
基于双特征和松弛边界的随机森林进行异常点检测
2019-08-01 01:54胡淼王开军
计算机应用 2019年4期
关键词:随机森林
胡淼 王开军


摘 要:针对现有基于随机森林的异常检测算法性能不高的问题,提出一种结合双特征和松弛边界的随机森林算法用于异常点检测。首先,在只使用正常类数据构建随机森林的分类决策树过程中,在二叉决策树的每个节点里记录两个特征的取值范围(每个特征对应一个值域),以此双特征值域作为异常点判断的依据。然后,在进行异常检测时,当某样本不满足决策树节点中的双特征值域时,该样本被标记为候选异常类;否则,该样本进入决策树的下层树节点继续作特征值域的比较,若无下层节点则被标记为候选正常类。最后,由随机森林算法中的判别机制决定该样本的类别。在5个UCI数据集上进行的异常点检测实验结果表明,所提方法比现有的异常检测随机森林算法性能更好,其综合性能与孤立森林(iForest)和一类支持向量机(OCSVM)方法相当或更好,且稳定于较高水平。
关键词:异常点检测;随机森林;双特征过滤;松弛边界
中图分类号:TP311
文献标志码:A
文章编号:1001-9081(2019)04-0956-07
Abstract: Aiming at the low performance of existing anomaly detection algorithms based on random forest, a random forest algorithm combining double features and relaxation boundary was proposed for anomaly detection. Firstly, in the process of constructing binary decision tree of random forest with normal class data only, the range of two features (each feature had a corresponding eigenvalue range) were recorded in each node of the binary decision tree, and the double-feature eigenvalue ranges were used as the basis for abnormal point judgment. Secondly, during the anomaly detection, if a sample did not satisfy the double-feature eigenvalue range in the decision tree node, the sample would be marked as a candidate exception class; otherwise, the sample would enter the lower nodes of the decision tree and continue the comparision with the corresponding double-feature eigenvalue range. The sample would be marked as candidate normal class if there were no lower nodes. Finally, the discriminative mechanism in random forest algorithm was used to distinguish the class of the samples. Experimented results on five UCI datasets show that the proposed method has better performance than the existing random forest algorithms for anomaly detection, and its comprehensive performance is equivalent to or better than isolation Forest (iForest) and One-Class SVM (OCSVM), and stable at a high level.
Key words: anomaly detection; Random Forest (RF); double-feature filtering; relaxation boundary
0 引言
