
3D视频编码原理简介
2019-07-20 08:21刘恩亚崔军峰
数字通信世界 2019年6期
刘恩亚,崔军峰,南 楠
(国家无线电监测中心,北京 100037)
3D技术以其栩栩如生的真实感极大地丰富了大众的娱乐生活,但是为了达到自然真实的效果,需要巨大的数据存储与传输。自20世纪90年代开始,视频编码标准不断迭代升级,以适应日新月异的技术发展需求。结合文献调研,本文简单介绍了3D视频编码的基本原理。
1 图像与视频编码基本原理
视频是连续的图像序列[1-3],由连续的帧构成,一帧即为一幅图像。由于人眼的视觉暂留效应,当帧序列以一定的速率播放时,我们看到的就是动作连续的视频。由于连续的帧之间相似性极高,为便于储存传输,我们需要对原始的视频进行编码压缩,以去除空间、时间维度的冗余。
1.1 图像编码基本原理
视频编码是建立在图像编码的基础上,以JPEG(Joint Photographic Experts Group,联合图像专家小组)格式为例,图像编解码原理如图1所示[1]:
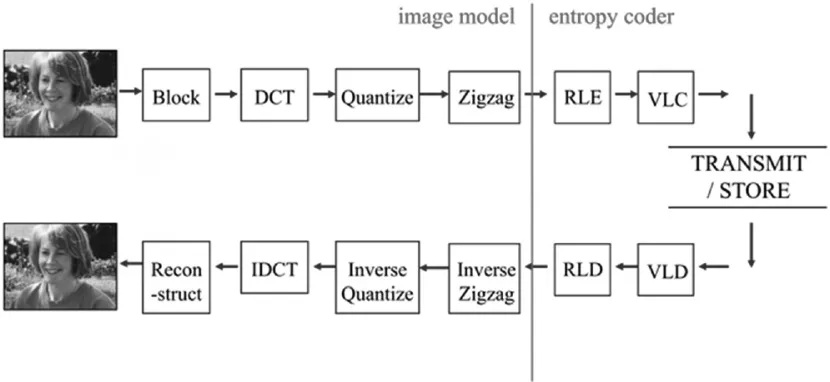
图1 图像编解码原理示意图
图像编码流程如下:
(1)首先将图像分块(Block),JPEG中通常为8*8像素。
(2)对分块进行DCT(Discrete Cosine Transform,离散余弦变换),将图像数据变换到空间频域。
(3)对变换后的空间频域矩阵进行量化(Quantize),通常需设定一个QP值(Quantization Parameter,量化参数)。把空间频域矩阵的每一个DCT系数除以QP值,再取整,从而DCT矩阵中较小的系数就被忽略掉了,以此达到压缩效果,如图2所示。
QP值是视频编码中的一个重要的参数,QP值越大,压缩后的文件越小,但是视觉上效果越差;QP值越小,则反之。
(4)经过量化后的矩阵含有大量0值,为进一步压缩,进行Zigzag扫描,如图3所示。
(5)将Zigzag扫描后得到的序列进行压缩编码(通常称作熵编码,Entropy Coding)。编码方法可采用RLE(Run-Level Encoding,游程编码)或VLC(Variable-Length Coding,变长编码)[1]。
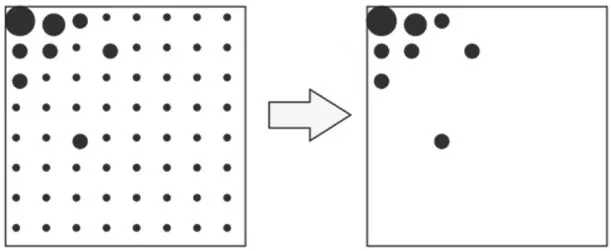
图2 DCT及量化示意图

图3 Zigzag扫描示意图
1.2 视频编码基本原理
视频编码时,要重点考虑消除帧与帧之间的冗余信息。相比于图像编码,视频编码增加了Motion Est.和Motion Comp.两个模块,如图4所示。Motion Esti.为运动估计(Motion Estimation),即计算两幅图像中变化的部分;Motion Comp.为运动补偿(Motion Compensation),即利用运动估计的结果和前一幅图像,计算得到新的图像。也即,运动估计去掉了时序上相邻的两幅图像中的冗余部分,仅保留其变化部分,以达到压缩的效果。
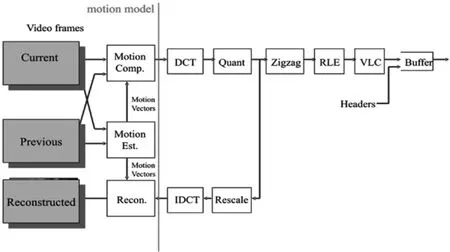
图4 视频编码原理示意图
视频解码过程如图5所示。
