12)
数据表示X(i+1)的计算方法为:
X(i+1)=gi(X(i)(Γ(i))T)
(13)
通过无监督表示学习获得最终的数据表示Xfinal,并且用于训练K-ELM分类器:
Ωfinalβ=T
(14)
式中:Ωfinal为核矩阵,权重矩阵的求解方法为:
(15)
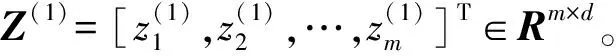
Z(i+1)=gi(Z(i)(Γ(i))T)
(16)
计算核矩阵ΩZ∈Rm×n获得最终的数据表示Zfinal:
(17)
(18)
1.4 经验核映射自编码器(Empirical kernel map Autoencoder, EKM-AE)
(19)
(20)
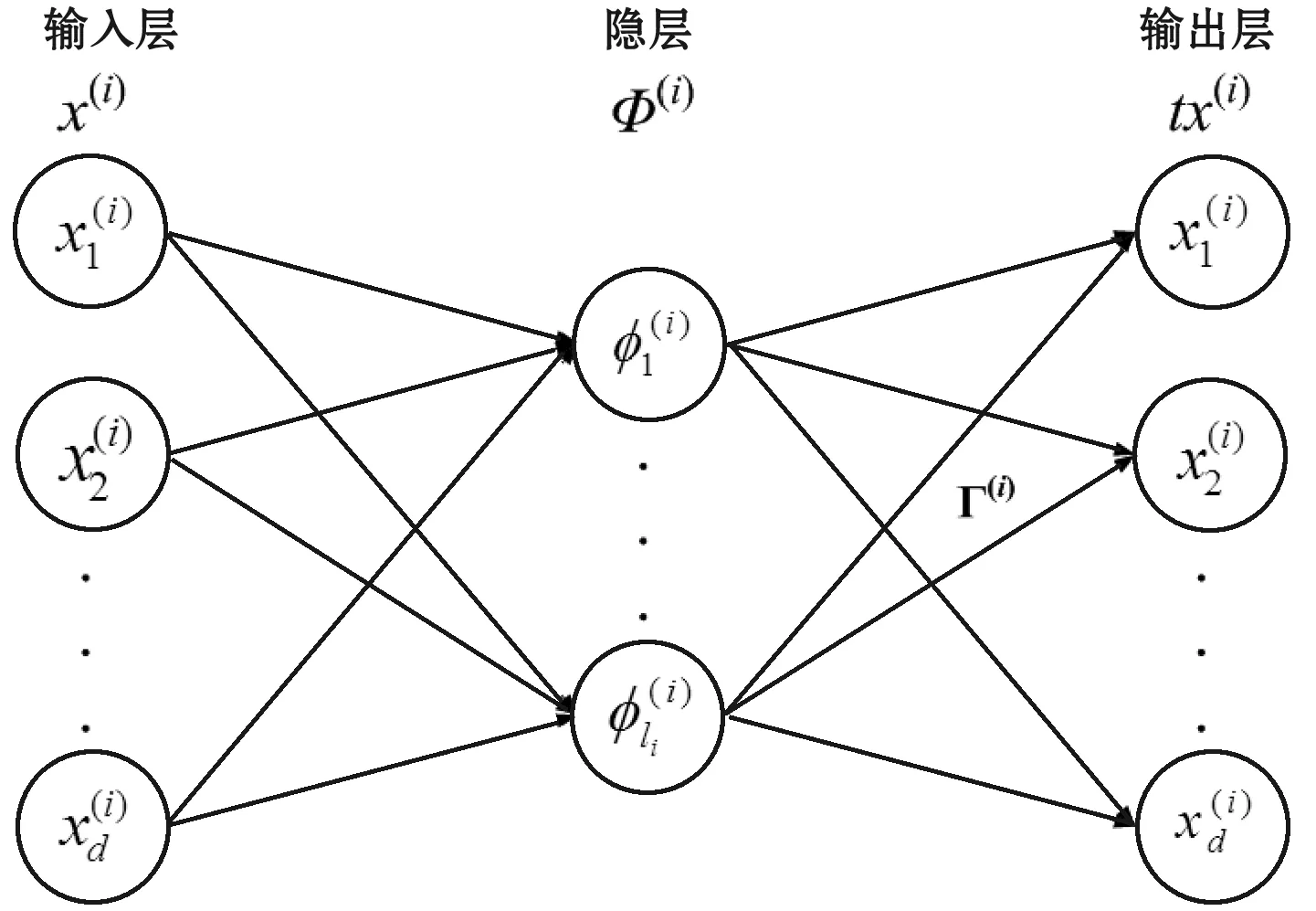
图3 第i个EKM-AE的结构
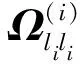
(21)

(22)
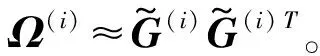
学习EKM-AE的第i个变换矩阵Γ(i):
(23)
Γ(i)的求解方法为:
(24)
数据表示X(i+1)计算为:
Xi+1=gi(X(i)(Γ(i))T)
(25)
1.5 改进的ELM
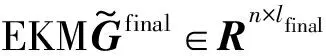
(26)
输出权重β的计算方法为:
(27)
将测试数据Z(i)与第i个变换矩阵Γ(i)相乘,获得数据表示:
Z(i+1)=gi(Z(i)(Γ(i))T)
(28)
(29)
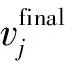
(30)
2 Sybil攻击的预测模型
设计了Sybil节点的预测方案,采用深度学习模型检测Sybil节点发出的请求,并且融合社交网络中用户的社交属性作为攻击检测的一个重要依据。本模型能够在线地检测社交网络中的Sybil攻击。