異常点检测问题是许多相关领域的研究热点。Hawkins的定义[1]揭示了异常点的本质:“异常点的表现与其他点如此不同,不禁让人怀疑它是由不同机制产生的”。在数据挖掘的工作中开展异常检测,其任务是发现与常规数据模式显著不同的数据模式,亦可将异常检测认为是一种对新模式的发现。目前,异常点检测已经在信用卡欺诈、电子商务中的犯罪行为探测、 网络入侵检测分析等领域得到了广泛应用。
专家学者针对异常点检测问题提出了一系列方法[2]:文献[3]提出一类支持向量机(One-Class SVM, OCSVM)机器学习算法用于异常点检测,用正常类数据训练OCSVM,然后用训练好的模型对输入数据分类从而检测异常值;文献[4-5]介绍基于统计学习理论的OCSVM在网络入侵检测和财务异常检测中的应用;文献[6-7]介绍了基于深度学习技术的异常点检测方法。近年来基于集成学习方法的异常点检测是一个研究热点。文献[8]提出孤立森林(isolation Forest, iForest)算法,依据随机选择训练集D中的一个特征q及其最大值和最小值之间值p,将D中在q特征上比p大的样本分至右子节点,比p小的样本分至左子节点;递归该步骤直至节点中只包含一个样本或多个相同样本时停止分裂,完成孤立树(isolation Tree, iTree)的构建;然后根据根节点到叶子节点的路径长度建立异常指数,当该指数值趋于1时,该叶节点的样本很可能是异常样本。
文献[9]基于iTree[8]提出一种改进算法EGITree(Entropy-based Greedy Isolation Tree),该算法通过启发式搜索检测出k个异常度较高的数据点。文献[10]提出一种基于随机森林的异常点检测方法,随机森林训练时,得到所有样本的异常点尺度,如果某一个样本的异常点尺度比较大,则说明这个样本与其他样本的相似程度较小,很有可能是异常样本,把异常点尺度超过某个阈值的样本当作异常点。文献[11]提出基于随机森林的异常点检测算法RFV(Random Forest based on Votes for anomaly detection)和RFP(Random Forest based on Proximity matrix for anomaly detection)。
RFV通过对正常类别数据构建随机森林模型,得到每一个正常类的投票均值,分类时通过样本的投票数是否达到正常类的投票均值,来判断样本是否为异常点。
RFP训练随机森林时,得到样本的相似度矩阵,然后计算得到每个类的类内相似度,作为阈值;分类时,计算新样本与每个类的相似度,若小于各类的阈值,则认为是异常点。
对于算法RFV,当树节点中最优切分点值大于或小于所有异常样本对应特征值时,致使异常样本点全部落入同一叶子节点中,其投票后的分类结果偏向于某一正常类,异常点检测易失败。
文献[10]方法和RFP算法[11]均采用样本的相似度矩阵计算相似度,这种计算相似度的方式只考虑样本落在一棵树同一叶子节点的情况,对落入不同叶子节点的样本间的相似度都统一视为0,故不能全面而完整地度量样本之间的相似度[12]。这些不足,降低了RFV和RFP算法在异常检测方面的性能。
文献[13]中提出一种结合模糊方法的随机森林进行异常点检测方法(Random Forest algorithm based on Fuzzy Tree node for anomaly detection, FuzzyTRF),利用关键特征在树节点中构造模糊值域进行异常点判断。FuzzyTRF方法中设计的模糊隶属度函数对异常检测的成败至关重要,而面对复杂应用时,设计出最优的模糊隶属度函数较为困难。
为了进一步提高基于决策树的随机森林方法在异常检测方面的性能,本文将双关键特征过滤方法引入到随机森林的决策树模型中,提出结合双特征和松弛边界的异常点检测(Double Features and Relaxation Boundary for anomaly detection, DFRB)算法。DFRB算法使用正常类样本构建随机森林模型过程中,在决策树节点中设计两个关键特征的值域用于过滤样本,异常点检测阶段利用构建好的双特征值域过滤出异常点。本文算法还可以避免距离度量和相似度矩阵的计算问题。
1 相关工作
本章主要介绍分类与回归树(Classification And Regression Tree, CART)算法[14-15]、Bagging分类器[16],以及随机森林算法[17]。
CART[14]由特征选择、树的生成以及剪枝组成,既可用于分类也可用于回归,具体实现可参见文献[15]。
Bagging算法[16]是一种通过操作训练样本集来生成互异的子分類器的算法,其基础是自助抽样法(bootstrap sampling),给定包含m个样本的数据集D,进行有放回的采样m次,得到含有m个样本的集合Di(i=1,2,…,m),使用Di构建基分类器,Di不完全包含D中样本,从而保证了训练集的差异性。