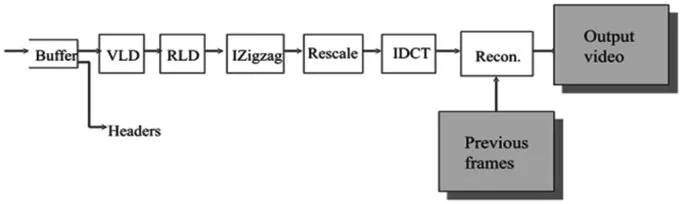
图5 视频解码原理示意图
2 视频编码标准简介
2.1 视频编码标准化进程
目前,主要有两家国际机构负责制定视频编码标准:国际电信联盟的视频编码专家组(ITU-T's Video Coding Experts Group)和国际标准化组织和国际电工委员会的动态图像专家组(ISO/IEC Moving Picture Experts Group,MPEG)。
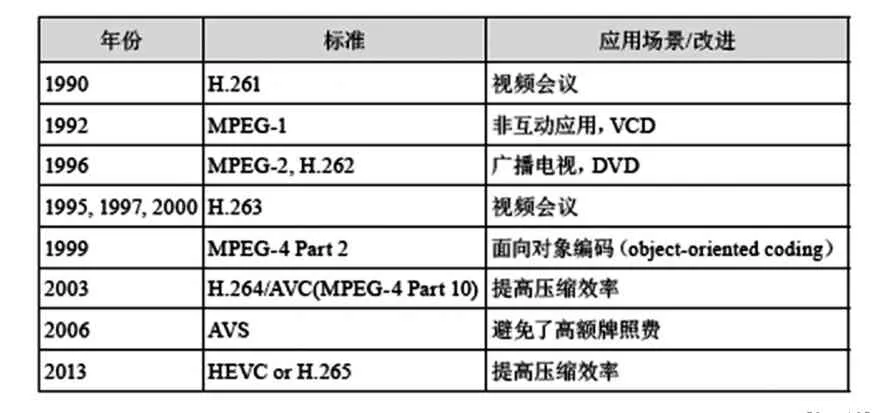
表1 视频编码标准演进情况表
简单回顾一下20世纪90年代以来的主流编码标准[9,12]。表1中,ITU-T的标准包括H.261、H.263、H.264,主要应用于实时视频通信领域,如视频会议;MPEG系列标准是由ISO/IEC制定的,主要应用于视频存储(DVD)、广播电视、互联网或无线网络的流媒体等。两个组织也共同制定了一些标准,H.262标准等同于MPEG-2的视频编码标准,而H.264标准则被纳入MPEG-4的第10部分。
表1中提到的各个标准在[8-12]中有着比较详尽的介绍,本文不再展开,值得一提的是AVS和HEVC这两种较新的编码标准。AVS的全称是The Audio Video Standard of China,即中国音视频编码[10],与其他标准相比,AVS可以在显著降低复杂度的同时提供近乎最优的性能。2006年,AVS作为中国国家标准正式发布[11]。HEVC全称是High Efficiency Video coding,即高效视频编码[13]。2013年1月26日,HEVC正式被批准称为国际标准,ISO/IEC将其纳入MPEG-H Part 2,而ITU-T则将其纳入H.265。HEVC主要针对高清、超高清视频,比起H.264/AVC而言,可以提高50%的编码效率,其代价是算法复杂度的升高。
2.2 H.264/AVC标准
H.264编码标准最初发表于2003年,是ITU-T和ISO/IEC两家机构的联合产品[3,4]。H.264是ITU-T沿用的标准名,而ISO/IEC则将其命名为MPEG-4 Part 10/AVC,AVC是高级视频编码(Advanced Video Coding)的首字母。H.264编解码大致流程如图6所示[3],分为三个步骤:预测(Prediction)、变换(Transform)和编码(Encode),解码则反之。
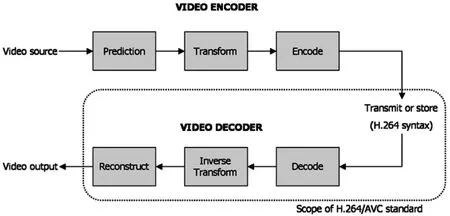
图6 H.264/AVC编解码原理示意图

图7 I,P,B帧示意图
在H.264编码的视频序列中,共分I,P,B三类帧(图7):I帧,即Intra Frame,是独立编解码的帧,不需要其他的帧作为参考。视频序列的第一帧一定是I帧,I帧通常包含较多的比特数。P帧,即Predictive Inter Frame,它以之前的I或P帧作为参考帧来进行编码。P帧通常比I帧包含更少的比特数,比I帧更易受到传输错误的干扰。B帧,即Bi-predictive Inter Frame,它的压缩编码不但需要参考之前的I或P帧,还需要参考之后的I或P帧。
