
基于国产FPGA的高速总线驱动设计及验证
2019-07-22 00:58魏志瑾
舰船电子对抗 2019年3期
魏志瑾
(中国电子科技集团公司第二十研究所,陕西 西安 710068)
0 引 言
在我国国防科技工业发展过程中,成熟的国防工业产品其核心处理器件多为国外现场可编程门阵列(FPGA)及数字信号处理(DSP)等芯片,但近年来,亚太安全形势急剧变化,“中兴事件”、“华为事件”、“中美贸易战”等事件的发生,提醒着我们必须掌握核心科技技术才能做到自主可控,不受制于人。因此,发展武器装备国产化与性能提升势在必行。随着国产芯片的设计水平提高,国产FPGA的系列和性能在逐步增加和提升,也开始大量应用到自主可控模块和设备中。
结合自主可控信号处理模块研制需求,将国产K7和V5系列的FPGA芯片应用到模块中,作为信号处理及数据传输的核心芯片。为保证数据稳定传输且有较高传输速率,高速总线协议采用Aurora总线协议。Aurora总线协议是一种可裁剪、轻量级、链路层点对点的串行传输通信协议,与SRIO、PCIE等总线相比,Aurora总线特征明显:用于解决FPGA之间的数据传输,支持通道绑定,带宽利用率高,传输速率灵活可配,目前可支持500 Mbps~13.1 Gbps[1]。其物理层采用差分信号进行数据传输,抗干扰能力强;链路层主要根据用户自定义协议,形成符合Aurora包格式的数据,完成打包、组帧以及8B/10B编/解码功能[2]。
1 Aurora总线驱动设计
Aurora总线协议适用于多个FPGA间点对点通信,支持全双工及单工2种通信架构,以及帧模式和流模式2种数据通信方式。一个Aurora 8B/10B的传输链路可包含一个或多个通道,以组合方式(X2、X4)支持更高的传输速度[3]。Aurora协议的IP核主要是基于GTX传输器作为物理层,根据Aurora协议实现链路层功能,并以AXI4协议接口与发送端和接收端实现用户数据交互,架构图[4]如图1所示。
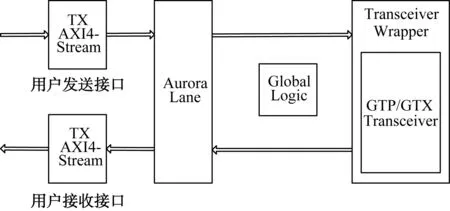
图1 Aurora IP核架构
根据信号处理模块的研制需求,调用Aurora协议IP核,在国产K7系列FPGA的GTX接口上采用X4全双工模式,用流模式传输数据,传输位宽为32 bit,Aurora驱动模块与应用层之间通过先进先出(FIFO)进行数据交互[5],交互关系如图2所示。其中接收FIFO设计为写位宽64 bit,深度32,读位宽64 bit(位宽深度可根据调试情况实时调整)。