2.1 系统架构
本文在线的Sybil攻击检测流程如图4所示。首先,从网络中采集数据,提取合适的特征,然后通过深度学习技术预测网络中的攻击行为。
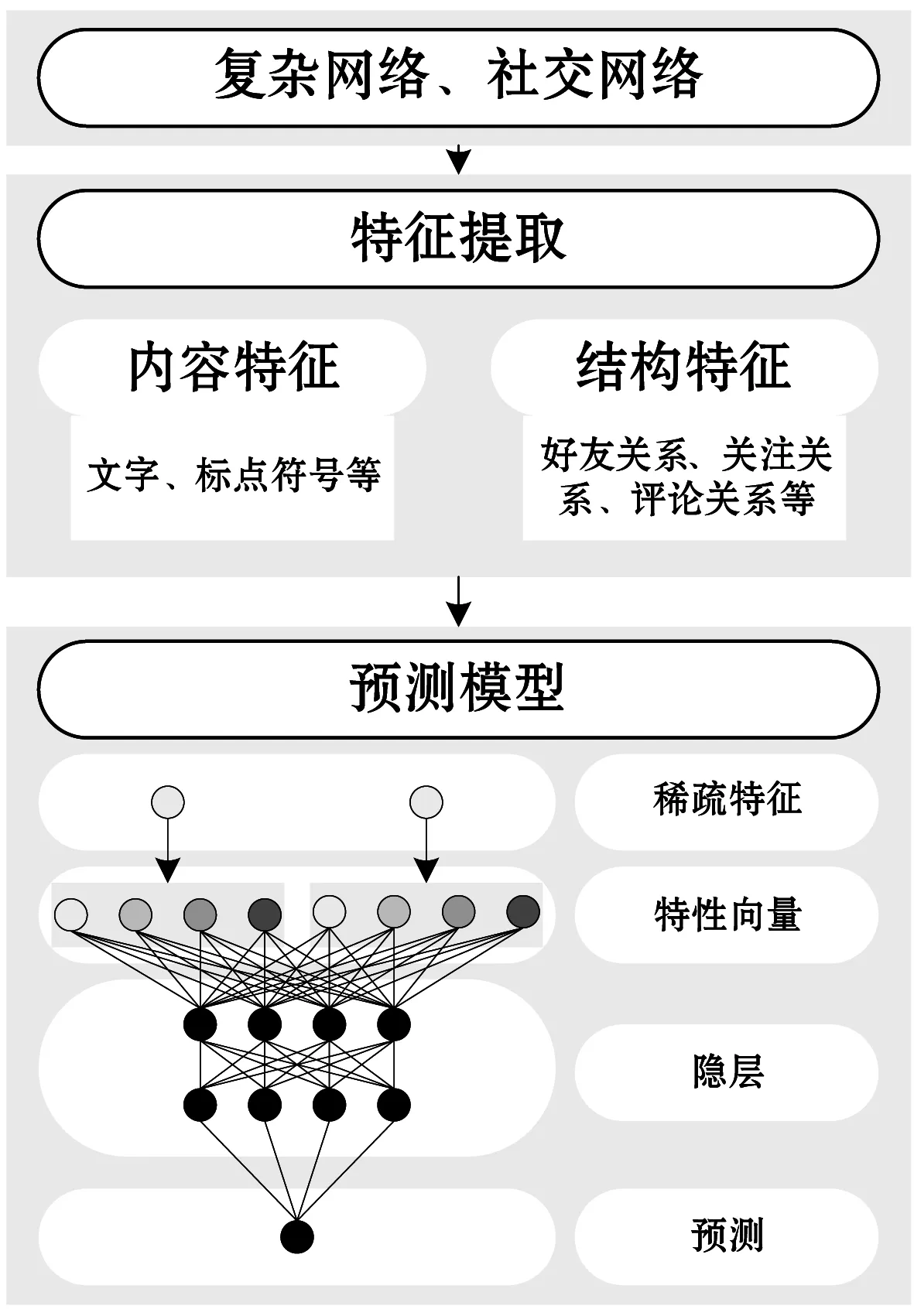
图4 在线的Sybil攻击检测流程
2.2 网络数据的采集模块
选择“微博”作为研究的社交网络模型,利用新浪微博提供的开放应用程序编程接口API编程提取微博的内部信息。
2.3 特征提取模块
为了准确地识别Sybil行为,该模块提取了用户不同类型的特征。通过新浪微博提供的开放API采集原始样本数据,然后将样本分为三种类型,如图5所示。
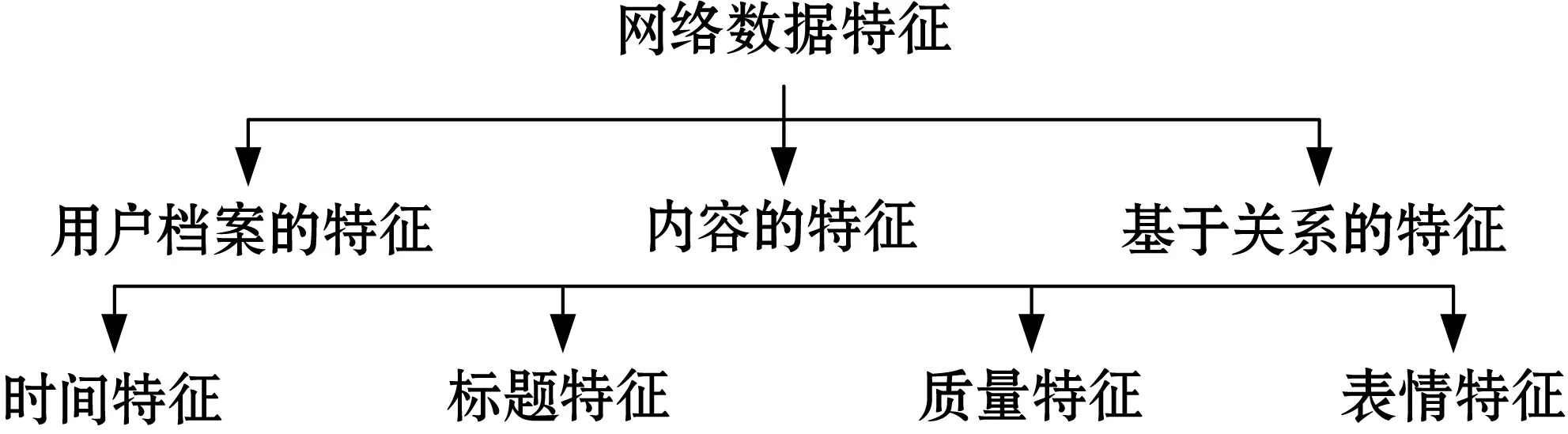
图5 微博的特征分类
2.3.1用户档案的特征
用户档案的信息可用于将用户与用户行为分类。采用微博的官方接口获取该类信息,包括:被关注数量、每天发布量、转发量等。此外,微博中“@”操作也是一种社交关系,将“@”操作作为一种社交关系。
2.3.2内容的特征
内容特征进一步分为四个子类型:
① 时间特征:微博发布的日期与时间作为一个关键变量,此类特征在市场变化的研究中具有重要的价值。该类特征包括了多个时间敏感的特征,例如:发微博的时间戳、两条微博之间的间隔。
② 标题特征:微博标题反映了一条微博的核心内容。其中关键词、共生词汇、标签、作者信息均为重要的特征。
③ 质量特征:语句的特点有助于理解微博和消息的潜在意思。Sybil用户的消息一般采用简单的词语与语法,本方案则考虑了用户消息的词汇量。采用文献[10]的“中文词汇分割与POS”技术对中文内容进行语言评级。