随机森林(Random Forest, RF)[17]是Bagging的一个扩展变体,RF是以决策树为基分类器构建在Bagging基础上,进一步在决策树构建过程中引入随机特征选择。
算法1 Random Forest算法。
随机森林算法原理简单、容易实现、计算开销小,它在很多现实任务中展现出强大的性能,被誉为“代表集成学习技术水平的方法”, 可看出RF对Bagging只是作了小改动,但是与Bagging中的基分类器的“多样性”仅通过样本扰动是不同的,RF中的基分类器的多样性不仅来自样本扰动,还来自特征的扰动,这使得最终集成的泛化性能可通过个体分类器之间差异度的增加而进一步提升[18]。
2 结合双特征和松弛边界的异常点检测
2.1 DFRB算法原理
随机森林算法中的决策树具有计算简单,既可处理离散数据也可处理连续型数据的优点;而且不需要计算样本相似度,可避免高维样本的维数灾难问题,且算法不易过拟合[17]。
同时,鉴于异常点的关键特征值与正常类样本取值有较大差异的特性[8],即异常点与正常点在关键特征上取值不同,故本文的DFRB以随机森林算法为基本框架,将关键特征过滤机制结合到决策树中,在树节点中记录关键特征的值域,使用该值域进行异常点的过滤。
本文DFRB算法设计为只使用正常类样本构建随机森林模型。决策树的分裂过程可描述为使用垂直于坐标轴的分割超平面进行递归划分,直至满足停止条件。
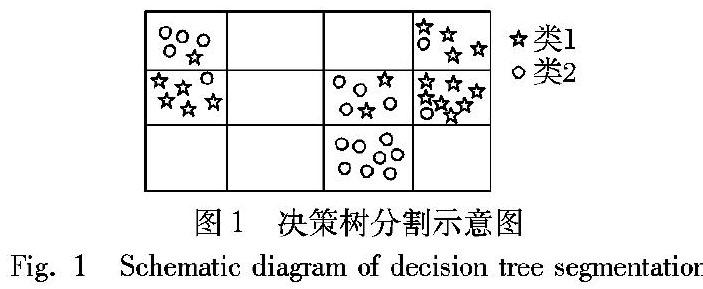
如图1所示,使用2类样本训练一棵决策树,在决策树分裂过程中设计双特征值域来刻画分裂区域,决策树训练完成时,样本空间被划分成多个不重叠区域;
若某样本落入这些区域之外,该决策树将其记为候选异常点。
这个过程即是在决策树的每个节点中设计描述正常类样本取值范围的双特征值域,该值域用于过滤出候选异常点;
当某个类别未知的样本通过DFRB随机森林模型时,每个决策树标记该样本为候选正常类或异常类,最终按照随机森林算法的判别机制(包括投票规则),识别该样本为正常类或异常类。
2.2 决策树节点的双特征值域
基于CART树,在树节点中设计双特征值域,构造一种结合双特征值域的CART(CART with Double Features, DF-CART)。构建CART时,在二叉决策树的节点中依据Gini指数得到该节点的最优特征和最优分割点,并且记录样本在两个特征上的取值范围(称为特征值域)。最优特征对决策树的分类贡献最大,将其作为一个重要考量。树节点中设计的两个特征分别是父节点的最优特征和一个随机特征。
算法2 决策树及双特征值域的生成。
输入 训练数据集D(特征个数为d);停止计算条件。
输出 DF-CART决策树(二叉树)。
1)在决策树训练过程中,从特征集合中随机选取一个包含k个特征的候选特征集,记为F。
2)在当前节点统计所有样本在父节点的最优分裂特征f上的取值,得到取值范围(值域)R( f);然后,随机选择一个特征fr,统计得到值域R( fr)。
根节点没有父节点,随机从特征集合F中选择一个特征作为根节点的父节点的最优特征f。
3)计算F中每个候选特征对当前节点的基尼指数,对应最小基尼指数得到最优分裂特征fb和最优切分点Vb,根据最优切分点生成左、右子节点。
4)对每个子节点递归重复步骤1)~3),直至满足停止条件。
停止条件:节点中的样本个数小于预定值,或样本集的基尼指数小于预设值(此时样本基本属于同一类),或者树的高度达到预设值。
2.3 结合双特征和松弛边界的异常点检测
本文算法DFRB的实现分为两个阶段:1)训练阶段。构建随机森林模型,采用算法2的决策树作为随机森林模型的基分类器。
训练完成后,得到的随机森林模型与传统随机森林不同的是在每个决策树的节点中记录了双特征的值域,用于分类阶段进行异常样本过滤。
随机森林的决策树构建时,训练数据是抽样得到,抽样数据不包含所有数据的信息,这就使得由样本得到的特征值域小于正常类数据的真实值域,很容易将正常类样本误认为是异常点,故需要对得到的特征值域作松弛处理。
2)检测阶段。引入松弛因子σ对特征值域作松弛操作。检测算法见算法3。
算法3中:a、b分别为特征值域的左右边界;|R( f)|即是|a-b|;异常比例ε表示随机森林中判断样本是异常点的决策树数量与随机森林中决策树总量的比值。
对于某样本,统计随机森林的输出结果,若判断样本为异常点的决策树所占的比例大于ε,则认为该样本点是异常点;否则归为多数票决定的类别。因每棵决策树所使用的是部分特征,而部分特征不能保证每棵决策树都能有效检测异常点,则只有部分树可以有效检测出异常点,故将ε设置在区间[0.1,0.5]内。
3 实验与结果分析
3.1 实验数据和性能指标
本文实验使用python3.6实现算法编码。选用UCI[19]中的5个数据集对算法进行测试,数据集的相关信息如表1所示。