当本地复位有效或channel_up未拉高时复位FIFO;当Aurora接收端m_axi_rx_tvalid有效时,Aurora将数据m_axi_rx_tdata存入RX FIFO;当FIFO中rd_data_count为设定的某值时,开始从FIFO中读出数据。发送FIFO设计为写位宽64 bit,深度32,读位宽64 bit。当Aurora发送端s_axi_tx_tready信号有效时,s_axi_tx_tvalid拉高,开始往FIFO中写入数据s_axi_tx_tdata,并注意将s_axi_tx_tvalid和s_axi_tx_tdata对齐发出。
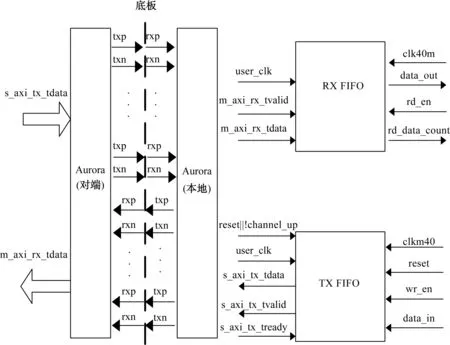
图2 X4流模式Aurora驱动交互关系图
在国产V5系列FPGA的GTX接口上采用X1全双工模式,用帧模式传输数据,传输位宽为32 bit,传输速率为3.125 Gbps,Aurora驱动模块与应用层之间通过双口随机存储器(RAM)进行数据交互,交互关系如图3所示。发送RAM可设计为位宽64 bit、深度32大小的双口RAM,将要发送的数据先写入双口RAM中,再将RAM中的数搬移到发送FIFO中,发送FIFO工作流程同流模式;当s_axi_tx_tvalid信号有效时,RAM地址开始累加,当s_axi_tx_tlast信号有效时,RAM地址清零。接收RAM大小同发送RAM,当m_axi_rx_tvalid信号有效时,RAM地址开始累加,当m_axi_rx_tlast信号有效时,RAM地址清零。
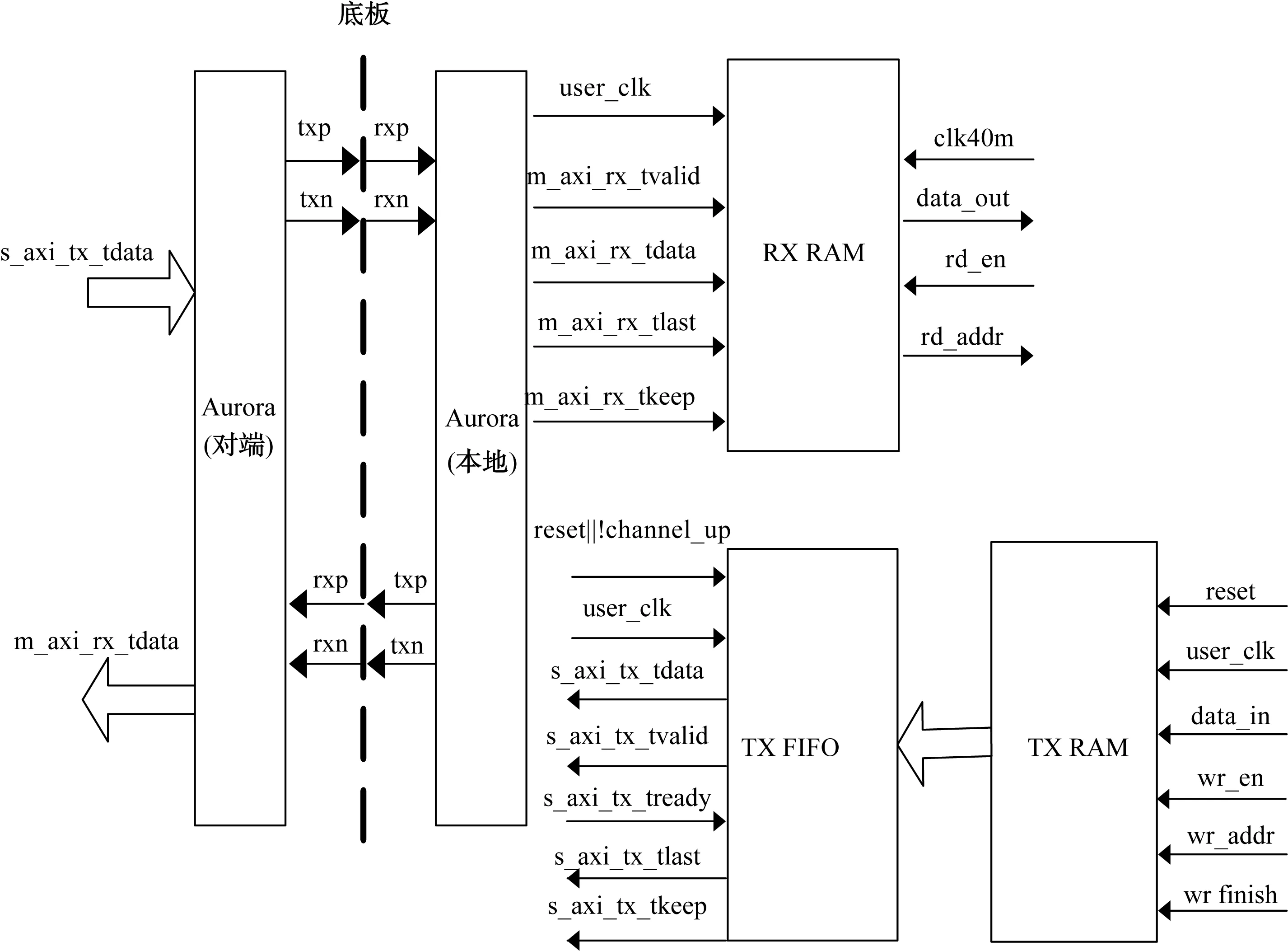
图3 X1帧模式Aurora驱动交互关系图
2 国产FPGA约束及优化处理
近年来虽然国产FPGA芯片设计水平和芯片性能都在不断提升,但由于国产芯片多为逆向设计,生产加工工艺与国外仍有差距,所以同一系列不同批次产品的性能也有一定差异,这些差异可能会带来门电路延时增大、高速口传输稳定性差等问题,如高速总线复位逻辑与时钟逻辑在布局布线中距离过远时,总线延时不可控,将导致传输误码率增加,传输速率降低,甚至链路无法正常建立[6]。针对某国产FPGA类似问题,在ISE软件Floorplan Area/IO/Logic中,使用Draw Pblock工具在靠近FPGA高速口引脚处圈定高速总线协议逻辑范围,形成物理上的约束,使得所有的逻辑电路物理上都在较近的范围内,可以有效减少延时,增加国产芯片的传输稳定性。在本次Aurora驱动设计时使用了这种约束方法,将Aurora相关的驱动逻辑以及用户逻辑约束在如图4、图5所示的范围内,解决了链路无法建立、延时不可控等问题。

