
基于相空间重构的GQPSO-WNN短时交通流预测
2019-07-16 01:19陈庆春类先富
计算机应用与软件 2019年7期
唐 瑞 陈庆春 类先富
1(西南交通大学信息科学与技术学院 四川 成都 611756)2(广州大学机械与电气工程学院 广东 广州 510006)
0 引 言
智能交通系统(ITS)的发展是减少城市污染、缓解交通拥堵以及避免交通事故发生的关键。短时交通流的预测模型是指预测时间不超过15 min,通过得到的交通流历史数据选择适当的预测模型,在t时刻在线实时地预测出时刻的交通流数据。短期交通预测模型的实际应用之一是根据实时交通信息帮助旅客选择t+Δt出行路线或提前计划出行。它还可以帮助制定主动的交通管理策略,改善交通拥塞。
传统的交通流预测精度已经无法满足需求[1],在过去的几十年中,交通短期变量预测得到了发展和改进。预测方法可以分为两类:统计算法类,如非参数回归模型、卡尔曼滤波等;人工智能类,如BP神经网络和WNN等[2-3];其中,WNN模型是最常用的短期交通预测模型。尽管WNN模型易于构建,并取得了让人满意的预测效果。但是人工智能网络预测模型存在着许多缺点,比如:早熟收敛或无法收敛、求解精度不高等,所以许多研究者引入了粒子群等优化算法来对这些智能网络算法进行改进[4]。粒子群优化算法收敛速度快,在寻求函数最优解方面有很大优势,能改善神经网络收敛速度慢、训练误差过大的问题。但是,标准粒子群算法存在一些缺点,如搜索空间有限、容易早熟、容易陷入局部优化[5]。对应的,本文采用全局收敛的量子粒子群算法在粒子后期搜索中改善收敛性能问题,由于量子粒子群算法没有交叉和变异过程,难以搜索到全局最优点,因此采用遗传算法进行改进。结合这两种算法,可以提高捕获交通流数据中的线性和非线性模式的可能性,并提高预测性能。为了使提出的预测模型更加可靠,还需要对交通流时间序列数据进行重构,分析序列内部的混沌特性,验证其可预测性[6]。
1 相空间重构
交通流时间序列是一组看似无规律、随机性的序列,这样的序列是否具有可预测性是后续预测模型建立的前提。1980年Packard[8]和Takens[9]提出了相空间重构理论(phase space reconstruction theory),其主要目的在于恢复时间序列的混沌吸引子,其原理是选择合适的延迟时间τ和嵌入维数m,采用混沌理论的相空间重构技术可以将低维时间序列映射到高维相空间里并保持微分同胚。设x={xi|i=1,2,…,N}为给定的交通流时间序列,选择适当的参数重构相空间得到[10]:
X=[xi,xi+τ,…,xi+(m-1)τ]Ti=1,2,…,M
(1)
式中:X是维数为M×m的轨线矩阵,相点个数为M=N-(m-1)τ。