④ 表情特征:表情是观察消息语气的重要特点。本文采用多个表情分析对消息内的表情进行处理,提取消息的表情特征,所采用的表情评级策略包括:活跃度、严肃性、满意度评级、表情符号等。
2.3.3基于网络图的特征
社交网络的结构直接决定了节点之间的互动情况。根据用户在社交网络中的操作方式也是发现Sybil攻击的有效方式。本系统追踪三个操作指标,分别为转发操作、用户访问操作、共生微博标签。前两个操作表示该用户不是直接社交关系,第三个操作同时出现多个标签,说明该用户消息具有广播的特点。
2.4 基于深度学习的Sybil攻击预测
采用基于极限学习机的深度学习技术对用户进行分类(Sybil用户与合法用户)。将每个用户表示为一个特征集,用户Ui表示为特征集F=(f1,f2,…,fk),k=80。为每个特征分配一个权重,权重集表示为一个向量W=(w1,w2,…,wk)。加权的特征集计算为下式:
(31)
Sybil攻击的极限学习机隐层方程为:
(32)
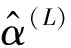
采用交叉熵损失方程(Cross-entropy Cost Function,CCF)作为极限学习机的计算方程,CCF成本方程如下:
(33)
2.5 算法复杂度分析
2.5.1存储复杂度
ML-KELM的训练阶段,第i层需要O(n2)的存储空间(Ω(i)与X(i))。本文的ELM方案保存第i层矩阵G(i)与X(i),其存储成本与数据规模n为线性关系。因此,存储成本从二次方级降低至线性级。

2.5.2时间复杂度
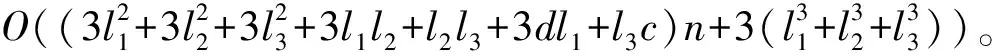
假设l1=l2=l3=np,因为p远小于1,那么ML-KELM与本文ELM方案训练阶段的计算复杂度分别为O(n3)与O(p2n3)。ML-KELM与本文ELM方案测试阶段的计算复杂度分别为O(n2)与O(p2n2)。
3 性能评估与分析
3.1 实验数据集