本文选择OCSVM[3]、RFV[11]、RFP[11]、iForest[8]四种方法作性能对比:OCSVM的程序来源于libSVM[20];iForest算法速度快、精度高,在工业开发中得到广泛应用,被多个机器学习库集成,本文的测试的程序来源于sklearn库提供的iForest算法[21];
RFV和RFP算法的程序由作者依据文献[11]编写。
本文实验采用召回率(Recall, R)、精度(Precision, P)和F1作为评价指标[22]。召回率是完全性的度量(即正元组标记为正的百分比), 本文实验指异常点标记为异常的百分比;精度是精确性的度量(即标记为正类的元组,实际为正类的百分比), 本文实验指被标记为异常的元组中,实际为异常点的百分比。
采用F1指标综合评价算法性能,它是R和P的调和平均,采用以下定义:
其中:Nr表示系统正确识别的异常样本数;Nanomaly表示测试集中异常样本总数;Ndetection表示系统检测出的异常样本總数。
3.2 异常点识别性能对比
实验时,首先对数据进行归一化处理;然后采用文献[11]中的仿真模式,对一个数据集轮流选择一个类Ci(i=1,2,3,…,k)作为异常类数据(anomaly_data),其余K-1类作为正常类数据。采用10折交叉验证方法评估分类器的性能:将正常类数据按顺序分成10份,第1次实验取第1份数据和异常类数据合并作为测试集(test_data),剩余9份数据作为训练集(train_data)用于构建随机森林模型,第2次实验取第2份数据和异常类数据合并作为测试集(test_data),剩余9份数据作为训练集(train_data),以此类推重复10次实验,最后将10次实验的结果平均作为性能指标。
对RFV、RFP、iForest和本文DFRB算法,均设置随机森林中树的数目m=100,决策树停止分裂的条件是:节点中的样本个数小于3,或节点样本集的基尼指数小于10-7,或者树的高度达到10层。
OCSVM的参数取程序设置的默认值nu=0.5;
依据文献[8]中所给的参数contamination(c)范围为0.02~0.5,iForest的参数取实验效果最好时的c=0.5,DFRB的参数ε、σ分别取0.3和0.01。实验结果对比如表2~6所示。
对于seeds数据集,class1作为异常类进行测试时,本文算法的检测效果稍低于RFP、iForest和OCSVM,明显优于RFV;class2作为异常类进行测试时,本文算法的检测效果与iForest和OCSVM相当,明显高于RFV和RFP;class3作为异常类进行测试时,本文算法的检测效果低于iForest和OCSVM,明显高于RFV和RFP,可发现iForest算法获得较高召回率的同时牺牲了检测精度。对于hepato数据集,class3作为异常类进行测试时,本文算法检测效果略低于RFV,其余类作为异常类进行测试时,本文提出的算法与RFV的检测性能相当,优于RFP,检测效果明显高于经典的iForest和OCSVM方法;class3、class4分布松散,且与其他类别数据交叉严重,可分性较差,使用class3、class4作为异常类进行测试时,iForest和OCSVM效果不理想,异常点检测效果较差。wine数据集上,class2、class3作为异常点时,本文算法优于其他算法;class1类作为异常点时,本文算法的检测效率略低于iForest,与同类的RFV、RFP方法相当,不难发现iForest和OCSVM以牺牲精度获得较高的召回率,精度低于DFRB。对于forestType数据集,经典方法iForest和OCSVM在class3作为异常点时,表现较好,召回率较高;其余类别作为异常类进行测试时,RFV算法较优;本文算法在召回率方面低于其他方法,而精度高,即说明本文算法的检测准确度优于其他方法。对于dermatology数据集,本文算法整体性能优于其他方法,由实验结果可知,其他方法能获得较高的召回率,但是牺牲了精度。通过以上结果分析表明,本文算法整体表现优越,获得较高召回率的同时,也能保证检测准确度。
3.3 双特征与单特征的对比分析
本文算法利用异常点与正常点在数值上的取值不同,提出特征值域过滤机制,即在树节点中设计两个特征,训练过程中统计得到两个特征值域,并以此为依据,进行异常点的过滤。
图2是对比单个随机特征作为过滤条件时,不同数据集在召回率、精度、F1的表现。由实验可得,在召回率和F1上双值域对异常点的检测效果优于单值域,在精度上低于单值域;即随着树节点中设计的过滤条件越多,更多的异常点被检测出来,召回率增加,但是增加了正常点误认为是异常点的可能性,导致精度降低。因此,本文算法采用双特征值域进行异常点检测,在获取较高召回率的同时,保证综合性能F1较高。
3.4 综合性能F1对比分析及参数讨论