图4 Aurora链路1高速口逻辑约束图

图5 Aurora链路2高速口逻辑约束
在调试时还需要注意调整预加重、摆幅等参数,以达到链路速率要求。某国产FPGA在调用Aurora IP核时,需要将Aurora_8b10b IP目录里的aurora_8b10b_0_gt.v第350行:.PMA_RSV2 (16'h2050)参数修改为.PMA_RSV2 (16′h2070)。修改完参数后,需要重新综合。最后打开Synthesized design,在Tcl console运行下述命令,可查看参数PMA_RSV是否修改成功:get_property PMA_RSV2 [lindex [get_cells -hierarchical -regexp -filter { PRIMITIVE_TYPE==IO.GT.GTXE2_CHANNEL } ] 0]。
3 国产FPGA Aurora驱动验证
测试验证系统主要由自主可控信号处理模块、测试底板、直流稳压电源、JTAG调试器以及测试计算机组成,测试连接图如图6所示。测试底板上也有对应的国产K7系列、V5系列FPGA,通过连接器可以与信号处理模块进行国产FPGA间高速口数据收发测试。

图6 测试系统连接关系图
针对X4流模式Aurora驱动,本地FPGA通过Aurora驱动发送变化的数据给测试底板上对端FPGA,测试底板将收到的数据再回传给本地FPGA,从FPGA接收到的数据来判断收发数据的一致性,图7所示为本地FPGA接收到的数据,与发送数据对比,没有误码,结果一致。
针对1X帧模式Aurora驱动,本地FPGA利用task产生一包帧格式数据,并设计2个RAM分别发送不同格式数据,利用DSP将帧数据前后各加上RAM_Sel及发送完成标识,组成一包数据通过Aurora驱动发送给对端FPGA,对端检测到发送完成标识后开始接收数据,并通过判断RAM_Sel以及帧头进行数据解析,从对端FPGA解析后的数据来判断是否与发送数据一致,如图8所示为对端FPGA接收到的数据,与发送数据对比,没有误码,结果一致。

图7 X4流模式Aurora接收数据

图8 X1帧模式Aurora接收数据
4 结束语
本文基于国产K7系列、V5系列FPGA完成了高速总线Aurora驱动的设计和验证。在设计及调试过程中根据国产FPGA的实际情况,通过对FPGA高速口逻辑约束及时序优化解决了高速口延时不可控、Aurora链路无法建立等问题,并利用自主可控信号处理模块与测试底板进行FPGA高速数据收发测试,通过对比收发数据的一致性,验证了驱动设计方案的可行性,对提高国产FPGA传输速率、稳定性具有促进意义,也对其他应用国产FPGA的国防工业产品提供了应用参考。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
包装工程(2022年9期)2022-05-13
移动通信(2021年5期)2021-10-25
科学家(2021年24期)2021-04-25
科技创新导报(2016年27期)2017-03-14
微型计算机(2009年12期)2009-12-21
现代电子技术(2009年14期)2009-09-05