诸如“IBBPBBPBB”这样的结构被称作一个GOP(Group of Pictures)。
2.2.1 预测模块(Prediction)
编码器在处理一帧图像时是基于宏块(Macroblock)进行的,一个宏块是16*16个像素点。每个宏块的预测都是参考之前已编码的宏块。根据已编码的宏块的来源不同,预测编码可以分为两类:一类是帧内预测编码(Intra Prediction),即以同一帧内的已编码的宏块作为参考;另一类是帧间预测编码(Inter Prediction),即以之前已被编码并且已被发送的帧的相关宏块作为参考。编码器将预测得到的数据从当前宏块中去掉,于是便得到剩余数据(residual)。
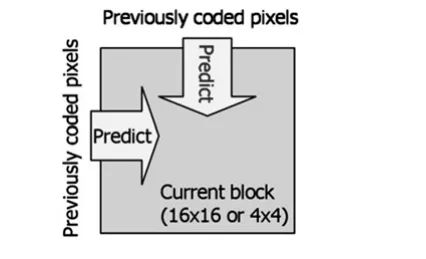
图8 帧内预测编码
帧内预测编码如图8所示,相对之前的编码标准来说,H.264的块大小较为灵活(可为16×16或者4×4个像素点),这也使得其在预测精度和编码效率上得到很大提高。
帧间预测编码需要考察连续帧之间的差异来进行压缩[4]。如图9所示,连续的三帧描述了一个人跑向房屋的场景。在三幅图像中,房屋不变,故在后两帧中可以视为冗余数据。针对这种情况,可采用差分编码(difference coding)的方法来进行压缩,即只编码那些相对于参考帧有变化的像素点。仅通过差分编码来进行帧间预测编码不足以较好地压缩图像中运动的部分,这时要采用运动补偿(motion compensation),运动补偿的基本思想是:当前帧中的图像数据大体上都可从之前已编码的帧中找到,只不过是位置不同而已,如果将其位置的变化找到并储存,即可预测得到当前帧,详见[4]。
2.2.2 变换及量化(Transform and Quantization)
在预测部分提到,编码器将预测得到的块的数据从当前的块中去掉,从而获得剩余数据(residual),继而对每一块剩余数据进行4×4或者8×8的整数变换(integer transform,整数变换是DCT变换的近似形式),随后再对变换后得到的系数进行量化,具体过程已在前文介绍。
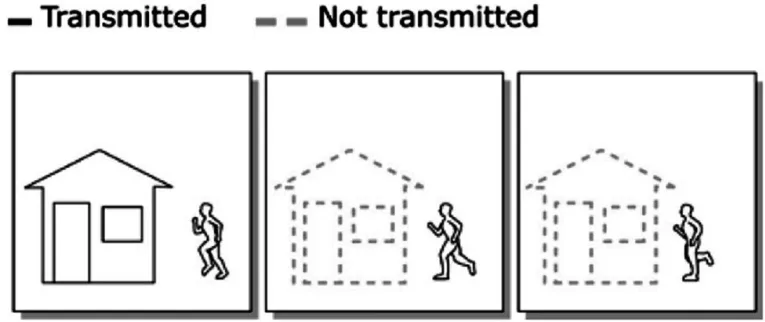
图9 Inter预测编码应用场景
2.2.3 比特流编码(Bitstream Encoding)
经过前述步骤后,我们得到了若干待压缩为比特流的数据。这些数据分别是:量化后的变换系数、解码器预测重建数据的有关信息、压缩数据的结构信息和编码时使用的压缩工具的信息、关于整个视频序列的有关信息。利用变长编码(Variable Length Coding,VLC)或算数编码(Arithmetic Coding),将上述提到的数据、参数(语法元素,syntax elements)转换为二进制码,即为比特流编码。经比特流编码后的二进制序列可用于传输或储存。本小节简单介绍了H.264/AVC的编码原理,详细的算法介绍可以参考[5-7]。
3 3D视频编码原理简介