每次实验使用数据集K个类别中的一类作为异常样本(异常点)进行异常点检测,采用F1指标来反映算法综合性能,结果如图3所示,其中横轴异常点百分比表示随机选取的异常点占这类异常测试样本的比例。
从图3可看出,本文算法综合性能F1与对比方法相当或更优。例如,对于hepato数据集,class3作为异常类进行测试,本文算法的综合性能F1略低于RFV;其余各类作为异常类进行测试时,与RFV相当,高于iForest和OCSVM。对于forestType数据集,本文算法表现出色,与一类模型方法iForest和OCSVM相当,综合性能明显优于RFV和RFP。对于seeds数据集,class3作为异常类进行测试时,本文算法的综合性能低于一类模型方法iForest和OCSVM,其余类作为异常类进行测试,本文算法的综合性能与iForest和OCSVM相当,高于RFV和RFP。对于wine数据集,class1作為异常类进行测试,本文算法综合性能略低于iForest,其他类作为异常类进行测试时,本文算法性能较好,高于其他方法。对于dermatology数据集,本文算法综合性能明显优于其他方法。
本文算法中引入异常比例ε和松弛变量σ两个参数,通过设置不同的ε和σ,观察不同参数对算法性能的影响。
图4~6的仿真实验分别分析了参数ε和σ对召回率、精度、F1的影响。
首先,分析不同异常比例ε对F1的影响。固定松弛因子σ=0.01,对于每个数据集,每次实验轮流选取其中一个类作为异常点进行异常检测,得到在不同异常比例ε下的F1指标,各次实验的F1均值情况如图4所示。
由图4可知,ε的范围在0.1~0.3,F1指标高,异常检测性能最好;除seeds数据集外,随着ε的增大,F1先上升后下降,ε≥0.5时,F1趋于稳定。随机森林中,不是所有的决策树都包含有关键特征,即不是所有的树都能够识别出异常点,当ε过大时,不能识别异常点的树会增多,但这些树不影响检测性能,故F1趋于稳定。
其次,分析松弛因子σ对召回率、 精度和F1的影响。固定异常比例ε=0.3,观察在不同σ条件下的召回率、精度和F1。观察图5可得随着σ的增大,召回率呈下降趋势, 精度逐渐升高,表示随着σ的增大,异常的召回率降低,识别正确率升高,容易理解当树节点中特征值域较大时,将异常点误认为是正常点,导致召回率下降,同时将正常点误认为是异常点的概率降低,提高了异常点检测精度。为满足综合性能F1较高的要求,选择σ=0.01时,异常点的检测效果最佳。
最后,分析异常比例ε和松弛变量σ两个参数同时变化,对算法性能的影响。松弛因子σ 从0 渐变至0.07,异常比例ε从0.1渐变至0.7,观察在不同参数下的召回率、精度和F1。观察图6,随着ε和σ同时增大,召回率逐渐降低,精度逐渐提高,即随着过滤条件的放宽,异常点被检测出的可能性降低,而检测的正确率提高。考虑算法的综合性能,算法的预设参数σ=[0,0.05],ε=[0.1,0.5]是合理的。
4 结语
针对异常点检测问题,设计了DFRB算法进行异常点检测,本文算法结合异常点特性,在决策树节点中引入特征过滤,通过对关键特征的阈值比较达到检测异常点的目的。实验结果表明,本文算法相对于传统随机森林算法RFV、RFP和iForest在多个数据集上有较高的综合性能,同时本文算法避免了传统的距离度量以及相似度矩阵计算问题。本文可进一步改进的工作包括选择更合适的双特征组合和来自特殊应用的数据集参数,以进一步提高异常点检测的精度。
参考文献(References)
[1] HAWKINS D M. Identification of outliers[M]. London: Chapman and Hall, 1980: 1-2.
[2] DOMINGUES R, FILIPPONE M, MICHIARDI P, et al. A comparative evaluation of outlier detection algorithms: experiments and analyses [J]. Pattern Recognition, 2018, 74: 406-421.
[3] WANG Y, WONG J, MINER A. Anomaly intrusion detection using one class SVM[C]// Proceedings from the Fifth Annual IEEE SMC Information Assurance Workshop. Piscataway, NJ: IEEE, 2004: 358-364.
[4] SCHOLKOPF B, WILLIAMSON R, SMOLA A, et al. Support vector method for novelty detection[J]. Advances in Neural Information Processing Systems, 2000, 12(3): 582-588.
