
数据挖掘技术在中职学校管理中的研究与应用
2019-07-16 03:14陈小年
电脑知识与技术 2019年15期
陈小年
摘要:中职学校教育管理工作涉及面广,会产生大量的数据。如何有效利用这些数据是一个十分有趣而又重要的课题。采用数据挖掘技术,在这些数据中进行挖掘,会得到一些有意义的信息,帮助中职学校的教书育人,完善自身管理建设,提升有效决策水平和能力。该文研究了一所中职学校的管理工作数据及其挖掘意义,并结合学生资助这项具体工作的数据进行实例挖掘,分析其挖掘结果,并在此基础上做进一步推广做简单分析。
关键词:数据挖掘;中职学校;管理
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)15-0010-03
Abstract: Educational administration in secondary vocational schools involves considerable data from comprehensive ways. How to effectively utilize these data is a topic of interest and importance. With data mining technology, significant information can be dig out from massive data, then benefit the teaching and studying in secondary vocational schools, and help to improve the management and administration of the schools and the efficiency of decision making. This paper is based on research of the data management and data mining in a secondary vocational school, takes financial aid for students as an example to mine the data therein, study the outcome, and makes a preliminary analysis on the possibility and feasibility of promotion.
Key words: Data Mining; Secondary Vocational Schools; management
1 数据挖掘概述
数据挖掘(Data Mining)是一项非常重要的数据透视技术,从存放在数据库、数据仓库或其他信息库中有噪声的、不完全的、模糊的大量随机表层数据分析提取出其背后隐含着的难以发现的、不为人知的有用信息,可能给人们的生产、生活、学习、研究带来意想不到的结果。数据挖掘涉及数据库和数据仓库技术、机器学习、高性能计算、统计学、模式识别、神经网络、图像与信号处理、数据可视化以及空间或时间数据分析,可谓信息技术中最有发展空间、潜力无限的交叉学科之一。
数据挖掘技术的发展主要有电子邮件阶段、信息发布阶段、电子商务阶段以及全程电子商务阶段等四个阶段。