如何在有限带宽前提下,成功展示满意的3D效果是摆在研究人员面前的一项艰巨任务。不同的3D显示技术需要用到不同的3D数据格式,也即需要采用不同的3D编码方法。但是,各种方法的目的是相同的,即有效地去除待编码视频之间的时间、空间冗余。基于之前介绍的H.264/AVC,文献[14-21]中提出的3D视频编码方法大致可以分为两类:一类是基于多视角(multi-view)的编码方法;另一类是基于视频加深度(video plus depth)的编码方法。
3.1 多视角3D视频编码方法
3.1.1 传统立体视频编码(CSV)
传统立体视频编码(Conventional Stereo Video Coding,CSV)是最经典的3D视频编码方式[14]。两台摄像机参考人眼的距离放置,同时拍摄同一场景。在压缩编码时,某一路视角的视频可以参考另一路视角来进行编码,提高压缩效率。采用CSV时,两路视角的视频分为基础层(base layer)和增强层(enhancement layer)。基础层完全当做独立的二维视频来进行编码,而增强层则在编码时需要以基础层作为参考。3D视频编码通常将左视作为基础层,右视作为增强层;左视具有后向兼容性,可以作为二维视频在常规显示设备上播放。CSV方法的缺陷在于其只能保证在拍摄视角观看视频时会有3D效果,而其他视角则不能。

图10 CSV编码方法视频结构示意
3.1.2 多视角视频编码(MVC)
多视角视频编码(Multi-view Video Coding,MVC)是CSV的升级版,即多个摄像机同时拍摄同一场景。这样,在观看时可以从多个位置看到立体效果。在编码压缩多视角视频信号时,可采用视差补偿(disparity compensation)来去除视角间的冗余(Inter-view Redundancy)[14]。基于H.264/AVC的“分层B帧(hierarchical B-pictures)”结构如图12所示。MVC方法也存在两个缺陷,一是其计算复杂度高,尤其不适合移动设备;二是虽然较CSV而言,MVC可以给观众更多的观看视角,但是这些视角在录制视频之初就固定了,缺乏一定的灵活性。
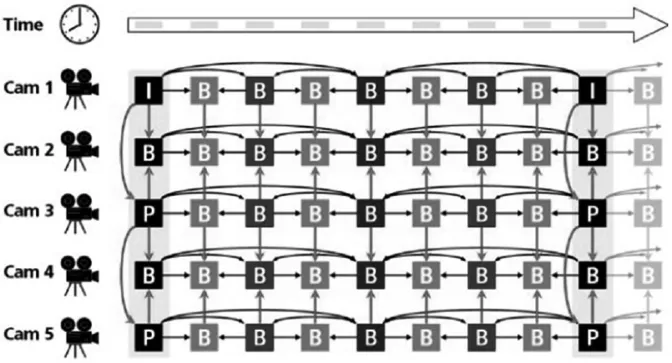
图11 MVC编码方法视频结构示意
3.1.3 双视抑制理论(BST)
L. Stelmach等学者于2000年提出了利用“双视抑制理论(Binocular Suppression Theory,BST)”来进行3D视频编码[15,22]。BST的理论指出:观众的主观测评结果是由高质量的视频(左视)决定的。在编码时可将右视的分辨率下采样至原始大小的二分之一或四分之一,如图13所示。BST在学术研究上是一个有意义的尝试,但其商业化应用较为有限。
3.2 视频加深度编码方法
3.2.1 视频加深度编码(V+D)
视频加深度编码方法(Coding of Video Plus Depth,V+D)是在欧洲信息社会技术(The European Information Society Technologies,IST)发起的“先进3D电视系统技术(Advanced Three-Dimensional Television System Technologies,ATTEST)”项目中提出的。V+D编码中3D图像表达为:单视角图像(monoscopic color video),外加一个深度信息(per-pixel depth information),如图13所示:

图12 BST编码方法视频结构示意 图13 V+D编码方法视频结构示意
单视角图像即为普通2D视频,深度图的每一个像素点与单视角图像的像素点一一对应,用8比特的灰度值(gray value)来代表原图像该像素的深度信息。灰度值为0表示“最远/深端”,灰度值为255则表示“最近/浅端”。可通过两种方法获取深度图[17]:一种方法是利用特殊设备,如“测距”相机(time of flight cameras);另一种是利用算法估计得到,如分析同一场景中同一物品的位移或差异(displacement or disparity)。在接收端,利用DIBR算法(Depth-Image-Based-Rendering Technique)可以从V+D格式的数据中恢复出适合人眼观看的3D视频效果。
V+D编码方式有两个显著的特点:一是它可实现非常高的压缩效率,由于深度信息为单色图像,所以在使用V+D方法压缩视频后会比压缩两路彩色视频节省资源;二是它具有“互动性”,接收端的3D效果展示是通过数学手段计算而得,故可将深度信息设置为与亮度、对比度类似的可调参数,通过调节深度来达到个性化的3D观看效果。V+D编码方式的也存在较为明显的缺陷,即图像中前景对后景的遮挡:如在图13中,我们无法获得被人脸遮挡部分的深度信息,如果观看者调整了观看角度,则DIBR算法无法算出被遮挡部分的深度,导致观看3D视频的主观体验下降。
3.2.2 多视角视频加深度编码(MVD)
MVD是Multi-view Video Plus Depth的缩写,它是V+D编码方法的扩展[14]。MVD需录制多视角的原始视频和深度信息(见图14)。MVD相比MVC来说更节省资源,但是随着视角数的增多,MVD会产生大量的数据。

图14 MVD编码方法视频结构示意
3.2.3 分层深度编码(LDV)
LDV是Layered Depth Video的缩写,LDV编码是针对V+D的不足而提出的[14]。LDV将原始视频中的前后景区分出来,分别进行V+D编码,以克服单纯使用V+D的不足,如图15所示。

图15 LDV编码方法视频结构示意
3.2.4 MVC与MVD的比较
MVC与MVD相比,其优势在于不需要额外的深度感知设备,当前的3D电影基本都是参考MVC标准制作的;而MVD相比MVC而言,在某些场景中会更节省资源,具体分析见[15]。诚然MVD有自己的优势,但是由于MVD方法与工业界的惯例做法没有传承关系,而且需要有特殊的深度感知设备,所以工业界一直没有采用并且推广MVD。[15]中也指出,未来市场中通用的3D编码方式将会是MVC。
4 结束语
结合文献调研,本文简要介绍了图像和视频压缩编码的基本原理,进一步介绍了3D视频编码基本原理和多种编码方法。随着5G时代的到来,从原理上了解3D视频编码方法,将对3D视频数据在通信(尤其是无线通信)网络中传输建模及分析应用大有裨益。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