1.1 C-C方法
1999年,H.S.Kim等[11]提出C-C方法,该方法认为嵌入维数m不依赖于延迟时间τd而依赖于延迟时间窗口τw,通过计算公式τw=(m-1)τd可以得出嵌入维数m的值。对于时间序列x={xi|i=1,2,…,N},定义关联积分为以下公式[7]:
(2)
式中:r>0为尺度,dij=‖Xi-Xj‖,Xi为根据给出延迟时间τ和嵌入维数m的值重构相空间的点。若x<0,则θ(x)>0;若x≥0,则θ(x)=1。将时间序列{xi}分解t个不重叠的时间序列,采用分块平均策略:
(3)
令N→∞时,有:
(4)
对于独立同分布的时间序列,那么m、t是固定的,当N趋近于无穷时,则对所有的r均有S(m,r,τ)恒等于0。但是实际序列是有限的且可能存在相关的元素,所以S(m,r,τ)≠0,关于半径r的最大偏差:
ΔS(m,τ)=max{S(m,rj,τ)}-min{S(m,rj,τ)}
(5)
m=2,3,4,5;j=1,2,3,4
Brock等[12]根据数学统计结果表明,选取合适的N,计算出时间序列的标准差σ,三个统计量的计算公式:
(6)
(7)
(8)
式中:rj=jσ/2,j=1,2,3,4。
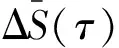

图1 C-C方法计算交通流数据表示图

1.2 Lyapunov指数计算
Lyapunov指数是刻画相空间中两条初始值十分靠近的轨道,随着时间推移呈指数形式的平均发散率[13],若最大Lyapunov指数大于0,则可以认为系统是混沌的。
小数组方法[14]是混沌理论里计算最大Lyapunov指数普遍适应的方法,跟Jacobian方法、P-范数法等比起来,该算法具有计算量不大、相对易操作、对小数据组比较可靠、求解精度较高的优点。
使用小数组方法求解Lyapunov指数的步骤如下[11]:
Step1对时间序列进行FFT变换,求出平均周期P;
Step2根据计算得到的m和τ,重构相空间矩阵{Xj=j=1,2,…,M};
Step3找出给定轨迹上的每个点相隔最近的点,即:
d(0)=min‖Xj-X′j‖ |j-j′|>P
(9)
Step4寻找相空间轨迹矩阵里Xj最近点经过i个时间点后的距离:
dj(i)=min‖Xj+i-X′j+1‖
(10)
Step5求出所有的lndj(i)平均y(i),q为当dj(i)≠0时的值,即:
(11)
如图2所示,对交通流时间序列数据进行仿真实验求得的最大Lyapunov指数,即为最小二乘法拟合后的曲线斜率λ。从图中可以看出,λ是大于0的,根据定理说明交通流时间序列是混沌的,可以进行短期预测。