数据挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法可以从不同的角度对数据进行挖掘。
1.1 数据挖掘的特點
数据挖掘技术主要有以下几个特点:
1)基于大量数据。小数据量当然也可以挖掘,而且很多数据挖掘的算法也能够运行在小数量上并得到结果。其实,过小的数据量人工分析就能总结出潜在的规律,而且小数据量对真实世界的特性也反映不出来。
2)隐含性。数据挖掘得到的结果不是数据表面上的,一眼能看出来的信息,而是深藏在数据内部及数据之间的信息。
3)价值性。数据挖掘得到的结果能够给挖掘者直接或间接地带来经济或社会效益。大量成功的挖掘案例证明,数据挖掘技术是提升效益的一大法宝。
4)新奇性。挖掘出来的知识是前所未知的,只有全新知识,才可以帮助挖掘者获得新的洞察力,否则只是对现有经验知识的一个验证。
2 中职学校管理工作数据
2.1 数据来源
中职学校日常管理工作中会产生大量的数据,主要包括:学生基本信息数据之姓名、性别、身份证号、家庭住址、联系电话;学生家庭数据的父母姓名、职业、年龄、收入水平、人口、兄弟姐妹人数、是否单亲、是否贫困、资助需求;学生校园生活数据之住宿房号、水电费、食堂消费;学生校园学习数据之在读专业、选修课程、成绩、出勤情况、对任课教师评价、实习、奖学金情况等;学生就业数据之实习公司、就业单位、岗位、行业、薪酬等;学生校园活动数据之校运会、文娱演出、社团、团组织活动、学生会团委任职。教师人事信息之基础人事数据、工资、出勤、科研、培训、考核等数据,学校教务活动中各种师资、课室、实验室、仪器等教学资源分配安排等数据,财务数据之项目资金、学费、住宿费、水电费、保险费、课本费等收支数据。
2.2 中职学校管理数据挖掘的意义
当前中职学校管理工作中产生的大量数据,存储在各种业务系统数据库中,为着某些管理工作服务,但是并没有得到充分利用。对这些大批量的数据,进行有效的挖掘,可以提取一些非常有用的信息,可以帮助指导学校制定、优化人才培养体系、招生计划、师资建设、完善后勤服务体系、为专业设置、课程建设、校园文化建设、人才培养等工作,具有重要的指导意义。
1)在学生资助工作中,分析受资助对象的生源地、修读专业类型、年龄、家庭结构、经济状况等数据,充分掌握受资助学生各种结构性关系,合理分配资助名额,协调开展资助工作。
2)在学校教学资源网站上,通过学生访问课程教学视频、微课的播放、下载、停顿等,分析学生学习的兴趣点、难点,促进教学改革,优化调整课程开设情况。
3)对师资数据进行挖掘分析,探索教师的性别、年龄、专业、职称、专长、奖励、科研、继续教育、进修提高、学生评教等情况,帮助合理引进师资、优化师资队伍。
4)在学校招生工作中,收集招生网站访问者注册登记、专业咨询、网上报名、实际缴费等数据情况,挖掘分析出学生对学校声誉、师资、校园、专业、学费、就业等情况的关注,有效调整招生宣传,突出重点,提高吸引力。分析往年招生录取情况,挖掘各出生源地招生情况、生源质量、家庭条件及资助情况,有利于招生工作力量的合理分配。
5)通过财务系统数据,及时发现学生拖欠学杂费用,及时控制各项目资金使用情况,加强对学校财务风险监控。
6)通过校园一卡通数据,分析出学生在校期间,在饭堂、商店消费情况,发现学生家庭经济收入水平与实际消费情况是否一致,发现学生对饭堂菜价、菜式的接受程度,有效提高后勤服务水平。