[5] 张晓惠, 林柏钢. 基于特征选择和多分类支持向量机的异常检测[J]. 通信学报, 2009, 30(增刊1): 68-73. (ZHANG X H, LIN B G. Anomaly detection based on feature selection and multi-class support vector machines[J]. Journal on Communications, 2009, 30(S1): 68-73.
[6] ERFANI S M, RAJASEGARAR S, KARUNASEKERA S, et al. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning[J]. Pattern Recognition, 2016, 58: 121-134.
[7] PAULA E L, LADEIRA M, CARVALHO R N, et al. Deep learning anomaly detection as support fraud investigation in brazilian exports and anti-money laundering[C]// Proceedings of the 2016 IEEE International Conference on Machine Learning and Applications. Piscataway, NJ: IEEE, 2016: 954-960.
[8] LIU F T, TING K M, ZHOU Z H. Isolation-based anomaly detection [J]. ACM Transactions on Knowledge Discovery from Data, 2012, 6(1): 1-39.
[9] SHEN Y, LIU H, WANG Y, et al. A novel isolation-based outlier detection method[C]// PRICAI 2016: Proceedings of the 2016 Pacific Rim International Conference on Artificial Intelligence. Berlin: Springer, 2016: 446-456.
[10] 邱一卉, 林成德. 基于隨机森林方法的异常样本检测方法 [J]. 福建工程学院学报, 2007, 5(4): 392-396. (QIU Y H, LIN C D. Outlier detection based on random forest[J]. Journal of Fujian University of Technology, 2007, 5(4): 392-396.)
[11] ZHOU Q F, ZHOU H, NING Y P, et al. Two approaches for novelty detection using random forest [J]. Expert Systems with Applications, 2015, 42(10): 4840-4850.
[12] 李贞贵.随机森林改进的若干研究[D]. 厦门: 厦门大学, 2013: 28-30. (LI Z G. Several research on random forest improve[D]. Xiamen: Xiamen University, 2013: 28-30.)
[13] 胡淼, 王开军, 李海超, 等.模糊树节点的随机森林与异常点检测[J]. 南京大学学报(自然科学版), 2018, 54(6): 1141-1151. (HU M, WANG K J, LI H C, et al. A random forest algorithm based on fuzzy tree node for anomaly detection[J]. Journal of Nanjing University (Natural Science), 2018, 54(6): 1141-1151.)
[14] BREIMAN L, FRIEDMAN J, OLSHEN R, et al. Classification and Regression Trees[M]. New York:Champman & Hall,1984:18-55.
[15] 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012: 67-71. (LI H. Statistical Learning Method[M]. Beijing: Tsinghua University Press, 2012: 67-71.)
[16] BREIMAN L. Bagging predictors [J]. Machine Learning, 1996, 24(2): 123-140.
[17] BREIMAN L. Random forest [J]. Machine Learning, 2001, 45(1): 5-32.
[18] 周志华.机器学习[M]. 北京: 清华大学出版社, 2016: 179-181. (ZHOU Z H. Machine Learning[M]. Beijing: Tsinghua University Press, 2016: 179-181.)
[19] BLAKE C L, M C J. UCI repository of machine learning databases [EB/OL]. [2018-05-10]. http://mlearn.ics.uci.edu/MLRepository.html.
[20] CHANG C C, LIN C J. LIBSVM: a library for support vector machines [EB/OL]. [2018-05-10]. http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[21] LIU F T, TING K M, ZHOU Z H. Isolation-based anomaly detection [EB/OL]. [2018-05-10]. http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html.
[22] HAN J W, KAMBER M. 数据挖掘: 概念与技术[M]. 范明, 孟小峰, 译.3版.北京: 机械工业出版社, 2012: 236-240. (HAN J W, KAMBER M. Data Mining: Concepts and Techniques [M]. FAN M, MENG X F, translated. 3rd ed. Beijing: China Machine Press, 2012: 236-240.)
猜你喜欢
中国中药杂志(2017年7期)2017-05-26
湖北农业科学(2017年7期)2017-05-13
电脑知识与技术(2017年5期)2017-04-08
时代金融(2017年6期)2017-03-25
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
电脑知识与技术(2016年23期)2016-11-02
软件(2016年2期)2016-04-08
现代电子技术(2015年15期)2015-08-14