采用新浪微博提供的开放API提取数据集,从关注量超过10万的账号中随机选择25 510个账号作为训练集,13 957个账号作为测试集,这些用户作为正常用户,如表1所示。采用Erdos-renyi模型[11]为训练集与测试集分别生成1 000个Sybil节点。
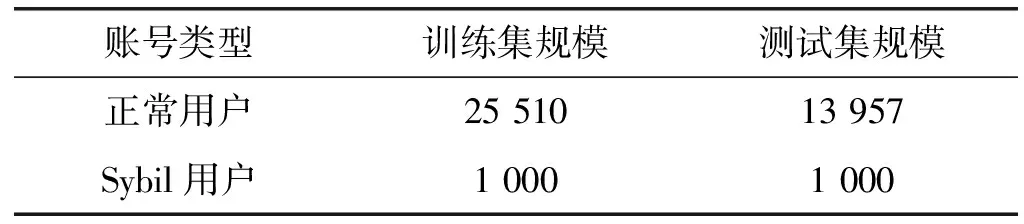
表1 实验数据集
3.2 Sybil攻击的检测效果
首先选择ML-ELM[12]与HELM[13]两种极限学习机与本方案比较,评估本方案对ELM的改进效果,然后,选择SRSUIM[14]与GSF[15]两个Sybil检测算法与本方案进行比较,评估本方案的检测性能。
采用攻击检测率、误检率与漏检率三个指标评估对Sybil攻击的检测性能,检测率指识别出的Sybil用户数量与Sybil用户总数的比例,误检率指错误识别的正常用户数量与正常用户数量的比例,漏检率指未能识别的Sybil用户与Sybil用户的比例。
图6所示是五个检测算法对于实验数据集的检测结果。可以看出,本方案的检测率高于ML-ELM与HELM两种基于极限学习机的检测算法,本方案对EML实现了有效的增强,GSF框架通过对社交网络的社交关系进行深入的分析,实现了较好的检测率,优于ML-ELM与HELM两个算法。三个基于ELM的检测算法表现出极为接近的误检率与漏检率,均低于SRSUIM与GSF两个算法,SRSUIM主要通过节点影响力分析识别Sybil用户,而有些正常用户与Sybil用户的行为较为相似,导致出现误检与漏检。综合检测率、误检率与漏检率三个指标可得出结论,本方案实现了较好的检测效果,并且实现了对ELM的增强。
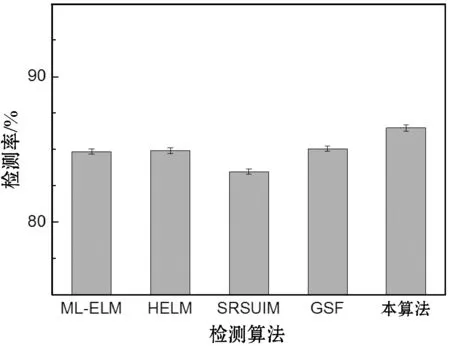
(a) 检测率
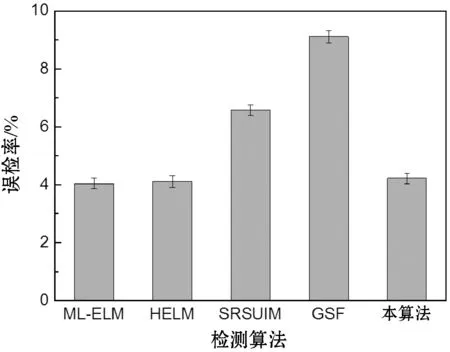