7)在学生日常校园管理工作中,分析学生出勤、出操、文体活动、社团活动、违纪记录等日常操行情况,对改进学生管理工作方法手段、优化调整第二课堂开设等问题提供重要信息。
8)通过图书馆图书借阅情况,来分析学生对专业课程的关注程度,对那些非专业知识的兴趣度,有利于图书馆优化图书采购计划,选择专题活动方向。
3 中职学校管理数据挖掘应用实例
3.1 确定挖掘对象
我们可以从学籍系统、资助系统、教学系统等业务系统中来提取学生学籍基础数据、校园生活、专业学习数据、校园活动数据、就业数据、设计一个挖掘系统,来挖掘数据之间的内在联系。本文案例在中职学校日常管理工作中的众多数据中,选择学生资助工作这个主题作为挖掘对象,希望从大量资助数据中挖掘出一些有用的信息,指导将来的学生资助工作。
3.2 数据准备
数据准备是数据挖掘成功与否的一项重要的基础工作,我们得到的数据往往可能具有不完整、含噪声和不一致等问题,这就需要对数据作预处理。
3.3 数据预处理
1)数据采集。数据可以来自现有的各种管理信息系统,比如学籍系统、教务系统、资助系统等,提取所需相关的最原始数据,并做一定的整合处理。
2)数据清洗。将数据库中重复的记录进行删除,只保留一条记录,避免重复。如学生退学了,该记录就要从学生表中删除。对于数据不准确不一致的,人工可以进行纠正清理,如班级名称不一致,电子商务1801班和电商1801其实是同一个班级,需要人工手动统一名称。
3)数据集成。数据可能来自多张表,需要通过一个关键字将多表连接成一张新表。例如在校学生都使用学号作为唯一身份标识,通过学号将学生的其他属性合并成一张表,包括学号、姓名、性别、身份证号码、是否困难家庭、银行卡账号等等信息。
4)数据转换。将数据集合转换成另一个描述形式,以便适合开展挖掘。在本实例中,对数据进行泛化处理,将生源地地市为汕头、汕尾、揭阳、潮州标记为粤东,将生源地为茂名、云浮、湛江、阳江标记为粤西,将清远、韶关、云浮、梅州、河源标记为粤北,将广州、佛山、珠海、中山、肇庆、江门、深圳、惠州等地标记为珠三角,将湖南、广西、江西等非广东籍生源标记为外省。
5)数据降维。数据基础属性繁多,只有一部分才是我们挖掘目的所关注的,其他无关的属性可以删除不用,这种相关性分析即为降维。降维的目的是通过降低挖掘对象规模来降低挖掘工作的复杂度,其前提要保证最终挖掘结果不受影响。比如,学生姓名、电话号码等属性对结果不会有任何影响,可以直接从表中剔除。
3.4 模型构建及挖掘
3.4.1 数据模型构建
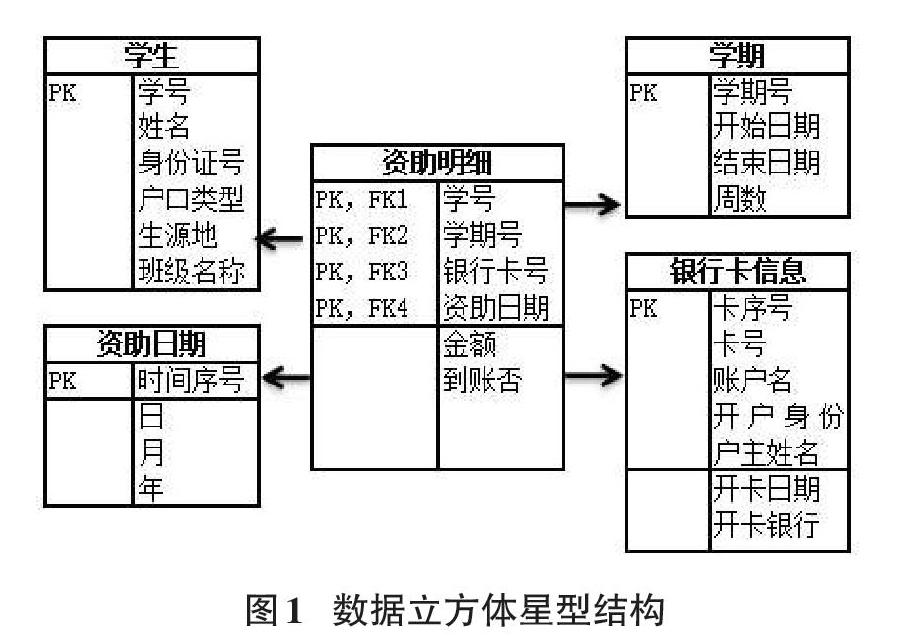
本实例采用星型模式来设计数据立方体,包括一个大的包含大量数据和冗余度极低的事实表,还有一系列小的维表,每维一个,存储各立方体的具体信息。本案例的学生资助明细表和各个维表的结构如图1所示。
3.4.2 关联规则挖掘
本实例采用Apriori算法来挖掘关联规则。该算法是一种关联规则的频繁项集挖掘算法,核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。本实例针对学生国家助学金管理数据进行挖掘,挖掘出来的关联规则可以有效地指导学校管理部门有针对性的开展贫困助学工作。
Apriori算法伪代码如下:
输入:数据立方体D[A1,A2,...,An];最小支持度阈值sup_min
输出:频繁项集L
Count_min=totalcount*sup_min;
L1=find_frequent_1-itemsets(D,count_min);
//通过OLAP引擎得到满足count_min的频繁一项集
For (k=2;Lk-1≠?;k++){
Ck=apriori_gen(Lk-1,); //Lk-1经自连接得到候选集Ck
For each I=(i1,i2,...,ik)∈Ck {
I.count=count_gen(I,D); //对每个候选集,通过OLAP引擎获取记数
If I.count >=count_min
Lk=Lk∪I;
}
}
Return L=UkLk
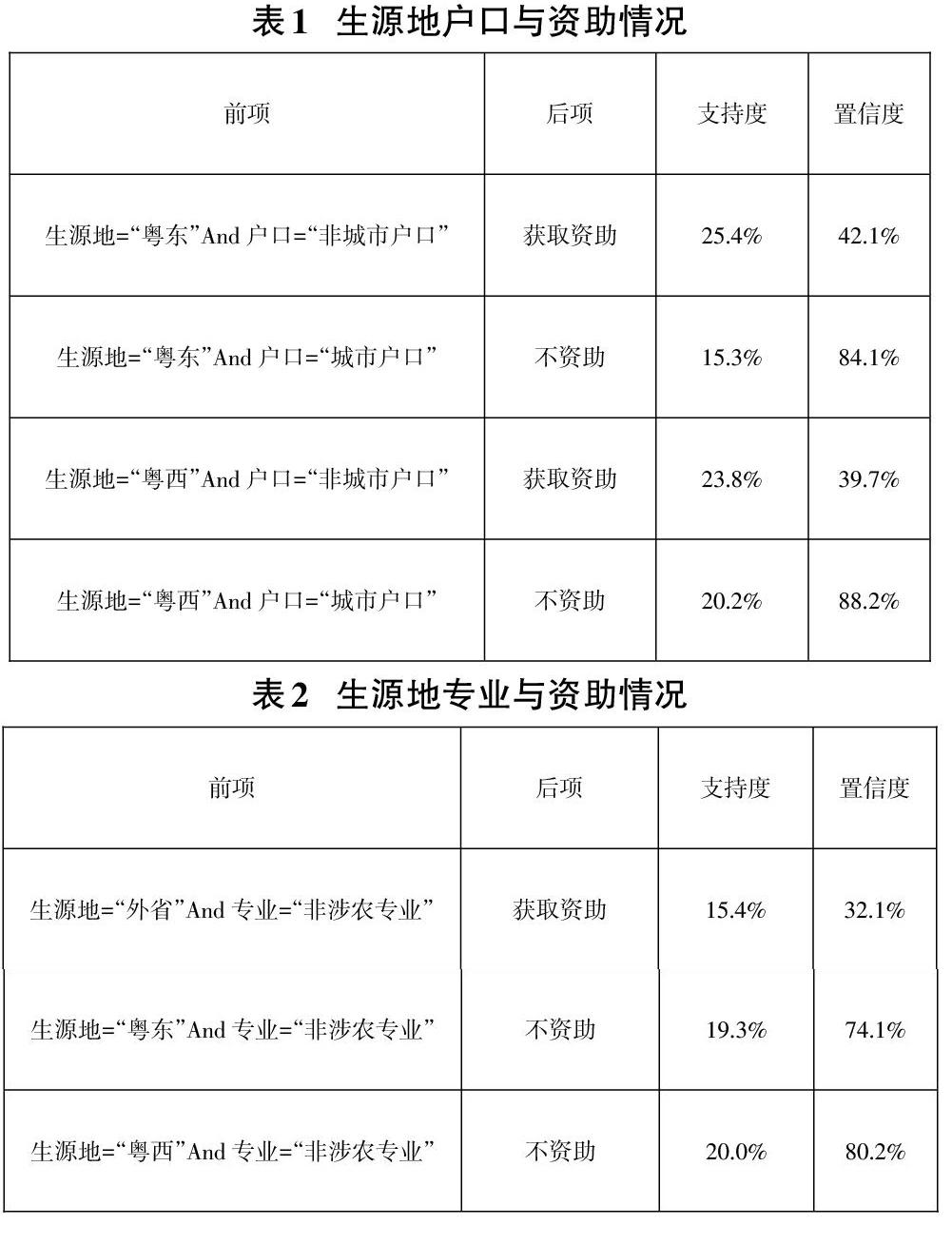
经过多次试验,尽量做到既保证不会产生大量无用规则,也不会漏掉重要规则,最终设置最小支持度为15%,最小置信度为30%,得到部分关联规则如表1和表2所示:
3.4.3 挖掘结果分析
由挖掘结果表1来看,生源地是粤东的学生,农村以及县镇非农的学生获得资助资格的数量很大。在很多人的印象中,粤东地区经济发展水平明显高于粤西,因此粤东地区困难家庭应该比粤西少。这跟大家的直观印象恰恰相反,一方面粤东地区经济收入较低的家庭依然很多,另一方面,笔者所在学校的粤东生源也多于粤西。因此,这给我们的资助工作带来了重要的情报,资助名额要适当地多考虑粤东生源。同时,也引导招生工作者在粤东招生宣传时要更多地突出国家助学金的利好政策,有助于在粤东招录更多的生源。
由表2来看,外省生源获得资助并非因为选择涉农专业,则说明家庭困难的很多;外省生源因读涉农专业而受资助没有出现在挖掘结果的强规则中,则是因为达不到15%的支持度,则说明外省生源对学校开设的涉农专业兴趣不大,在面向外省招生宣传时要注意多突出非涉农专业。同时,粤东粤西生源量大,能获国家助学金的并不多,对涉农专业兴趣不大。
4 结束语
存储着海量数据的数据仓库就是一座庞大的“信息金矿”,科学使用数据挖掘技术进行挖掘探索,可以获取得到更多有趣、有用的信息。在以我们中职教育为代表的教育管理工作中积累起来的数据矿藏中包含着各种丰富的数据,合理地挖掘开发出来,在学校工作中的招生、教学、科研、就业、日常管理、后勤服务等教书育人活动中都可以发挥出重要作用,有效提升管理水平和科学决策能力,这应该是一个值得我们继续努力的方向!
参考文献:
[1] 张晶. 数据挖掘技术在艺术院校计算机能力考核成绩分析中的应用研究[J]. 电脑知识与技术, 2017(7): 197-199.
[2] 郭琪瑶. 数据挖掘技术在职业学校德育管理中的应用[J]. 电脑知识与技术, 2010, 9(26): 7303-7305.
[3] 谢琦, 张振兴. 基于Apriori算法和OLAP的關联规则挖掘模型设计[J]. 计算机应用, 2007(6): 4-5
[4] 殷文俊. 数据挖掘在高职计算机一级考试成绩中的分析研究[J]. 福建电脑, 2017(1): 50-51.
【通联编辑:谢媛媛】
猜你喜欢
今日农业(2022年15期)2022-09-20
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