图2 小数量法求得交通流最大Lyapunov指数
2 小波神经网络(WNN)模型
如图3所示,WNN是三层架构,包括输入层、隐藏层(其中小波函数用作激活函数)和输出层(其是隐藏层的加权输出的线性求和)[5]。

图3 小波神经网络拓扑结构
图3中xi是输入参数,yk是输出参数。wij和wjk是神经网络的权值。
(12)
本文采用的小波基函数为Morlet母小波基函数,因为它在[-1,0]以及[0,1]上是单调的,数学公式为:
y=cos(1.75x)e-x2/2
(13)
WNN的输出网络层计算公式为:
(14)
式中:wik为隐含层到输出层权值;h(i)为第i个隐含层节点的输出;l为隐含层节点数;m为输出层节点。
传统的小波神经网络采用的是梯度下降法来调整参数,网络权值、伸缩因子、平移因子这些参数的初值选取一般采用试探法给定[15],可能会造成求解过程中陷入局部最优和产生振荡的不良效果,网络训练误差也达不到设定的要求,因此本文采用粒子群优化算法对其进行改进。
3 量子粒子群优化算法
3.1 粒子群优化算法
粒子群优化算法(Particle Swarm Optimization,PSO)[16]是一种利用速度向量Vi和位置向量Xi模拟社会有机体的自然演变过程。算法里面的每个粒子相当于一种当前问题的候选解决方案,这些粒子将四处移动以搜索最佳值,每个粒子记录其最佳先前位置(给出最佳适应值的位置)为gbesti,称为个体最佳位置。在每次迭代中,每个粒子与整个种群中的其他粒子竞争最佳位置zbest的最佳粒子(在种群中具有最佳适应值),称为全局最佳位置。然后使用这些信息来调整自己的速度和位置,从而实现解决方案领域的个性化优化。粒子的更新公式如下:
(15)
(16)
式中:ω为惯性权重;k为当前的迭代次数;Vid为粒子速度;c1和c2为加速度因子;r1和r2为分布于[0,1]之间的随机数。粒子群算法虽然在鲁棒性、求解精度上有明显优势,但是粒子由于随机性不高容易陷入局部最优。
3.2 量子粒子群算法
Sun等提出的QPSO算法,这是一种基于PSO和量子模型的新算法。在经典粒子群优化算法中,通过位置矢量Xi和Vi速度矢量来描述粒子飞行轨迹。但是在CPSO系统中,粒子的动力学行为是广泛发散形式,即不能同时确定Xi和Vi的精确值。由于粒子会因为速度的原因使得搜索空间限制在某个区域,于是QPSO算法采用波函数表示粒子的运动状态。量子粒子群算法的更新方程为:
(一)基本建设投资管理缺乏科学有效的分工决策机制。基本建设项目由投资主管部门进行立项、可行性研究、初步设计和概算审批,其主要考虑项目需求,往往忽略财政可承受能力评估,容易出现超越现有财力或者虽然确定了筹资渠道但是无法落实的情况,绑架财政不断扩大支出。同时,现行决策制度也缺乏硬约束,有的前期论证流于形式,“边设计、边报批、边施工”,时常出现“预算超概算,决算超预算”的情况。整个链条不同环节没有形成合力,不同的部门之间沟通不畅,影响科学决策。
(17)
(18)
(19)
式中:M为粒子种群数,φ1=rand(),φ2=1-φ1,u=rand();mbesti为迭代t次后所有粒子的最佳位置平均值,β为收缩-扩张系数,为了保证算法的收敛性,一般使用1.0~5.0线性下降策略[15]:
β=βmax-(βmax-βmin)t/tmax
(20)
3.3 GQPSO
QPSO是一种进化算法,在其全局搜索能力、相对快速的收敛性方面大大优于PSO[17],但是也存在缺陷,随着迭代次数的增加,QPSO的收敛性能将逐渐趋于缓慢,寻优能力会下降,并且可能在局部极小值中周旋。采用遗传算法里的交叉变异操作,可以改进量子粒子群算法里随着迭代次数增加而生成的新的个体过于单一的问题。在GQPSO算法中,个体不再只是根据群体里的最优位置信息交换群体知识,而是从具有较好适应度的个体随机选择需要学习的对象。GQPSO算法步骤如下:
1) 通过适应度函数计算粒子的适应度值,对群体的局部最佳gbesti和全局最佳zbest分别进行更新。
2) 对杂交池numpool进行初始化,利用公式seed1=floor(rand()×numpool)+1计算出需要进行杂交操作的粒子。
3) 计算杂交后产生的新粒子的适应度的值,若优于父代适应度的值,则用子代的位置替代父代的位置。
4) 初始化变异范围大小,计算出需要进行变异操作的粒子seed2=floor(rand()×mutationpool)+1。
5) 更新变异后的子代粒子的位置,计算适应度的值,若优于父代适应度的值,则代替父代位置。
6) 重复上述步骤1)至5),直到满足误差终止条件。
4 实验分析
为验证GQPSO-WNN算法的有效性,本文采用了PeMs(http://pems.dot.ca.gov/)能力度量系统上采集的2016年12月5号到7号美国加州快速路网I110-N号线圈检测的采样间隔为5 min的实时交通流量数据,共864条数据,将最后230条数据作为测试样本进行仿真实验。
由于采集到的数据可能存在噪声,所以首先对数据进行了降噪和归一化处理,根据C-C算法确定的时间延迟τ和嵌入维数m(参见图1)重构相空间,计算得到Lyapunov指数大于0(参见图2),证明该交通流序列具有混沌特性,设置小波神经网络各个参数,网络的输入层应该等于嵌入维数,故输入层为6,输出层为1,隐含层数7,随机初始化50个粒子。本文采用以下模型评价指标:

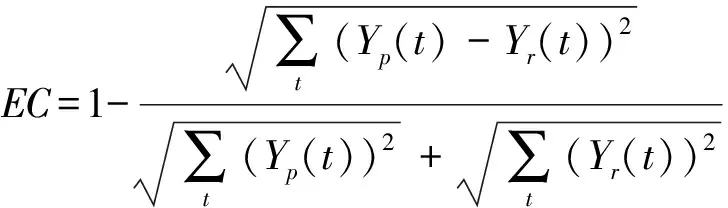
式中:Yp(t)是第t时的预测值,Yr(t)是第t时的实际值。图4-图8给出了WNN模型,PSO-WNN模型以及GQPSO-WNN模型对实际交通流的预测结果和误差对比图,同时分别比较了PSO-WNN模型和GQPSO-WNN模型的收敛性。

图4 WNN预测结果对比曲线和绝对误差
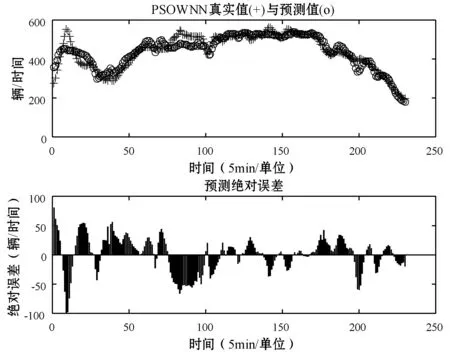
图5 PSO-WNN预测结果对比曲线和绝对误差
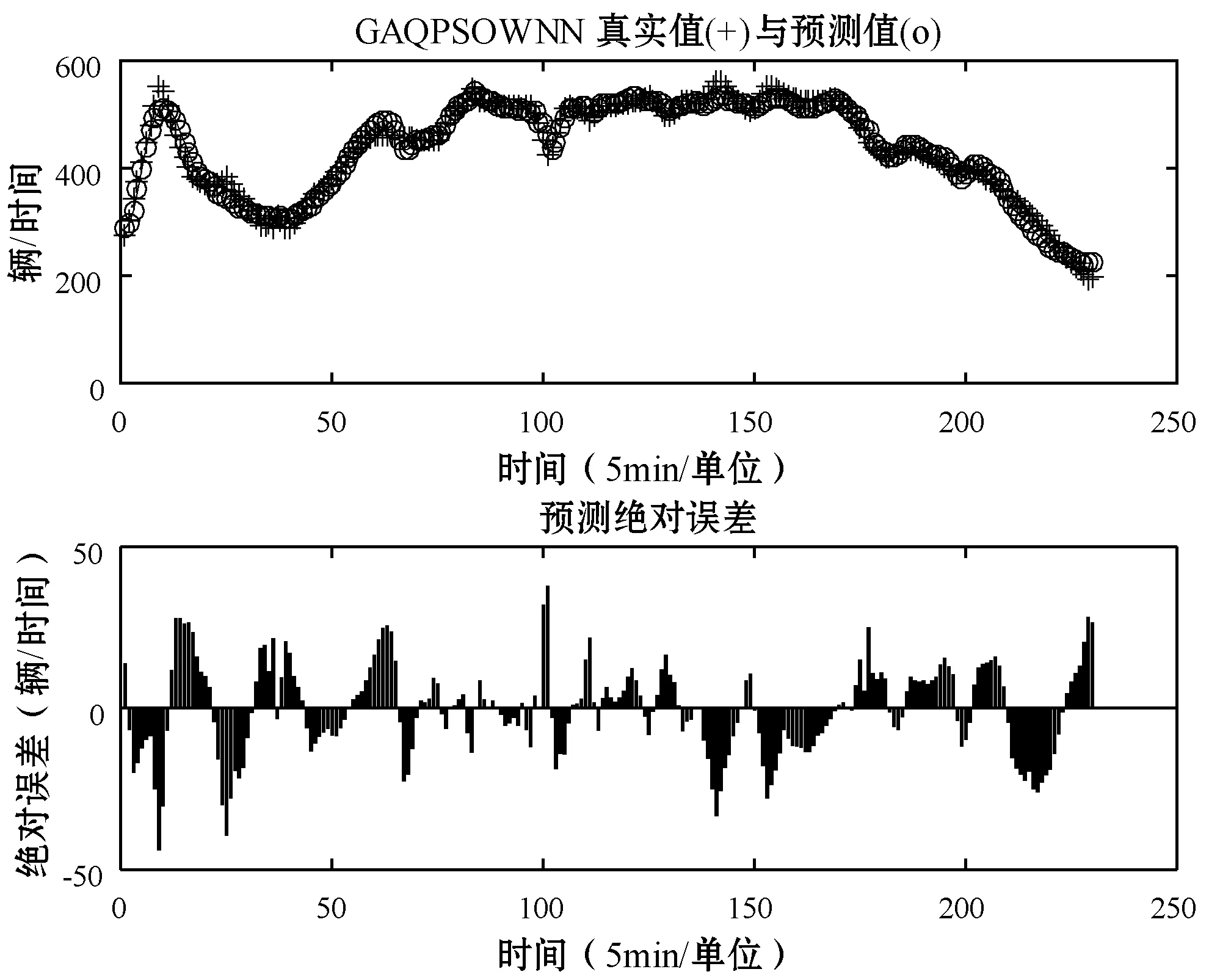
图6 GQPSO-WNN预测结果对比曲线和绝对误差

图7 PSO-WNN适应度值迭代曲线

图8 GQPSO-WNN适应度值迭代曲线
从图6和图8可以看出,GAQPSO-WNN算法模型预测结果曲线更加贴合真实交通流曲线,算法在迭代次数不超过10次时,适应度值就已经下降到0.2以下,迭代到接近20次时GAQPSO-WNN预测模型的曲线几乎收敛。由此可见,该算法相较于PSO-WNN算法收敛性较好,预测准确度也更高。
将预测模型多次试验取平均值得到结果如表1所示。综合对比BP、WNN和PSO-WNN等算法的评估指标结果,经过混合优化后的GQPSO-WNN短时交通流预测模型的均方误差比PSO-WNN模型低56%左右,拟合度也明显高于WNN模型和PSO-WNN模型。
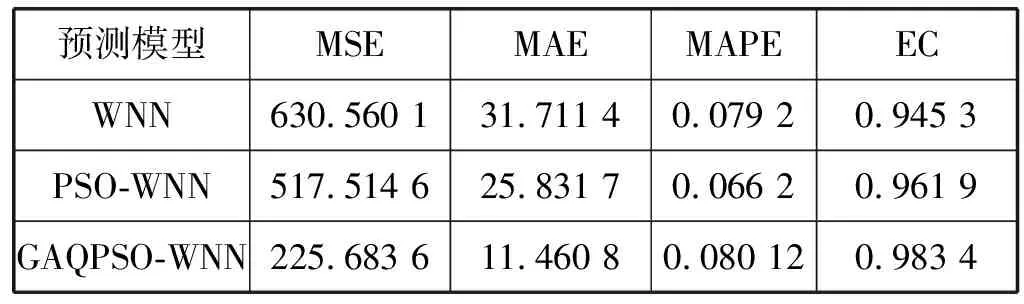
表1 各类模型交通预测性能对比
5 结 语
本文在建立预测模型之前,利用最大Lyapunov指数分析交通流的预测性质。在现有的短时交通流智能预测模型基础上,提出基于相空间的GQPSO-WNN的混合预测模型,该方法结合了GA和QPSO的优点,优化小波神经网络参数值选取。实验结果表明,与以往研究中的模型相比,所提模型的收敛速度和预测精确度均可以达到理想水平,有望应用于未来的实际交通领域中。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
计算机仿真(2022年8期)2022-09-28
广西大学学报(自然科学版)(2022年2期)2022-07-06
沈阳理工大学学报(2021年6期)2021-12-30
火力与指挥控制(2021年10期)2021-12-29
广东蚕业(2021年2期)2021-04-22
计算机系统应用(2019年6期)2019-07-23
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
现代电子技术(2009年15期)2009-09-30