(b) 误检率
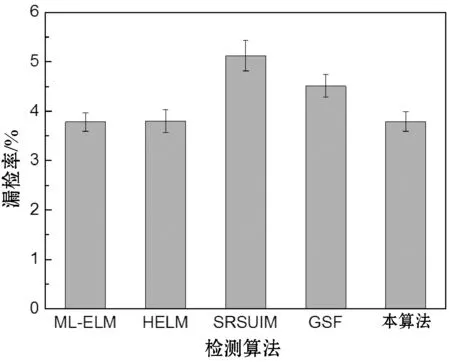
(c) 漏检率图6 五个检测算法对于实验数据集的检测结果
3.3 Sybil攻击的时间效率与存储成本
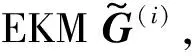
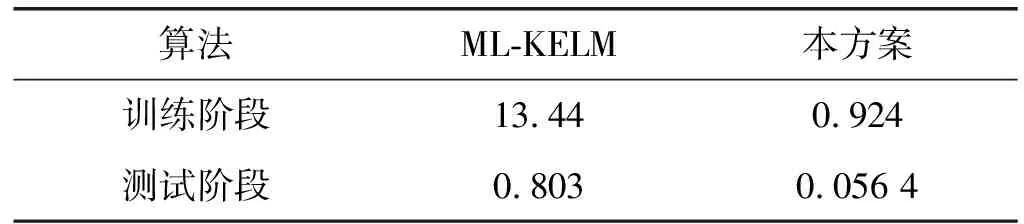
表2 两种ELM的时间效率 s
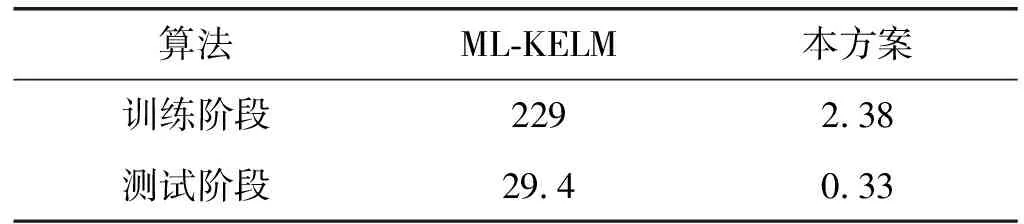
表3 两种ELM的存储成本 MB
4 结 语
社交网络的规模极大、拓扑复杂,本文从攻击检测系统的效率出发,采用深度学习技术同时提高对复杂网络中Sybil攻击的检测准确率与时间效率。极限学习机对于大规模数据的学习速度是一个瓶颈,本文对传统ELM进行了改进,将传统的学习时间从小时级别降低到秒级别。实验表明,本方案提高了ELM的时间效率与存储效率,并且实现了较高的Sybil用户检测效果。本方案将ML-ELM随机产生的隐层替换为估计的隐层,该处理提高了训练阶段的速度,但是对模型的精度会产生微小的影响,未来将重点考虑在模型精度与时间效率之间取得平衡。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
消费电子(2022年6期)2022-08-25
中学生天地·高中学习版(2018年6期)2018-07-05
海峡姐妹(2018年3期)2018-05-09
电脑知识与技术·经验技巧(2017年6期)2018-02-24
Coco薇(2015年5期)2016-03-29
海外星云(2015年15期)2015-12-01
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
